![[Перевод] Суперкомпьютер на основе Game Boy](https://cdn-images-1.medium.com/max/1000/1*B4symXkzExzOMlfqVPoA3w.gif "[Перевод] Суперкомпьютер на основе Game Boy")
Распределённый тетрис (1989)
Как построить такой компьютер?
Рецепт
Возьмите горсть кремния, примените обучение с подкреплением, опыт работы с суперкомпьютерами, страсть к компьютерной архитектуре, добавьте пота и слёз, помешивайте 1000 часов, пока не закипит – и вуаля.
Зачем кому-то может понадобиться такой компьютер?
Короче говоря: чтобы двигаться по направлению к усилению искусственного интеллекта.
Одна из 48 плат IBM Neural Computer, использовавшегося для экспериментов
А вот более подробная версия
2016 год. Глубинное обучение повсеместно. Распознавание изображений можно считать решённой задачей благодаря свёрточным нейросетям, и мои исследовательские интересы стремятся к нейросетям с памятью и обучением с подкреплением.
Конкретно, в работе авторства Google Deepmind было показано, что можно достичь уровня человека или даже превзойти его в различных играх для Atari 2600 (домашней игровой консоли, вышедшей в 1977), используя простой алгоритм обучения с подкреплением Deep Q-Neural Network. И всё это происходит просто при просмотре игрового процесса. Это привлекло моё внимание.
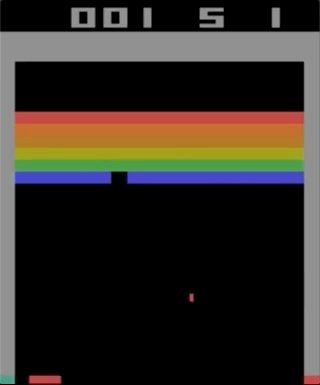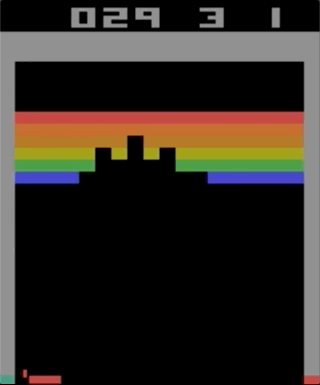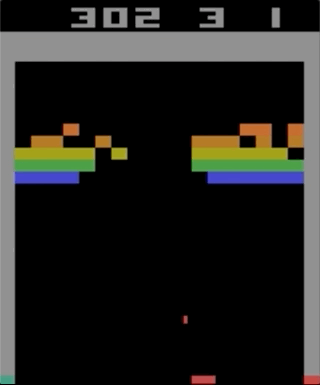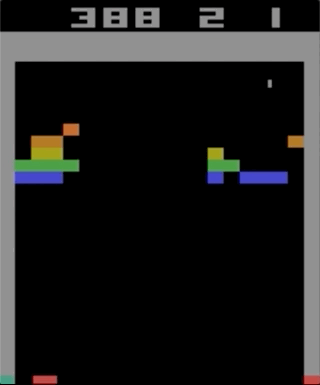
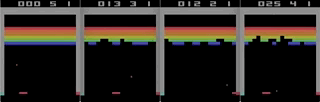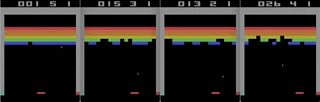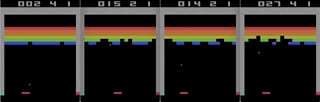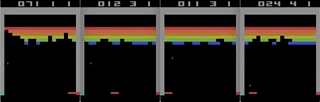
Одна из игр с Atari 2600, Breakout. Машина натренировалась при помощи простого алгоритма обучения с подкреплением. После миллионов итераций компьютер стал играть лучше человека.
Я начал проводить эксперименты с играми Atari 2600. Игру Breakout, пусть она и впечатляющая, нельзя назвать сложной. Сложность можно определить степенью сложности в соответствии ваших действий (джойстик) вашим результатам (очкам). Проблема появляется тогда, когда эффекта нужно ждать довольно долго.
