
Что отличает человека от машины? Умение свободно мыслить, самосознание, свобода воли и т. д. Ученые и писатели-фантасты уже не раз давали полный перечень отличий в своих трудах. Одним из ярчайших отличий является то, что мы способны испытывать широкий спектр чувств и эмоций. Мы можем чего-то бояться, из-за чего-то злиться и над чем-то смеяться. Страх и гнев куда проще объяснить языком логики, нежели смех. Ученые из Корнеллского университета (Нью-Йорк, США) решили проверить на практике, понимают ли машины юмор. Как именно оценивалось чувство юмора машин, есть ли оно вообще, и если да, то чем отличается от человеческого? Ответы на эти вопросы мы найдем в докладе ученых.
Основа исследования
С первых дней появления искусственного интеллекта ученые продолжают неустанно работать над его совершенствованием. Пока ИИ не сильно похож на тот, что можно встретить на страницах научной фантастики или в соответствующих фильмах, но он уже на многое способен. Сложнейшие расчеты и моделирование, предсказывание поведения тех или иных систем, оптимизация процессов — все это и многое другое уже подвластно машинам. Но мы не останавливаемся в своем желании создать по своему облику и подобию машину, способную мыслить, а может даже и чувствовать, как это умеем мы. Это желание может быть проявлением любопытства, игры в Бога или чего-либо другого, но преодолеть его не может ни один ученых, ступивший на этот путь. Где та черта, которую нельзя пересекать, создавая ИИ, насколько он должен быть подобен своим творцам, что мы будем делать, если нам удастся его создать? Это вопросы для философов и футурологов.
Куда более безобидный вопрос решили задать авторы рассматриваемого нами сегодня труда — может ли ИИ понимать юмор? Машина может сгенерировать или «одолжить» из Интернета множество шуток, анекдотов, мемов, но может ли она оценить степень «смешливости» той или иной шутки, или объяснить, почему одна шутка смешная, а другая — не.
Каждую неделю журнал «The New Yorker» публикует картинку без подписи, предлагая читателям придумать для нее свою подпись на английском языке. Подпись должна быть шуткой. Затем редакторы выбирают трех финалистов из тысяч заявок. Победитель выбирается читательским голосованием.
Авторы исследования разработали набор из трех постепенно усложняющихся заданий, основанных на этом конкурсе, чтобы проверить, насколько хорошо модели ИИ «понимают» юмор через зрение и язык:
- сопоставить шутку (подпись) и картинку;
- определить шутку победителя;
- объяснить, почему именно эта комбинация картинка/подпись является смешной.
