")
Привет! Чем еще заняться на каникулах любителю Data Scienсe как не анализом тональности комментариев под новогодними обращениями?! На эту мысль меня натолкнули алгоритмы YouTube, выдавшие к просмотру первого января 2022 года два видео, с очень разными по эмоциональной окраске комментариями.
Тогда я подумал, что пошаговый разбор решения задачи классификации этих комментариев по их тональности мог бы стать довольно наглядным примером для знакомства с базовыми техниками обработки естественного языка, а о том, насколько это получилось предлагаю судить вам.
Итак, в процессе классификации наших комментов мы поучимся :
-
Писать парсер комментариев YouTube
-
Предобрабатывать тексты для их последующего анализа
-
Получать частотность слов в наборах текстов
-
Создавать красивые графики «облака тэгов»
-
Находить размеченные наборы текстов и оценивать их пригодность для задачи
-
Получать векторные представления текстов bag of words и TF-IDF
-
Классифицировать комментарии с помощью логистической регрессии
-
Оценивать качество классификации с помощью графиков ROC-кривых и матрицы ошибок
-
Визуализировать наиболее важные для классификации слова
-
Применять полученный классификатор для анализа тональности комментариев
A для работы нам понадобится только: компьютер, доступ в интернет, настроенная среда Jupyter Notebook и пару вечеров свободного времени.
Все материалы и код используемые в этой статье я выложил в github, a для тех, кому удобнее смотреть чем читать, записал видео-туториал c разбором кода на своем канале:
Парсинг комментариев
Для парсинга комментариев воспользуемся python библиотекой Selenium которая с помощью модуля WebDriver позволяет автоматизировать действия в браузере предоставляя для их реализации API. Для того чтобы парсить комментарии с видео в YouTube c помощью API WebDriver необходимо дополнительно скачать драйвер для того браузера в котором вы хотели бы производить действия, в нашем случае это ChromeDriver, кратко разберем код парсера, который я подсмотрел тут
# Импортируем webdriver
from selenium import webdriver
# Импортируем визуализатор счетчика итераций
from tqdm import tqdm
# Создаем список для результатов парсинга
scrapped = []
# Инициализируем наш экземпляр webdriver
with webdriver.Chrome(executable_path =
# указываем путь к .exe файлу драйвера Google Chrome
'/path_chrome_driver/chromedriver.exe'
) as driver:
# Указываем время ожидания в секундах и URL видео
wait = webdriver.support.ui.WebDriverWait(driver,1)
driver.get("https://www.youtube.com/watch?v=wCycCRk_Eak")
# Задаем количество прокруток для загрузки комментариев
# для сбора более чем 3300 комментариев мне было достаточно
# 200 итераций
for item in tqdm(range(200)):
wait.until(webdriver.support.expected_conditions
.visibility_of_element_located(
(By.TAG_NAME, "body")))
.send_keys(webdriver.common.keys.Keys.END)
# Указываем время ожидания в секундах после каждой прокрутки
time.sleep(2)
# Получаем комментарии по тэгу "#content"
for comment in wait.until(webdriver.support.expected_conditions
.presence_of_all_elements_located(
(By.CSS_SELECTOR, "#content"))):
# Добавляем тексты комментариев в список
scrapped.append(comment.text)Если вы все сделаете правильно, то после запуска кода у вас откроется окошко с браузером и начнет смотреть видео прокручивая и собирая комментарии.
