Новые архитектуры нейросетей

Предыдущая статья «Нейросети. Куда это все движется»
В этой статье кратко рассматриваются некоторые архитектуры нейросетей, в основном по задаче обнаружения объектов, чтобы найти (или хотя бы попытаться найти) будущие направления в этой быстро развивающейся области.
Статья не претендует на полноту охвата и хорошее понимание прочитанных «по диагонали» статей. Автор уверен, что пока писал эту статью, появилось еще много новых архитектур. Например, смотрите здесь: https://paperswithcode.com/area/computer-vision.
- EfficientNet
- EfficientDet
- SpineNet
- CenterNet
- ThunderNet
- CSPNet
- DenseNet
- SAUNet
- DetNASNet
- SM-NAS
- AmoebaNet
- Graph Neural Network
- Growing Neural Cellular Automata
- Импульсная нейронная сеть
- DPM
- Выводы
Object Detection in 20 Years — большой обзор на 400+ статей для обнаружения объектов за 20 лет.
The Neural Network Zoo — зоопарк нейросетей, содержимое которого постоянно меняется.
Интересное видео с рекомендациями, как спроектировать нейронную сеть: «How to Design a Neural Network».
EfficientNet
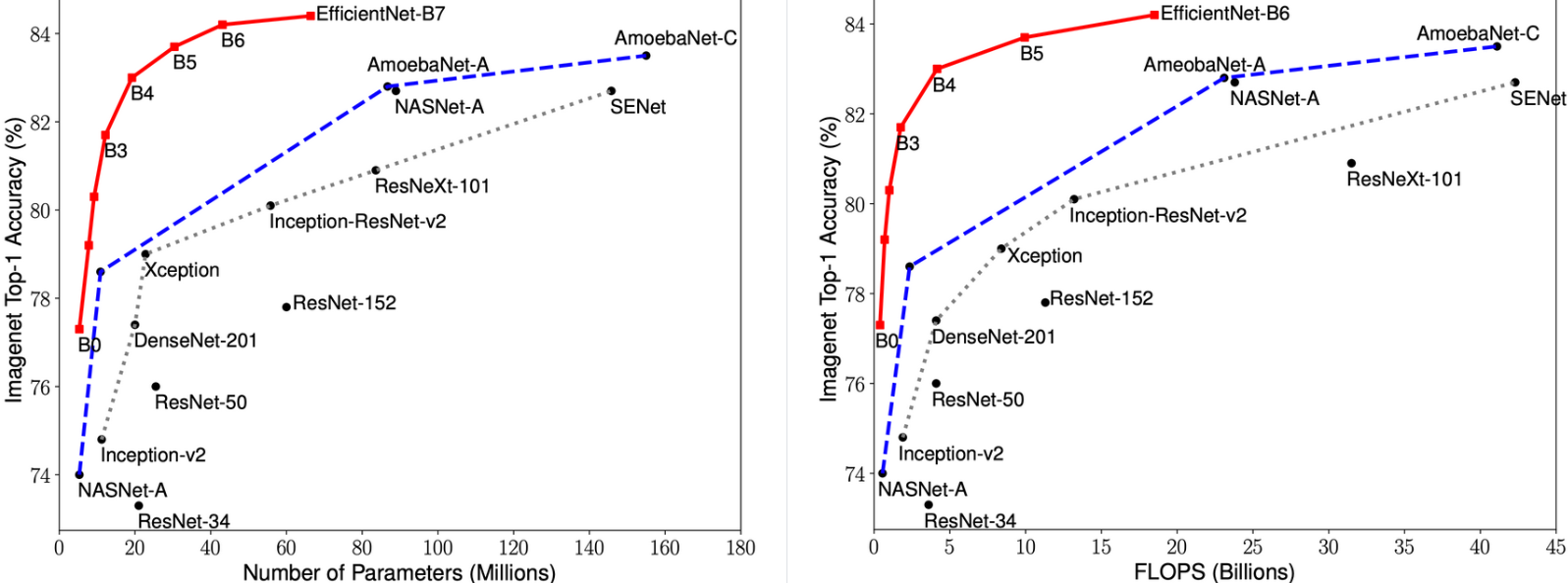
EfficientNet — класс новых моделей, который получился из изучения масштабирования (скейлинг, scaling) моделей и балансирования между собой глубины и ширины (количества каналов) сети, а также разрешения изображений в сети. Авторы статьи предлагают новый метод составного масштабирования (compound scaling method), который равномерно масштабирует глубину/ширину/разрешение с фиксированными пропорциями между ними. Из существующего метода под названием «Neural Architecture Search» (NAS, статья1, статья2, видео) для автоматического создания новых сетей и своего собственного метода масштабирования авторы получают новый класс моделей под названием EfficientNets.
- статья «EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks»
- обзор оригинальной статьи на русском
- исходный код для TensorFlow
- видео1, видео2.1, видео2.2, видео3
EfficientDet
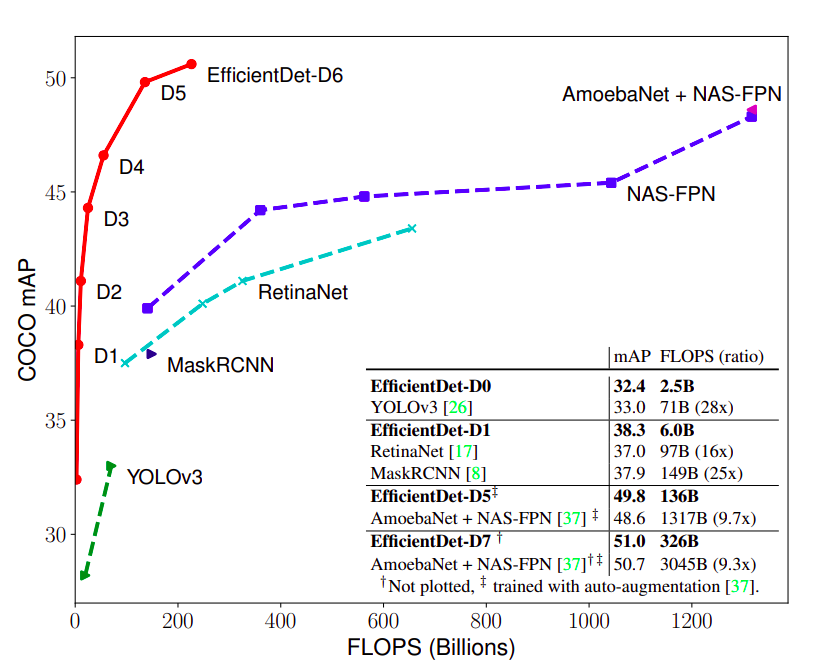
EfficientDet применяется для обнаружения объектов. Архитектура показана на рисунке ниже. Состоит из EfficientNet в качестве основы, к которой приделан слой по работе с пирамидой признаков под названием BiFPN, за которым идет «стандартная» сеть вычисления класс/рамка объекта.
