
Спустя два года после того как BERT был представлен миру, трансформеры по-прежнему доминируют в списках лидеров и породили многочисленные последующие исследования.
Первая версия нашей попытки обзора литературы по BERT (Rogers et al., 2020) содержала обзор около 40 статей в феврале 2020 года. К июню их было более сотни.
Окончательная версия TACL c достаточно хорошим внешним видом содержит около 150 цитат, связанных с BERT, и нет никаких иллюзий завершённости: в августе 2020 года у нас закончились отведённые для журнала страницы.
Но даже несмотря на все эти исследования, всё ещё не ясно, почему BERT работает так хорошо. Давайте разбираться вместе с Анной Роджерс – доцентом Копенгагенского университета, экспертом в области обработки естественного языка, машинного обучения и социальных данных.
Многие исследования показывают, что BERT имеет много информации о языке, что должно объяснить его высокую производительность. Однако большинство аналитических работ BERT сосредоточены на различных типах зондов: прямых исследованиях модели замаскированного языка или различных задачах (POS-разметка, NER, синтаксический анализ и т. д.), для которых контролируемый классификатор обучается поверх полного BERT или его части. Первый на самом деле мало что говорит нам о тонко настроенном BERT, как он чаще всего используется, а второй добавляет дополнительные параметры, что затрудняет однозначное приписывание базовым представлениям BERT. Кроме того, теперь ясно, что многие текущие наборы данных НЛП имеют всевозможные предубеждения и артефакты, и BERT действительно их использует.
Недавняя работа даёт подсказки для альтернативного направления исследований:
- Гипотеза лотерейного билета предполагает, что случайно инициализированные нейронные сети содержат подсети, которые могут быть повторно обучены отдельно, чтобы достичь (а иногда и превысить) производительности полной модели;
- Большинство параллельных проходов через механизм самонаблюдения BERT можно обрезать на основе оценок важности, полученных из градиентов модели;
- Для моделей Base-Transformer, обученных машинному переводу, последние упрощённые параллельные проходы самонаблюдения, как правило, имеют синтаксические функции.
Учитывая всё это, если BERT излишне параметризован, можем ли мы добиться лучшей интерпретируемости, обрезав её до самых важных компонентов? Если они действительно имеют решающее значение для производительности модели, то их функции должны рассказать нам кое-что о том, как всё это на самом деле работает. При таком подходе мы воспользуемся обрезкой как методом анализа модели, а не её сжатия.
В совместном проекте с Sai Prasanna (Zoho) и Anna Rumshisky (UMass Lowell) мы обнаружили, что неструктурированная обрезка весов BERT, основанная на их величине, согласуется с прогнозами основной гипотезы лотерейных билетов и даёт стабильные подсети. Однако обрезка параллельных проходов и MLP на основе оценок их важности не даёт «хороших» подсетей, согласованных при инициализациях тонкой настройки или даже при выполнении аналогичных задач (что указывает на согласованные стратегии рассуждений). Эти подсети также не содержат преимущественно параллельных проходов самонаблюдения, которые кодируют потенциально интерпретируемые паттерны. Для большинства задач GLUE «хорошие» подсети можно переобучить, чтобы достичь производительности, близкой к производительности полной модели, но то же самое можно сделать и для подсетей того же размера, выбранных случайным образом. Это хорошая новость для сжатия BERT (это лотерея, в которой нельзя проиграть), но плохая новость для интерпретируемости.
Обрезка BERT
Ещё раз: гипотеза лотерейного билета прогнозирует, что случайно инициализированные нейронные сети содержат подсети, которые можно переобучить отдельно, чтобы достичь производительности полной модели. Мы используем два метода обрезки, чтобы найти такие подсети и проверить, верна ли гипотеза: неструктурированное обрезка по величине и структурированная обрезка.
Классическая гипотеза лотерейного билета в основном проверялась с помощью неструктурированной обрезки, в частности обрезки по величине (m-обрезки), при котором веса с наименьшей величиной обрезаются независимо от их положения в модели. Мы итеративно сокращаем 10 % весов с наименьшей величиной по всей тонко настроенной модели (кроме векторных представлений) и оцениваем на наборе для разработки до тех пор, пока производительность обрезанной подсети составляет более 90 % производительности полной модели.
