![[Перевод] Можем ли мы вскрыть чёрный ящик искусственного интеллекта?](https://habrastorage.org/getpro/geektimes/post_images/2fc/0cc/06e/2fc0cc06e20442ec15b3f9db163a274a.png "[Перевод] Можем ли мы вскрыть чёрный ящик искусственного интеллекта?")
Дин Помело [Dean Pomerleau] всё ещё помнит, как ему впервые пришлось столкнуться с проблемой «чёрного ящика». В 1991 году он делал одну из первых попыток в той области, которая сейчас изучается всеми, кто пытается создать робомобиль: обучение компьютера вождению.
А это означало, что нужно сесть за руль специально подготовленного Хамви (армейского вседорожника), и покататься по улицам города. Так рассказывает об этом Помело, в ту пору бывший аспирантом по робототехнике в Университете Карнеги-Меллон. Вместе с ним катался и компьютер, запрограммированный следить через камеру, интерпретировать происходящее на дороге и запоминать все движения водителя. Помело надеялся, что машина в итоге построит достаточно ассоциаций для самостоятельного вождения.
За каждую поездку Помело тренировал систему несколько минут, а затем давал ей порулить самостоятельно. Всё вроде бы шло хорошо – пока однажды Хамви, подъехав к мосту, не повернул внезапно в сторону. Человеку удалось избежать аварии, только быстро схватив руль и вернув управление.
В лаборатории Помело попробовал разобраться в ошибке компьютера. «Одной из задач моей научной работы было вскрыть ‘чёрный ящик’ и разобраться, о чём он думал»,- поясняет он. Но как? Он запрограммировал компьютер как «нейросеть» – тип искусственного интеллекта, имитирующий работу мозга, обещавший быть лучше стандартных алгоритмов в обработке сложных ситуаций, связанных с реальным миром. К сожалению, такие сети непрозрачны так же, как и настоящий мозг. Они не хранят всё изученное в аккуратном блоке памяти, а вместо этого размазывают информацию так, что её очень сложно расшифровать. Только после широкого спектра тестов реакции софта на различные входные параметры, Помело обнаружил проблему: сеть использовала траву по краям дорог для определения направлений, и поэтому появление моста её смутило.
Через 25 лет расшифровка чёрных ящиков стала экспоненциально сложнее, при одновременном возрастании срочности этой задачи. Произошёл взрывной рост сложности и распространенности технологий. Помело, на полставки обучающий робототехнике в Карнеги-Меллон, описывает его давнюю систему как «нейросеть для бедных», по сравнению с огромными нейросетями, реализуемыми на современных машинах. Техника глубокого обучения (ГО), в которой сети тренируются на архивах из «больших данных», находит разные коммерческие применения, от робомобилей до рекомендаций продуктов на сайтах, сделанных на основе истории просмотров.
Технология обещает стать повсеместно распространённой и в науке. Будущие радиообсерватории будут использовать ГО для поиска значимых сигналов в массивах данных, которые иначе и не разгребёшь. Детекторы гравитационных волн будут использовать их для понимания и устранения мелких шумов. Издатели будут использовать их для фильтрации и пометки миллионов исследовательских работ и книг. Некоторые считают, что в итоге компьютеры при помощи ГО смогут продемонстрировать воображение и творческие способности. «Можно будет просто закинуть в машину данные, и она вернёт вам законы природы»,- говорит Жан-Рох Влиман [Jean-Roch Vlimant], физик из Калифорнийского технологического института.
Но такие прорывы сделают проблему чёрного ящика ещё более острой. Как именно машина находит значимые сигналы? Как можно быть уверенным, что её выводы верны? Насколько люди должны доверять глубокому обучению? «Думаю, что с этими алгоритмами мы вынуждены уступать»,- говорит специалист по робототехнике Ход Липсон [Hod Lipson] из Колумбийского университета в Нью-Йорке. Он сравнивает ситуацию со встречей с разумными инопланетянами, глаза которых видят не только красный, зелёный и голубой, но и четвёртый цвет. По его словам, людям будет очень сложно понять, как эти инопланетяне видят мир, а им – объяснить это нам. У компьютеров будут те же проблемы с объяснением своих решений, говорит он. «В какой-то момент это начнёт напоминать попытки объяснить Шекспира собаке».