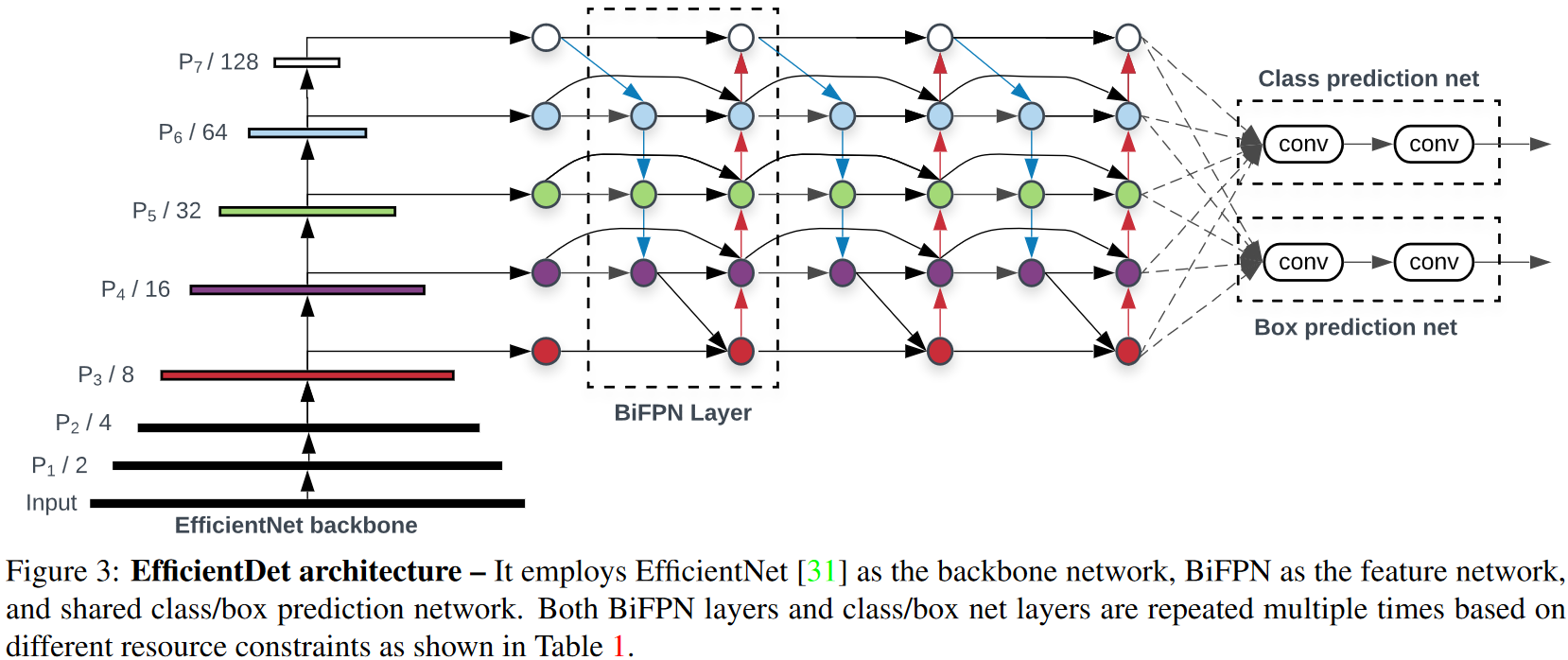
Рисунок — Архитектура EfficientDet == EfficientNet + BiFPN + сеть вычисления класс/рамка
- статья «EfficientDet: Scalable and Efficient Object Detection»
- исходный код для TensorFlow
- исходный код для PyTorch
- видео1
SpineNet
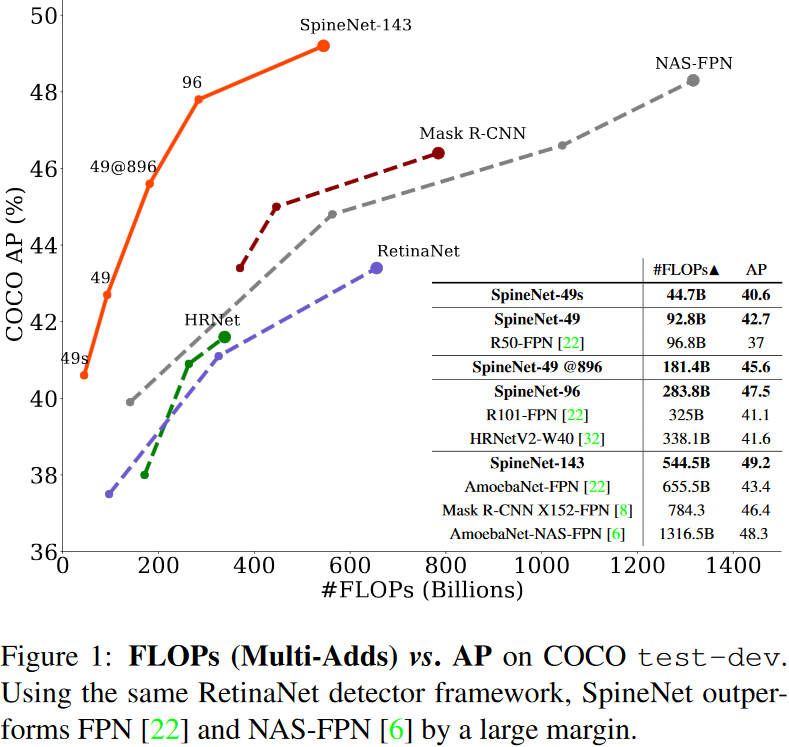
SpineNet применяется для обнаружения объектов на изображении. Исследователи из Google Research достигли хороших результатов, которые превышают имеющиеся state-of-the-art (SOTA) подходы.
Сверточные нейросети обычно кодируют входное изображение в последовательность промежуточных признаков меньшей размерности. Такой подход хорошо работает для задачи классификации изображений, но плохо работает для задачи распознавания объектов (распознавание и локализация). Для обхода ограничения сверточных сетей по локализации (сегментации) объектов применяются сверточные кодировщик-декодировщик с архитектурой типа «песочные часы» (Convolutional Encoder-Decoder Neural Network). В архитектурах типа «песочные часы» декодировщик располагается поверх кодировщика. Таким образом кодировщик применяется для задач классификации, а декодировщик – для задач локализации (сегментации). При этом кодировщик является основной моделью (backbone model), как правило, содержит больше параметров и потребляет больше вычислительных мощностей, чем декодировщик. Исследователи заявляют, что архитектура типа «песочные часы» неэффективна для генерации признаков разных масштабов, потому что в такой модели масштаб изображения постоянно уменьшается при помощи основной модели (кодировщика).