Предобработка текстов комментариев и визуализация частотности слов
Любые исходные данные это руда которую нужно обрабатывать и после того как мы получили комментарии их также необходимо очистить чтобы с ними можно было работать дальше. Оставим в наших текстах только кириллические символы, приведем все к нижнему регистру, и удалим различные предлоги и местоимения, которые не очень полезны для нашей задачи. Это нам нужно для упрощения сравнения текстов одинаковые слова написанные разным регистром будут для нас одинаковы, «100 поцелуев» и «100500 поцелуев» также не будут отличаться. Напишем для предобработки пару функций
# Расчехляем регулярки, кудаже без них :)
iport re
# Оставим в тексте только кириллические символы
def clear_text(text: str) -> str:
"""
Функция получает на вход строчку текста
Удаляет с помощью регулярного выражения
все не кириллические символы и приводит
слова к нижнему регистру
Возвращает обработанную строчку
"""
# Пишем регулярное выражение которое заменяет на ' '
# все, что не входит в кириллический алфавит
clear_text = re.sub(r'[^А-яЁё]+', ' ', text).lower()
return ' '.join(clear_text.split())
# напишем функцию удаляющую стоп-слова
def clean_stop_words(text : str,
stopwords : list):
"""
Функция получает:
* text -- строчку текста
* stopwords -- список стоп слов для исключения
из текста
Возвращает строчку текста с исключенными стоп словами
"""
text = [word for word in text.split() if word not in stopwords]
return " ".join(text)Выведем пару примеров обработки текстов:
# Протестируем работу функции очистки текста
for _ in range(3):
text = comments_shulman_df.sample(n = 1)['comment'].values[0][:70]
print(text)
print('=======================================')
print(clean_stop_words((clear_text(text)), stopwords))
print()
>>>
Спасибо️
=======================================
спасибо
С Новым годом! Именно такие слова и такое пожелание я хотела услышать!
=======================================
новым годом именно такие слова такое пожелание хотела услышать
Спасибо, Екатерина Михайловна! Прекрасные слова.
=======================================
спасибо екатерина михайловна прекрасные словаЛемматизация текстов
Лемматизация — приведение всех слов текста к их леммам — изначальным формам:
-
для существительных — именительный падеж, единственное число;
-
для прилагательных — именительный падеж, единственное число, мужской род;
-
для глаголов, причастий, деепричастий — глагол в инфинитиве (неопределённой форме) несовершенного вида.
Лемматизация позволяет еще больше универсализировать наши тексты, привести их так сказать к общему знаменателю, но тут есть и обратная сторона — лишая наши предложения падежей и времен мы теряем достаточно много информации которая может содержать эмоциональную окраску. При решении конкретно этой задачи лемматизация оказала хоть и не значительное но негативное влияние на качество классификации, но возможно в других задачах лемматизация может оказаться полезной.
Давайте напишем функцию для лемматизации, использующую библиотеку от Яндекса pymystem3. У этой библиотеки есть некоторые сложности с параллелизацией запросов, поэтому для ускорения обработки больших массивов приходится несколько исхитрятся и объединять сразу большое количество текстов в батч вставляя перед этим символ разделения затем получая результат лемматизации извлекать его обратно получая исходные тексты. Кстати это решение я подсмотрел тут же, на Хабре.
import numpy as np
import pandas as pd
from pymystem3 import Mystem
from tqdm import tqdm
def lemmatize(df : (pd.Series, pd.DataFrame),
text_column : (None, str),
n_samples : int,
break_str="br",
) -> pd.Series:
"""
Принимает:
df -- таблицу или столбец pandas содержащий тексты,
text_column -- название столбца указываем если передаем таблицу,
n_samples -- количество текстов для объединения,
break_str -- символ разделения, нужен для ускорения,
количество текстов записанное в n_samples объединяется
в одит большой текст с предварительной вставкой символа
записанного в break_str между фрагментами
затем большой текст лемматизируется, после чего разбивается на
фрагменты по символу break_str
Возвращает:
Столбец pd.Series с лемматизированными текстами
в которых все слова приведены к изначальной форме:
* для существительных — именительный падеж, единственное число;
* для прилагательных — именительный падеж, единственное число,
мужской род;
* для глаголов, причастий, деепричастий — глагол в инфинитиве
(неопределённой форме) несовершенного вида.