Мы также экспериментируем со структурированной обрезкой (s-обрезкой) целых компонентов архитектуры BERT на основе их оценок важности: в частности, мы «удаляем» наименее важные параллельные проходы самонаблюдения и MLP, применяя маску. На каждой итерации мы удаляем 10 % проходов BERT и 1 MLP, пока производительность обрезанной подсети – это более 90 % производительности полной модели. Чтобы определить, какие проходы и MLP нужно обрезать, мы используем аппроксимацию, основанную на потерях: оценки важности, предложенные Michel, Levy and Neubig (2019) для проходов самонаблюдения, которые мы распространяем на MLP. Пожалуйста, ознакомьтесь с нашей статьёй и оригинальной формулировкой, чтобы узнать больше.
Для обоих методов маски определяются по отношению к полной производительности модели на конкретном наборе данных. Мы заинтересованы найти подсети, которые позволят BERT эффективно выполнять полный набор из 9 задач GLUE. Наборы тестов GLUE не общедоступны, и мы используем наборы для разработки как для поиска масок обрезки, так и для тестирования модели. Поскольку нас интересуют «стратегии рассуждений» BERT, а не обобщение, этот подход позволяет нам увидеть лучшие и худшие возможные подсети для этих конкретных данных.
Насколько стабильны «хорошие» подсети при случайной инициализации?
Недавняя работа показала, что существует значительная разница в производительности BERT при случайных инициализациях слоя, который специфичен для конкретной задачи (Dodge et al., 2020), до такой степени, что разные инициализации приводят к резко различающейся производительности обобщения.
Мы оцениваем стабильность «хороших» подсетей, выполняя каждый эксперимент для каждой задачи GLUE с пятью случайными инициализациями слоя, специфичного для задачи BERT (во всех экспериментах используется один и тот же набор начальных значений). Вот примеры «хороших» подсетей, найденных с помощью обоих методов обрезки:

Пример «хорошей» подсети: два метода обрезки выбирают очень разные подсети.
Ясно, что подсети с m-обрезкой довольно стабильны (стандартное отклонение обычно около 0,01). Но этого нельзя сказать о s-обрезке: есть несколько параллельных проходов, которые особенно живучи (супер-выжившие) (т. е. они выживают во всех случайных данных инициализации), а некоторые после обрезки не выживают никогда, но примерно для 70 % параллельных проходов самонаблюдения стандартное отклонение находится в диапазоне 0,45–0,55. Каппа Флейсса для масок выживания прохода / MLP для случайных чисел инициализации также низкая, в диапазоне 0,1–0,3.
Причина этого, по всей видимости, заключается в том, что оценки важности для большинства параллельных проходов самонаблюдения BERT одинаково низкие. Вот пример распределения оценок важности для CoLA на первой итерации обрезки: большинство проходов одинаково не важны, их все можно обрезать с примерно одинаковым эффектом.

Распределение оценок внимания: CoLA, итерация 1. Большинство проходов имеют низкие оценки важности.
Насколько стабильны «хорошие» подсети при выполнении задач?
Поскольку для m-обрезки ключевым фактором является величина предварительно обученных весов BERT, подсети с m-обрезкой очень похожи как для случайных чисел инициализации, так и для разных задач. Но это не относится к s-обрезке, где «хорошие» подсети сильно различаются для разных задач.
Кажется, что связанные задачи, с точки зрения «хороших» подсетей, не всегда имеют больше общего. На следующей диаграмме показано среднее количество «общих» параллельных проходов самонаблюдения в подсетях для всех пар задач GLUE. Например, QQP и MRPC ближе с точки зрения постановки задач, чем QQP и MNLI, но в «хороших» подсетях в обоих случаях общие 52–55 проходов.
