Всем привет,
В данной статье я расскажу о реверс-инжиниринге ресурсов игры Twisted Metal 4 для первой Playstation. В качестве основного инструмента я буду использовать Ghidra.
Наверняка вы слышали об игровой серии Twisted Metal. А кому-то, наверное, довелось и поиграть (мне нет). По словам тех, кто играл в четвёртую часть, в игре имеются некоторые неприятные баги. Так вот, реверс-инжиниринг должен помочь исправить их. Поехали…
Игровые форматы
Как обычно, разбор игры для первой плойки начинается с анализа основного исполняемого файла, в данном случае — SCUS_945.60. После непродолжительного осмотра данного файла, я пришёл к выводу, что в нём, фактически, большей части кода-то и нет. Значит, всё упрятано куда-то ещё.
На диске, кроме основного исполняемого файла, обнаружились следующие форматы: IMG, MR, STR, TIM. Два последних являются стандартными для PSX, и представляют из себя видео-стримы и изображения соответственно. А вот на первые два надо бы взглянуть. Открываем в hex-редакторе первый попавшийся файл и видим:
 в Ghidra. Часть 1")
Судя по «плотности» байт, файл чем-то упакован. Значит, нужно понять, где и как происходит распаковка.
Загрузка SCUS_945.60 в Ghidra
Для работы с исполняемыми файлами Sony Playstation 1 в Ghidra имеется загрузчик, я писал о нём здесь. Устанавливаем его, открываем Гидру, создаём новый проект и закидываем в него файл SCUS_945.60 из корня диска с игрой.

Узнаём, что при разработке игры использовался PsyQ 4.5.

Дожидаемся завершения анализа файла, и переходим в автоматически определившуюся функцию main().