"""
result = []
m = Mystem()
if df.shape[0] % n_samples == 0 :
n_iterations = df.shape[0] // n_samples
else:
n_iterations = (df.shape[0] // n_samples) + 1
for i in tqdm(range(n_iterations)) :
start = i * n_samples
stop = start + n_samples
sample = break_str.join(df[text_column][start : stop].values)
lemmas = m.lemmatize(sample)
lemm_sample="".join(lemmas).split(break_str)
result += lemm_sample
return pd.Series(result, index = df.index)Выведем несколько результатов работы функции:
поздравление здорового человека
======================================================================
поздравление здоровый человек
здоровья вашей семье спасибо екатерина михайловна новым годом
======================================================================
здоровье ваш семья спасибо екатерина михайловна новый год
новым годом екатерина михайловна благодаря эта настойчивость
======================================================================
новый год екатерина михайловна благодаря этот настойчивостьВизуализация частотности слов. Облако тэгов «Word cloud»
Визуализация данных — это большая часть Data Science и важна не только в качестве презентации результатов, но и в как важный инструмент при анализе данных. Глядя на гистограммы, боксплоты или тепловые карты корреляций можно очень быстро получить представление о том с какими выборками мы имеем дело и какие зависимости могут быть в наших данных, да и просто это как правило очень красиво.
Посмотрим на визуализацию 100 наиболее частотных слов, уникальных для каждого набора наших обработанных наборов комментариев.

Разберем подробнее как получить такой график. Для начала нам нужно пройтись по каждому набору текстов и посчитать частоту встречаемости каждого уникального слова.
Несложно написать соответсвующую функцию, но мы воспользуемся уже готовым классом CountVectorizer из библиотеки scikit-learn:
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
# Для каждого коруса текстов инциализируем свой экземпляр класса
shulman_counter = CountVectorizer(ngram_range=(1, 1))
putin_counter = CountVectorizer(ngram_range=(1, 1))
# Получаем словарь уникальных слов (fit)
# и сразу же считаем частотность для каждого текста (transform)
shulman_count = shulman_counter.fit_transform(comments_shulman_df['text_clear'])
putin_count = putin_counter.fit_transform(comments_putin_df['text_clear'])
shulman_frequence = pd.DataFrame(
# получаем словарь из CountVectorizer
# c помощью .get_feature_names_out()
{'word' : shulman_counter.get_feature_names_out(),
# получаем частотность слов
# находя сумму компонент векторов
'frequency' : np.array(shulman_count.sum(axis = 0))[0]
}).sort_values(by = 'frequency', ascending = False)
putin_frequence = pd.DataFrame(
{'word' : putin_counter.get_feature_names_out(),
'frequency' : np.array(putin_count.sum(axis = 0))[0]
}).sort_values(by = 'frequency', ascending = False)
# Убираем с помощью запроса пересекающиеся слова
# Оставляем 100 наиболее частотных
putin_frequence_filtered = putin_frequence
.query('word not in @shulman_frequence.word')[:100]
shulman_frequence_filtered = shulman_frequence
.query('word not in @putin_frequence.word')[:100]Затем мы обращаемся к функции WordCloud и передаем ей словарь с частотой слов, по которым она генерирует красивые картинки, которые мы в свою очередь выводим на экран с помощью библиотеки matplotlib.pyplot
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Генерируем красивые картинки со словами
# на которых размер шрифта соответствует частотности
wordcloud_shulman = WordCloud(background_color="black",
colormap = 'Blues',
max_words=200,
mask=None,
width=1600,
height=1600)
.generate_from_frequencies(
dict(putin_frequence_filtered.values))
wordcloud_putin = WordCloud(background_color="black",
colormap = 'Oranges',
max_words=200,
mask=None,
width=1600,
height=1600)
.generate_from_frequencies(
dict(shulman_frequence_filtered.values))
# Выводим картинки сгенерированные вордклаудом
# С помощью matplotlib.pyplot
fig, ax = plt.subplots(1, 2, figsize = (20, 12))
ax[0].imshow(wordcloud_shulman, interpolation='bilinear')
ax[1].imshow(wordcloud_putin, interpolation='bilinear')
ax[0].set_title('title_1',
fontsize = 20
)
ax[1].set_title('title_2',
fontsize = 20
)
ax[0].axis("off")
ax[1].axis("off")
plt.show()Классификация комментариев по эмоциональной окраске
Хорошо, мы предобработали и немного поиграли с нашими текстами, теперь можем перейти к решению задачи sentiment analysis. В нашем случае сведем решение этой задачи к задаче бинарной классификации, то есть присвоению каждому комментарию числовой метки в интервале от 0 до 1, где 0 будет соответствовать негативному комментарию, а 1 позитивному. Верхнеуровнево наметим план решения задачи:
-
Поиск похожего набора текстов с размеченными интонациями
-
Проведение обработки текстов размеченного датасета
-
Получение векторных представлений текстов
-
Обучение классификатора на полученных векторах
-
Оценка качества полученного классификатора
-
Классификация комментариев с помощью обученной модели
-
Оценка адекватности полученной классификации
Поиск подходящего датасета для обучения
Это очень важный этап от которого зависит качество всех последующих результатов. При поиске датасета для задачи анализа тональности текстов важно учесть что лексикон — набор специфических слов и устойчивых выражений может сильно зависеть от конкретной площадки.