Предложенная модель SpineNet позволяет выучивать разномасштабные признаки из-за сверточных слоев смешанных размеров (смотрите рисунок ниже). Размеры слоев подбирались с помощью нейронного поиска архитектур (Neural Architecture Search, NAS). Использование SpineNet в качестве базовой модели дает прирост в точности (Average Precision, AP). При этом на обучение модели требуется меньше вычислительных ресурсов.
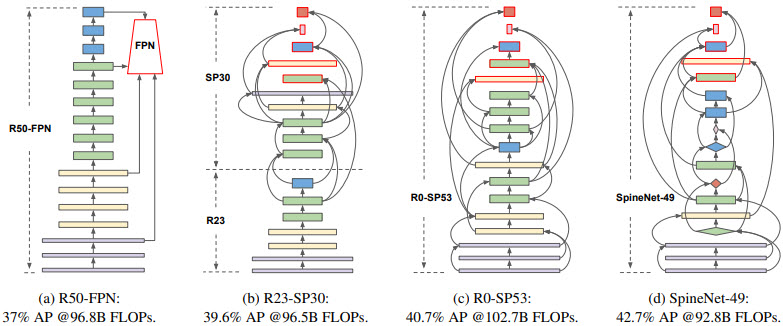
Рисунок – Построение моделей со смешанным масштабом с помощью перестановок слоев архитектуры ResNet (ResNet-50-FPN крайняя слева)
- статья «SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization»
- обзор на русском «SpineNet: архитектура для распознавания и локализации объекта на изображении»
- SpineNet online demo
CenterNet
CenterNet и CornerNet-Lite считались на 2019 год мейнстримовыми легковесными системами обнаружения объектов в реальном времени (cтатья «Объекты как точки»).
CenterNet моделирует объект, как одну точку, которая находится в центре ограничительной рамки. Размер объекта, его ориентация, 3D-форма, направление, поза и т.д. извлекаются в последствии через характеристики изображения (image features) около полученной точки. Авторы подают входное изображение в полносвязную сверточную сеть, которая генерирует тепловую карту (heatmap). Пики на этой тепловой карте соответствуют центрам объектов. Характеристики изображения в каждом пике тепловой карты предсказывают размеры ограничительной рамки вокруг объекта. С помощью CenterNet авторы статьи экспериментируют с определением 3D размеров объектов и оценкой позы человека по двумерному изображению.
В другой статье исследователи используют 3 точки: левый верхний угол, правый нижний угол и центр объекта для более точного определения положения объекта.
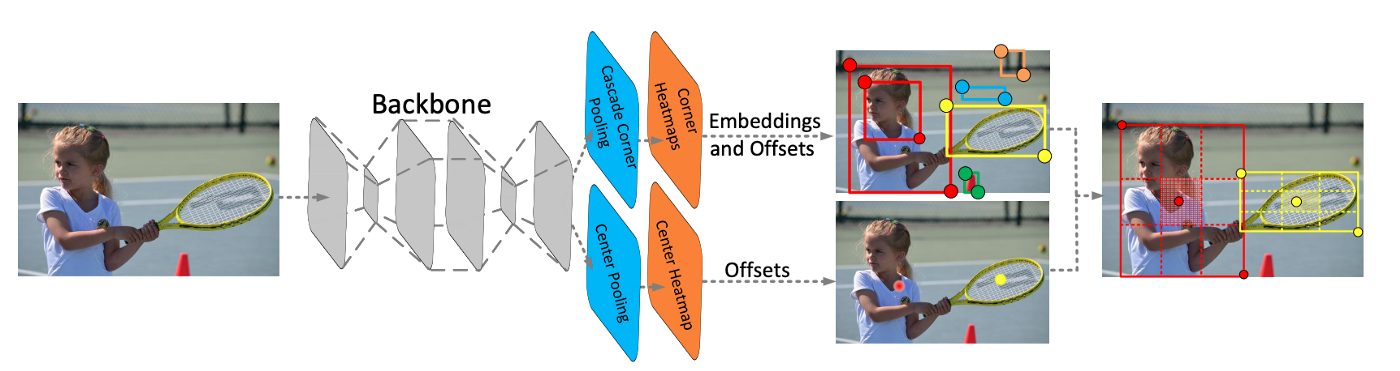
Рисунок – Диаграмма CenterNet
CornerNet является предшественником CenterNet. CornerNet обнаруживает объект, как пару точек: верхний левый и правый нижний углы ограничительной рамки (bounding box). Таким образом распознавание по набору фиксированных рамкок (anchor box), как у нейросетей SSD и YOLO, заменяется на определение пары точек верхнего левого и правого нижнего углов ограничительной рамки вокруг объекта. Также авторы предлагают архитектуру на основе последовательности нескольких нейросетей типа «песочные часы», которые до этого не использовались для определения объектов.
В CornerNet применяется механизм «corner pooling» для определения углов ограничительной рамки вокруг объектов. В CenterNet добавляется механизм «center pooling» для определения центра рамки.
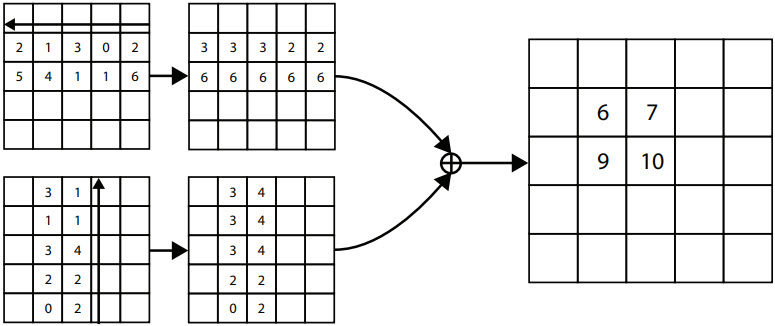
Рисунок – Механизм «corner pooling» для верхнего левого угла. Сканирование проходит справа налево для горизонтального «max-pooling» и снизу вверх для вертикального «max-pooling». Затем две карты характеристик (feature maps) слаживаются.
