Наверное вы слышали о том, что возможности современных ботов для компьютерных игр превышают человеческие. Такие боты могут быть жёстко запрограммированными, всегда одинаково реагирующими на одни и те же наборы входных данных. Ещё один подход к их разработке заключается в том, что им позволяют учиться и эволюционировать. Они по-разному ведут себя в одних и тех же ситуациях в попытках найти оптимальные решения встающих перед ними проблем.
![[Перевод] Почему машина может нечеловечески хорошо играть в Mario, но не в Pokemon?](https://habrastorage.org/webt/d5/gv/pu/d5gvpucjbsaf_ln4hyy7yg86-e8.jpeg "[Перевод] Почему машина может нечеловечески хорошо играть в Mario, но не в Pokemon?")
Вот несколько известных примеров таких ботов:
- AlphaZero — шахматный бот, который, после 24-х часового обучения, стал величайшим игроком на Земле.
- AlphaGo — программа, которая обыграла в Go Ли Седоля и Кэ Цзе.
- MarI/O — бот для Super Mario, который самостоятельно обучается, стремясь как можно быстрее проходить уровни игры.
Шахматы, го, Super Mario — непростые игры, боты представляют собой разумно подобранные комбинации алгоритмов, на их обучение нужно немало времени.
Этот материал посвящён анализу бота MarI/O и рассказу о том, почему подход, использованный при создании этого бота, не поможет написать программу, которая сможет хорошо играть в Pokemon.
В чём разница между Mario и Pokemon?
Между играми Mario и Pokemon существуют три ключевых отличия, которые и определяют возможный успех ботов:
- Количество целей.
- Коэффициент ветвления.
- Противоречие между глобальной и локальной оптимизацией
Сравним игры с учётом этих факторов.
Количество целей
Машины обучаются, оптимизируя некую целевую функцию. Это может быть максимизация функции вознаграждения или функции приспособленности (при обучении с подкреплением и при использовании генетических алгоритмов), это может быть минимизация функции потерь (при обучении с учителем). В любом случае, если говорить о применении к игре, речь идёт о наборе максимально возможного количества очков.
В игре Mario есть одна цель: дойти до конца уровня. Проще говоря, чем дальше удалось продвинуться в игре — тем лучше. Этот показатель выражает единственная целевая функция, и возможности модели могут быть оценены, просто и понятно, по единственному показателю.
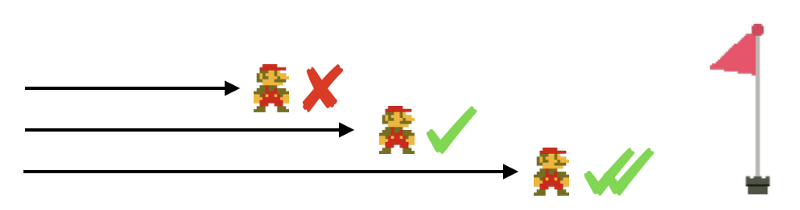
Цель игры Mario
А вот в Pokemon много целей. Попробуем их выяснить. Может быть, цель игры заключается в том, чтобы победить элитную четвёрку? Может это — поимка всех покемонов? А может — нужно натренировать самую сильную команду? Возможно, что цель игры является некоей комбинацией всех предыдущих целей или даже чем-то совершенно другим. Вполне вероятно, что в реальности, если спросить об этом конкретного игрока, его цель будет представлена в виде сложной комбинации множества достижений, доступных в игре.
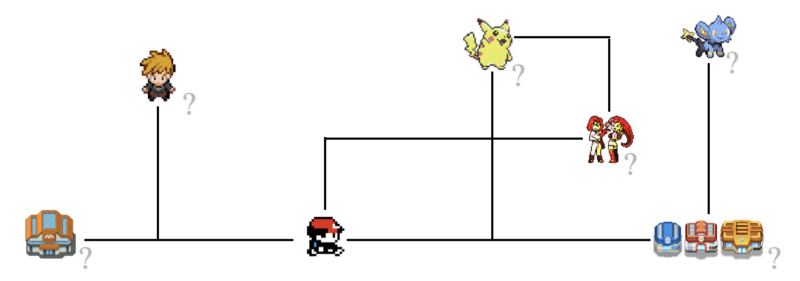
Цели игры Pokemon
Анализируя игру, нужно не только определить её конечную цель, но и решить, как именно происходит продвижение в игре, как некие действия влияют на целевую функцию, ухудшая её или улучшая в зависимости от огромного множества вариантов действий, доступных игроку в отдельно взятый момент времени.