Например для оценки комментариев нам точно не подойдет корпус текстов новостей, поскольку это довольно сильно отличающиеся тексты, в новостях как правило вы не найдете нецензурных слов, там будет гораздо меньше слов с ошибками и интернет слэнга.
Перебрав в течении часа не слишком большой набор доступных датасетов с русскоязычными текстами я в итоге остановился на наборе состоящем из 114,911 положительных, 111,923 отрицательных постов Twitter сделанных на русском языке за период с конца ноября 2013 года до конца февраля 2014 года, которые были автоматически размечены на два класса positive и negative (ссылка на источник https://study.mokoron.com/). Вот так выглядит набор данных после аналогичной предобработки и объединения всех комментариев в одну таблицу:

Всего в корпусе позитивных комментариев употребляется 100 143 слова, а в корпусе позитивных — 119 363. Посмотрим на 100 наиболее частотных слов специфичных для каждого класса комментариев:

Получение векторных представлений мешок слов и TF-IDF
Чтобы производить обучение классификатора нам для начала необходимо будет преобразовать каждый текст в набор чисел. От способа, которым тексты переводятся в численные вектора очень сильно зависит качество классификации. Один такой способ мы уже рассмотрели — это просто посчитать количество упоминаний в каждом тексте каждого уникального слова. Такие вектора называются мешками слов (bag of words) потому что не учитывают порядок слов.
Еще один способ, не учитывающий порядок слов но более чувствительный к специфичным, редким словам — это вектора TF-IDF. В случае TF-IDF мы также получаем вектор длины равной количеству уникальных слов, но сама оценка строится немного по другому — каждый компонент такого вектора состоит из двух сомножителей:
-
TF — term frequency — частота встречаемости слова в тексте
-
IDF — inverse document frequency — логарифм от обратной частоты встречаемости документов с указанным словом. Например если обычная частота встречаемости документа с указанным словом — это количество документов со словом деленное на количество всех документов, то обратная частота по аналогии с обратной функцией — переворачивает эту дробь и мы получаем количество всех документов разделить на количество документов с нужным словом.
TF-IDF может быть полезен для снижения веса часто встречаемых слов и повышения веса редких слов, которые могут быть важны для классификации текста.
В более сложные способы получения векторного представления с помощью глубоких нейронных сетей мы пока лезть не будем, но надеюсь, что руки дойдут написать статью и про них тоже (подписывайтесь на меня если интересна эта тема).
Классификация с помощью логистической регрессии
Для нашей задачи мы воспользуемся логистической регрессией, давайте кратко рассмотрим как она работает. По сути это линейная регрессия к результату которой в конце применяется логистическая функция.