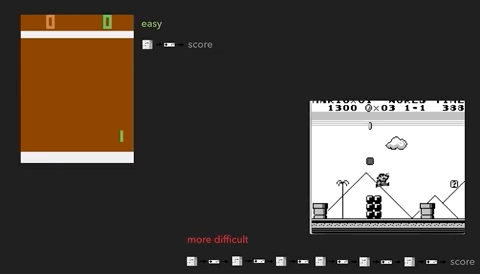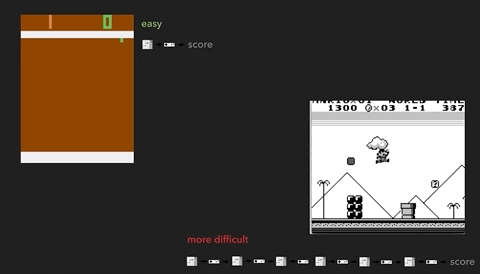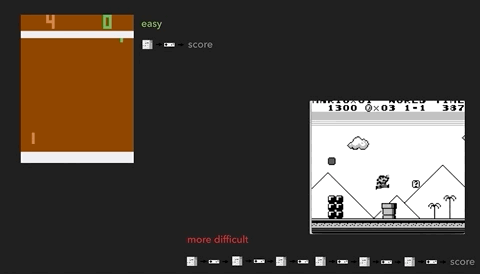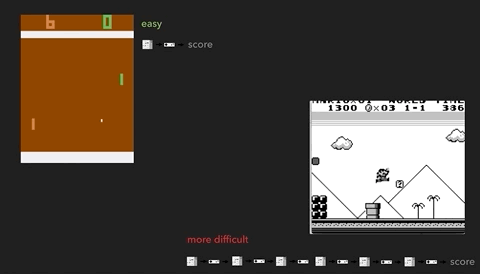
Иллюстрация проблемы на примере более сложных игр. Слева — Breakout (ATARI 2600) [автор ошибся, это игра Pong / прим. перев.] с очень быстрой реакцией и быстрой обратной связью. Справа — Mario Land (Nintendo Game Boy) не даёт мгновенной информации о последствиях действия, между двумя важными событиями могут появляться длительные периоды не относящихся к делу наблюдений.
Чтобы сделать обучение более эффективным, можно представить попытки передать часть знаний из более простых игр. Эта задача сейчас остаётся нерешённой, и представляет собой активную тему для исследований. Недавно опубликованное задание от OpenAI пытается измерить как раз это.
Возможность передачи знаний не только ускорила бы тренировку – я считаю, что некоторые проблемы обучения вообще нельзя решить при отсутствии базовых знаний. Нам требуется эффективность данных. Возьмём игру Prince of Persia:

В ней нет очевидных очков.
Для того, чтобы пройти игру, требуется 60 минут.

Можно ли тут применять тот же подход, что использовался при написании работы по Atari 2600? Насколько вероятно, что можно пройти до конца, нажимая случайные клавиши?
Этот вопрос подвигнул меня на вклад в сообщество, заключающийся в попытке решить эту задачу. По сути, у нас есть задача курицы и яйца – нам нужен алгоритм получше, который позволит нам передавать сообщение, однако для этого нужны исследования, а эксперименты отнимают много времени, поскольку у нас нет более эффективного алгоритма.

Пример передачи знаний: представьте, что сначала мы научились играть в простую игру, такую, как слева. Затем мы сохраняем такие концепции, как «гонка», «машина», «трасса», «выигрыш» и обучаемся цветам или трёхмерным моделям. Мы утверждаем, что общие концепции можно «переносить» между играми. Сходство игр можно определять по количеству переносимых между ними знаний. К примеру, игры «Тетрис» и F1 не будут похожими.
Поэтому я решил использовать второй по идеальности подход, избежав изначального замедления, кардинально ускорив систему. Моими целями были:
— ускоренное окружение (представьте, что Prince of Persia можно пройти в 100 раз быстрее) и одновременный запуск 100 000 игр.