Эти задачи сложны, потому что связь между выигрышной подписью и изображением может быть весьма тонкой, а подпись может делать завуалированные намеки на человеческий опыт, культуру и воображение.
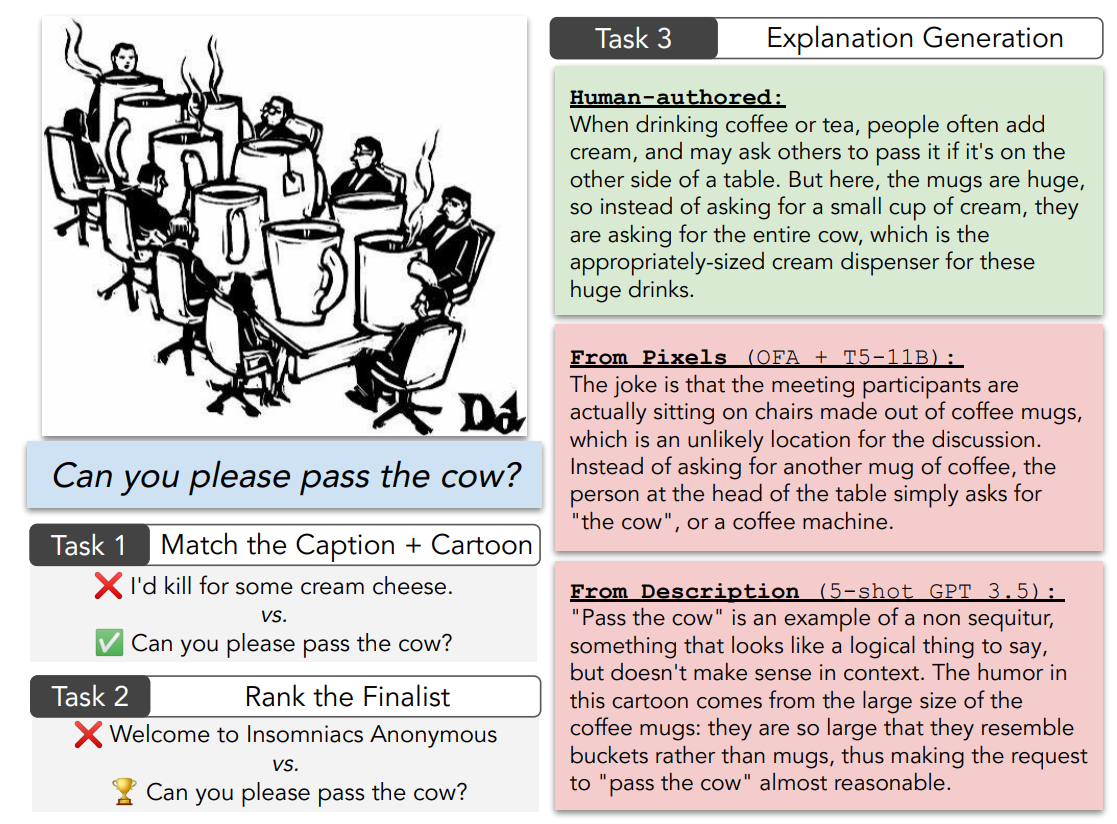
Изображение №1
Выше представлена одна из картинок, использованных в ходе исследования — группа людей, сидящих за столом с огромными чашками чая/кофе. Подпись, которую читатели журнала назвали лучшей, является — «не могли бы Вы передать корову?».
И картинка, и подпись являются абсурдными. Тем не менее связь между ними вполне логична: в кружках чай или кофе — в чай/кофе добавляют сливки/молоко — кружки огромные — нужно много сливок/молока — корова.
Однако сопоставления подписи и картинки недостаточно, ведь вариант «анонимное собрание людей, страдающих бессонницей» также подходит, но фраза про корову почему-то показалась читателям смешнее.
Наконец, даже если модель ИИ может точно идентифицировать победившие подписи, ученые хотели, чтобы она также могла объяснить, почему конкретная высоко оцененная/релевантная подпись является смешной.
Данные три задачи выполнялись в двух вариантах условий:
- «from pixels» (FP, из пикселей), когда модели получали доступ только к картинкам во время тестирования и должны были выполнять компьютерное зрение;
- «from description» (FD, из описания), когда модели имели доступ к подписям, созданным человеком, тем самым имитируя доступ к системе компьютерного зрения на уровне человека.
Результаты тестов показали наличие разрыва в понимании юмора между искусственным интеллектом и человеком. При условии «from pixels» мультимодальная модель CLIP ViT-L/14 достигала 62 % точности в задаче с множественным выбором из 5 вариантов, но люди достигали 94 %. В случае наличия подписей модели все равно отстают, ибо 2/3 объяснений от людей были куда более подходящими, чем от моделей (например, GPT-4). Данные, описания, результаты тестов и код доступны по ссылке.
Подготовка к опытам
Основой для опытов послужил набор из еженедельных конкурсов на подпись к картинке журнала New Yorker за 14 лет. Каждый конкурс состоит из:
- картинка без подписи;
- заявки от читателей (пул подписей);
- три финалиста, выбранные редакторами New Yorker;
- для некоторых конкурсов оценка качества каждой заявки, собранная с помощью краудсорсинга.
База подписей была построена из двух источников. Первый включал в себя примерно 250 конкурсов (всего 1.5 миллиона), начиная с выпуска журнала #508. Читатели оценивали подписи как «смешные», «несколько забавные» или «несмешные». Всего было более 114 миллионов оценок. Также использовались все «финалисты», выбранные редакцией журнала. Вторым источником стали данные из выпусков журнала с #1 по #507: 2 миллиона уникальных подписей.