То есть для каждого компонента вектора (читай для каждого слова из словаря), который мы подаем на вход, логистическая регрессия подбирает некоторое число — вес, таким образом, чтобы после умножения каждого компонента вектора на свой вес и последующего суммирования всех произведений мы бы для каждого текста получали число в интервале от 0 до 1, которое бы говорило нам о том насколько данный текст близок к классу 0 — негативных комментариев или классу 1 — позитивных комментариев.
Первая часть с подбором весов умножением на компоненты векторов и сложением — это линейная регрессия, мы как-бы регрессируем из большого набора чисел в одно число. Логистическая же функция в самом конце масштабирует любое полученное число на интервал от нуля до единицы. И если можно было бы показать только одну-единственную формулу в этой статье, то я бы без раздумий выбрал логистическую функцию, взгляните на эту красавицу:

Где e — число Эйлера равное примерно 2.71828, а основные свойства этой формулы зависят от показателя его степени, то есть с увеличением x, мы будем получать увеличение отрицательной степени у числа e, а значит экспоненциальное стремление знаменателя дроби к единице. С другой стороны, при больших отрицательных значениях аргумента мы будем получать экспоненциальный рост знаменателя к бесконечности и следовательно стремление всей дроби к нулю. График функции при x от -6 до +6 выглядит так:
")
Логистическая регрессия очень удобна для нашей задачи, поскольку позволяет нам не только интерпретировать ответ классификатора, как вероятность принадлежности текста к классу, но также и получать веса признаков, то есть слов из нашего словаря.
Давайте напишем код расчёта векторного представления для комментариев, не забыв предварительно разделить выборку на обучающую и тестовую в пропорции 4 к 1. Ведь если мы начнем считать статистики слов используя полный корпус текстов то не сможем потом проверить, как себя будет вести классификатор встретившись с незнакомыми текстами.
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# предварительно разделим выборку на тестовую и обучающую
train, test = train_test_split(
labeled_tweets,
test_size = 0.2,
stratify = labeled_tweets['label'],
random_state = 12348,
)
# инцициализируем векторайзер и укажем размер n-грамм
counter_idf = TfidfVectorizer(ngram_range=(1,1))
# Получаем словарь и idf только из тренировочного набора данных
count_train = counter_idf.fit_transform(train['text'])
# Применяем обученный векторайзер к тестовому набору данных
count_test = counter_idf.transform(test['text'])
# Инициализируем модель с параметрами по умолчанию
model_lr = LogisticRegression(random_state = 12345,
max_iter = 10000,
n_jobs = -1)
# Подбираем веса для слов с помощь fit на тренировочном наборе данных
model_lr.fit(count_train, train['label'])
# Получаем прогноз модели на тестовом наборе данных
predict_count_proba = model_lr.predict_proba(count_test)Давайте сразу выведем веса наших слов, возьмем 100 слов с наибольшими отрицательными весами и 100 слов с наибольшими положительными весами и нарисуем из них облака тэгов:
# Объединим в таблицу словарь из нашего векторайзера
# и веса для слов из обученной модели
weights = pd.DataFrame({'words': counter_idf.get_feature_names_out(),
'weights': model_lr.coef_.flatten()})
# Создаем копию отсортированную по возрастанию
weights_min = weights.sort_values(by= 'weights')
# И еще одну отсортированную по убыванию
weights_max = weights.sort_values(by= 'weights', ascending = False)Код построения графиков используем тот же:

Оценка качества классификации. Матрица ошибок
Веса слов выглядят довольно правдоподобно, теперь давайте численно оценим качество полученного классификатора. Есть довольно много метрик классификации, в числе которых accuracy, precision, recall, F1, но в большинстве случаев вам достаточно понимать как устроена матрица ошибок (confusion matrix), поскольку все перечисленные метрики вычисляются из неё.