— окружение, более подходящее для исследований (концентрируемся на задачах, но не на предварительных расчётах, имеем доступ к различным играм).
Изначально я считал, что узкое место, связанное с быстродействием, может как-то зависеть от сложности кода эмулятора (к примеру, база кода Stella большая, к тому же, она полагается на абстракции С++ — не лучший выбор для эмуляторов).
Консоли

Я в сумме работал на нескольких платформах, начиная с одной из самых первых игр из когда-либо созданных (вместе с игрой Pong) – аркадой Space Invaders, Atari 2600, NES и Game Boy. И всё это было написано на С.
Я сумел достичь максимальной частоты кадров в 2000-3000 в секунду. Чтобы начать получать результаты экспериментов, нам нужны миллионы или миллиарды кадров, поэтому разрыв был огромным.

Space Invaders, работающие в FPGA – режим отладки с низкой скоростью. Счётчик на FPGA показывает количество прошедших тактовых импульсов.
А потом я подумал – что, если бы мы могли ускорить нужное окружение при помощи железа. К примеру, оригинальные Space Invaders шли на 8080 CPU с частотой 1 МГц. Мне удалось эмулировать 8080 CPU частоты 40 МГц на процессоре Xeon частоты 3 ГГц. Неплохо, но после того, как я разместил всё это внутри FPGA, частота поднялась до 400 МГц. Это означало 24000 FPS от одного потока – эквивалент Xeon частоты 30 ГГц! А я упоминал, что в средний FPGA можно впихнуть 100 процессоров 8080? Это даёт уже FPS в 2,4 млн.

Space Invaders с хардварным ускорением, 100 МГц, четверть полной скорости
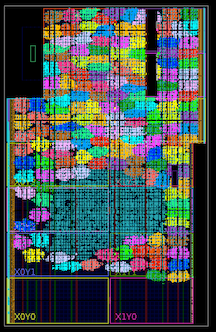
Более сотни ядер внутри Xilinx Kintex 7045 FPGA (обозначены яркими цветами; голубое пятно в середине – это общая логика для демонстрации).
Неровный путь выполнения
Вы можете спросить, а что насчёт GPU? Если кратко, то нам нужен параллелизм типа MIMD, а не SIMD. Студентом я некоторое время работал над реализацией поиска по дереву методом Монте-Карло на GPU (такой поиск использовался в AlphaGo).
В то время я бесчисленное количество часов провёл, пытаясь заставить GPU и другие железки, работающие по принципу SIMD (IBM Cell, Xeon Phi, AVX CPU) выполнять подобный код, и у меня ничего не вышло. Несколько лет назад я начал думать, что было бы неплохо иметь возможность самостоятельно разработать железо, специально предназначенное для решения задач, связанных с обучением с подкреплением.
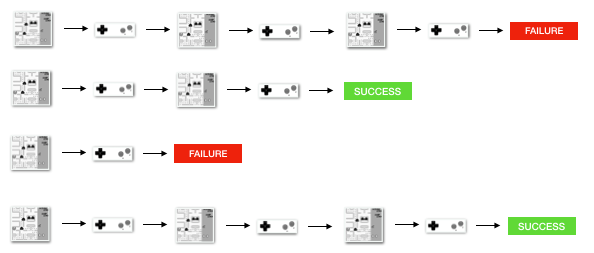
MIMD-параллелизм
ATARI 2600, NES или Game Boy?
На 8080 я реализовал Space Invaders, NES, 2600 и Game Boy. И вот некоторые факты о них и о преимуществах каждого из них.
NES Pacman
Space Invaders были просто разогревом. Нам удалось заставить их работать, но это была лишь одна игра, поэтому результат был не очень полезным.
Atari 2600 – это фактически стандарт в исследованиях обучения с подкреплением. Процессор MOS 6507 представляет собой упрощённую версию знаменитого 6502, его дизайн элегантнее и эффективнее, чем у 8080. Я выбрал 2600 не только из-за определённых ограничений, связанных с играми и с их графикой.