Встретив такие проблемы, исследователи ИИ реагируют так же, как Помело – вскрывают чёрный ящик и выполняют действия, напоминающие неврологию, для понимания работы сетей. Ответы не интуитивные, говорит Винчезо Инноченте [Vincenzo Innocente], физик из ЦЕРН, первым применивший ИИ в своей области. «Как учёный я не удовлетворён простым умением отличать собак от кошек. Учёный должен иметь возможность сказать: разница в том-то и в том-то».
Хорошая поездка
Первая нейросеть была создана в начале 1950-х, почти сразу после появления компьютеров, способных работать по нужным алгоритмам. Идея в том, чтобы эмулировать работу небольших счётных модулей – нейронов – расположенных слоями и соединённых с цифровыми «синапсами». Каждый модуль в нижнем слое принимает внешние данные, например, пиксели картинки, затем распространяет эту информацию вверх некоторым из модулей следующего слоя. Каждый модуль во втором слое интегрирует входные данные от первого слоя по простому математическому правилу, и передаёт результат далее. В итоге верхний слой выдаёт ответ – например, относит исходное изображение к «кошкам» или «собакам».
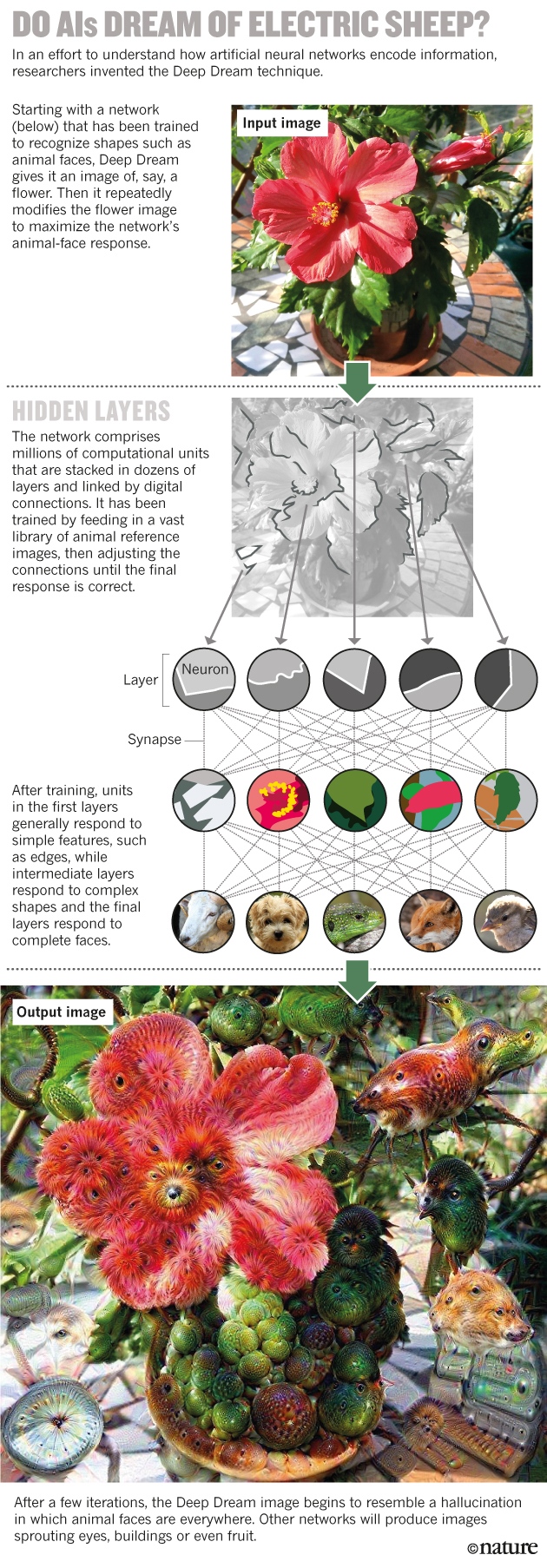
Снятся ли ИИ электроовцы? Технология «Глубокий сон» (Deep Dream) даёт в качестве входных данных для нейросети, натренированной на распознавание лиц, изображение, допустим, цветка – а затем последовательно меняет его, чтобы получить максимальный отклик от нейросети.
После тренировки первый слой сети в среднем реагирует на простые формы вроде границ, средние – на сложные формы, а последний уже работает с лицами целиком.
Результат работы Deep Dream напоминает галлюцинацию.
