
Привет, я Никита Брижак, серверный разработчик из Pixonic. Сегодня я хотел бы поговорить о компенсации лагов в мобильном мультиплеере.
Про серверную лагкомпенсацию написано много статей, в том числе на русском языке. В этом нет ничего удивительного, ведь эта технология активно используется при создании многопользовательских FPS еще с конца 90-ых. Например, можно вспомнить мод QuakeWorld, прибегнувший к ней одним из первых.
Используем ее и мы в своем мобильном мультиплеерном шутере Dino Squad.
В этой статье моя цель ― не повторить то, что было написано уже тысячу раз, но рассказать, как мы внедряли лагкомпенсацию в нашу игру с учетом нашего технологического стэка и особенностей кор-геймплея.
В паре слов о нашем коре и технологиях.
Dino Squad ― сетевой мобильный PvP-шутер. Игроки управляют динозаврами, обвешанными разнообразным вооружением, и сражаются друг с другом командами 6 на 6.
И клиент, и сервер у нас на Unity. Архитектура довольно классическая для шутеров: сервер ― авторитарный, а на клиентах работает клиентское предсказание. Игровая симуляция написана с использованием in-house ECS и используется как на сервере, так и на клиенте.
Если вы впервые услышали про лагокомпенсацию, вот краткий экскурс в проблематику.
В многопользовательских FPS-играх матч, как правило, симулируется на удаленном сервере. Игроки отправляют на сервер свой инпут (информацию о нажатых клавишах), а в ответ сервер присылает им обновленное состояние игры с учетом полученных данных. При такой схеме взаимодействия задержка между нажатием на клавишу «вперед» и тем моментом, когда персонаж игрока на экране сдвинется с места, всегда будет больше пинга.
Если на локальных сетях эта задержка (в народе именуемая input lag) может быть незаметна, то при игре через интернет она создает ощущение «скольжения по льду» при управлении персонажем. Эта проблема вдвойне актуальна для мобильных сетей, где случай, когда у игрока пинг составляет 200 мс, считается еще отличным соединением. Часто пинг бывает и 350, и 500, и 1000 мс. Тогда уже играть с инпут лагом в быстрый шутер становится практически невозможно.
Решением этой проблемы становится предсказание симуляции на стороне клиента. Здесь клиент сам применяет инпут к персонажу игрока, не дожидаясь ответа от сервера. А когда ответ получен, просто сверяет результаты и обновляет позиции противников. Задержка между нажатием на клавишу и отображением результата на экране в этом случае минимальна.
Тут важно понимать нюанс: себя клиент всегда рисует по последнему своему инпуту, а врагов ― с сетевой задержкой, по прежнему состоянию из данных с сервера. То есть, стреляя в противника, игрок видит его в прошлом относительно себя. Подробнее про клиентское предсказание мы писали ранее.
Таким образом клиентское предсказание решает одну проблему, но создает другую: если игрок стреляет в ту точку, где противник находился в прошлом, на сервере при выстреле в эту же точку противника в том месте может уже и не оказаться. Серверная лагкомпенсация пытается решить эту проблему. При выстреле из оружия сервер восстанавливает то состояние игры, которое видел игрок в момент выстрела локально, и проверяет, действительно ли он мог попасть в противника. Если ответ «да», попадание засчитывается, даже если противника в этой точке на сервере уже нет.
Вооружившись этими знаниями, мы начали внедрять серверную лагкомпенсацию в Dino Squad. Прежде всего предстояло понять, как вообще восстановить на сервере то, что видел клиент? И что конкретно нужно восстанавливать? В нашей игре попадания оружия и способностей рассчитываются через рейкасты и оверлапы ― то есть, через взаимодействия с физическими коллайдерами противника. Соответственно, то положение этих коллайдеров, которое «видел» игрок локально, нам и требовалось воспроизвести на сервере. На тот момент мы использовали Unity версии 2018.x. API физики там статический, физический мир существует в единственном экземпляре. Возможности сохранить его состояние, чтобы потом его восстановить из коробки, нет. Так что же делать?
Решение было на поверхности, все его элементы уже нами использовались для решения других задач:
- Про каждого клиента нам нужно знать, в каком времени он видел противников, когда нажимал на клавиши. Мы уже писали эту информацию в пакет инпута и использовали ее для корректировки работы клиентского предсказания.
- Нам нужно уметь хранить историю состояний игры. Именно в ней мы будем держать позиции противников (а значит, и их коллайдеров). На сервере история состояний у нас уже была, мы использовали ее для построения дельт. Зная нужное время, мы легко могли бы найти нужное состояние в истории.