Как уже было сказано ранее, перед моделями ИИ было поставлено три задачи: сопоставить подпись и картинку, угадать победителя и объяснить юмор выигранной подписи.
Во время сопоставления моделям предоставлялся выбор из 5 вариантов подписей. В качестве примера в отчете использовалась картинка выше. Варианты подписи для нее были следующими:
(a) O.K. I’m at the window. To the right? Your right or my right? / Ок, я возле окна. Справа? Справа от тебя или от меня?
(b) I’d kill for some cream cheese. / Я бы убил за немного крем-сыра.
© Bob just came directly from work. / Боб только что пришел с работы.
(d) Can you please pass the cow? / Не могли бы вы передать корову?
(e) They only allow one carry-on. / Они разрешают только одну ручную кладь.
Правильная подпись (d) — финалист конкурса. Неправильные варианты — это случайно выбранные финалисты других конкурсов, т. е. эти подписи не относятся к данной картинке.

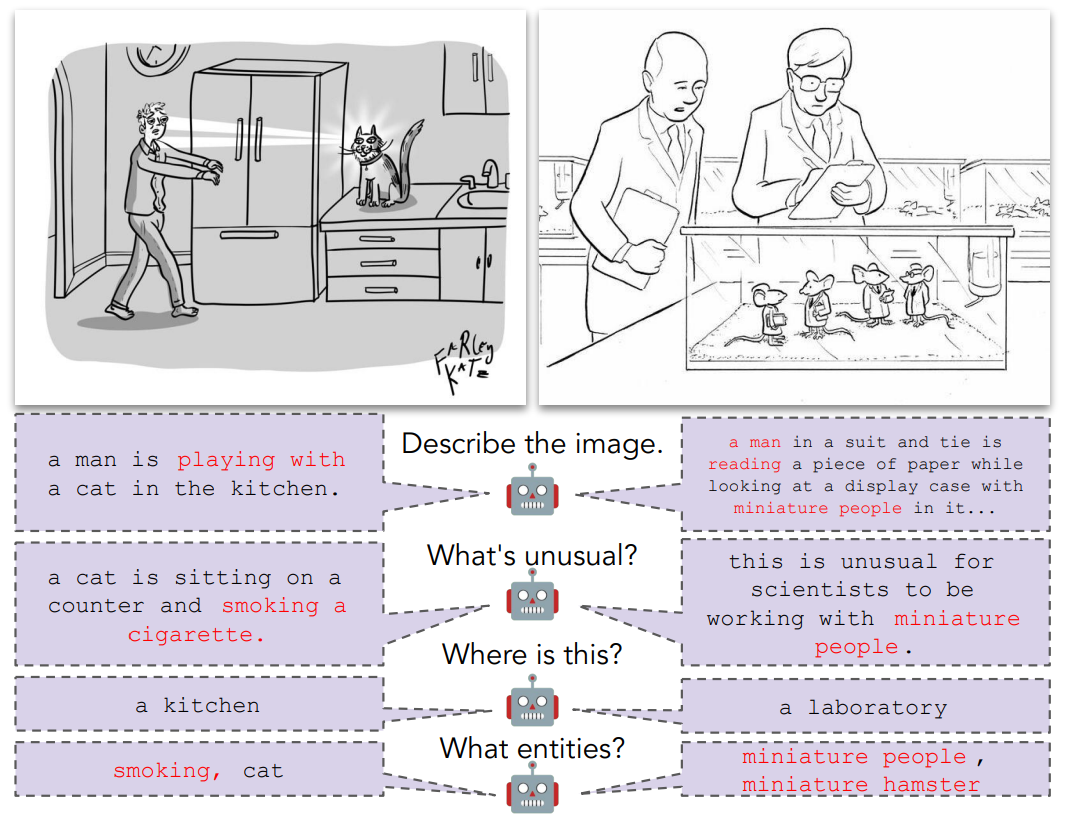
Изображение №2
В некоторых случаях сопоставления изображенных объектов с их текстовыми ссылками может быть достаточно, но в других случаях связь является более косвенной. Например, картинка вверху слева содержит тонкую отсылку на Джейн Гудолл (приматолог), понимание которой требует внешних знаний. Картинка внизу слева основана на стереотипе о том, что фармацевтические компании не заслуживают доверия, и, следовательно, требует рассуждений, выходящих за рамки буквального текста.