Также я реализовал NES (Nintendo Entertainment System), она делит CPU с 2600. Там игры гораздо лучше, чем на 2600. Но обе консоли страдают от чрезмерно сложного конвейера обработки графики и нескольких форматов картриджей, которые надо поддерживать.
А тем временем я заново открыл Nintendo Game Boy. И это было то, что я искал.
Почему Game Boy такой классный?

1049 классических игр и 576 игр для Game Boy Color
В сумме более 1000 игр, очень большое разнообразие, высокое качество, некоторые из них довольно сложны (Prince), игры можно сгруппировать и назначить сложность для исследований по переносу знания и по обучению (к примеру, есть варианты тетриса, гоночных игр, Mario). Для решения игры Prince of Persia может понадобиться передача знаний от какой-то другой похожей игры, в которой явно указываются очки (в Prince такого нет).
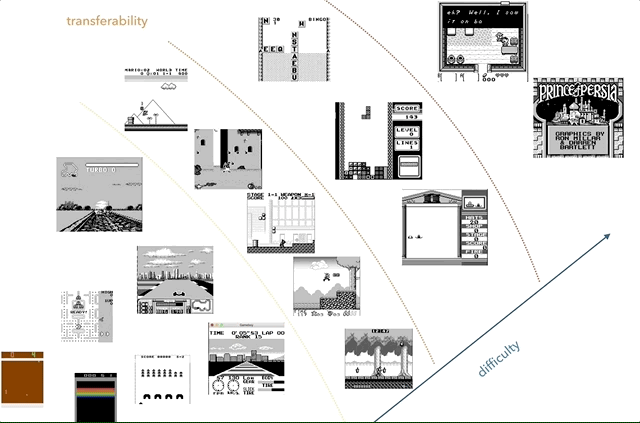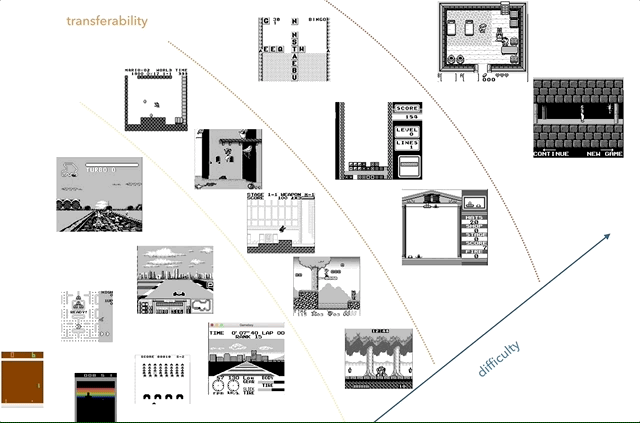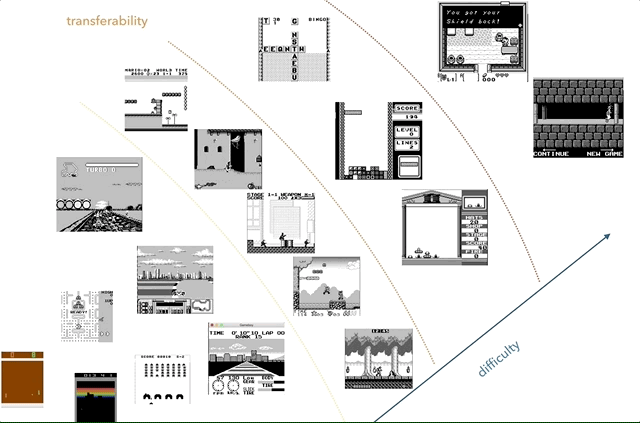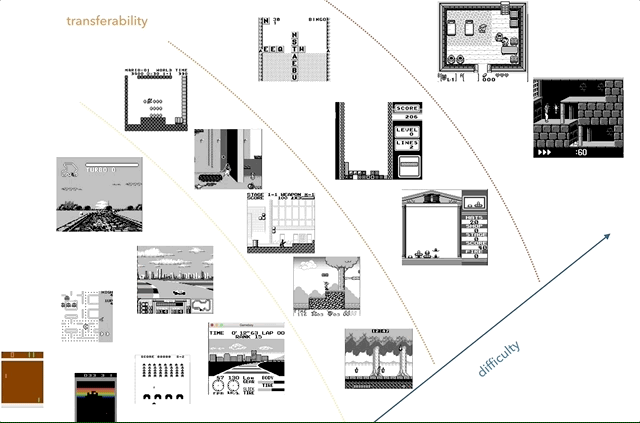
Nintendo Game Boy – моя любимая платформа для исследований по переносу знаний. На графике я попытался сгруппировать игры по сложности (субъективно) и похожести (концепции типа гонок, прыжков, стрельбы, различных игр типа тетриса; кто-нибудь играл в HATRIS?).