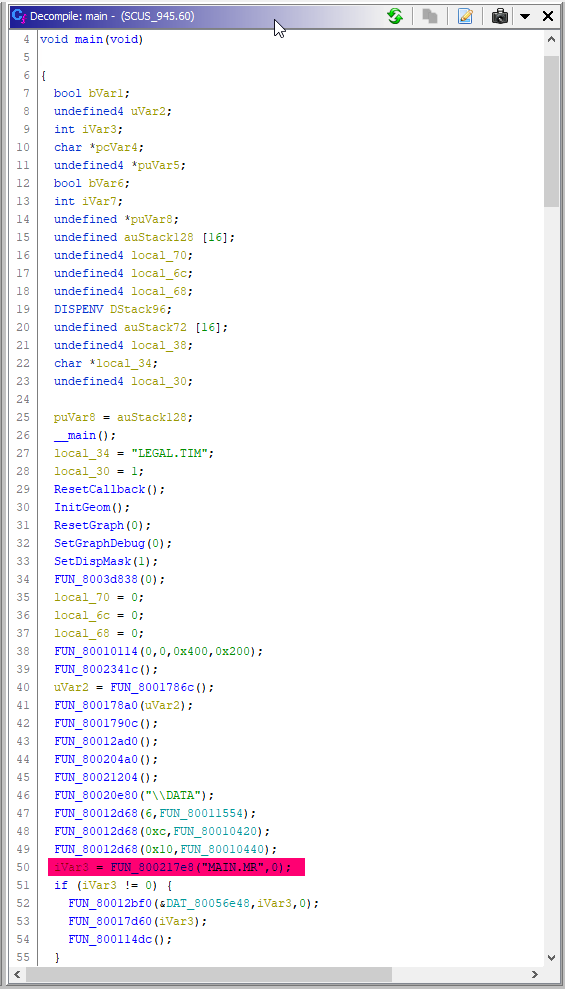
Я выделил на скриншоте функцию, которая бросается в глаза — похоже, она имеет какое-то отношение к разбору MR-файлов. Посмотрим, что она делает.
FUN_800217e8
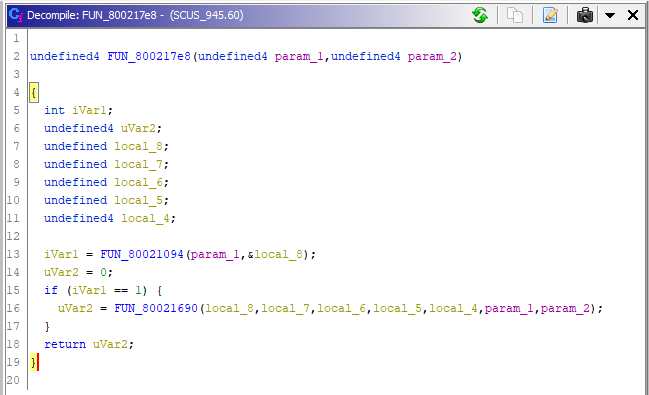
В вызове этой функции в main() мы видели, что первым аргументом туда приходит имя файла, поэтому меняем тип первого аргумента на соответствующий — char * (у Гидры понятий const, не const нет), и переименовываем в mr_name.
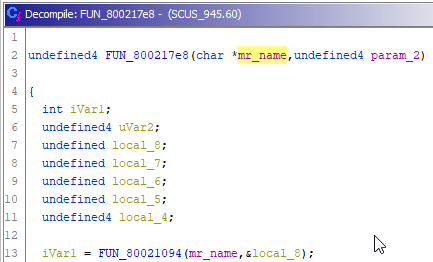
Далее видим, что имя файла передаётся в следующую функцию:
iVar1 = FUN_80021094(mr_name,&local_8);Зайдём в неё:
FUN_80021094
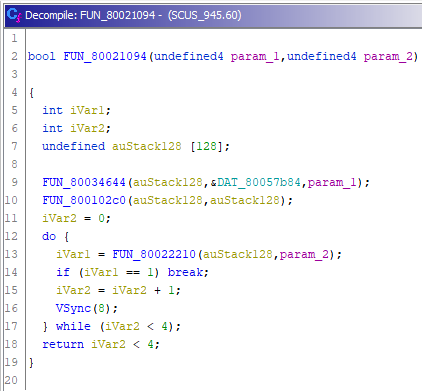
Здесь так же переименовываем и меняем тип аргумента. Первой же строчкой в этой функции видим использование какой-то переменной.
FUN_80034644(auStack128,&DAT_80057b84,mr_name);Взглянув на неё, понимаем, что это константная строка.

Чтобы заставить Гидру определить эту строку как константу, нужно сначала обозначить её как строку (T->string).
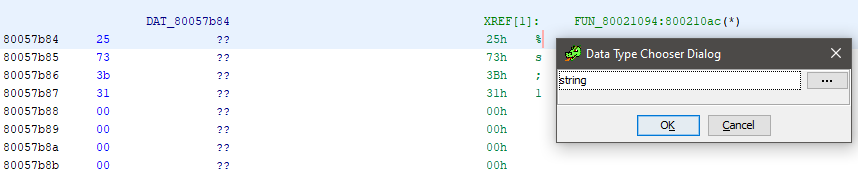

Отлично, теперь мы видим, что это форматная строка, и она передаётся в какую-то функцию вторым аргументом. А это значит, что данная функция, скорее всего, sprintf(). Так её и переименуем.
sprintf(auStack128,"%s;1",mr_name);Далее идёт вызов другой функции, в которую передаётся результат вызова sprintf().
FUN_800102c0(auStack128,auStack128);Заходим в функцию, и видим, что она каждый символ переданной строки делаем прописным, вызывая toupper().