- статья по CenterNet «CenterNet: Keypoint Triplets for Object Detection» + исходный код 1 + исходный код 2
- статья по CornerNet-Lite «CornerNet-Lite: Efficient Keypoint Based Object Detection» + исходный код
- статья по CornerNet: «CornerNet: Detecting Objects as Paired Keypoints» + исходный код + видео презентация
ThunderNet
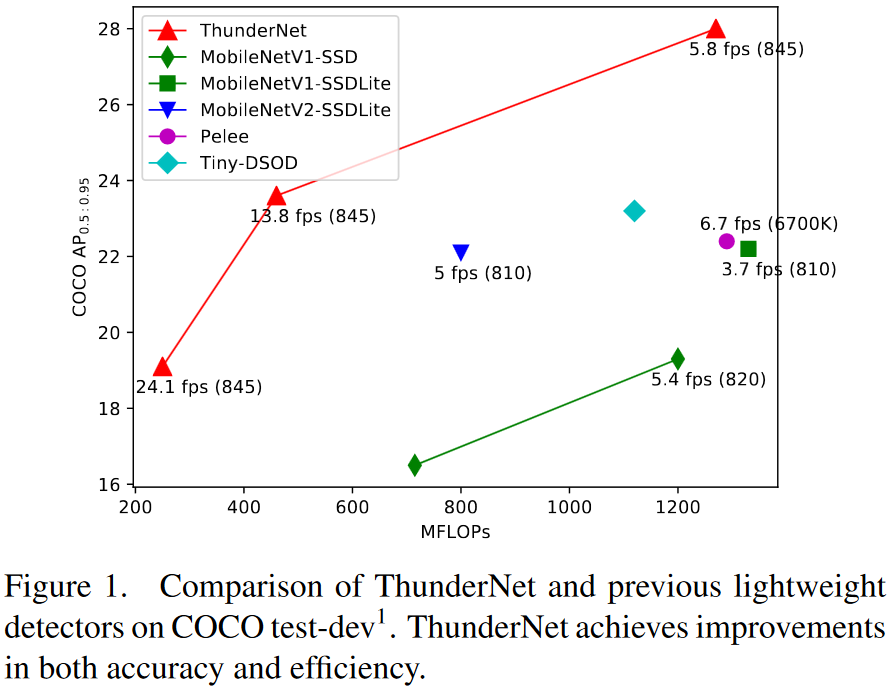
ThunderNet применяется для обнаружения объектов на изображении. Является легковесным двуступенчатым детектором. Как утверждают авторы, является первым детектором объектов в реальном времени, который был запущен на платформах ARM (мобильные телефоны и одноплатные компьютеры) со скоростью 24.1 fps (frames per second, кадров в секунду) и точностью сравнимой с MobileNet-SSD.
- статья «ThunderNet: Towards Real-time Generic Object Detection»
- результаты поиска примеров в GitHub
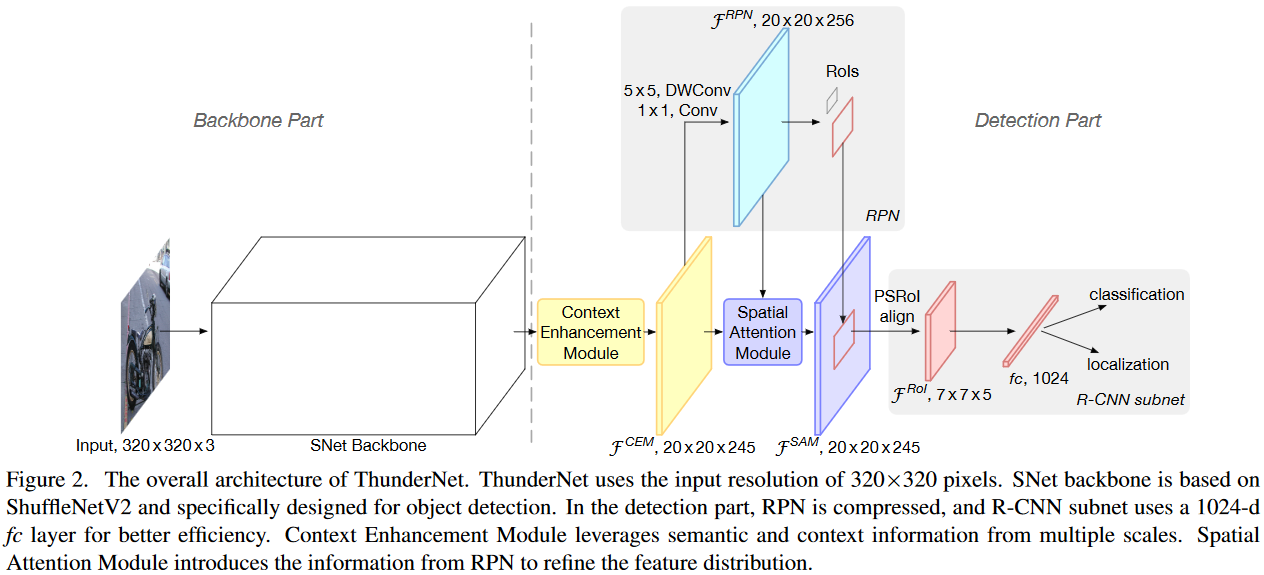
Рисунок — Архитектура ThunderNet
CSPNet
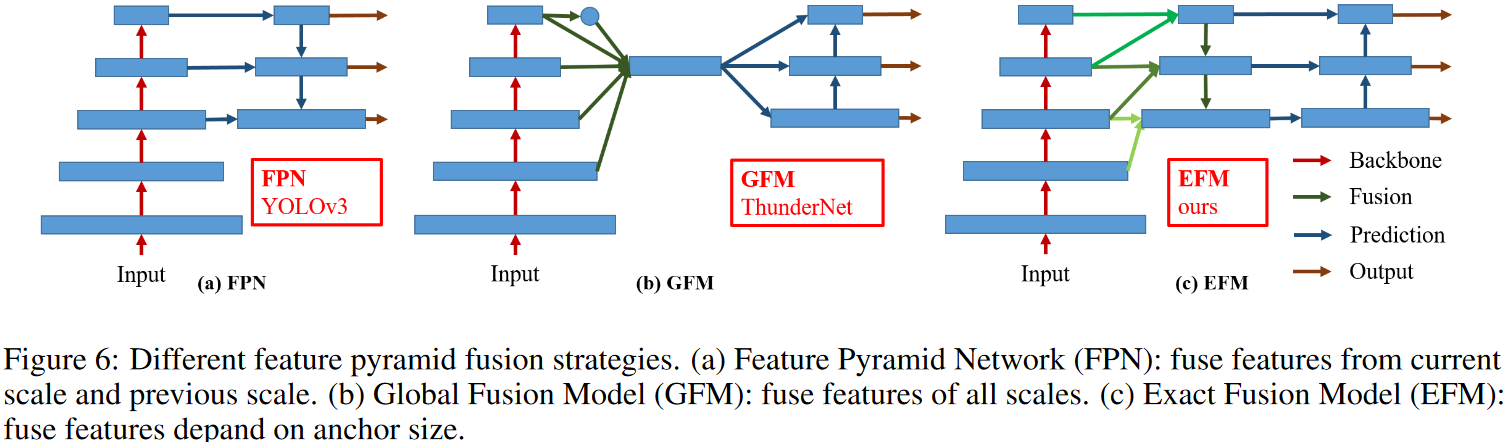
CSPNet (Cross Stage Partial Network) работает на фреймворке Darknet, сайт. Метод применяется не сам по себе, а как улучшение уже существующих остаточных нейросетей (residual neural networks, ResNet). Основная концепция в том, чтобы поток градиента распространялся по разным сетевым путям через разделения потока градиента. Таким образом распространяемая информация о градиенте может иметь большую корреляцию, если переключать этапы конкатенации и перехода. CSPNet может значительно сократить объем вычислений, повысить скорость вывода и точность. Как видно из картинки выше, суть CSPNet заключается в более сложной обработке пирамид признаков (feature pyramid network, FPN).