Посмотрим на матрицу ошибок нашего классификатора:
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(test['label'],
# В качестве порогового значения вероятности
# ниже которого объекты будут принадлежать
# к классу негативных выберем 0.5
(predict_lr_base_proba_1[:, 0] < 0.5).astype('int'),
normalize="true",
)
matrix
>>>
array([[0.70199178, 0.29800822],
[0.2416975 , 0.7583025 ]])Вкратце о том, с чем едят матрицу ошибок. Так как мы разделяли объекты на два класса в нашей матрице будет 2 строки и 2 столбца. Главное что нужно запомнить — строчки это истинные классы объектов, столбцы — это то, как наша модель назначила этим объектам классы.
По главной диагонали (от верхнего левого числа к нижнему правому) в матрице ошибок отображаются доли верно классифицированных объектов каждого класса. В каждой строчке по соседству с долей верно классифицированных комментариев находится доля объектов данного класса, которую классификатор ошибочно записал в другой класс. Нарисуем красивый график матрицы ошибок:

Например если у нас было 1000 негативных комментариев и 1000 положительных комментариев то поскольку мы видим что в первой строчке стоят числа 0.702, 0.298, это значит из нашей тысячи негативных комментариев 702 были распознаны верно, но при этом 298 были ошибочно классифицированы как позитивные, а во второй строчке мы видим по соседству числа 0.242 , 0.758, значит что из 1000 позитивных комментариев мы ошибочно признали негативными 242.
Построение графиков ROC-кривых
Но мы же помним, что логистическая регрессия выдает в качестве ответа число в интервале от 0 до 1 и мы можем сами определять ту границу после которой мы считаем прогноз негативным. По умолчанию если мы выведем прогноз модели с помощью метода predict() эта граница устанавливается равной 0.5, но мы можем вывести сырой прогноз с помощью predict_proba() как мы и сделали и теперь например мы можем сказать — окей пусть все тексты для которых ответ меньше 0.7 — считаются положительными. Это может позволить увеличить охват верно классифицированных положительных текстов, но если классификатор обучился не достаточно хорошо, то это также увеличит и количество негативных текстов которые будут ошибочно классифицированы как положительные, то есть возрастет количество ложных срабатываний. И на переборе различных значений граничных значений основана еще одна очень наглядная техника оценки классификатора — построение графика ROC кривой (Receiver Operating Characteristic).
Вот, например как выглядят ROC кривые для наших классификаторов, обученных на разных векторных представлениях: bag of words, TF-IDF и на TF-IDF на лемматизированных текстах:

Давайте заодно разберем как понимать график ROC-кривой. Если наш классификатор обучился очень хорошо его ответы будут очень близки единице для большинства положительных негативных текстов и очень близки к нулю для большинства позитивных текстов. Например прогнозы для 90% отрицательных текстов будут находится в интервале ответов от 0 до 0.3, и 90% положительных текстов в интервале от 0.7 до 1.
Тогда сдвиг границы в интервале от 0.3 до 0.7 не будет особо менять долю ложно классифицированных объектов, а доля верно классифицированных объектов будет близка к единице. На графике мы будем видеть резкий подъем к высоким значениям по оси Y при низких значения по оси X.
И чем более не уверенный классификатор мы получим, тем при увеличении порогового значения, будет более равномерно увеличиваться и доля ложно классифицированных объектов. У самого плохого классификатора, который в качестве прогноза будет выдавать случайное число, при сдвиге границы будет происходить симметричный рост ложно классифицированных объектов. На графике мы будем видеть линию которая близка к диагонали, как на графике выше у пунктирной линии «Coin» по аналогии с прогнозом при подбрасывании монетки.
Чтобы не разглядывать форму кривой можно просто замерять площадь под ней, рандомный классификатор всегда будет иметь площадь около 0.5, отличных классификаторов эта площадь будет 0.9 и выше, у нашего лучшего варианта — чуть не дотягивает до 0.81.