Возможности таких сетей проистекают из их способности обучаться. Обучаясь на начальном наборе данных с заданными правильными ответами, они постепенно улучшают свои характеристики, подстраивая влияние всех связей, чтобы выдавать правильные результаты. Процесс эмулирует обучение мозга, усиливающего и ослабляющего синапсы, и даёт на выходе сеть, способную классифицировать данные, изначально не входившие в тренировочный набор.
Возможность обучения соблазняла физиков из ЦЕРН в 1990-х годах, когда они одними из первых приспосабливали большие нейросети к работе на науку. Нейросети сильно помогли в реконструкции траекторий субатомной шрапнели, разлетающейся в стороны при столкновениях частиц на Большом адронном коллайдере.
Эта форма обучения также является причиной того, что информация очень сильно размазана по сети: как и в мозгу, её память закодирована в силе различных соединений, а не хранится в определённых местах, как в привычной базе данных. «Где в вашем мозгу хранится первая цифра вашего телефонного номера? Возможно, в наборе синапсов, возможно, недалеко от остальных цифр»,- говорит Пьер Балди [Pierre Baldi], специалист по машинному обучению (МО) из Калифорнийского университета. Но там нет определённой последовательности битов, кодирующих номер. В результате, как говорит специалист по информатике Джефф Клюн [Jeff Clune] из Вайомингского университета, «хоть мы и создаём эти сети, мы можем понять их не лучше, чем человеческий мозг».
Для учёных, работающих с большими данными, это значит, что ГО нужно использовать осторожно. Андреа Ведальди [Andrea Vedaldi], специалист по информатике из Оксфордского университета поясняет: представьте, что в будущем нейросеть натренируют на маммограммах, на которых будет отмечено, появился ли у исследуемых женщин рак груди. После этого, допустим, что ткани некоей здоровой женщины покажутся машине подверженными заболеванию. «Нейросеть может обучиться распознавать онкомаркеры – те, о которых мы не знаем, но которые могут предсказывать рак».
Но если машина не сможет объяснить, как она это определяет, то, по словам Ведальди, для врачей и пациентов это станет серьёзной дилеммой. Женщине и так нелегко подвергнуться превентивному удалению грудной железы из-за наличия генетических особенностей, которые могут привести к возникновению рака. И сделать такой выбор будет ещё сложнее, поскольку будет даже неизвестно, что это за фактор – даже если предсказания машины окажутся точными.
«Проблема в том, что знания встраиваются в сеть, а не в нас»,- говорит Майкл Тайка [Michael Tyka], биофизик и программист Google. «Поняли ли мы что-нибудь? Нет – это сеть поняла».
Несколько групп учёных занялись проблемой чёрного ящика в 2012 году. Команда под руководством Джоффри Хинтона [Geoffrey Hinton], специалиста по МО из Торонтского университета, участвовала в соревновании по компьютерному зрению, и впервые продемонстрировала, что применение ГО для классификации фотографий из базы данных, содержащей 1,2 миллиона изображений, превзошла любой другой подход с использованием ИИ.
Разбираясь в том, как это возможно, группа Ведальди взяла алгоритмы Хинтона, предназначенные для улучшения нейросети, и прогнала их задом наперёд. Вместо обучения сети на правильную интерпретацию ответа, команда взяла предварительно натренированные сети и попыталась воссоздать картинки, благодаря которым они тренировались. Это помогло исследователям определить, как машина представляет некоторые особенности – всё было так, будто они спрашивали некую гипотетическую нейросеть, предсказывающую рак, «Какая часть маммограммы натолкнула тебя на отметку о риске рака?».
В прошлом году Тайка и его коллеги из Google использовали похожий подход. Их алгоритм, который они назвали Deep Dream, начинает с картинки, допустим, цветка, и изменяет её так, чтобы улучшить отклик определённого нейрона верхнего уровня. Если нейрону нравится отмечать изображения, допустим, птиц, то изменённая картинка начнёт показывать птиц везде. Итоговые картинки напоминают видения под LSD, где птицы видны в лицах, зданиях и много где ещё. «Думаю, что это очень похоже на галлюцинацию»,- говорит Тайка, являющийся ещё и художником. Когда он с коллегами увидел потенциал алгоритма в творческой области, они решили сделать его свободным для скачивания. Уже через несколько дней эта тема стала вирусной.