- статья «CSPNet: A New Backbone that can Enhance Learning Capability of CNN»
- исходный код 1, исходный код 2
Рисунок — Пример пирамиды признаков
DenseNet
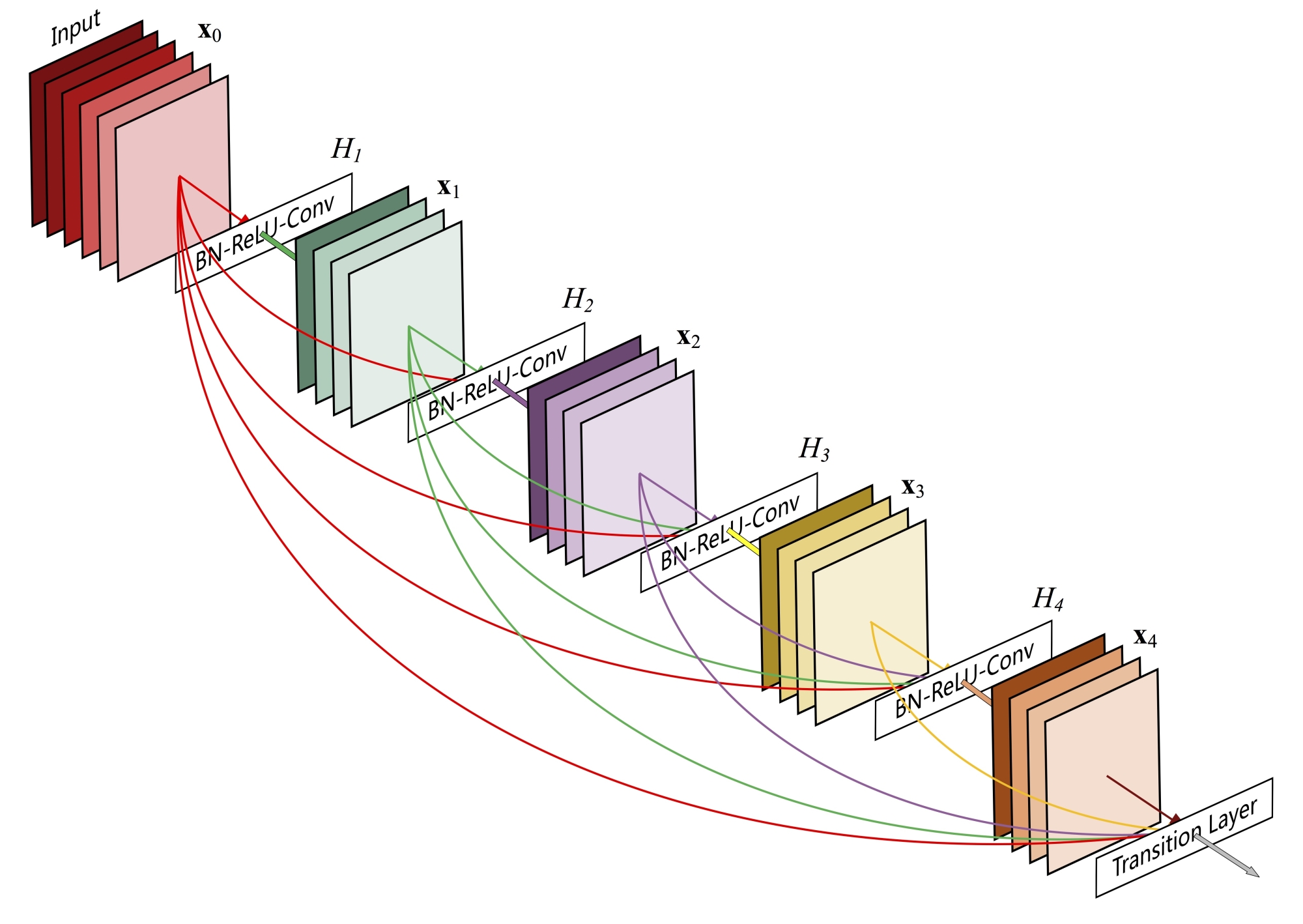
Рисунок — Один плотный блок DenseNet c 5 слоями и скоростью роста k = 4. Каждый слой принимает все предыдущие карты признаков в качестве входных данных.

Рисунок — DenseNet с тремя плотными блоками
DenseNet (Densely Connected Convolutional Network) была предложена в 2017 году. Успех ResNet (Deep Residual Network) позволил предположить, что укороченное соединение в CNN позволяет обучать более глубокие и точные модели. Авторы проанализировали это наблюдение и представили компактно соединенный (dense) блок, который соединяет каждый слой с каждым другим слоем. Важно отметить, что, в отличие от ResNet, признаки («фичи») прежде чем они будут переданы в следующий слой не суммируются, а конкатенируются (объединяются, channel-wise concatenation) в единый тензор. При этом количество параметров сети DenseNet намного меньше, чем у сетей с такой же точностью работы. Авторы утверждают, что DenseNet работает особенно хорошо на малых наборах данных.
- статья «Densely Connected Convolutional Networks»
- видео презентация
- видео реализация на Keras + исходный код этой и многих других моделей в CoLab
- реализация на Torch от автора, обученные модели и реализации на других фреймворках
SAUNet
SAUNet (Shape Attentive U-Net) показывает наилучшие на начало 2020 года результаты по сегментации изображений МРТ сердца и предлагается автомами, как сеть по сегментации медицинских изображений.