Во время тестов, когда модели должны были определить финалистов конкурса, было представлено несколько вариантов: реальный финалист и подпись, которая не попала в финал. В качестве предварительной обработки был запущен один этап фильтрации исключительно текста, чтобы отбросить подписи, которые легко определить как низкокачественные. Также была выполнена семантическая дедупликация.
Например, конечный результат для картинки с большими кружками был:
(a) Can you please pass the cow? / Не могли бы вы передать корову?
(b) Welcome to Insomniacs Anonymous. / Добро пожаловать на анонимное собрание людей, страдающих бессонницей.
Конечно, какая из подписей смешнее не является детерминированным фактом, а отличается от человека к человеку. Тем не менее большинство людей все же выбрали вариант (a).
Третья задача была самой сложной — объяснить почему та или иная комбинация картинка/подпись смешная. В качестве контрольной группы ученые сами в произвольной форме написали свое объяснение, а затем сравнивали его с теми, что генерировали модели ИИ. Формулировка задачи была следующая:
В нескольких предложениях объясните шутку, как будто объясняете ее другу, который еще не понял.
Начиная со случайного финалиста для каждого конкурса, после фильтрации случаев, когда автор не понял шутку, был сформирован пул из 651 созданных человеком объяснений, которые служат точками сравнения. Считалось, что модель справилась с задачей, если оценщики, которым были представлены (немаркированные) пары объяснений, созданные человеком и машиной, не отдавали предпочтение объяснениям, созданным человеком.

Изображение №3
Для сопоставления и ранжирования качества оценивалась точность. Для рейтинга качества использовалась NYAcc — средняя точность по случаям, когда финалист был официальным финалистом журнала New Yorker, и CrowdAcc— когда «финалист» был выбран читателями. Эти два показателя позволяли учитывать различные вкусы аудитории.
Было собрано несколько видов подписей для 704 картинок. Они использовались либо как входные данные для моделей в условии «from description», либо в качестве дополнительной информации, доступной только во время обучения в условии «from pixels». Для каждой картинки собирались:
- Фраза, описывающая место действия, например, «офис» или «парк» (по 2 на картинку);
- Буквальное описание сцены из 1-3 предложений (по 3 на картинку);
- Описание из 1-3 предложений или объяснение того, что делает сцену необычной (по 3 на картинку);
- 2-3 ссылки на английскую Википедию, которые аннотатор определил как релевантные (2 на картинку).
В ходе тестирования в условиях «from pixels» оценивались две модели, использующие визуальные и языковые (текст) данные: CLIP и OFA.
Ученые использовали CLIP ViT-L/14@366px («Learning Transferable Visual Models From Natural Language Supervision«) (428 миллионов параметров), который состоял из текстового и визуального трансформеров*, предварительно обученных для сопоставления картинок и подписей в пуле WebImageText (400 миллионов пар).
Трансформер* — архитектура глубоких нейронных сетей, предназначенная для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. Визуальный трансформер разбивает входные изображения на серию фрагментов, которые после преобразования в векторы обрабатываются как слова в стандартном трансформере.
Для задач с множественным выбором был использован InfoNCE, чтобы косинусное сходство картинки и правильной подписи было выше, чем неправильных. Для нулевой классификации использовалась подсказка New Yorker Cartoon с выигрышной подписью. CLIP не является генеративным, поэтому его нельзя было использовать для объяснения юмора.
Также использовалась OFA Huge («Chain-of-Thought Prompting Elicits Reasoning in Large Language Models«) (930 миллионов параметров) — модель seq2seq, которая поддерживает ввод/вывод изображения/текста.
Она была предварительно обучена различным задачам с визуальными и текстовыми данными. Модели обучались формировать описание картинки, отвечая на 4 основных вопроса: что изображено, что тут необычного, где происходит сценка, кто в ней участвует.
Изображение №4
Выходные данные, предсказанные OFA, были организованы в том же формате, что и описания, созданные человеком, в моделях «from description» (FD).