- Теперь, когда у нас на руках есть состояние игры из истории, нам нужно уметь синхронизировать данные об игроках с состоянием физического мира. Существующие коллайдеры ― передвинуть, недостающие ― создать, лишние ― уничтожить. Эта логика у нас тоже уже была написана и состояла из нескольких ECS систем. Использовали мы ее для того, чтобы держать несколько игровых комнат в одном Unity-процессе. И поскольку физический мир ― один на процесс, его приходилось переиспользовать между комнатами. Перед каждым тиком симуляции мы «сбрасывали» состояние физического мира и заново инициализировали его данными для текущей комнаты, пытаясь по максимуму переиспользовать игровые объекты Unity через хитрую систему пулов. Оставалось вызвать эту же логику для игрового состояния из прошлого.
Собрав все эти элементы вместе, мы получили «машину времени», которая умела откатывать состояние физического мира до нужного момента. Код получился незамысловатый:
public class TimeMachine : ITimeMachine
{
//История игровых состояний
private readonly IGameStateHistory _history;
//Текущее игровое состояние на сервере
private readonly ExecutableSystem[] _systems;
//Набор систем, расставляющих коллайдеры в физическом мире
//по данным из игрового состояния
private readonly GameState _presentState;
public TimeMachine(IGameStateHistory history, GameState presentState, ExecutableSystem[] timeInitSystems)
{
_history = history;
_presentState = presentState;
_systems = timeInitSystems;
}
public GameState TravelToTime(int tick)
{
var pastState = tick == _presentState.Time ? _presentState : _history.Get(tick);
foreach (var system in _systems)
{
system.Execute(pastState);
}
return pastState;
}
}Оставалось понять, как использовать эту машину для лагкомпенсации выстрелов и способностей.
В простейшем случае, когда механики построены на одиночном хитскане, вроде все понятно: перед выстрелом игрока нужно откатить физический мир до нужного состояния, сделать рейкаст, засчитать попадание или промах и вернуть мир в начальное состояние.
Но в Dino Squad таких механик очень мало! Большая часть оружия в игре создает проджектайлы ― долгоживущие пули, которые летят несколько тиков симуляции (в некоторых случаях ― десятки тиков). Как быть с ними, в каком времени они должны лететь?
В древней статье про сетевой стек Half-Life ребята из Valve задавались тем же вопросом, и их ответ был такой: лагкомпенсация проджектайлов проблематична, и лучше ее избегать.
У нас этой опции не было: оружие, основанное на проджектайлах, было ключевой особенностью игрового дизайна. Поэтому нам пришлось что-то придумывать. Немного побрейнштормив, мы сформулировали два варианта, которые нам показались рабочими:
1. Мы привязываем проджектайл ко времени того игрока, который его создал. Каждый тик серверной симуляции для каждой пули каждого игрока мы откатываем физический мир до клиентского состояния и производим необходимые вычисления. Такой подход позволял иметь распределенную нагрузку на сервер и предсказуемое время полета проджектайлов. Предсказуемость для нас была особенно важна, поскольку у нас все проджектайлы, включая проджектайлы противников, предсказываются на клиенте.

На картинке игрок в 30-ом тике стреляет ракетой на упреждение: он видит, в каком направлении бежит противник, и знает примерную скорость ракеты. Локально он видит, что попал в цель в 33-ем тике. Благодаря лагкомпенсации попадет он и на сервере
2. Мы делаем все то же самое, что и в первом варианте, но, посчитав один тик симуляции пули, не останавливаемся, а продолжаем симулировать ее полет в рамках того же серверного тика, каждый раз приближая ее время к серверному на один тик и обновляя позиции коллайдеров. Делаем мы это до тех пор, пока не случится одно из двух:
- Срок жизни пули истек. Это означает, что вычисления окончены, мы можем засчитать промах или попадание. И это в тот же тик, в который был совершен выстрел! Для нас это было и плюсом, и минусом. Плюсом ― поскольку для стреляющего игрока это существенно уменьшало задержку между попаданием и уменьшением здоровья врага. Минусом ― поскольку такой же эффект наблюдался при стрельбе противников по игроку: противник, казалось бы, только выстрелил медленной ракетой, а урон уже засчитали.