У классического Game Boy очень простой экран (160х144, 2-битный цвет), благодаря чему предобработка становится простой, и можно сконцентрироваться на важных вещах. На 2600 даже у простых игр есть много цветов. Кроме того, на Game Boy объекты демонстрируются гораздо лучше, без мигания и без необходимости брать максимум от двух последовательных кадров.

Никакой безумной разметки памяти, как у NES или 2600. Большую часть игр можно заставить работать с 2-3 мапперами.
Компактный код – у меня получилось уместить весь эмулятор на С не более, чем в 700 строк кода, а моя реализация Verilog умещается в 500 строк.
Есть такая же простая версия Space Invaders, как в аркаде.
И вот он, мой Game Boy с точечной матрицей 1989 года и версия для FPGA, работающая через HDMI на экране с разрешением 4К.

А вот, чего не может мой старый Game Boy:
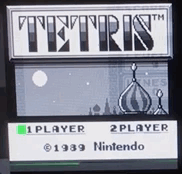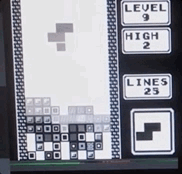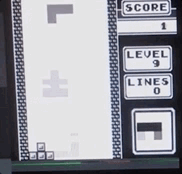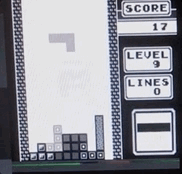
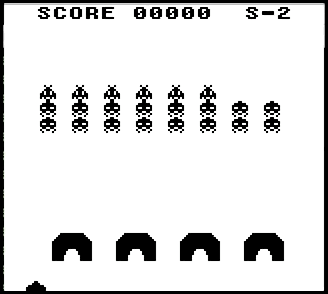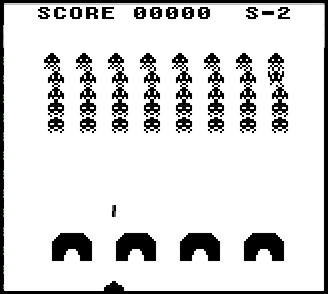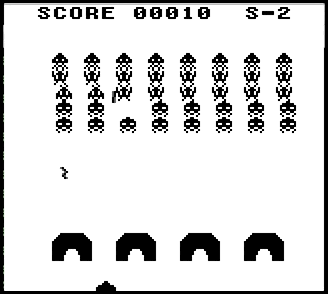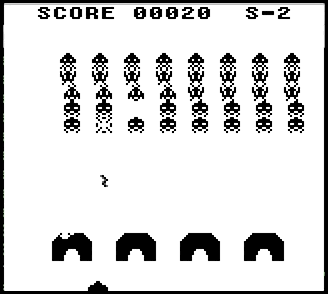
Тетрис, ускоренный при помощи железа – запись с экрана в реальном времени, скорость равна 1/4 от максимальной.
А есть от этого реальная польза?
Да, есть. Пока что я проверял систему в простых условиях, с внешней сетью правил, взаимодействующей с отдельными Game Boy. Конкретнее, я использовал алгоритм A3C (Advantage Actor Critic), и планирую описать его в отдельном посте. Мой коллега подсоединил его к свёрточной сети на FPGA, и он работает.