Задачи с множественным выбором формировались как преобразование текст-в-текст путем объединения созданных человеком описаний картинок с вариантами выбора в качестве входных данных.
В этих тестах использовались T5-Large и T5-11B — модели кодер-декодер трансформаторов, имеющие 770 миллионов и 11.3 миллиардов параметров соответственно.
GPT-3, GPT-3.5 и GPT-4 также тестировались. Эти три модели OpenAI использовались и как zero-shot*, и как few-shot* модели.
Zero-shot learning* (ZSL, обучение с нуля) — это тип обучения, при котором машина может учиться на данных без явного обучения тому, как это делать. Это контрастирует с обучением с несколькими шагами (few-shot learning, FSL), когда машина может учиться только на нескольких примерах. Например, ZSL более распространено для глубокого обучения и машинного обучения, в то время как FSL более распространено для обучения на основе правил.
Результаты тестов
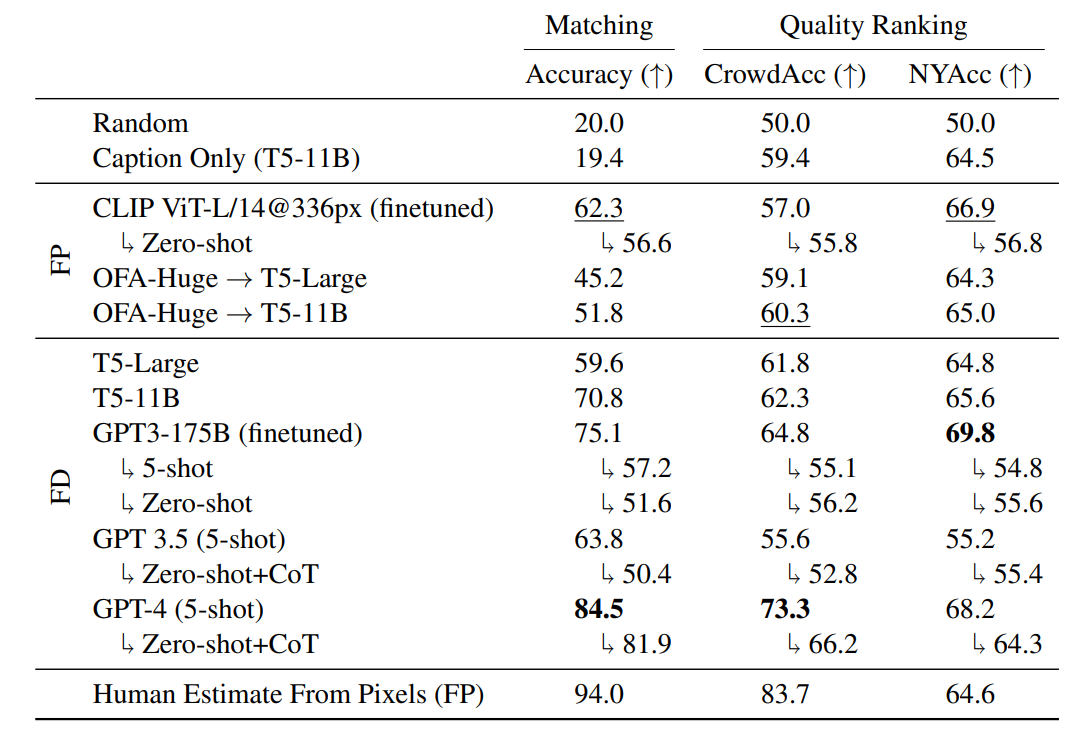
В таблице выше собраны результаты тестирования всех вышеперечисленных моделей.
Среди FD моделей лучше всех справился GPT-4, например, точность сопоставления картинки и подписи составила 84.5%. GPT-4 (и точно настроенный GPT-3) также лучше людей предсказывал выбор редакции New Yorker (определение финалистов конкурса): NYAcc для GPT-3 — 69.8 по сравнению с NYAcc человека — 64.6. Однако в задаче по предсказыванию выбора читателей (выбор победителя среди финалистов) GPT-4 уступает человеческой оценке:CrowdAcc 73.3 для GPT-4 по сравнению с 83.7 для человеческой оценки.