Переименовываем функцию в string_uppercase().
Следующая функция — FUN_80022210. Посмотрим, что она делает.
FUN_80022210
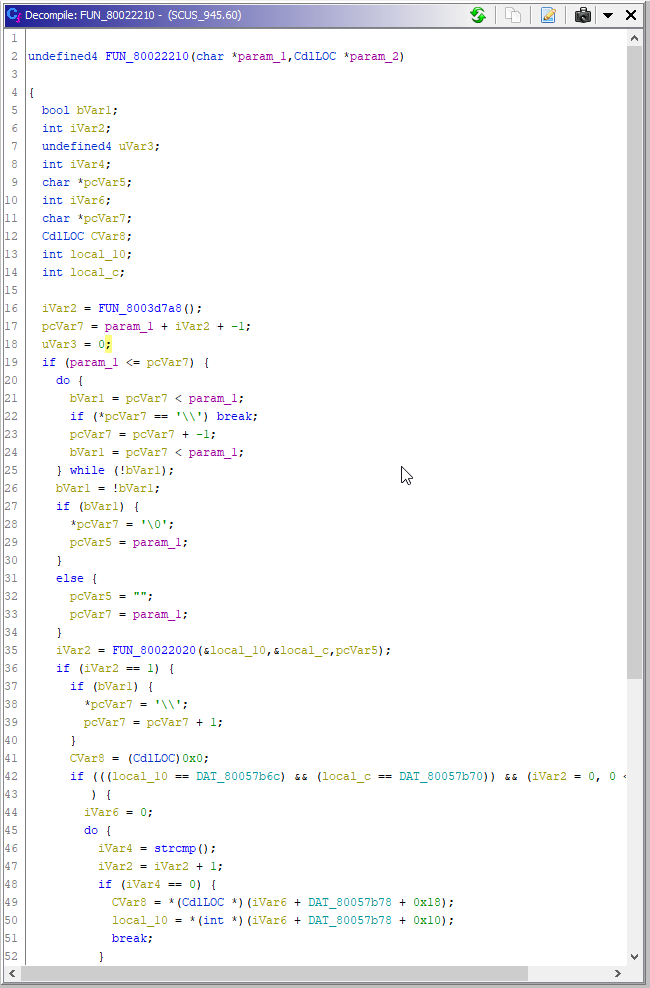
Судя по её второму аргументу — CdlLOC*, определяет местоположение файла на диске. Так её и назовём — get_file_location().
undefined4 get_file_location(char *param_1,CdlLOC *param_2)Тип
CdlLOCопределён в PsyQ и хранит часы, минуты, секунды позиции файла на диске.
Теперь, чтобы типы аргументов функции get_file_location() применились в тех местах, где она функция вызывается, необходимо нажать клавишу P (Commit Params/Return) в C++-листинге.
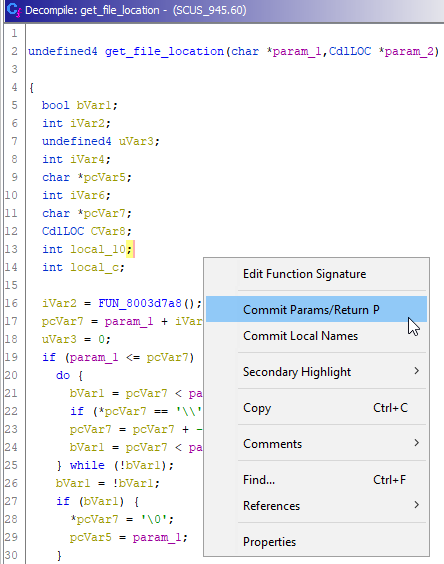
Возвращаемся на уровень выше:
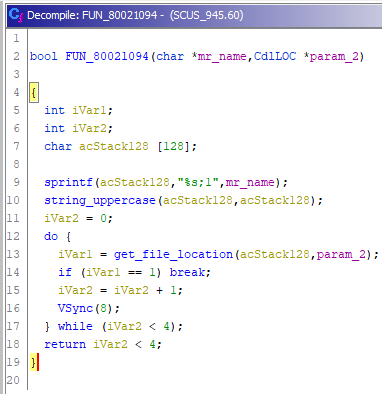
Приходим к выводу, что функция FUN_80021094 всего лишь определяет, где располагается файл на диске. Переименовываем в get_file_offset(), применяем типы аргументов (клавиша P) и возвращаемся к функции выше — к FUN_800217e8.
FUN_800217e8
Теперь данная функция выглядит следующим образом.