Собственно говоря, выбор варианта действия в некоей ситуации приводит нас ко второму показателю сравнения игр.
Коэффициент ветвления
Коэффициент ветвления — это, если говорить простыми словами, показатель, указывающий на число вариантов действий, доступных на каждом шаге игрового процесса. В шахматах средний коэффициент ветвления — 35. В го — 250. Если бот пытается «заглянуть в будущее», просчитав методом полного перебора все ходы, которые он может совершить прямо сейчас, а потом — все ходы, которые он может совершить после выполнения текущего хода, и так далее, то каждый такой уровень означает серьёзный рост сложности задачи. А именно, число вариантов при таком подходе растёт экспоненциально, выражаясь формулой вида (коэффициент ветвления)^(число уровней).
В Mario персонаж может двигаться влево или вправо, может прыгать и может просто ничего не делать. Число вариантов действий, которые нужно оценить боту, невелико. Чем меньше коэффициент ветвления — тем дальше в будущее бот может заглянуть, затратив на это приемлемые вычислительные ресурсы.
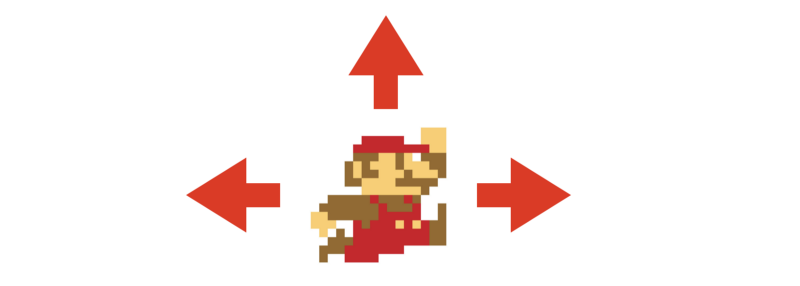
Варианты действий в Mario
В Pokemon открытый игровой мир. Это означает, что в каждый конкретный момент времени у игрока много вариантов действий. При этом простое перечисление направлений возможного перемещения персонажа в данном случае не подходит для вычисления коэффициента ветвления. Вместо этого роль играют некие действия, имеющие в игровом мире какой-то смысл. Будет ли следующим действием бой, разговор с игровым персонажем, переход в другую область карты? При этом число вариантов выбора, по мере продвижения по игре, растёт.
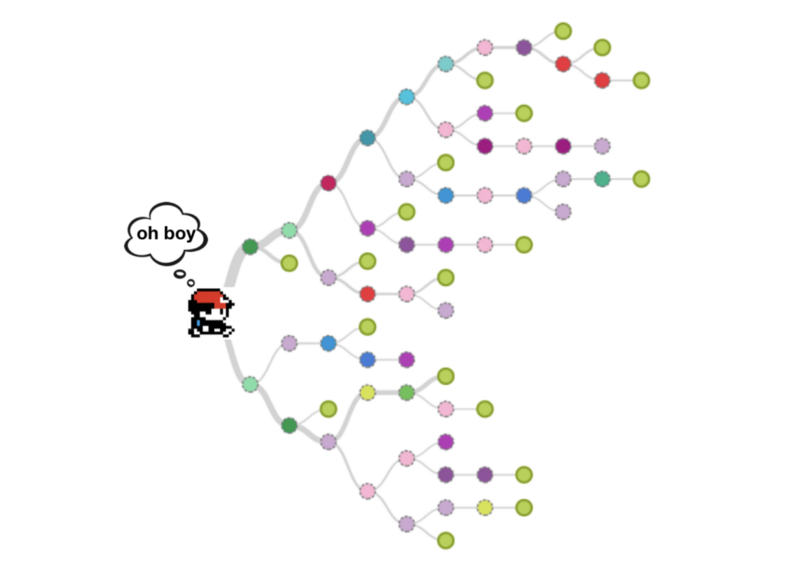
Упрощённое представление вариантов действий персонажа в Pokemon
Для того чтобы создать бота, который мог бы выяснить, какую последовательность решений нужно принять в подобной ситуации, нужно чтобы этот бот учитывал бы свои краткосрочные и долгосрочные цели, что ведёт нас к следующему измерению сравнения игр Mario и Pokemon.