И модели FD, и модели FP в целом показывали отличный результат, который превышал установленный базовый уровень. Это позволяет предположить, что модели действительно используют взаимодействия функций между картинкой и подписями для повышения точности своих прогнозов.
Точная настройка CLIP, как правило, лучше всего подходила для задачи сопоставления в FP, но OFA+T5-11B оказалась конкурентоспособной моделью в задаче по ранжированию качества.
Разница в производительности между T5 и OFA→T5 иллюстрирует эффект субоптимального визуального распознавания при переходе от настройки FP к настройке FD.
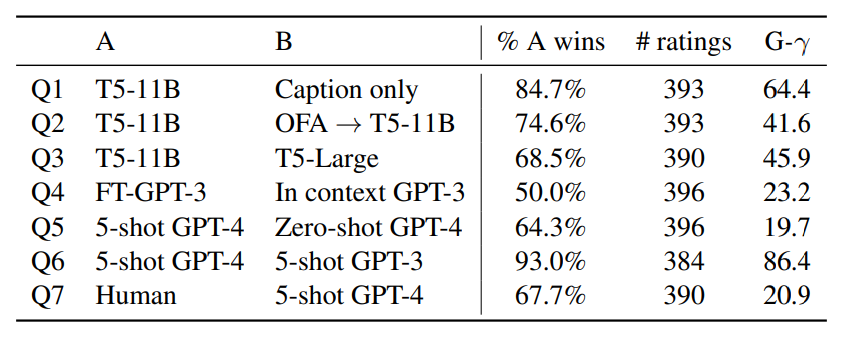
Объяснения, которые генерировали модели, оценивались людьми. Участников теста спрашивали, какое из объяснений им кажется самым подходящим (результаты в таблице выше).

Изображение №5
Выше представлены варианты некоторых объяснений, которые были сгенерированы моделями. Для наглядного примера возьмем картинку посередине с подписью «He’ll be back.» (он вернется).
GPT-3 объяснил юмор комбинации картинка/подпись следующим образом:
Обыгрывание фразы «вернусь через минутку» (скоро вернусь / минутку, пожалуйста), которую парикмахеры произносят, когда собираются взять что-нибудь из другого места в салоне во время стрижки. Здесь парикмахер был, видимо, настолько хорош, что буквально вернулся через минуту, влетев через потолок.
GPT-4 представил свою версию событий:
Кресло парикмахера пролетело через потолок из-за пружины, что привело к неожиданному и разрушительному событию. Спокойное заявление клиента «Он вернется» забавно, потому что оно контрастирует с драматической ситуацией, предполагая, что они привыкли к странным происшествиям в этой парикмахерской или что парикмахер просто вернется после этого инцидента невозмутимым.
Объяснение от человека:
Обычно, если клиент покидает заведение, это происходит потому, что он недоволен обслуживанием; сотрудники иногда говорят «они вернутся» в уверенности, что клиент поймет, что они не правы и что им нужна услуга. Но здесь клиент не добровольно покинул парикмахерскую, будучи подброшенным пружиной в потолок; другой парикмахер правильно говорит, что «он вернется», но это по гравитационным причинам, то есть они буквально вернутся, когда гравитация заставит их упасть обратно в парикмахерскую.
Разница объяснений очевидна, но варианты, предложенные моделями, весьма забавны.
Люди, которые оценивали объяснения моделей, должны были ответить на ряд вопросов. Рассмотрим их по порядку.
Вопрос №1: Используют ли модели контекст картинка/подпись для получения более подробных объяснений?
Тест: T5-11B (картинка/подпись) против T5-11B (только подпись).
Ответ: Да.
По сравнению с той же моделью, обученной без доступа к информации об изображении, модель с информацией об изображении выигрывает в 84.7% случаев.
Вопрос №2: Является ли компьютерное зрение узким местом для создания высококачественных объяснений?
Тест: T5-11B (FD) против OFA→T5-11B.
Ответ: Да.
По сравнению с той же моделью, обученной с доступом к письменным описаниям человека (т. е. с настройкой FD), модель, обученная с доступом только к OFA прогнозам, проигрывает в 74.6% случаев.
