
Крупные компании пока используют проприетарные нейросети, мягко говоря, неохотно или не используют вовсе. Как правило, их применяют отдельные сотрудники. Частично это можно объяснить опасениями со стороны специалистов
по информационной безопасности
, ведь тот же ChatGPT, например, открыто общается с интернетом. И в этот момент на сцену выходит open source.
В этой статье поговорим, из чего состоит h2oGPT, на каких моделях функционирует, какими метриками оценивается и в какой сервис «завернут». Дополнительно взглянем на конкурентов и ситуацию на рынке в целом.
Используйте навигацию, если не хотите читать текст полностью:
→ Что такое h2oGPT
→ H2O LLM Studio
→ Какие модели доступны пользователям
→ Обучение модели
→ Обзор участников рынка
Что такое h2oGPT
h2oGPT представляет собой набор репозиториев с открытым исходным кодом, «обернутый» в оболочку H2O LLM Studio (о ней подробнее в следующем разделе). Само название проекта уже недвусмысленно намекает нам на применение Generative Pretrained Transformer. Кстати, самостоятельно познакомиться с ботом поближе и почитать документацию можно на сайте разработчика, на Hugging Face или на GitHub.
Компания H2O.ai, разработчик h2oGPT, заявляет, что ее продукт — часть инициативы по внедрению больших языковых моделей в корпоративный сегмент через open source. По словам разработчиков, их цель — представить открытые альтернативы коммерческим LLM, сделать доступ к таким моделям свободным и, в то же время, «ответственным». При этом акцент сделан на безопасности h2oGPT для использования внутри компаний, поскольку чат-бот может «жить» в пределах корпоративной сети, не отдавая данные в интернет.
h2oGPT может работать с различными типами и форматами файлов, включая csv, docx, pdf, mp3, zip, txt, ppt и wav. Понимает Markdown- и HTML-разметку, может читать электронные письма и так далее. В его составе значатся языковая модель, эмбеддинг, базы данных для документов, интерфейс командной строки, а также расширенный интуитивно понятный графический интерфейс. Последний включает в себя функции для работы пользователя, поддержку голосового TTS с использованием лицензированных Microsoft Speech T5, в том числе клонирование голоса и потоковую аудио-конвертацию, а также режим голосового управления AI Assistant для беспроводного управления чатом h2oGPT.
Чат-бот поддерживает интеграцию с различными инференс-серверами: HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI и Anthropic. Более того, последняя предлагает API для работы с сервером и клиентом на Python. Это позволяет использовать h2oGPT в качестве замены OpenAI и обеспечивает высокое качество по результатам более чем 1 000 единичных и интеграционных тестов.
Что отмечают разработчики
- Поддержка открытой векторной базы данных Chroma и векторной базы данных Weaviate;
- Суммаризация и извлечение информации, которое достигает производительности 80 токенов в секунду при использовании модели LLaMa;
- Применение HyDE (Hypothetical Document Embeddings) для улучшения поиска на основе ответов LLM;
- Поддержка моделей LLaMa2, Mistral, Falcon, Vicuna, WizardLM, AutoGPTQ;
- Поддержка инференс-серверов HF TGI, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic.
- Поддержка Docker.
Помимо этого h2oGPT может работать на Linux, macOS и Windows, поддерживает UI или CLI с потоковой передачей всех моделей и воспринимает любую открытую LLM от Hugging Face. А еще поддерживает веса адаптера
, 4-битное квантование и умеет работать без интернета.

H2O LLM Studio
H2O LLM Studio — платформа для обеспечения качества данных и расширение h2oGPT для обучения LLM. Платформа предлагает веб-интерфейс без кода и Python API. Это, вероятно, будет плюсом для пользователей, у которых нет больших навыков в программировании. То есть, обучать и настраивать языковую модель можно через графический интерфейс без кодинга.
В H2O LLM Studio пользователь может настроить:
- набор данных,
- модель,
- оптимизатор,
- learning rate,
- токенизатор,
- адаптер,
- валидационный набор данных и т. д.
При этом полностью поддерживаются логирование, валидация и мультимодальность. Если достаточно вычислительных ресурсов, пользователь может отслеживать прогресс обучения, степень понимания моделью контекста, корректность ответов, предвзятость, запоминание данных и другие параметры.