Видим вызов функции FUN_80021690, в которую передаются «координаты» файла, его имя, и второй аргумент функции. Зайдём и посмотрим.
FUN_80021690

Тут, вроде как всё просто и интуитивно, если учитывать, что мы имеем дело с координатами файла, его позицией и т.п. Делаю предположение, что первая вызываемая функция — FUN_80017cf8 — выделяет память под содержимое файла, которое будет прочитано далее. А вторая — собственно чтение. Для проверки я заглянул в первую функцию, и ужаснулся — значит, это точно выделение памяти! Посмотрим на вторую.

Да, очень похоже на чтение с диска. Переименовываем её в read_data_by_pos(). Поднимаемся выше, и переименовываем функцию FUN_80021690 в read_file_with_alloc(). Не забываем нажимать P для применения параметров.
FUN_800217e8
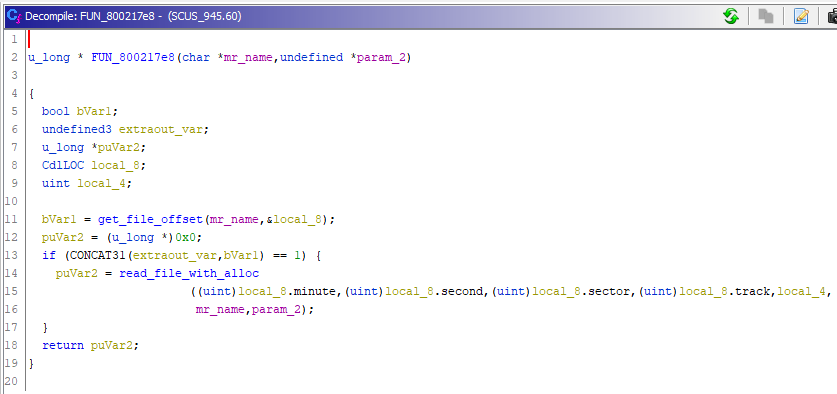
Возвращаясь снова к этой функции, можно смело назвать её read_file(), и определить второй аргумент функции, как offset, с которого начинается чтение файла, ибо указатель на выделенную память занят за результатом функции, который она возвращает через return.
main
И вот, мы снова вернулись в главную функцию, имея указатель на прочитанные из файла MAIN.MR данные.

Видим, что функция FUN_80012bf0 принимает этот указатель вторым аргументом. А первым снова идёт какая-то переменная (или константа). Уже имея в этом опыт, выясняем, что это — строка «/«. Давайте теперь посмотрим, что же делает FUN_80012bf0.
FUN_80012bf0

Ясности первый осмотр функции, в то что она делает, не внёс. Зайдём в FUN_800128cc, которая, судя по листингу, не принимает аргументов и разберём её.
FUN_800128cc

Аргументы у этой функции всё таки есть. Нажмём P. Видим что имеется вызов strcpy, но, почему-то с нераспознанными аргументами, исправим:

Зайдём в первую вызываемую функцию, куда передаётся первый аргумент, имеющий теперь тип char *:
iVar1 = FUN_80012a24(param_1);FUN_80012a24
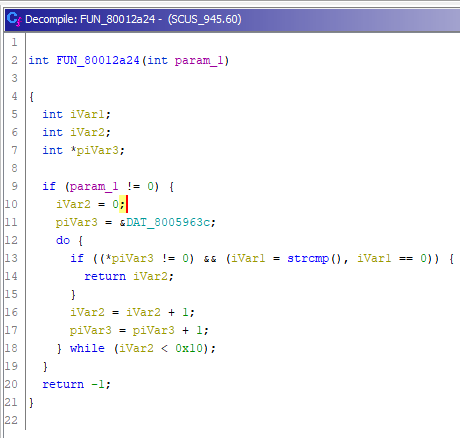
Снова библиотечная функция, но на этот раз — strcmp(), добавим ей аргументы.