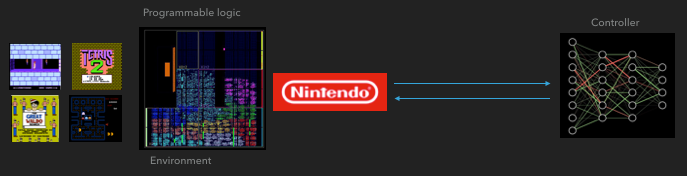
Как FGPA общается с нейросетью
Распределенная A3C
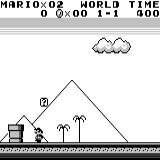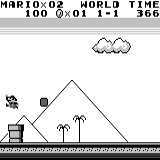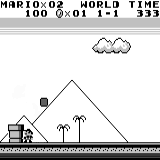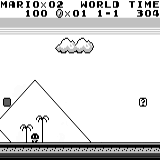
Mario land: начальное состояние. Случайное нажатие на клавиши не сможет увести нас далеко. В правом верхнем углу показано оставшееся время. Если нам повезёт, мы быстро закончим игру после того, как дотронемся до гумбы. Если нет, то на то, чтобы «проиграть», потребуется 400 секунд.
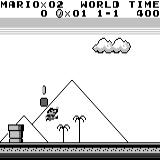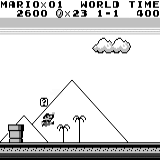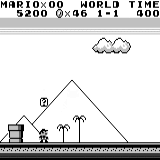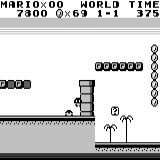
Mario land: после часа игры Марио научился бегать, прыгать и даже открыл тайную комнату, залезши в трубу.
Pac Man: после примерно часовой тренировки нейросеть даже смогла один раз закончить всю игру (съев все точки).
Заключение
Хочется думать, что следующее десятилетие станет периодом, когда суперкомпьютерные вычисления и ИИ найдут друг друга. Мне хотелось бы иметь железо, позволяющее до определённого уровня себя настраивать, чтобы подстраиваться под нужный алгоритм ИИ.
Следующее десятилетие
Отладка
Меня часто спрашивают: что было самым сложным? Всё – весь проект был довольно тягостным. Для начала, нет никакой спецификации для Game Boy. Всё, что мы узнали, мы получили благодаря реверс-инжинирингу, то есть мы запускали промежуточную задачу, например игру, и смотрели, как она выполняется. Это очень отличается от стандартной программной отладки, поскольку тут мы отлаживаем железо, выполняющее программы. Пришлось придумать разные способы для осуществления этого. А я говорил о том, как сложно следить за процессом, когда он выполняется с частотой 100 МГц? А, и никакого printf там нет.
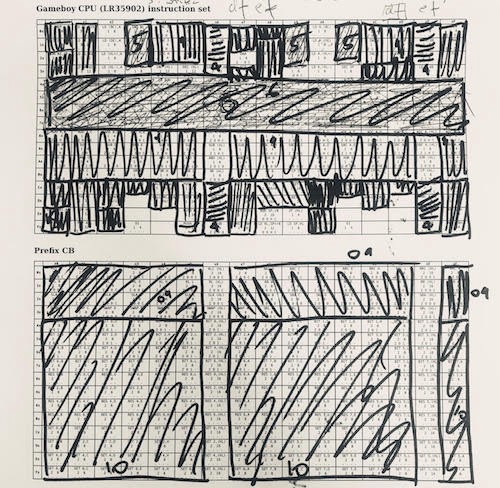
Один подход реализации CPU – сгруппировать инструкции по их функциям. С 6502 это гораздо проще. В LR35092 напихано много всякой «случайной» ерунды и там встречается много исключений. Вот эту таблицу я использовал, работая с CPU Game Boy. Я использовал жадную стратегию – брал самый крупный кусок инструкций, реализовывал их и вычёркивал, затем повторял. 1/4 инструкций это ALU, 1/4 – загрузка регистров, реализовать которую можно довольно быстро. На другой стороне спектра есть всякие отдельные вещи, типа «загрузить из HL в SP со знаком», которые надо было обрабатывать отдельно.