Противоречие между глобальной и локальной оптимизацией
Локальную и глобальную оптимизацию можно рассматривать как в пространственном, так и во временном смысле. Краткосрочные цели и окружающее игрового персонажа пространство небольшой площади имеют отношение к локальной оптимизации. Долгосрочные цели и сравнительно большие фрагменты игрового пространства (нечто вроде «города» или всего игрового мира) относятся к глобальной оптимизации.
Если, в Pokemon, разбить каждый ход на составные части — это поможет представить проблему, которую предстоит решить боту, состоящей из очень маленьких фрагментов. Локальная оптимизация, позволяющая, скажем, попасть из точки A в точку B, сложностей не вызовет. Гораздо более сложная проблема заключается в выборе точки B, направления движения. Жадные алгоритмы тут нам не помогут, так как локально оптимальные решения необязательно ведут к глобально оптимальным результатам.
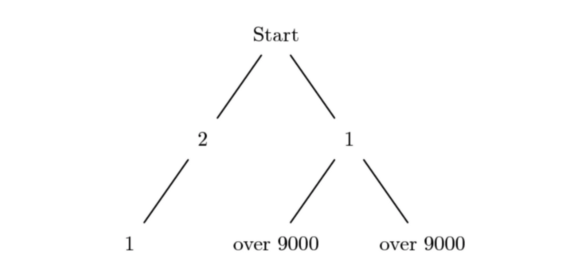
Проблема выбора следующего шага
Карты в Mario невелики и отличаются линейностью. Карты в Pokemon имеют большие размеры, они сложны и нелинейны. Перед игроком, по мере продвижения по игре и по мере того, как он преследует всё более важные цели, постоянно встают новые задачи. А задача организации связи локальных оптимизаций с глобальными целями непроста. По крайней мере, существующие модели пока не готовы её решить.
Итоги
С точки зрения ботов Pokemon — это не одна игра. Боты отличаются узкой специализацией, и бот, который помогает игроку передвигаться по карте, окажется бесполезным, если игрок встретит игрового персонажа, с которым нужно вступить в бой. С точки зрения ботов перемещения по карте и битвы — это совершенно разные задачи.

Боты — это узкоспециализированные системы
Во время боя на каждом шаге приходится выбирать из десятков вариантов. Нужно решить, какое действие совершить, какого взять покемона, нужно понять — когда использовать различные предметы. Всё это, само по себе, представляет сложные задачи оптимизации. Вот материал, где исследуется задача по разработке симулятора боя в Pokemon. Статья это хорошо проработанная, довольно сложная, но и там не рассматривается проблема предметов, важнейшего фактора, влияющего на исход битвы.
В итоге можно сказать, что нам нужно радоваться тому факту, что мы можем создавать ботов, которые лучше нас играют в наши же игры. Эти игры сложны с математической точки зрения, но их цели определяются легко. С развитием технологий искусственного интеллекта человечество сможет создать машины, которые смогут решать всё более важные проблемы реального мира. Делать они это будут, изучая эти проблемы, являющиеся сложными задачами оптимизации. Но пока, могу вас заверить, существуют задачи, которые мы решаем лучше машин, включая игры, в которые многие из нас играли в детстве. По крайней мере, сейчас дела обстоят именно так.
Уважаемые читатели! Приглашаем вас принять участие в первом в России турнире по олдскульным видеоиграм Game Overnight. В турнире есть отборочная часть и реальная битва лучших из лучших, которая пройдёт 30 ноября в Музее советских игровых автоматов. Нас ждёт турнир с 20 до 3 часов, пенные напитки Smart Admin, Dj Огурец (Сергей Мезенцев), а помогать ему будет админ RUVDS диджей Unpushible, а ещё мы будем пробовать новые снежные бургеры Sub Zero от наших админов. Так что, как говорится, добро пожаловать!

Источник