Становится понятно, что мы имеем дело со списком строк (DAT_8005963c), и их 16 штук (судя по условиям цикла). Исправим тип для указанного адреса на char*[16]. Для этого сначала перейдём по адресу 0x8005963C, зададим тип char* для первого указателя (через T), а затем нажмём клавишу [, чтобы создать массив.
![]()
Теперь функцию FUN_80012a24 можно переименовывать в find_prev_string_index(). Возвращаемся назад.
FUN_800128cc
Теперь мы видим довольно интересный кусок кода. Опытный глаз сразу определяет подсчёт длины strlen(), и выделение памяти под новую строку (ещё один malloc()?).

Но давайте проверим. Заходим в первую вызываемую функцию — FUN_8003d7a8:

Тут так и написано: «Possible STRLEN.OBJ/strlen«. Почему же анализатор автоматически не применил сигнатуру, спросите вы? Варианта может быть два:
- Ранее нашлась совпадающая по сигнатуре функция
- Энтропия сигнатуры не превысила минимально допустимой, заданной в настройках (минимум
3.0)
Ну а вторая функция (FUN_80017cd8) оказалось такой же объёмной внутри, как и ранее найденный malloc(), поэтому смело называем данную функцию malloc2().
Итого, вся функция FUN_800128cc — это что-то типа strdup() с кэшированием. Переименовываем, и возвращаемся наверх.
FUN_80012bf0

Теперь начинается что-то интересное. Смотрим первый вызов:
iVar2 = FUN_80012148(DAT_80056f38,rel_path);
Выглядит объёмно, но пока не очень сложно. Замечаем, что вызов strncpy() имеет больше аргументов, чем нужно. Но, почему-то в этой версии Ghidra (9.2) переопределить параметры мне не удалось.
Видим ещё один вызов функции:
param_1 = FUN_800120d8(param_1,pcVar5);Заглянем и туда:
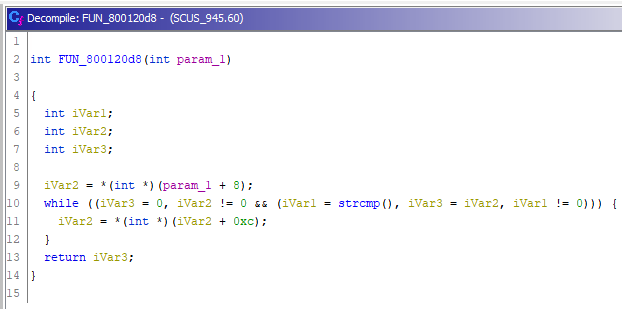
Видим снова вызов strcmp() без параметров, исправляем (почему-то старое переопределение здесь не подтянулось).
Отлично, у нас вырисовывается первое использование каких-то структур данных (видим использование смещений относительно указателей):
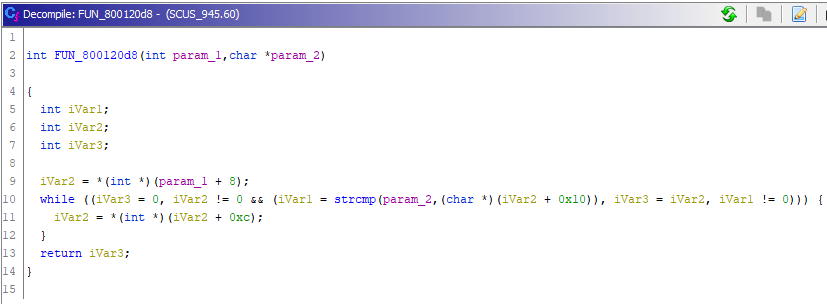
У Ghidra на эту тему есть готовая фича: Auto Create Structure (Shift+[). Жмём на таком указателе указанную комбинацию и получаем автоматически созданную структуру, которую останется только переименовать. Таких указателей у нас два: param_1 и iVar2.