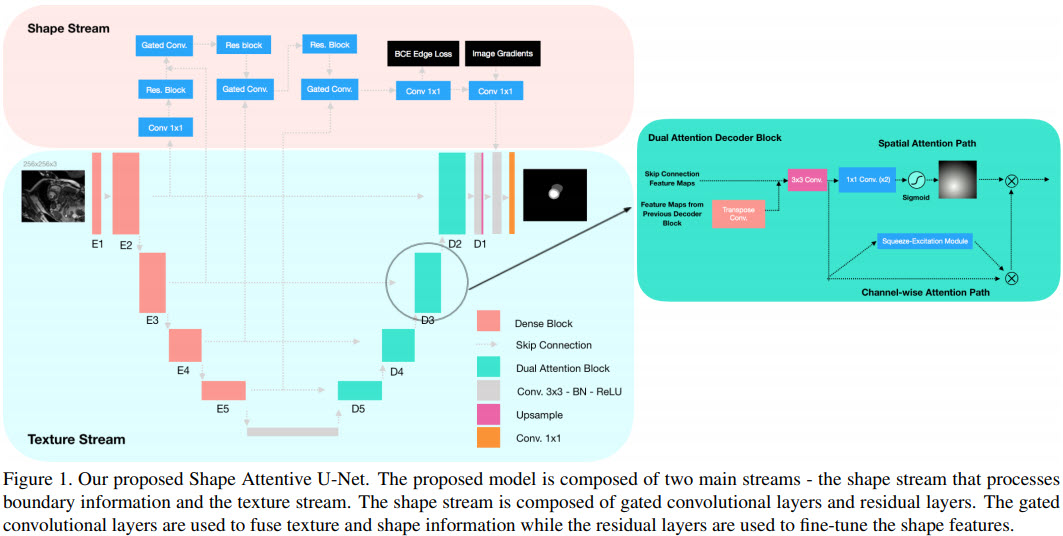
Рисунок — SAUNet состоит из двух частей: одна часть обрабатывает текстуры (texture stream); вторая часть обрабатывает формы (gated shape stream). В кодировщике текстур сети U-Net используются блоки DenseNet-121 (смотрите выше DenseNet), а в декодере в качестве слоев сети U-Net применяются «блоки внимания» (dual attention decoder block).
Архитектура SAUNet является модульной и состоит из многих различных блоков: U-Net, DenseNet, Gated-SCNN и механизма внимания на основе Squeeze-and-Excitation Networks.
- статья «SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation»
- исходный код на PyTorch
DetNASNet
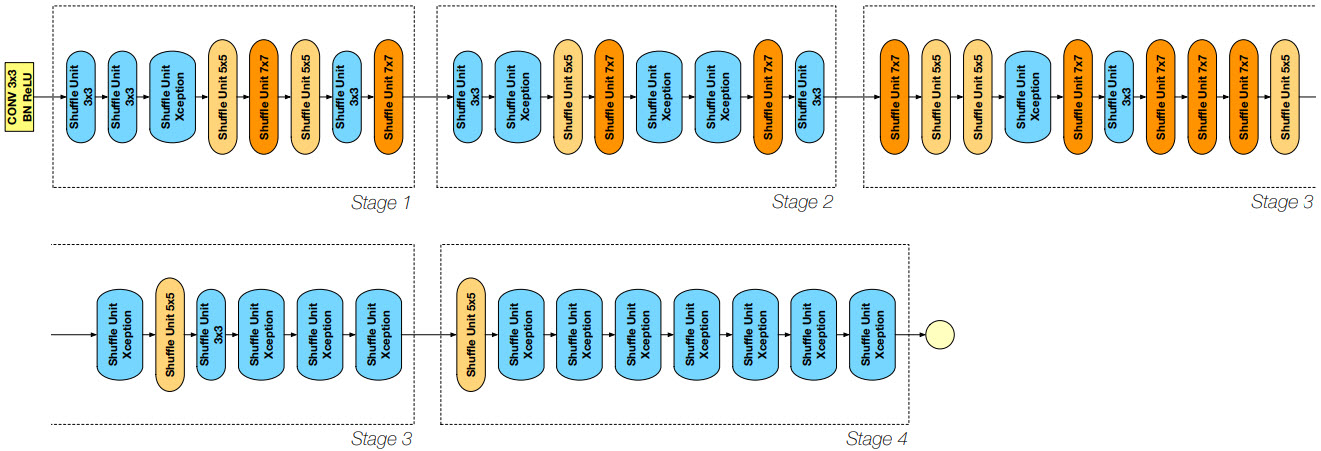
Рисунок — Архитектура DetNASNet
Многие детекторы объектов работают на сетях, которые спроектированы для классификации изображений, что не оптимально, потому что определение объектов (object detection) и классификация изображений (image classification) являются различными задачами. DetNASNet использует подход под названием Neural Architecture Search (NAS) для разработки архитектур, которые определяют объекты. Авторы утверждают, что они впервые применили процесс NAS, т.е. автоматический поиск оптимальных гиперпараметров нейросети, для оптимизации задачи определения объектов. Количесто вычислений составило 44 GPU-дня на наборе данных COCO. Достигнутая точность лучше, чем у ResNet-101, с гораздо меньшим количеством FLOP-пов.