Также есть информация, что LLM Studio использует популярные адаптеры для файнтюнинга. Среди них — Low-Rank Adaptation (LoRA) и QLoRA. Такой подход позволяет проводить дообучение небольших LLM на обычных GPU — даже в Google Colab или Kaggle. Например, модели, которые содержат менее 10 миллиардов параметров, можно обучить на одной NVIDIA T4 16 ГБ.
Тут нужно сделать оговорку: применение одной видеокарты для обучения LLM хоть и возможно, но вряд ли оправдано с практической точки зрения. Такой эксперимент мы проводили, когда сравнивали возможности GPU A100 40 GB и A6000 Ada 48 GB для обучения больших языковых моделей.
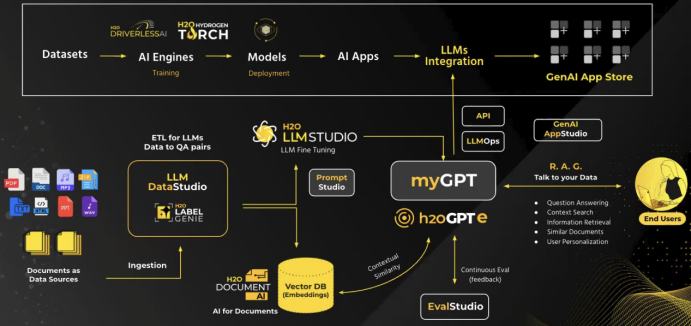
Архитектура и пайплайн продуктовой линейки H2O.ai. Источник.
Возможности H2O LLM Studio
H2O LLM Studio функционально настроена на выполнение множества задач. Модели можно обучить резюмированию длинного текста, следованию инструкциям, генерации ответов с учетом логической связности и т. д. Кроме того, разработчики обещают, что h2oGPT можно применять в самых разных коммерческих сферах.
H2O.ai заявляет, что планирует интегрировать новые методы квантования моделей, дистилляции и длинно-контекстного обучения (длина контекста более 100 тысяч токенов). Компания также планирует поддерживать больше мультиязычных и мультимодальных моделей, упростить масштабирование и добавить возможность изменения базового кода под корпоративные нужды.
Вот что еще H2O LLM Studio обещает пользователям:
- простой и быстрый файнтюнинг любой доступной LLM без необходимости какого-либо опыта кодирования;
- использование графического интерфейса пользователя (GUI), специально разработанного для больших языковых моделей;
- применимость LoRA, а также 16-, 8- и 4-битной моделей обучения;
- использование расширенных метрик для оценки сгенерированных моделью ответов;
- визуальное отслеживание и сравнение производительности моделей посредством интеграции с Neptune;
- легкий экспорт своих моделей в Hugging Face Hub.
Чтобы запустить GUI для чат бота в самом базовом варианте, используйте команду:
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-12b
Что стоит учесть при работе с H2O LLM Studio
- Набор для обучения должен присутствовать в виде пары «запрос — ожидаемый ответ».
- Как всегда, важен ответственный подход к выбору контента для обучения моделей (например, чтобы избежать оскорблений, унижений, притеснений по какому-либо признаку).
- «галлюцинации» выбранных LLM — проблема пользователей, которую придется решать самостоятельно.
Пайплайн работы с системой H2O LLM Studio
Типичный рабочий процесс подготовки данных в H2O LLM Studio включает несколько последовательных шагов.
- Загрузка данных пользователем. В процессе из коннекторов импортируются различные типы документов;
- Выбор целевой задачи обучения (предварительное обучение, настройка инструкций, разработка чат-бота или RLHF);
- Включение в набор дополнительных данных из других источников;
- Очистка данных — например, удаление длинных строк с чистыми пробелами или необычными символами, которые могут помешать анализу или моделированию;
- Проверка качества данных c использованием метрик bleu / meteor / similarity или модели вознаграждения RLHF. При необходимости в проверке можно использовать дополнительные фильтры — например, по длине или на наличие ненормативной лексики;
- Преобразование данных и метаданных в подходящий формат, например JSON;
- Подготовка данных в соответствии с требованиями целевой модели — например, по длине контекста или отсечения.

Какие модели доступны пользователям
Сегодня у пользователей есть доступ к нескольким настроенным моделям, на которых функционирует h2oGPT. Они содержат до 40 млрд параметров и подходят для коммерческого использования под лицензиями Apache 2.0. Рассмотрим некоторые из них.