Здесь мы имеем дело с односвязным списком: в field_0x8 первой структуры хранится указатель на список, в field_0xc второй структуры — следующий его элемент. Данные элемента хранятся в поле field_0x10. Переименуем всё соответствующим образом. Пока не понятно, это две разных структуры, или одна, но мы всегда сможем всё объединить.
Вспоминаем, что мы зашли в эту функцию, чтобы понять что она делает, и понимаем, что здесь происходит поиск строки из аргумента param_2 в списке из аргумента param_1. Переименуем функцию в get_item_by_string().
Поднимаемся в место вызова этой функции, и видим следующую картину:

Вспоминаем, что get_item_by_string() возвращает указатель на элемент списка, сопоставляем с фактом, что результат функции записывается в param_1, и приходим к выводу, что те две структуры на самом деле являлись одной. Правим astruct_1 следующим образом:
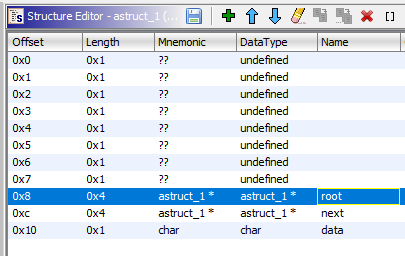
Теперь можно разобраться вот с этим куском кода:

Судя по всему, в этих двух указателях хранятся два разных списка типа astruct_1, поэтому поменяем их типы на правильные и переменуем в str_list1 и str_list2.
Остаётся эта непонятная куча кода со стековыми указателями, но с ней мне разобраться не удалось, т.к. у Гидры в целом плохо со строковыми переменными на стеке. Всё равно это не мешает понять, что делает функция FUN_80012148 — она ищет путь к файлу в списке и, если таковой имеется, возвращает указатель на элемент списка, иначе — NULL. Переименуем в get_item_by_full_path().
FUN_80012bf0
Снова поднимаемся наверх, и смотрим, что теперь представляет из себя функция FUN_80012bf0:

Судя по всему, мы добрались до разборщика MR-формата, т.к. у нас читается первый short (mr_mem пока имеет тип short*), а дальше в функцию FUN_80011f0c передаётся на идущие следом данные:
if (*mr_mem == 0x67) {
FUN_80011f0c(paVar2,mr_mem + 2,iVar1);
uVar3 = 1;
}Самое время создать для mr_mem новую структуру (через Auto Create Structure) и перейти к разбору FUN_80011f0c.
FUN_80011f0c

Я немного переименовал входные аргументы, чтобы было понятнее, остаётся разобраться, что здесь делается.
Во первых, здесь осуществляется проход по структуре mr_sub_data (это та, которая начинается со смещения +0x04 — не +0x02 потому что short* — от начала mr_mem, т.е. от начала MR-файла). Во вторых, да, mr_sub_data это структура, поэтому давайте её создадим. Почему-то, в этот раз Ghidra с автоматическим созданием не справилась, создав слишком короткую структуру, поэтому сделаем это вручную (просто добавляем по байтовому полю, пока не пропадут обращения к указателю со структурой как к массиву):