- статья «DetNAS: Backbone Search for Object Detection»
- исходный код на PyTorch
SM-NAS
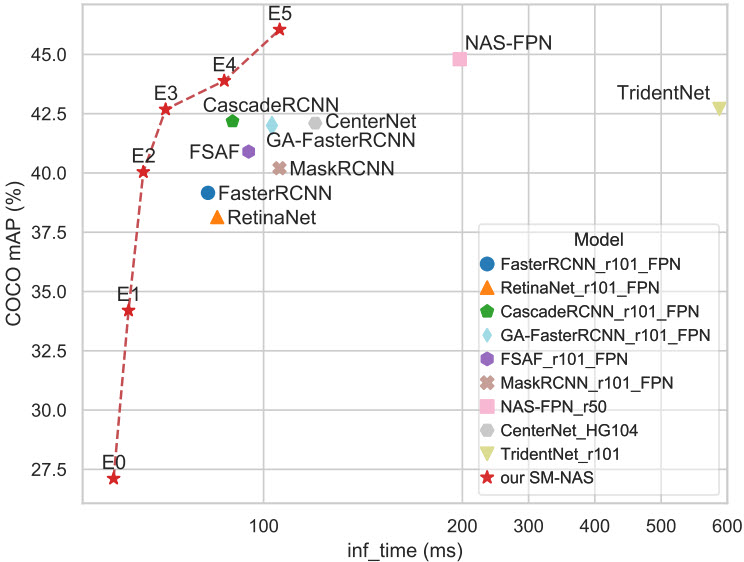
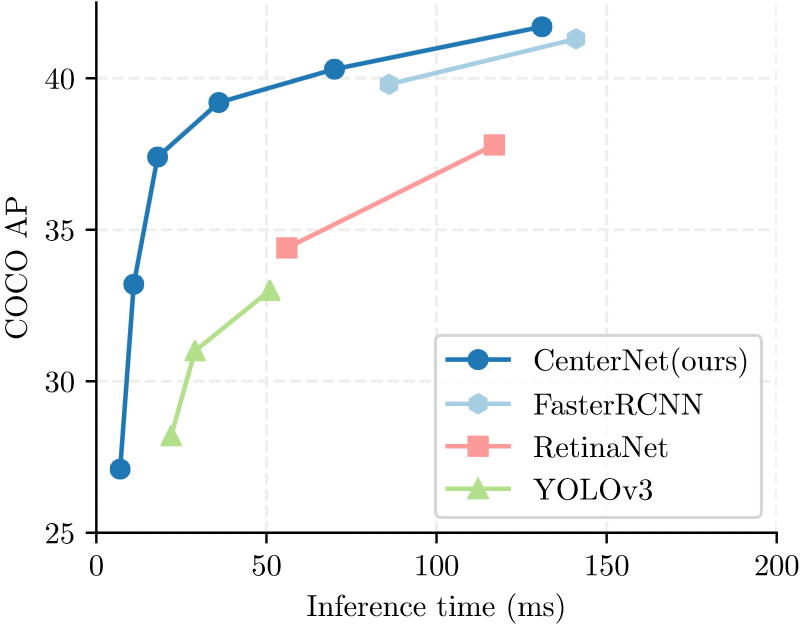
Рисунок — Сравнение времени вывода (мс) и точности обнаружения (mAP) на наборе данных COCO.
В SM-NAS предлагается двухэтапная стратегия грубого поиска под названием Structural-to-Modular NAS (SM-NAS): первый этап поиска на структурном уровне направлен на поиск эффективной комбинации различных модулей; второй этап поиска на модульном уровне развивает каждый конкретный модуль и продвигает фронт Парето вперед к более быстрой сети для конкретных задач.
- Исходный код не найден.
- статья «SM-NAS: Structural-to-Modular Neural Architecture Search for Object Detection»
AmoebaNet
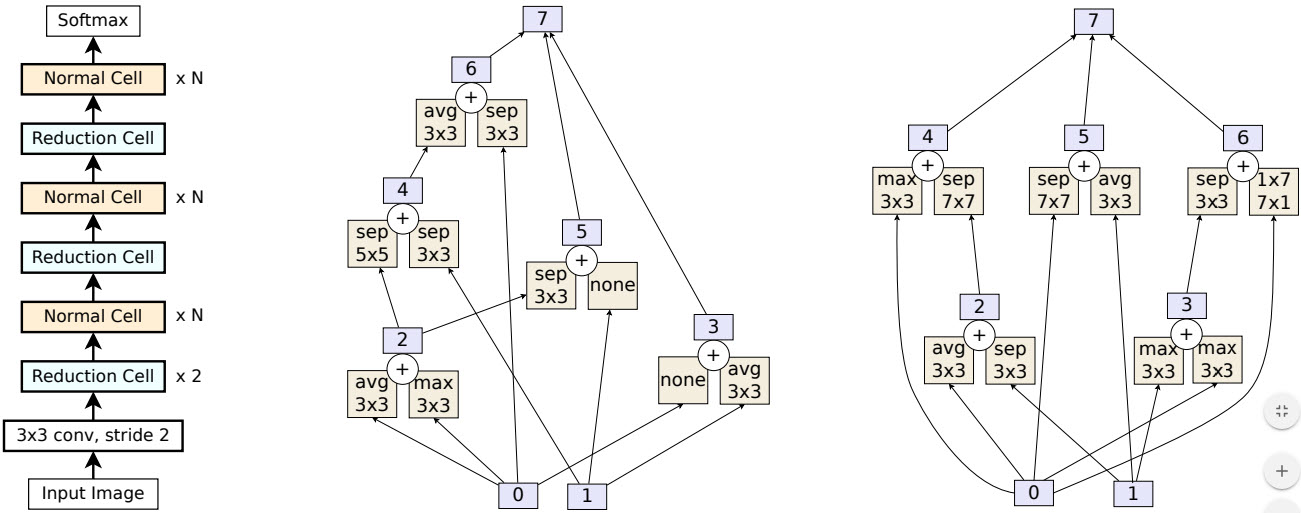
Рисунок — Архитектура сети AmoebaNet-A. Слева общая модель. В центре блок «Normal Cell». Справа блок «Reduction Cell».
AmoebaNet также относится к алгоритмам по автоматическому созданию нейросетей. AmoebaNet использует эволюционные алгоритмы вместо алгоритмов обучения с подкреплением для автоматического поиска оптимальных архитектур нейросетей. AmoebaNet использует то же простарство поиска (search space), что и NASNet. Является очень затратной по вычислениям и использует сотни TPU (Tensor Processing Units) для вычислений.
- статья «Regularized Evolution for Image Classifier Architecture Search»
- исходный код
Graph Neural Network
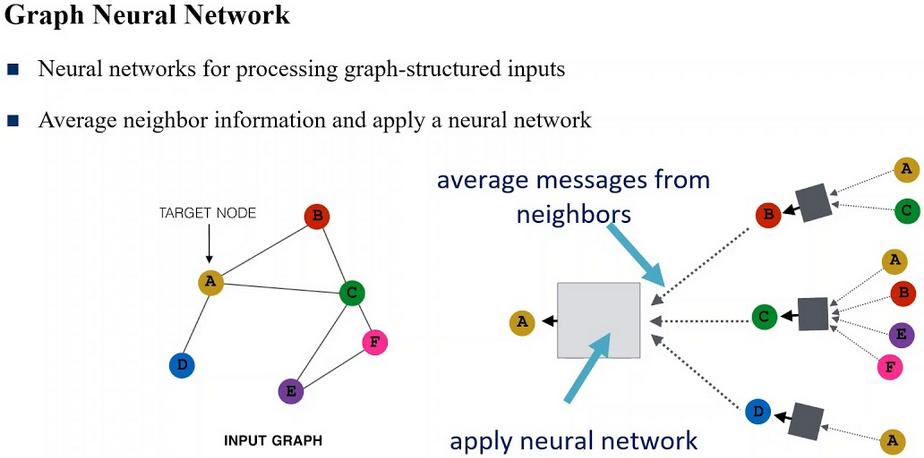
Graph Neural Network или нейронная сеть на графе, где искусственные нейроны — это узлы графа, а соединения между нейронами — это ребра графа. Полезны для решения задач машинного обучения на графах, т.е. если задачу можно представить в виде какого-нибудь графа. А на графах можно сделать очень многое и даже прововодить обработку изображений. Наиболее популярные библиотеки для машинного обучения на графах: PyTorch Geometric для PyTorch, Graph Nets для TensorFlow, Deep Graph самая удобная для начала ознакомления.