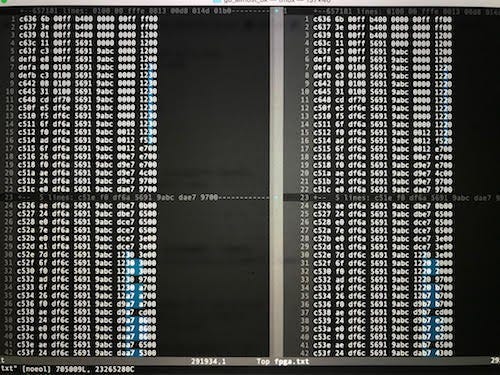
Отладка: запускаете код на железе, которое вы отлаживаете, записываете лог вашей реализации и дополнительной информации (тут показано сравнение кода Verilog слева с моим С-эмулятором справа). Потом запускаете diff для логов, чтобы найти несоответствия (голубые). Одна из причин использования автоматизации – во многих случаях я находил проблемы после миллионов циклов исполнения, когда единственный флажок CPU приводил к эффекту снежного кома. Я пробовал несколько подходов, и этот оказался наиболее эффективным.
Вам потребуется очень много кофе!

Этим книжкам по 40 лет. Удивительно было рыться в них и смотреть на мир компьютеров глазами тогдашних пользователей – я чувствовал себя гостем из будущего.
Запрос на исследования от OpenAI
Сначала я хотел работать с играми с точки зрения памяти, как это описано в посте от OpenAI.
Удивительно, но заставить Q-обучение хорошо работать на входных данных, представляющих собой состояния памяти, было неожиданно трудно.
Этот проект может не иметь решения. Было бы неожиданно узнать, что Q-обучение никогда не добьётся успеха на работе с памятью в Atari, но есть шансы на то, что эта задача окажется довольно трудной.
Учитывая, что игры на Atari использовали всего 128 б памяти, казалось весьма привлекательным обрабатывать эти 128 б вместо полных кадров экрана. У меня получались неоднозначные результаты, поэтому я начал с этим разбираться.
И хотя я не могу доказать, что обучаться на основе памяти невозможно, я могу показать, что предположение о том, что память отображает полное состояние игры, неверно. CPU Atari 2600 (6507) использует 128 б памяти, но у него ещё есть доступ к дополнительным регистрам, живущим на отдельном контуре (TIA, адаптер для телевизора, что-то вроде GPU). Эти регистры используются для хранения и обработки информации об объектах (ракетка, ракета, мяч, столкновения). Иначе говоря, они будут недоступны, если рассматривать только память. Также и у NES и Game Boy есть дополнительные регистры, которые используются для управления экраном и прокруткой. Только одна память не отражает полного состояния игры.
Только 8080 впрямую хранит данные в видеопамяти, что позволит вам извлечь полное состояние игры. В других случаях регистры «GPU» подключаются между CPU и экранным буфером, находясь вне RAM.
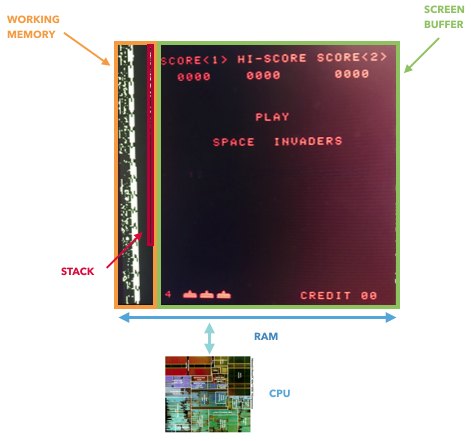
Интересный факт: если вы проводите исследования истории GPU, то 8080 может оказаться первым «графическим ускорителем» – у него есть внешний регистр сдвига, позволяющий подвинуть космических захватчиков при помощи одной команды, что разгружает CPU.

EOF
Источник