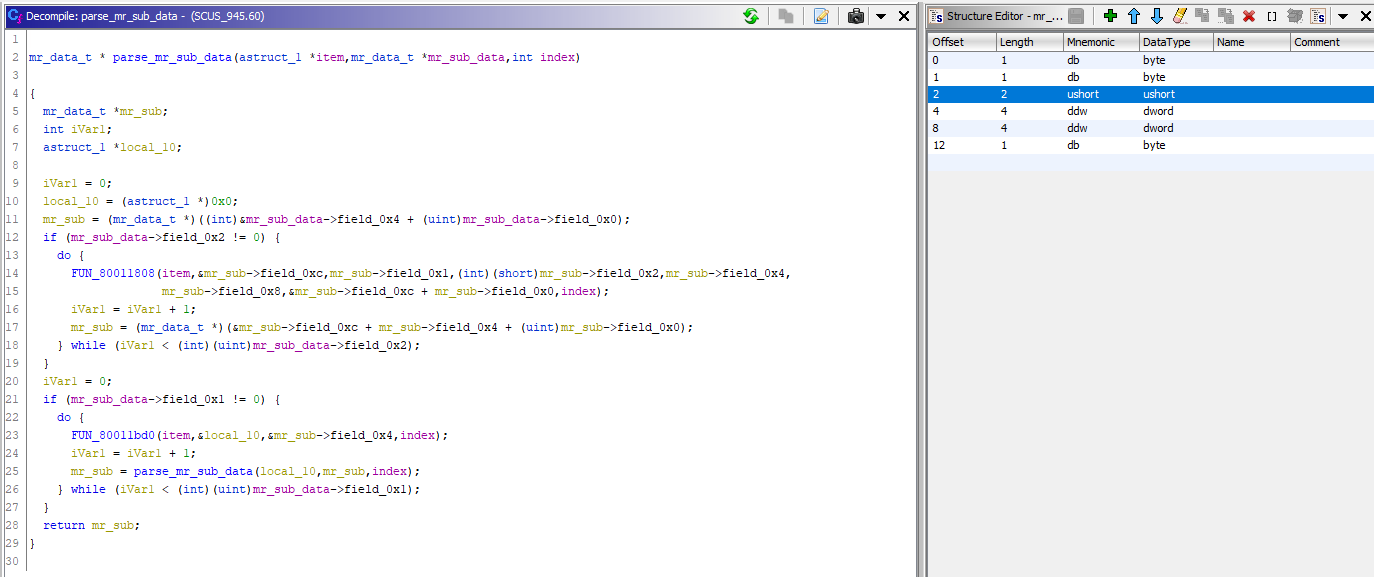
Обратив внимание, что в текущей функции используется рекурсия при вызове FUN_80011f0c, решаем разобраться сразу с тем блоком кода, в котором она имеется, а именно:

FUN_80011bd0
В блоке с рекурсией есть всего одна неизвестная функция, поэтому мы сразу перешли в неё.

Выглядит достаточно просто: имеется множество обращений к полям структуры astruct_1, (которая, напоминаю, является списком), а также очевидно формирование новой подструктуры того же типа. Изменим типы полей и переименуем их так, чтобы итоговый код функции смотрелся приятнее, и получим следующее:

FUN_80011808
Теперь нас ждёт второй блок кода, в котором рекурсии не было. Переходим в единственную вызываемую из него функцию. Код оказался слишком большим, поэтому пришлось спрятать его под спойлер:
/* WARNING: Globals starting with '_' overlap smaller symbols at the same address */
undefined4 FUN_80011808(astruct_1 *item,char *param_2,int param_3,undefined2 param_4,size_t param_5,size_t param_6,void *param_7,int index)
{
dword dVar1;
int iVar2;
int iVar3;
undefined4 uVar4;
undefined *puVar5;
char *dst;
int iVar6;
dword dVar7;
void *pvVar8;
dword dVar9;
undefined local_res8;
char local_230 [512];
size_t local_30;
size_t local_2c;
iVar2 = strlen(param_2);
iVar6 = iVar2 + 1;
iVar3 = iVar6;
if (iVar6 < 0) {
iVar3 = iVar2 + 4;
}
iVar3 = iVar6 + (iVar3 >> 2) * -4;
if (0 < iVar3) {
iVar6 = (iVar2 + 5) - iVar3;
}
pvVar8 = (void *)0x0;
if (*(code **)(&DAT_800595a0 + param_3 * 4) == (code *)0x0) {
if ((int)param_6 < 1) {
puVar5 = (undefined *)malloc2(iVar6 + param_5 + 8);
FUN_80017e5c(puVar5 + iVar6 + 8,param_7,param_5);
dst = puVar5 + 8;
}
else {
local_2c = param_6;
puVar5 = (undefined *)malloc2(iVar6 + param_6 + 8);
FUN_8001441c(puVar5 + iVar6 + 8,&local_2c,param_7,param_5);
dst = puVar5 + 8;
}
}
else {
local_230[0] = '�';
memset();
FUN_800127a4(_DAT_00000170,item,local_230);
iVar3 = strlen(local_230);
local_230[iVar3] = "https://habr.com/";
local_230[iVar3 + 1] = '�';
strcat(local_230,param_2);
if (0 < (int)param_6) {
local_30 = param_6;
pvVar8 = malloc(param_6);
FUN_8001441c(pvVar8,&local_30,param_7,param_5);
param_5 = param_6;
param_7 = pvVar8;
}
uVar4 = FUN_80012aa0(index);
iVar3 = (**(code **)(&DAT_800595a0 + param_3 * 4))(local_230,param_3,param_5,param_7,uVar4);
if (iVar3 == 1) {
if (pvVar8 == (void *)0x0) {
return 1;
}
FUN_80017d60(pvVar8);
return 1;
}
puVar5 = (undefined *)malloc2(iVar6 + param_5 + 8);
FUN_80017e5c(puVar5 + iVar6 + 8,param_7,param_5);
dst = puVar5 + 8;
if (pvVar8 != (void *)0x0) {
FUN_80017d60(pvVar8);
dst = puVar5 + 8;
}
}
strcpy(dst,param_2);
local_res8 = (undefined)param_3;
puVar5[1] = local_res8;
*(undefined2 *)(puVar5 + 2) = param_4;
*puVar5 = (undefined)index;
dVar9 = 0;
dVar1 = item->field_0x4;
if (item->field_0x4 == 0) {
item->field_0x4 = (dword)puVar5;
}
else {
do {
dVar7 = dVar1;
iVar3 = strcmp(param_2,(char *)(dVar7 + 8));
if (iVar3 == 0) {
*(undefined4 *)(puVar5 + 4) = *(undefined4 *)(dVar7 + 4);
if (dVar9 == 0) {
item->field_0x4 = (dword)puVar5;
}
else {
*(undefined **)(dVar9 + 4) = puVar5;
}
*(undefined4 *)(puVar5 + 4) = *(undefined4 *)(dVar7 + 4);
FUN_80017d60(dVar7);
return 0;
}
if (iVar3 < 0) {
if (dVar9 == 0) {
item->field_0x4 = (dword)puVar5;
}
else {
*(undefined **)(dVar9 + 4) = puVar5;
}
*(dword *)(puVar5 + 4) = dVar7;
goto LAB_80011af0;
}
dVar1 = *(dword *)(dVar7 + 4);
dVar9 = dVar7;
} while (*(dword *)(dVar7 + 4) != 0);
*(undefined **)(dVar7 + 4) = puVar5;
}
*(undefined4 *)(puVar5 + 4) = 0;
LAB_80011af0:
item->field_0x2 = item->field_0x2 + 1;
return 1;
}Конец первой части
Думаю, на этом моменте можно остановиться, т.к. код здесь довольно объёмный, а дальше будет только больше. Во второй (и, возможно, третьей) части у нас будет:
- Дальнейший разбор MR-формата
- Сжатие
zlib - Парсер MR-формата на Python
- Разбор собственного формата PIC-кода (Position Independent Code) с релокациями, импортами и блекджеком. Напоминаю, что в MIPS все адреса вызовов должны быть абсолютные
- Загрузчик MR-формата для Ghidra
На этом всё.