- Пуля достигла серверного времени. В этом случае ее симуляция продолжится в следующем серверном тике уже без лагкомпенсации. Для медленных проджектайлов это теоретически могло бы сократить число «откатов» физики по сравнению с первым вариантом. В то же время возрастала неравномерность нагрузки на симуляцию: сервер то простаивал, то за один серверный тик просчитывал десяток тиков симуляции для нескольких пуль.
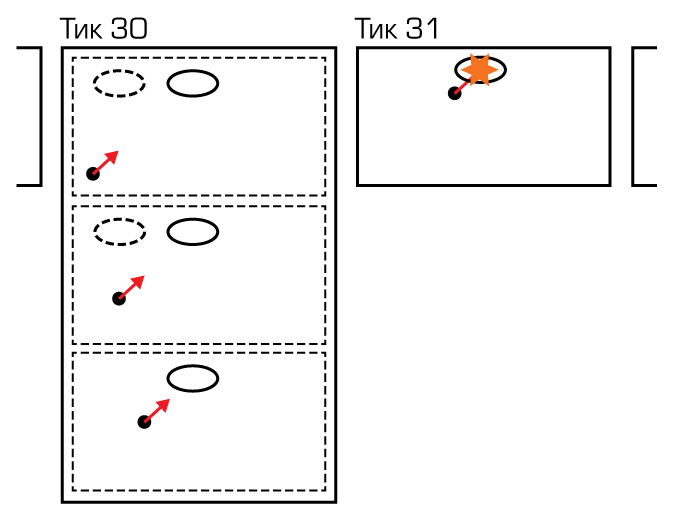
Тот же сценарий, что и на предыдущей картинке, но посчитанный по второй схеме. Ракета «догнала» серверное время в том же тике, что произошел выстрел, и попадание можно засчитать уже на следующий тик. В 31-ом тике в данном случае лагкомпенсация уже не применяется
В нашей реализации эти два подхода отличались буквально парой строчек кода, поэтому запилили мы оба, и долгое время они у нас существовали параллельно. В зависимости от механики оружия и скорости полета пули мы выбирали тот или иной вариант для каждого динозавра. Переломным моментом тут стало появление в игре механик типа «если ты попал столько-то раз по врагу за такое-то время, получи такой-то бонус». Любая механика, где время, в которое игрок попал по врагу, имело важную роль, отказывалась дружить со вторым подходом. Поэтому в итоге мы остановились на первом варианте, и сейчас он применяется для всего оружия и всех активных способностей в игре.
Отдельно стоит поднять вопрос производительности. Если вам показалось, что все это будет тормозить, отвечаю: так оно и есть. Перемещение коллайдеров, их включение и выключение Unity делает довольно медленно. В Dino Squad в «худшем» случае в бою может одновременно существовать несколько сотен проджектайлов. Двигать коллайдеры, чтобы посчитать каждый проджектайлов по отдельности, ― непозволительная роскошь. Поэтому нам было совершенно необходимо минимизировать число «откатов» физики. Для этого мы создали отдельный компонент в ECS, в который мы записываем время игрока. Его мы повесили на все энтити, требующие лагкомпенсации (проджектайлы, способности и т. д.). Перед тем, как начать обработку таких энтитей, мы кластеризуем их по этому времени и обрабатываем их вместе, откатывая физический мир один раз для каждого кластера.
На этом этапе мы получили в целом рабочую систему. Ее код в несколько упрощенном виде:
public sealed class LagCompensationSystemGroup : ExecutableSystem
{
//Машина времени
private readonly ITimeMachine _timeMachine;
//Набор систем лагкомпенсации
private readonly LagCompensationSystem[] _systems;
//Наша реализация кластеризатора
private readonly TimeTravelMap _travelMap = new TimeTravelMap();
public LagCompensationSystemGroup(ITimeMachine timeMachine,
LagCompensationSystem[] lagCompensationSystems)
{
_timeMachine = timeMachine;
_systems = lagCompensationSystems;
}
public override void Execute(GameState gs)
{
//На вход кластеризатор принимает текущее игровое состояние,
//а на выход выдает набор «корзин». В каждой корзине лежат энтити,
//которым для лагкомпенсации нужно одно и то же время из истории.
var buckets = _travelMap.RefillBuckets(gs);
for (int bucketIndex = 0; bucketIndex < buckets.Count; bucketIndex++)
{
ProcessBucket(gs, buckets[bucketIndex]);
}
//В конце лагкомпенсации мы восстанавливаем физический мир
//в исходное состояние
_timeMachine.TravelToTime(gs.Time);
}
private void ProcessBucket(GameState presentState, TimeTravelMap.Bucket bucket)
{
//Откатываем время один раз для каждой корзины
var pastState = _timeMachine.TravelToTime(bucket.Time);
foreach (var system in _systems)
{
system.PastState = pastState;
system.PresentState = presentState;
foreach (var entity in bucket)
{
system.Execute(entity);
}
}
}
}Оставалось только настроить детали:
1. Понять, насколько сильно ограничивать максимальную дальность перемещения во времени.