Pythia-6.9b
Это
с 6,9 миллиардами параметров, обученная
от
. Основное внимание разработчики уделили исследованиям в области интерпретируемости и динамики обучения, а не применению в коммерческих чат-ботах. Pythia6.9b была оценена с использованием
.
Исследование Pythia направлено на понимание того, как развиваются и эволюционируют LLM в процессе обучения и масштабирования. Pythia-6.9b, как и остальные в наборе, основана на архитектуре GPTNeoXForCausalLM и использует трансформеры для обработки текста. Модель доступна для работы через Hugging Face и содержит 9,9 ГБ файлов, разделенных на две части.
Характеристики модели
- Размер модели: 6,9 миллиардов параметров;
- Требуемая VRAM: 13,8 ГБ;
- Поддерживаемые языки: английский;
- Архитектура модели: GPTNeoXForCausalLM;
- Длина контекста: 2 048 токенов;
- Максимальная длина модели: 2 048 токенов;
- Версия трансформеров: 4.22.2;
- Класс токенизатора: GPTNeoXTokenizer;
- Размер словаря: 50 432;
- Диапазон инициализации: 0.02;
- Тип данных Torch: float16.
Pythia-12b и Pythia-12b-deduped
Обе модели — часть серии Pythia и используются для генерации текста на английском языке. Суффикс deduped в названии указывает на то, что модель была очищена от дублирующих данных во время обучения.
Pythia-12B и Pythia-12B-deduped содержат по 12 миллиардов параметров. Эти модели были обучены на одинаковых данных в одном и том же порядке и включают в себя по 154 промежуточные контрольные точки. Обе разработаны для исследований в области интерпретируемости и превосходят по производительности аналогичные модели, например, из наборов OPT и GPT-Neo.
GPT-neox-20b
Это авторегрессионная языковая
с 20 миллиардами параметров, разработанная EleutherAI и обученная на большом
с использованием библиотеки
. GPT-neox-20b во многом
на GPT-J-6B.
В ходе обучения модели особый акцент был сделан на разработке подходящей параллельной архитектуры для обучения на нескольких графических процессорах. Несмотря на потенциал модели, есть трудности в ее развертывании. Для этого придется установить соответствующее оборудование и увеличить размер входных данных до 2 048 токенов. Это потребует больше видеопамяти.
MPT-7b-storywriter
относится к семейству
(MPT), разработанных компанией
. Они используют модифицированную архитектуру трансформеров, оптимизированную для эффективного обучения и инференса. В частности, MPT-7B-StoryWriter-65k+ была специально обучена на подмножестве книг из
для чтения и создания вымышленных историй с очень длинными контекстами.
Модель основана на модифицированной архитектуре декодера-трансформера и была обучена с использованием технологий FlashAttention и ALiBi (Attention with Linear Biases). Последняя — ключевой архитектурный выбор в модели MPT-7B, который позволяет модели обрабатывать контексты длиной до 65 000 токенов и даже выходить за пределы этого количества при выводе. MPT-7B-StoryWriter-65k+ способна генерировать тексты длиной до 84 000 токенов на одном узле с восемью GPU A100 80 GB.
Falcon-7b
из семейства Falcon, разработанного TII. Содержит семь миллиардов параметров и предназначена только для генерации текста (causal decoder-only). Обучена на 1,5 триллионах токенов
, и доступна под лицензией Apache 2.0.
Разработчики обучали модель на 384 графических процессорах A100 (40 ГБ) с использованием стратегии 2D-параллелизма (PP = 2, DP = 192) в сочетании с ZeRO на AWS SageMaker. Изначально Falcon-7B обучена только на английском и французском языках.
Bloom-176b
Открытая авторегрессионная
со 176 миллиардами параметров, разработанная и обученная с использованием
на
. Он включает сотни источников на 46 естественных и 13 программных языках.
Bloom использует для обучения технологию Megatron-DeepSpeed. Она позволяет эффективно распределять обучение по нескольким устройствам, используя параллелизм данных, тензоров и конвейеров. Модель обучена с использованием алгоритма Byte Pair Encoding (BPE) и может распознавать и использовать 250 680 уникальных токенов.