Как видим из графика выше у нашей классификации качество довольно среднее. И это так же можно видеть на гистограмме распределения текстов каждого из классов по прогнозу классификатора:
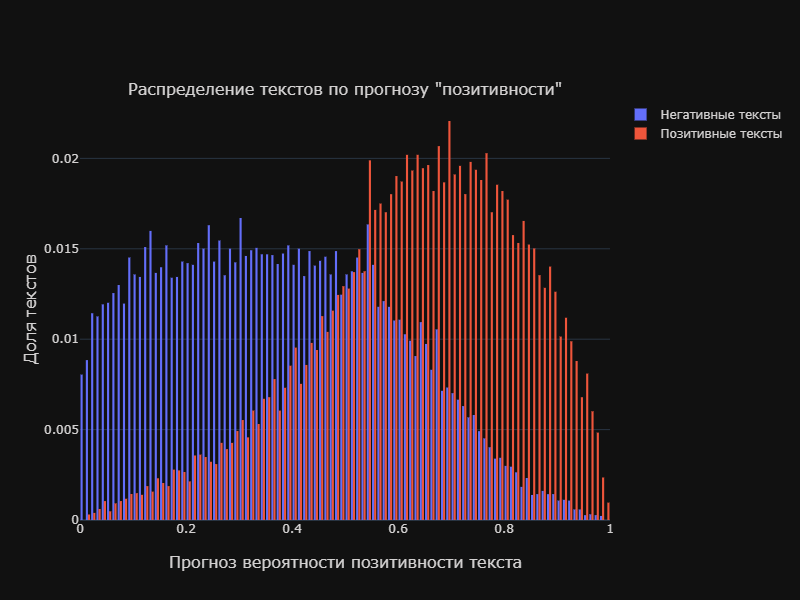
Подбор оптимального порогового значения
Пересечение классов у нашего классификатора, как мы видим на графике выше довольно большое и как не выбирай границу по оси x, мы всгеда будем захватывать довольно много объектов другого класса. Но мы можем несколько про оптимизировать границу, максимизируя общее количество верно классифицированных объектов. Или если этого требует бизнес-задача, несколько сместить акцент на один из классов поступившись охватом другого класса.
Например мы можем поставить задачу верно классифицировать не менее 75% негативных комментариев. Тогда пройдемся по всем значениям от 0.01 до 0.99 и запишем в таблицу долю верно классифицированных положительны и отрицательных объектов а также общую сумму соответствующие каждому пороговому значению, а затем выведем только те значения порогов в которых доля классифицированных негативных текстов не меньше 0,75 и отсортируем по убыванию общей суммы true positive rate + true negative rate, также сравним полученное пороговое значение с оптимальным, то есть дающим наибольшее значение true positive + true negative

В целом мы видим, что наша задача выполняется ценой не слишком большой потери в качестве, порядка десятых долей процента.
Классификация не размеченных комментариев
Теперь когда наша модель обучена и оценено её качество, давайте посмотрим как она справляется с боевой задачей классификации собранных комментариев. Сначала самостоятельно оценим, на сколько адекватно работает модель, будем выводить по 5 случайных комментов, переводить их в вектора с помощью обученного векторайзера и подавать числа в обученную модель, получая вероятность негатива:
# Выведем 5 случайных комментариев c оценкой негатива первого видео
for _ in range(5):
source = comments_putin_df.sample(n=1)
text_clear = source['text_clear'].values[0]
text = source['comment'].values[0]
print(text[:100])
tf_idf_text = count_idf_1.transform([text_clear])
toxic_proba = model_lr_base_1.predict_proba(tf_idf_text)
print('Вероятность негатива: ', toxic_proba[:, 0])
print()Результат будет выглядеть так:

И для второго видео:

Мы видим, что работа классификатора далека от идеала, но в среднем, похоже что основные интонации он улавливает. Получим вероятность негатива для всех комментариев из первого и второго видео и отобразим распределение комментариев каждого видео по полученным оценкам в виде сглаженных гистограмм или т.н. скрипичных диограмм (violin plots)
# Получим вектора tf-idf
putin_tf_idf = counter_tf_idf.transform(comments_putin_df['text_clear'])
shulman_tf_idf = counter_tf_idf.transform(comments_shulman_df['text_clear'])
# Получим прогноз негативности комментария
putin_negative_proba = model_lr.predict_proba(putin_tf_idf)
shulman_negative_proba = model_lr.predict_proba(shulman_tf_idf)
# Добавим прогнозы в таблицу
comments_putin_df['negative_proba'] = putin_negative_proba[:, 0]
comments_shulman_df['negative_proba'] = shulman_negative_proba[:, 0]
# Посчитаем доли негативных комментариев при подобранном пороговом значении
putin_share_neg = (comments_putin_df['negative_proba'] > 0.45).sum()