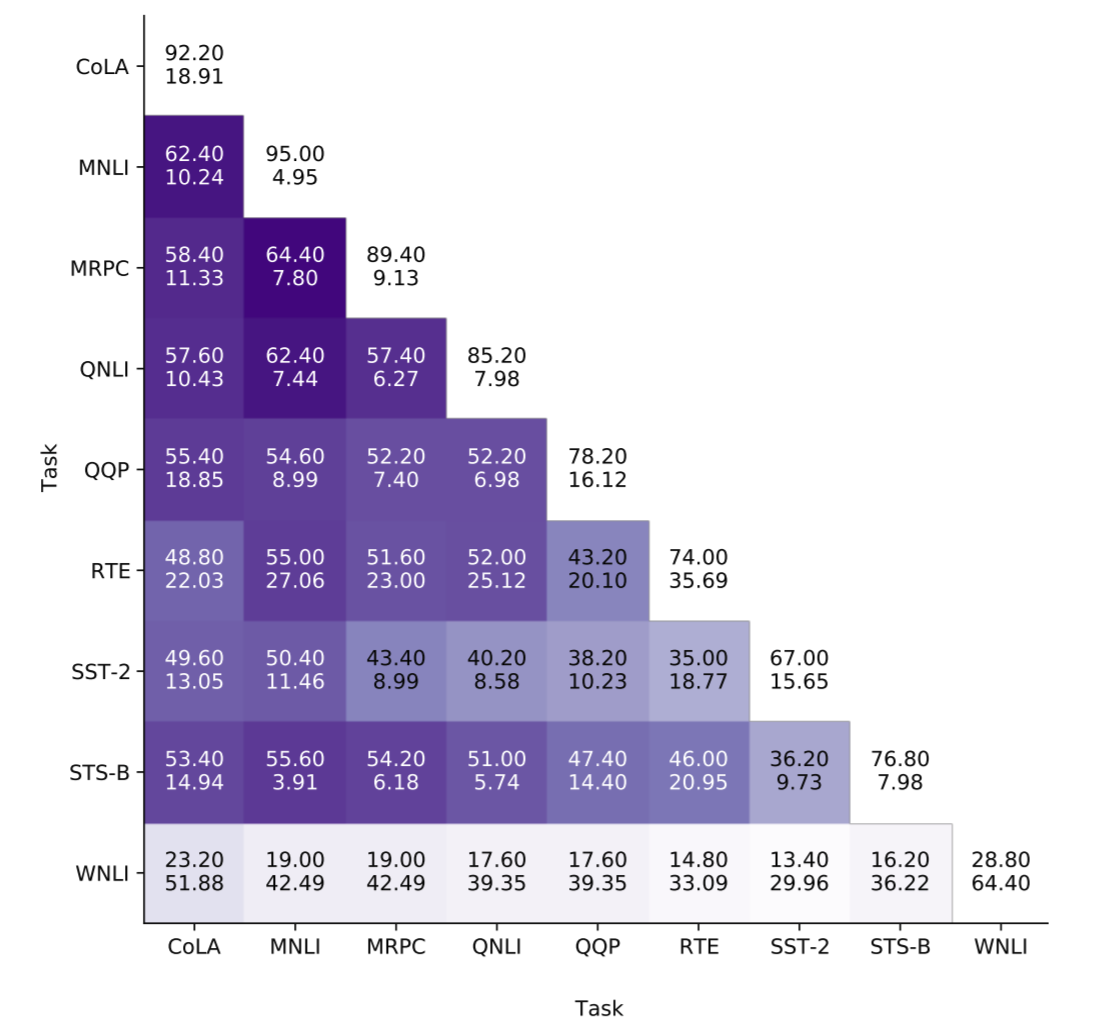
Общие проходы с самонаблюдением в «хороших» подсетях для задач GLUE: связанные теснее задачи не всегда имеют больше общих проходов (например, QQP/MRPC и QQP/MNLI).
Гипотеза лотерейного билета для BERT?
Мы рассматриваем три экспериментальные установки:
- «Хорошие» подсети: элементы, выбранные из полной модели с s- или m-обрезкой;
- «Случайные» подсети: элементы, случайно отобранные из полной модели, чтобы соответствовать «хорошему» размеру подсети;
- «Плохие» подсети: элементы, которые не пережили обрезку, плюс несколько элементов, отобранных из оставшихся, чтобы соответствовать хорошему размеру подсети.