Bloom демонстрирует высокую производительность в задачах многоязычного резюмирования. И она увеличивается с ростом количества параметров модели. Кроме того, общая точность Bloom на тестах crowS-Pairs для английского и французского языков была близка к 0.50.
На практике применение этой LLM в h2oGPT выглядит достаточно сомнительным: модель слишком тяжела для чат-бота и дообучения. Для работы Bloom-176B нужно 360 ГБ оперативной памяти. Однако Microsoft представила уменьшенную версию с весами INT8 (от оригинальных весов FLOAT16), которая работает на движке DeepSpeed Inference и использует параллелизм тензоров. Эта версия модели разделена на восемь частей и может быть распределена по восьми GPU, что позволяет более эффективно использовать доступные ресурсы.
Небольшое резюме по моделям
Большинство перечисленных LLM обучены на относительно небольшом количестве токенов с использованием законов масштабирования
. Однако оказалось, что небольшие модели, тренированные на большем количестве токенов, такие как LLaMa и Falcon, могут работать еще лучше.
За исключением mpt-7b-storywriter, все перечисленные модели имеют относительно небольшую длину контекста (2 048 лексем) и могут резюмировать примерно одну страницу текста. Очевидно, модели с большей длиной контекста были бы предпочтительнее для многих генеративных задач.
Также все перечисленные модели, кроме falcon-7b, были обучены на наборе данных Pile объемом 825 ГБ. Falcon обучалась на RefinedWeb, который представляет собой 2,8 ТБ интернет-данных, подготовленных с помощью усовершенствованных методов фильтрации и дедупликации.
Обучение модели
Подход к обучению
Вот как сами разработчики h2o.ai
процесс обучения.
Для обучения h2oGPT используется PEFT, стандартный пайплайн по работе с Hugging Face, и LoRA (Low Rank Approximation). К тому же, в таких условиях требуемое состояние оптимизатора составляет порядка 20 МБ вместо 20 ГБ.
В результате количество параметров для обучения обычно составляет около 0,1% от исходных весов, а степень аппроксимации можно настроить с помощью всего нескольких параметров, большинство из которых не оказывают большого влияния на точность. Это делает LoRA одной из самых полезных техник для эффективного файнтюнинга.
Чтобы еще больше снизить требования к памяти дорогостоящих GPU, разработчики отказались от 32- и 64-битной полной точности обучения. Вместо этого они использовали 16-, 8- и 4-битное обучение с использованием аппаратной и программной поддержки смешанной точности.
Обучение или инференс с базовой моделью в 8- или 4-битном формате достигается с помощью PEFT и BitSandBytes. Обратная сторона такой экономии — время на обучение модели и генерацию текста, которое существенно увеличивается по сравнению с 16-битной архитектурой.
Для файнтюнинга разработчики h2oGPT рекомендуют использовать карты NVIDIA A100 или H100. Или применить 4-битное обучение для карт с меньшим объемом видеопамяти. При этом 16-битное обучение рекомендуется использовать везде, где это возможно. Далее приводится краткое сравнение требований для обучения LLM:
Метрики оценки качества моделей
Для оценки качества работы моделей H2O.ai использует комплекс
, чтобы убедиться, что настроенные LLM все еще демонстрируют те же базовые возможности, что и исходные. Также дополнительно применяются подсказки
, предоставленные h2oGPT, для улучшения качества ответов и оценивания их результатов. В качестве
используют
или более продвинутые LLM, такие как GPT-3.5/4.
Среди выявленных недостатков генеративных моделей:
- обрывы рассуждений в цепочке мыслей (фактологическая несвязность),
- ошибки в операциях и нарушение логики (потеря цепочки рассуждений),
- некорректная интерпретация кода,
- погрешности в представлении фактов (галлюцинирование или потеря исходного источника).
Обзор участников рынка
Раз уж мы говорим о h2oGPT как продукте для коммерческого использования, почему бы не взглянуть на то, что сегодня уже есть на рынке? Посмотрим, какие продукты занимают лидирующие позиции, в чем их особенности, сильные стороны и как они себя позиционируют. А также — чего им удалось добиться за прошедшее время.
OpenAI
— одна из наиболее известных реализаций LLM, разработанная OpenAI. Нейросеть генерирует текст, отвечает на вопросы, ищет ошибки в коде, переписывает код с одного языка на другой, создает простые полнофункциональные приложения, умеет спорить, делает прогнозы, дает персональные советы и т. д.