/ comments_putin_df.shape[0]
shulman_share_neg = (comments_shulman_df['negative_proba'] > 0.45).sum()
/ comments_shulman_df.shape[0]
# Отобразим полученные данные в виде графиков скрипичных диаграмм
fig = make_subplots(1,1,
subplot_titles=
['Распределение комментариев по оценке негативности']
)
fig.add_trace(go.Violin(
x = comments_shulman_df['negative_proba'],
meanline_visible = True,
name="Shulman (N = %i)" % comments_shulman_df.shape[0],
side="positive",
spanmode="hard"
))
fig.add_trace(go.Violin(
x = comments_putin_df['negative_proba'],
meanline_visible = True,
name="Putin (N = %i)" % comments_putin_df.shape[0],
side="positive",
spanmode="hard"
))
fig.add_annotation(x=0.8, y=1.5,
text = "%0.2f — доля негативных комментариев (при p > 0.45)"
% putin_share_neg,
showarrow=False,
yshift=10)
fig.add_annotation(x=0.8, y=0.5,
text = "%0.2f — доля негативных комментариев (при p > 0.45)"
% shulman_share_neg,
showarrow=False,
yshift=10)
fig.update_traces(orientation='h',
width = 1.5,
points = False
)
fig.update_layout(height = 500,
xaxis_zeroline=False,
template="plotly_dark",
font_color="rgba(212, 210, 210, 1)",
legend=dict(
y=0.9,
x=-0.1,
yanchor="top",
),
)
fig.update_yaxes(visible = False)
fig.show()Результат:

На графике выше мы можем видеть сравнение распределений комментариев под двумя видео. Пунктирной линией выделено медианное значение, то есть такое значение правее и левее которого находится одинаковое количество текстов. Для комментариев под видео с участием Владимира Путина полученное медианное значение оценки негативности составило 0.45, а для видео с Екатериной Шульман — 0.34, можно сказать что общая оцененная вероятность негатива в комментариях под первым видео значительно выше чем под вторым, что в целом соответствует общему изначальному ожиданию которое сформировалось после прочтения нескольких сотен случайно выбранных комментариев.
Наметим стратегию улучшения классификатора.
-
Парсим много много-много комментариев порядка сотен тысяч.
-
С помощью обученного классификатора оцениваем негативность и позитивность не размеченных комментариев, и забираем из выборки только те комментарии, в которых классификатор очень уверен, например, с оценками больше 0.8 или меньше 0.2
-
Добавляем наиболее уверенно классифицрованные тексты в копрус размеченных текстов, снова получаем по ним вектора tf-idf и обучаем модель
-
Убираем наиболее уверенно классифицированные тексты из не размеченной выборки
-
Возвращаемся на шаг № 2
Итоги
Чему мы научились и узнали:
-
Парсить тексты комментариев из YouTube и собирать из них базы данных
-
Предобрабатывать тексты и получать их векторные представления tf-idf и bag of words
-
Классифицировать тексты с помощью логистической регрессии и оценивать качество классификации с помощью confusion matrix и ROC-curve
-
Строить красивые графики облаков слов и скрипичных диаграмм
Надеюсь, что этот data-sci-pop туториал был вам полезен и вы узнали что-то новое для себя, буду рад если подпишитесь на меня тут или на мой канал на YouTube : https://www.youtube.com/c/ivanovnikitok , там планирую и дальше делать разборы решений задач из различных областей DataSciense и стараться, чтобы это было не скучно. Всем желаю максимизации счастья и минимизации страданий!