- простой пример в CoLab
- видео by Siraj Raval
- документация библиотеки DGL (Deep Graph Library)
Growing Neural Cellular Automata
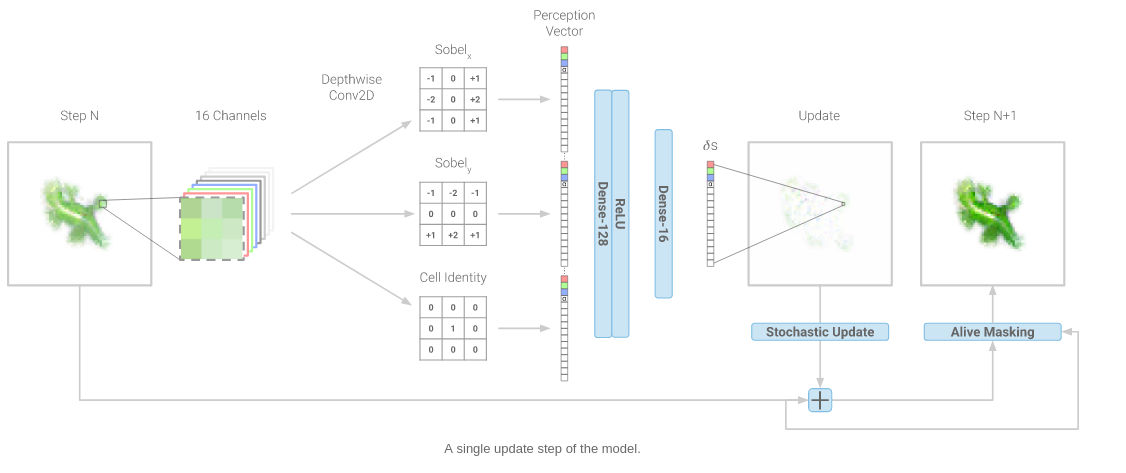
Рисунок — Один шаг обновления модели
Growing Neural Cellular Automata являются скрещением идей клеточных автоматов и искусственных нейронных сетей, результатом которого являются «живые» самовоспроизводящиеся и взаимодействующие друг с другом изображения. Ничто не мешает вместо изображений взять любые другие объекты (текст, музыку и т.д.). Растущие нейронные клеточные автоматы выглядят привлекательно и эффектно. Изображения «выращиваются» из вектора в 16 чисел с плавающей запятой. Таким образом данные могут быть «упаковываны» в компактную цепочку чисел, как код ДНК, что в будущем может составить конкуренцию форматам сжатия данных типа JPEG (изображения), MP3 (звук), MPEG (видео) и ZIP (текст).
В интерактивной статье исследователи объясняют принцип устройства растущих нейронных клеточных автоматов, а также пути достижения устойчивости картинки с течением времени, способность восстанавливаться (регенерировать) при повреждениях и устойчивость к вращению.
- интерактивная статья на сайте Distill
- исходный код в Colab notebook
- видео презентация by Yannic Kilcher
- игра «Жизнь»
Импульсная нейронная сеть
Импульсная нейронная сеть или Spiking neural network является самой реалистичной с точки зрения физиологии. В ней нейроны обмениваются короткими импульсами одинаковой амплитуды. Первая научная модель импульсной нейросети была предложена еще в 1952 году Аланом Ходжкином и Эндрю Хаксли, однако данный вид искусственных нейронных сетей известен немногим специалистам в этой области. Основная идея состоит в том, чтобы скопировать поведение биологическкого нейрона. Такие модели могут быть полезны при изучении функций мозга. Для того, чтобы быстро летать, необязательно махать крыльями, однако при решении прикладных задач некоторые свойства можно позаимствовать у биологических организмов.
- Википедия (ru, en)
- результаты поиска на сайте PapersWithCode.com
DPM
DPM, Deformable Part Model detector, не нейросеть. Использует марковское случайное поле (смотрите реализацию в CoLab) и гистограммы направленных градиентов (HOG). Была популярна при обнаружении пешеходов где-то в 2009 году, а затем, как пишут в статье «Object Detection in 20 Years: A Survey», уступила первенство алгоритму Integral Channel Features (ICF), который затем уступил первенство нейросетям.
Сотни готовых «классических» алгоритмов могут использоваться для предварительной обработки и постобработки данных, как дополнение к нейросетям, которое обеспечивает новый синтез идей, и даже вместо нейросетей. Например, в статье «Deformable Part Models are Convolutional Neural Networks» алгоритм DPM заменяется на эквивалентную ему сверточную нейронную сеть.
- статья «Deformable Part Models are Convolutional Neural Networks» + довольно устаревшая реализация на MatLab и Caffe
Выводы
-
Усилия исследователей направлены на:
- автоматический поиск оптимальных параметров нейросети, развитие идей AutoML, «нейросеть генерирует нейросеть», Neural Architecture Search (NAS и NASNet);
- механизм внимания (attention mechanism), карты внимания;
- развитие сверточных сетей типа «песочные часы» для задач обнаружения объектов, которые часто используются как основные (backbone) модели в модульных архитектурах;
- модульность, многие современные state-of-the-art (SOTA) архитектуры сотоят из многих частей.
-
Чтение статей без последующей работы с исходным кодом дает мало пользы. Даже если понятна задумка исследователей, но без понятного исходного кода и умения использовать исходный код на практике такое знание не имеет смысла. Кроме осведомленности, что такой метод уже есть, чтобы не изобретать велосипед заново. После чтения «по диагонали» нескольких десятков статей в очередной раз убедился, что ИТ — это практическая дисциплина, нацеленная на результат.
P.S. Рекомендую видео блог ML Tokyo, в котором автор объясняет и делает нейросети на Keras. Его CNN семинар — это как раз то, что нужно начинающему «нейрокодеру» вроде меня.
Спасибо за внимание!