Используя техники, максимизирующие выдачу любого нейрона, а не только одного из верхних, команда Клюна в 2014 году обнаружила, что проблема чёрного ящика может быть сложнее, чем казалась ранее. Нейросети очень легко обмануть при помощи картинок, воспринимаемых людьми как случайный шум или абстрактные узоры. К примеру, сеть может взять волнистые линии и решить, что это морская звезда, или перепутать чёрно-белые полоски со школьным автобусом. Более того, те же тенденции возникали и в сетях, натренированных на других наборах данных.
Исследователи предложили несколько вариантов решения проблемы с одурачиванием сетей, но общего решения пока не найдено. В реальных приложениях это может быть опасно. Один из пугающих сценариев, по мнению Клюна, состоит в том, что хакеры научаться пользоваться этими недостатками сетей. Они могут отправить робомобиль в рекламный щит, который тот примет за дорогу, или обмануть сканер сетчатки на входе в Белый дом. «Нужно засучить рукава и провести глубокие научные исследования с тем, чтобы сделать МО более надёжным и умным»,- заключает Клюн.
Такие проблемы заставили некоторых специалистов по информатике думать, что не стоит зацикливаться на одних только нейросетях. Зубин Гахрамани [Zoubin Ghahramani], исследователь МО в Кембриджском университете, говорит, что если ИИ должен давать ответы, которые людям легко интерпретировать, это приведёт к появлению «большого количества проблем, с которыми ГО не сможет помочь справиться». Один из довольно понятных научных подходов впервые был показан в 2009 году Липсоном и вычислительным биологом Майклом Шмидтом [Michael Schmidt], в то время работавшим в Корнеллском университете. Их алгоритм Eureqa продемонстрировал процесс переоткрытия законов ньютона путём наблюдения за простым механическим объектом – системой памятников – в движении.
Начав со случайной комбинации математических кирпичиков вроде +, -, синуса и косинуса, Eureqa методом проб и ошибок, схожим с дарвиновской эволюцией, меняет их, пока не приходит к описывающим данные формулам. Затем она предлагает эксперименты для проверки моделей. Одно из её преимуществ – простота, говорит Липсон. «У модели, выработанной Eureqa, обычно десяток параметров. У нейросети их миллионы».
На автопилоте
В прошлом году Гарахмани опубликовал алгоритм автоматизации работы учёного по данным, от сырых данных до готовой научной работы. Его софт Automatic Statistician, замечает тренды и аномалии в наборах данных и даёт заключение, включая подробное объяснение рассуждений. Эта прозрачность, по его словам, «совершенно критична» для применения в науке, но также важна и для коммерческого применения. К примеру, во многих странах банки, отказывающие в займах, по закону обязаны объяснить причину отказа – а это алгоритму ГО может быть не под силу.
Те же сомнения присущи и различным организациям, поясняет Элли Добсон [Ellie Dobson], директор по науке о данных в фирме Arundo Analytics в Осло. Если, допустим, в Британии что-то пойдёт не так из-за изменения базовой ставки, Банк Англии не может просто сказать «это всё из-за чёрного ящика».
Но, несмотря на все эти страхи, специалисты по информатике говорят, что попытки создать прозрачный ИИ должны быть дополнением к ГО, а не заменой этой технологии. Некоторые прозрачные техники могут хорошо работать в областях, уже описанных в виде набора абстрактных данных, но при этом не справляться с восприятием – процессом извлечения фактов из сырых данных.
В итоге, по их словам, сложные ответы, полученные благодаря МО, должны быть частью инструментария науки, поскольку реальный мир сложный. Для таких явлений, как погода или финансовый рынок, редукционистских, синтетических описаний может просто не существовать. «Есть вещи, которые нельзя описать словами»,- говорит Стефан Маллат [Stéphane Mallat], математик-прикладник из парижской Политехнической школы. «Когда вы спрашиваете врача, почему он поставил такой диагноз, он опишет вам причины,- говорит он. – Но почему тогда нужно 20 лет, чтобы стать хорошим врачом? Потому что информацию получают не только лишь из книг».
По мнению Балди, учёный должен принять ГО и не сильно париться по поводу чёрных ящиков. У них ведь есть такой чёрный ящик в голове. «Вы постоянно используете мозг, вы всегда доверяете ему, и вы не понимаете, как он работает».
Источник