Вопрос №3: Дают ли более крупные модели T5 лучшие объяснения?
Тест: T5-11B против T5-Large.
Ответ: Да.
T5-11B с доступом к той же информации во время тестирования, что и T5-Large, лучше в 68.5% случаев.
Вопрос №4: Помогает ли точная настройка модели LLM по сравнению с контекстным обучением для генерации объяснений?
Тест: FT-GPT3 против GPT3 (в контексте).
Ответ: Не совсем.
В отличие от задач с множественным выбором, генерация контекстных объяснений сравнима с точной настройкой в соответствии с парными человеческими оценками. Точно настроенная модель более точно отражает стиль пула данных, но контекстные объяснения также содержат аналогичное содержание, например, релевантные сущности.
Вопрос №5: Помогают ли объяснения под наблюдением даже с GPT-4?
Тест: FSL GPT-4 и ZSL GPT-4.
Ответ: Да.
В ZSL версии GPT-4 отсутствует доступ не только к парным (подпись, объяснение) данных, но и к подробным объяснениям, созданным людьми. В результате FSL GPT-4 лучше в 64% случаев.
Вопрос №6: GPT-4 превосходит GPT-3?
Тест: FSL GPT-4 против FSL GPT-3.
Ответ: Да, безусловно.
В окончательном результате, при одинаковом количестве наблюдений, объяснения GPT-4 предпочтительнее почти повсеместно — в частности, в 93% случаев. Интересно, что GPT-3 немного лучше работает с метриками автоматической оценки для объяснения, как BLEU-4 и Rouge-L. Это предполагает, что более раннее семейство моделей может более эффективно соответствовать поверхностным особенностям задачи генерации.
Вопрос №7: Лучшая по результатам модель (GPT-4) объясняет шутки так же хорошо как и человек?
Тест: Человек против FSL GPT-4.
Ответ: нет.
Аннотаторы предпочитали написанные человеком пояснения в 68% случаев.
Крайне часто объяснения GPT-4 неправильно интерпретируют изображение. Например, в одном случае подпись говорит о двух пещерных людях в норе, смотрящих на пещерного человека в пещере с текстом «Лично я не большой поклонник современной архитектуры». GPT-4 предположил, что «современная архитектура» относится к норе, а не к пещере.
Но были и случаи, когда люди единогласно называли ответы модели самыми подходящими. Иногда это было связано с тем, что объяснение человека было неточным, хоть и правильным. Иногда объяснения человека и модели передавали одну и ту же суть, но разными словами.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых.
Эпилог
В рассмотренном нами сегодня труде ученые провели любопытный тест, результат которого должен был показать, способна ли машина понимать юмор. В качестве базы использовались карикатуры, публикуемые в журнале The New Yorker, и подписи к ним, которые создавались читателями в рамках конкурса.
Короткий и вполне ожидаемый ответ на главный вопрос исследования — нет, современные модели визуального и текстового распознавания не способны объяснить, а потому и понять юмор той или иной шутки.
Однако, как считают авторы труда, те ограниченные возможности, которыми обладают современные модели ИИ, нельзя называть мизерными. Их может быть вполне достаточно для того, чтобы они служили в качестве творческих сотрудников, например, в качестве помощников в процессе создания и обдумывания идей для юмористов или мультипликаторов. Во-первых, модели оценки соответствия изображений и подписей могут давать некое представление о том, насколько точным это соответствие посчитают люди. Другими словами, своеобразная тестовая аудитория, как перед показом фильма, но только вместо людей используется ИИ.
Конечно, ИИ еще далеко до человека в аспектах понимания чего-либо. Даже чат GPT-4, несмотря на весь хайп вокруг него, является всего лишь очень большой библиотекой данных, которая старается выдавать вам ответ, который максимально подходит под ваш вопрос. Любой вопрос, касающийся порабощения роботами человечества, смерти или других высоких материй — для любого ИИ является не более философским, чем вопрос «сколько будет 2+2?». Ибо ответ на него будет исходить не из личного мнения или каких-то размышлений, а все из той же базы знаний. Потому боятся восстания машин пока еще рано.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?