Во всех трёх настройках мы измеряем производительность обрезанных подсетей, а также производительность той же самой повторно настроенной подсети, при этом оставшаяся часть модели маскируется. Опять же, прогноз гипотезы лотерейного билета состоит в том, что «хорошие» подсети должны быть в состоянии достичь полной производительности модели при повторной тонкой настройке.
Мы действительно находим такие подсети в случае m-обрезки: обрезанные и повторно настроенные «хорошие» подсети достигают полной производительности модели в 8 из 9 задач GLUE (за исключением WNLI, где модель обычно не обучается). Эти результаты согласуются с одновременной работой на обрезке по величине BERT (Chen et al., 2020). «Случайные» и «плохие» подсети также обычно работают лучше при повторной настройке, но «плохие» подсети постоянно хуже «случайных».

Хорошее, плохое и случайное: обрезка по величине. «Хорошие» подсети в основном могут быть переобучены, чтобы соответствовать производительности полной модели, «случайные» подсети также могут быть переобучены, но их дела идут хуже, а «плохие» подсети неизменно остаются худшими.
Однако для подсетей с s-обрезкой тенденция иная. Для большинства задач подсети с s-обрезкой достигают не совсем полной производительности модели, хотя для многих задач разница находится в пределах двух баллов. Однако «случайные» подсети могут быть повторно обучены почти так же, как и «хорошие»; это согласуется с наблюдением о том, что оценки важности для большинства параллельных проходов одинаково низкие. Что касается «плохих» подсетей, обратите внимание, что, поскольку мы оцениваем наборы GLUE для разработчиков, которые мы также используем, чтобы выбрать маски, «плохие» подсети являются наихудшим выбором элементов BERT для этих конкретных данных. Тем не менее даже они остаются легко обучаемыми и в среднем соответствуют базовому уровню biLSTM + GloVe GLUE.

Хорошие, плохие и случайные: структурированная обрезка. «Хорошие» подсети не вполне достигают всей производительности модели после переобучения, хотя они близки к этому. Но большинство «случайных» подсетей работают так же хорошо, и даже «плохие» подсети легко обучаемы.