Для нас было важно сделать игру максимально доступной в условиях плохих мобильных сетей, поэтому мы ограничили историю с запасом ― 30-ю тиками (при тикрейте в 20 гц). Это позволяет игрокам попадать в противников даже на очень высоких пингах.
2. Определить, какие объекты можно перемещать во времени, а какие нет.
Противников мы, понятно, перемещаем. А вот устанавливаемые энергетические щиты, например, нет. Мы решили, что тут лучше отдать приоритет защитной способности, как часто поступают в сетевых шутерах. Если уж игрок поставил щит в настоящем, лагкомпенсируемые пули из прошлого не должны пролетать сквозь него.
3. Решить, нужно ли лагкомпенсировать способности динозавров: укус, удар хвостом и т. п. Мы решили, что нужно, и обрабатываем их по тем же правилам, что и пули.
4. Определить, что делать с коллайдерами игрока, для которого выполняется лагкомпенсация. По-хорошему, их позиция не должна смещаться в прошлое: игрок должен видеть себя в том же времени, в котором он находится сейчас на сервере. Тем не менее, коллайдеры стреляющего игрока мы тоже откатываем, и на то есть несколько причин.
Во-первых, это улучшает кластеризацию: мы можем использовать одно и то же физическое состояние для всех игроков с близким пингом.
Во-вторых, во всех рейкастах и оверлапах мы и так всегда исключаем коллайдеры игрока, которому принадлежат способности или проджектайлы. В Dino Squad игроки управляют динозаврами, у которых достаточно нестандартная по меркам шутеров геометрия. Даже если игрок стреляет под необычным углом, и траектория пули проходит через коллайдер динозавра игрока, пуля его проигнорирует.
В-третьих, позиции оружия динозавра или точку применения способности мы вычисляем по данным из ECS еще до начала лагкомпенсации.
В результате реальное положение коллайдеров лагкомпенсируемого игрока для нас несущественно, поэтому мы пошли по более производительному и в то же время более простому пути.
Сетевую задержку нельзя просто убрать, ее можно только замаскировать. Как и любой другой способ маскировки, серверная лагкомпенсация имеет свои трейдоффы. Она улучшает игровой опыт стреляющего игрока за счет того игрока, в которого стреляют. Для Dino Squad, впрочем, выбор здесь был очевиден.
Конечно, заплатить за это все пришлось еще и возросшей сложностью серверного кода в целом ― как для программистов, так и для геймдизайнеров. Если раньше симуляция представляла из себя простой последовательный вызов систем, то с лагкомпенсацией в ней появились вложенные циклы и ветвления. На то, чтобы с ней можно было удобно работать, мы тоже потратили немало сил.
В 2019 версии (а может, и чуть раньше), в Unity появилась плюс-минус полноценная поддержка независимых физических сцен. Мы почти сразу после обновления внедрили их на сервере, поскольку хотелось поскорее избавиться от общего для всех комнат физического мира.
Мы выдали каждой игровой комнате по своей физической сцене и таким образом избавились от необходимости «очищать» сцену от данных соседней комнаты перед расчетом симуляции. Во-первых, это дало существенный прирост производительности. Во-вторых, позволило избавиться от целого класса багов, которые возникали в случае, если программист допустил ошибку в коде очистки сцены при добавлении новых игровых элементов. Такие ошибки были трудны в отладке, и они часто приводили к тому, что состояние физических объектов со сцены одной комнаты «перетекало» в другую комнату.
Помимо этого, мы провели небольшое исследование на тему того, можно ли использовать физические сцены для хранения истории физического мира. То есть, условно, выделить каждой комнате не одну сцену, а 30 сцен, и сделать из них циклический буфер, в котором и хранить историю. В целом вариант оказался рабочим, но внедрять мы его не стали: он не показал какого-то сумасшедшего прироста производительности, но требовал довольно рискованных изменений. Сложно было предсказать, как поведет себя сервер при длительной работе с таким количеством сцен. Поэтому мы последовали правилу: «If it ain't broke, don't fix it».