Кроме того, есть попытки применения ChatGPT для решения серьезных технологических задач, например, поиска новых материалов, генерации медико-биологических компонентов для вакцин, доказательства математических теорем или создания дизайна.
Известно, что OpenAI ведет переговоры о привлечении более восьми миллиардов долларов от холдинга G42 из Абу-Даби, специализирующегося на ИИ. Полученные инвестиции пойдут на разработку собственных чипов в надежде отказаться от влияния NVIDIA (а может, даже составить конкуренцию производителю).
Планируется, что новые чипы будут носить название Tigris. Но и на этом OpenAI не собирается останавливаться. После того, как в нее уже было вложено 13 миллиардов долларов от Microsoft, начался новый виток переговоров о вложении еще 100 миллиардов при эмиссии собственных акций на 86 миллиардов долларов.
Таким образом, если Сэму Альтману удастся пройти все «тонкие» моменты, его компания станет вторым самым дорогим стартапом в истории. Пальма первенства пока что у Илона Маска с его SpaceX (150 миллиардов долларов), но возможно, ему придется уступить.
— прямой конкурент ChatGPT. Он интегрирован с реальными результатами поисковых запросов и поддерживает большинство расширений Google, таких как Google Maps и YouTube. Это делает его более актуальным для пользователей. Кроме того, Gemini способен понимать не только текст, но и видео, изображения и аудио, решать математические и физические задачи, а также писать код на разных языках программирования с разной степенью точности.
Вероятно, Сундар Пичаи продолжит политику, начатую в 2023 году, по достижению «амбициозных целей» по наращиванию прибыли и сокращению издержек на производство. После запуска Gemini акции Google выросли на 6%, тогда как количество сотрудников снизилось на 12 000 человек, причем под сокращение попали разработчики из разных отделов, таких как Asistant и Fitbit. Видимо, в этом году политика останется неизменной.
Stability.AI
— первый крупномасштабный открытый чат-бот, обученный так, чтобы соответствовать ожиданиям человека. Этот метод обучения называется Reinforcement Learning from Human Feedback, или RLHF. Stable Vicuna является развитием модели Vicuna v013b.
Microsoft
— система, которая состоит из LLM в качестве контроллера и имеет множество экспертных моделей из состава совместных исполнителей (из HuggingFace Hub). Платформа Hugging Face предоставляет инструменты и ресурсы для разработчиков и исследователей, чтобы облегчить создание, обучение и развертывание моделей машинного обучения. Она включает в себя библиотеки для работы с моделями, такие как Transformers и Tokenizers, а также платформу для хостинга и совместной работы над моделями, наборами данных и приложениями.
Anthropic
— чат-бот от Anthropic, который использует собственную языковая модель для обработки и генерации текста. По словам разработчиков, отличие Claude в том, что он ориентирован на безопасность и ответственность. Чат-бот способен генерировать и анализировать длинноформатные тексты (блоги, эссе и т. д.), а также код.
Sber
— голосовой помощник, разработанный компанией Sber в рамках собственной цифровой банковской экосистемы, но ориентированный на широкого пользователя. GigaChat использует передовые технологии искусственного интеллекта для обработки естественного языка при общении с пользователями. Он предоставляет возможность задавать вопросы, получать информацию, генерировать код, управлять банковскими услугами и выполнять другие задачи с помощью голосовых команд и текстовых сообщений.
По последним данным, финансовый эффект от применения GigaChat должен составить не менее 10 миллиардов рублей, модель активно развивается и совершенствуется, а доступ открыт для всех желающих.
Общие проблемы нейросетей в корпоративной среде
Несмотря на распространение языковых моделей, они пока не находят широкого применения в большом продакшене из-за некоторых трудностей, бюрократических вопросов, этики, клиентоориентированности, корпоративных секретов и безопасности.
Возможно, именно последний пункт можно назвать решающим. Специалисты по информационной безопасности опасаются внедрять во внутренние системы генеративные AI-продукты, а разработка частных LLM пока доступна далеко не каждой компании. Решит ли эту проблему open source-проект h2oGPT — покажет время.
Как думаете, есть ли будущее у LLM с открытым исходным кодом в коммерческой сфере? Делитесь мнением в комментариях.