Мы сделали из этого следующий вывод: можно сказать, что у s-обрезанного BERT нет «проигрышных» билетов. Это даёт не совсем полную производительность модели, но для большинства задач GLUE случайное подмножество полной модели работает почти так же хорошо, как подсеть, выбранная по оценкам важности. Это свидетельствует о том, что либо большинство компонентов BERT избыточны (и в этом случае большинство случайных подмножеств по-прежнему будут содержать одну и ту же информацию), либо существуют реальные различия в информационном содержании различных компонентов, но оценки важности недостаточно чувствительны к ним.
Насколько лингвистически информативны «хорошие» подсети?
В этом эксперименте мы рассматриваем именно самые живучие компоненты: компоненты BERT, которые пережили s-обрезку с пятью случайными инициализациями. Если успех подсетей BERT объясняется лингвистическими знаниями, которые они кодируют, самые живучие должны содержать их значительно больше.
Мы сосредотачиваемся на проходах самонаблюдения, поскольку они были в центре внимания многочисленных исследований BERT, показывающих, что они кодируют определённые лингвистические знания, а также дискуссии об интерпретируемости. Вместо того чтобы использовать зондирование для определения потенциальных функций параллельных проходов самонаблюдения BERT, мы выбираем прямой анализ их паттернов внимания. Есть 5 типов паттернов:
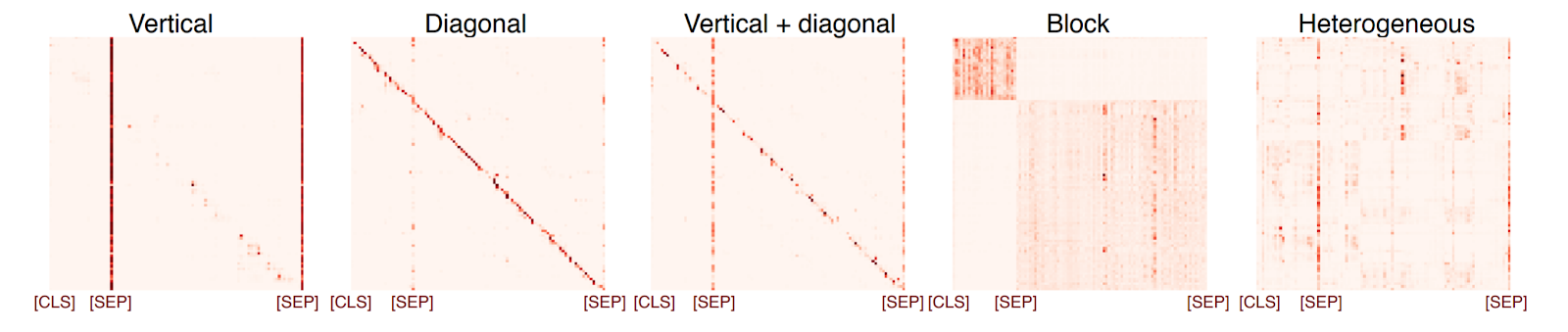
Типы паттернов самонаблюдения (Kovaleva et al., 2019)
Поскольку «гетерогенный» паттерн – единственный, который потенциально может кодировать лингвистически интерпретируемые отношения, соотношение проходов самонаблюдения с такими паттернами даёт верхнюю границу интерпретируемых паттернов. Следуя, мы обучаем классификатор CNN на аннотированном вручную наборе из 400 карт самонаблюдения, представленном авторами. Мы также рассматриваем нормированные по весу карты самонаблюдения, которые должны снижать внимание к специальным токенам и для которых мы аннотируем ещё 600 образцов карт наблюдения. Затем мы кодируем 100 примеров из каждой задачи GLUE, генерируем карты наблюдения для каждого прохода BERT и используем наши обученные классификаторы, чтобы оценить, сколько паттернов каждого типа мы получаем. На аннотированных данных классификаторы дают F1 0,81 для необработанных карт наблюдения и 0,74 для карт наблюдения, нормированных по весу.
Мы наблюдаем, что для необработанных карт самонаблюдения супер-выжившие имеют больше блочных и вертикальных + диагональных паттернов, но количество гетерогенных паттернов не увеличивается. В нормированном по весу состоянии соотношение диагональных паттернов уменьшается, но для большинства задач у супер-выживших остается 30–40 % диагональных паттернов. В обоих условиях две задачи обнаружения перефразирования (MRPC и QQP) имеют заметное увеличение количества вертикальных паттернов наблюдения, что обычно указывает на внимание к SEP, CLS и пунктуации.
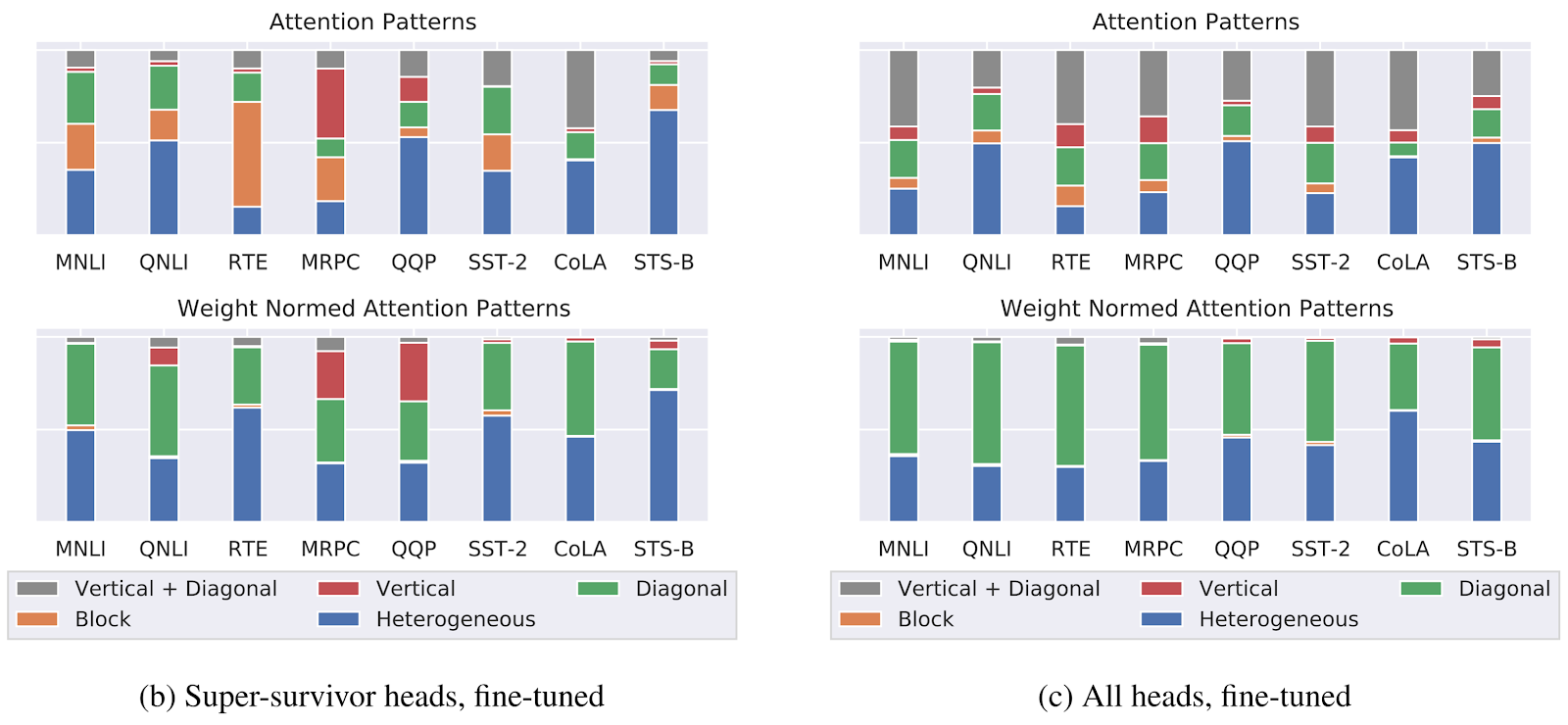
Распределение паттернов самонаблюдения в параллельных проходах супер-выживших. Соотношение потенциально интерпретируемых паттернов самонаблюдения (синий) существенно не меняется в подсетях супер-выживших (слева) по сравнению с полным распределением моделей (справа) ни в исходном, ни в нормированном по весу внимании.
В целом похоже, что подсети супер-выживших состоят преимущественно из потенциально значимых паттернов самонаблюдения. Этот результат контрастирует с предыдущим отчётом о проходах самонаблюдения, которые выполняют «тяжёлую работу»; тем не менее в двух исследованиях исследуются разные архитектуры (BERT сравнивается с полным трансформером), и они полагаются на разные методы обрезки и интерпретации проходов самонаблюдения.
Заключение
Как наше исследование, так и параллельная работа (Chen et al., 2020) подтверждают, что гипотеза лотерейного билета верна при использовании обрезки по величине в BERT: «хорошие» подсети могут быть переобучены для достижения полной производительности модели.
Структурированная обрезка рассказала нам о другом: мы обнаружили, что обрезка большинства подсетей BERT этим методом приводит к аналогичной производительности между «хорошими», «случайными» и «плохими» сетями и что ни одна из них не может достичь полной производительности исходной сети. Таким образом, можно сказать, что при структурированной обрезке BERT не имеет «проигрышных» билетов, даже если он не полностью «выигрывает».
Кроме того, наши эксперименты показывают, что высокая производительность BERT, похоже, не является результатом специальных лингвистических знаний, уникальным образом закодированных в предварительно подготовленных весах конкретных компонентов BERT (проходов самонаблюдения и MLP): иначе «хорошие» подсети были бы стабильны при случайной инициализации. Они также нестабильны во всех задачах GLUE, а «хорошие» подсети для задач одного типа не обязательно имеют больше общего. Наконец, даже те проходы самонаблюдения, которые выживают наибольшим постоянством, преимущественно не имеют тех моделей самонаблюдения, которые потенциально могут быть интерпретированы.
Всё это означает, что теперь у нас ещё больше вопросов, чем ответов о том, как BERT достигает замечательных результатов. Если так много важных проходов самонаблюдения даже потенциально не интерпретируются, стоит ли нам отказаться от идеи, что некоторые знания кодируются в конкретных компонентах архитектуры, а не распространяются по всей сети? Как изучать такие распределённые представления? Приписать ли в целом высокую производительность GLUE знаниях о языке в BERT или артефактам наборов данных? Ожидать ли, что они будут проявляться так же, как и в весах самонаблюдения? Речь вообще идёт о кодировании лингвистических знаний, или, возможно, это в большей степени связано с соответствием между инициализацией специфического для конкретной задачи слоя и оптимизационной поверхностью предварительно подготовленных весов? Результаты LSTM свидетельствуют о том, что для выполнения лингвистических задач может быть полезным нелингвистическое предварительное обучение.
Единственное, что мы знаем наверняка, – это то, что исследования в BERTology ещё далеки до завершения.
- Brunner, Gino, Yang Liu, Damián Pascual, Oliver Richter, and Roger Wattenhofer. 2019. On the Validity of Self-Attention as Explanation in Transformer Models. On the Validity of Self-Attention as Explanation in Transformer Models.
- Chen, Tianlong, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. 2020. The Lottery Ticket Hypothesis for Pre-Trained BERT Networks.
- Clark, Kevin, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 276–86.
- Dodge, Jesse, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.
- Ettinger, Allyson. 2020. What BERT Is Not: Lessons from a New Suite of Psycholinguistic Diagnostics for Language Models.
- Frankle, Jonathan, and Michael Carbin. 2019. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.
- Geva, Mor, Yoav Goldberg, and Jonathan Berant. 2019. Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets.
- Goldberg, Yoav. 2019. Assessing BERT’s Syntactic Abilities.
- Gururangan, Suchin, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith. 2018. Annotation Artifacts in Natural Language Inference Data.
- Hewitt, John, and Christopher D. Manning. 2019. A Structural Probe for Finding Syntax in Word Representations.
- Htut, Phu Mon, Jason Phang, Shikha Bordia, and Samuel R. Bowman. 2019. Do Attention Heads in BERT Track Syntactic Dependencies?
- Jain, Sarthak, and Byron C. Wallace. 2019. Attention Is Not Explanation.
- Jin, Di, Zhijing Jin, Joey Tianyi Zhou, and Peter Szolovits. 2020. Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment.
- Kobayashi, Goro, Tatsuki Kuribayashi, Sho Yokoi, and Kentaro Inui. 2020. Attention Module Is Not Only a Weight: Analyzing Transformers with Vector Norms.
- Kovaleva, Olga, Alexey Romanov, Anna Rogers, and Anna Rumshisky. 2019. Revealing the Dark Secrets of BERT.
- Liu, Nelson F., Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. Linguistic Knowledge and Transferability of Contextual Representations.
- McCoy, R. Thomas, Junghyun Min, and Tal Linzen. 2019. BERTs of a Feather Do Not Generalize Together: Large Variability in Generalization Across Models with Similar Test Set Performance.
- McCoy, Tom, Ellie Pavlick, and Tal Linzen. 2019. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference.
- Michel, Paul, Omer Levy, and Graham Neubig. 2019. Are Sixteen Heads Really Better Than One?
- Papadimitriou, Isabel, and Dan Jurafsky. 2020. Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models.
- Rogers, Anna, Olga Kovaleva, Matthew Downey, and Anna Rumshisky. 2020. Getting Closer to AI Complete Question Answering: A Set of Prerequisite Real Tasks.
- Rogers, Anna, Olga Kovaleva, and Anna Rumshisky. 2020. A Primer in BERTology: What We Know About How BERT Works.
- Sugawara, Saku, Kentaro Inui, Satoshi Sekine, and Akiko Aizawa. 2018. What Makes Reading Comprehension Questions Easier?
- Tenney, Ian, Dipanjan Das, and Ellie Pavlick. 2019. BERT Rediscovers the Classical NLP Pipeline.
- Voita, Elena, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. 2019. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned.
- Wang, Alex, Amapreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.
- Wiegreffe, Sarah, and Yuval Pinter. 2019. Attention Is Not Not Explanation.

- Профессия Data Scientist
- Профессия Data Analyst
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по Data Engineering
- Курс «Python для веб-разработки»
- Курс «Алгоритмы и структуры данных»
- Курс по аналитике данных
- Курс по DevOps


