![[Перевод] Действительно ли искусственный интеллект непостижим?](https://habrastorage.org/getpro/geektimes/post_images/c97/20b/1a6/c9720b1a68c8f7f9bdecf81b9333fbc9.png "[Перевод] Действительно ли искусственный интеллект непостижим?")
Дмитрий Малютов мало что может рассказать о своём творении.
Он работает в исследовательском отделе IBM, и часть своего времени посвящает созданию систем машинного обучения, решающих задачи корпоративных клиентов компании. Одна такая программа разрабатывалась для большой страховой компании. Задание было непростым, требовался сложный алгоритм. Когда пришло время объяснять результаты клиенту, возникла заминка. «Мы не могли объяснить им эту модель, потому что они не разбирались в машинном обучении».
А даже если бы и разбирались, это могло им не помочь. Потому что моделью была искусственная нейросеть, программа, принимающая данные нужного типа – в нашем случае, дела клиентов страховой компании – и находившая в них шаблоны. Подобные сети используются на практике уже полстолетия, но недавно они испытали возрождение, и помогают совершать прорывы везде, от распознавания речи и переводов до игры в Go и робомобилей.

И несмотря на все успехи нейросетей, есть у них и одна проблема: никто, по сути, не знает точно, как они работают. А значит, никто не может предсказать, когда они ошибутся.
Возьмём, к примеру, ситуацию, о которой недавно поведала исследователь в области машинного обучения Рич Каруана [Rich Caruana] со своими коллегами. Они описали опыт команды из Медицинского центра Питтсбургского университета, использовавшей МО для предсказания возникновения осложнений у больных пневмонией. Они стремились к тому, чтобы отправлять пациентов с небольшим риском на амбулаторное лечение, и экономить места в госпиталях. Они попробовали разные методы, в том числе различные нейросети, а также деревья решений, созданные программами, выдававшие понятные человеко-читаемые правила.
Нейросети оказывались правы чаще, чем другие методы. Но когда исследователи и врачи обратились к человеко-читаемым правилам, они заметили нечто неприятное: одно из правил предписывало врачам отправлять домой больных пневмонией, у которых была астма, несмотря на то, что больные астмой очень плохо переносят осложнения.
Модель сделала, что ей было поручено: обнаружила шаблоны в данных. Плохой совет был результатом неточности в данных. В правилах госпиталя была прописана отправка астматиков с пневмонией в отделение интенсивной терапией, и это правило так хорошо работало, что астматики почти не сталкивались с осложнениями. А без особого ухода результаты их лечения были бы совсем другими.
Это происшествие показывает большое значение возможности интерпретации результатов. «Если система, основанная на правилах, выяснила, что астма понижает риски, конечно, и нейросеть это тоже выучила»,- писал Каруана с коллегами – но работу нейросети люди не могли интерпретировать, и её странные заключения по поводу астматиков было бы сложно объяснить (1). Если бы у них не было интерпретируемой модели, предупреждает Малютов, «можно было бы случайно поубивать людей».
Поэтому многие не торопятся ставить на загадочные нейросети. Когда Малютов представлял свою аккуратную но непонятную нейросетевую модель своему корпоративному клиенту, он предложил им и альтернативную систему, основанную на правилах, работу которой он мог просто объяснить. Вторая модель работала менее аккуратно, чем первая, но клиент решил использовать её – несмотря на то, что для работающей с математикой и точными данными страховой компании важна была любая доля процента точности. «Они лучше её понимали,- говорит Малютов. – Они высоко ценят интуицию».
Даже правительства начинают беспокоиться по поводу растущего влияния непонятных пророков от нейросетей. В ЕС недавно предложили ввести «право на объяснение», которое позволяло бы гражданам требовать прозрачности алгоритмических решений (2). Но такой закон сложно будет ввести, поскольку регистраторы не дали чёткого определения «прозрачности». Непонятно, является ли этот просчёт результатом непонимания проблемы или признанием её сложности.
На самом деле, некоторые верят, что это определение невозможно дать. Пока что, хотя мы знаем всё по поводу того, что делают нейросети – ведь это, по сути, просто компьютерные программы – мы очень мало что можем сказать о том, почему они это делают. Сети состоят из множества, иногда из миллионов, отдельных элементов, называемых нейронами. Каждый нейрон преобразовывает множество чисел на входы в одно число на выходе, которое потом передаётся дальше одному или нескольким нейронам. Как и в мозгах, нейроны делятся на «слои», группы клеток, принимающих данные от нижнего слоя и отправляющих его на верхний.
Нейросети тренируются путём скармливания им данных, а затем регулировки связей между слоями до тех пор, пока вывод сети не начнёт наилучшим образом соответствовать просчитанному. Невероятные результаты последних лет появились благодаря серии новых техник, сделавших возможным быструю тренировку глубоких сетей, со многими слоями между первым вводом и окончательным выводом. Одна из популярных глубоких сетей AlexNet используется для категоризации фотографий – и, помечая их, способна распознавать такие тонкие моменты, как отличия пород померанский шпиц и ши-тцу. Она содержит более 60 миллионов «весов», каждый из которых сообщает каждому нейрону о том, сколько внимания нужно уделять каждому кусочку входных данных. «Чтобы говорить о понимании работы сети,- говорит Ясон Йосинский, программист из Корнеллского университета, работающий в компании Geometric Intelligence,- нужно обладать пониманием этих 60 миллионов чисел».
И даже если было бы возможно настолько разобраться в работе нейросети, это не всегда нужно. Требование точного понимания её работы можно рассматривать, как ещё один набор ограничений, мешающий модели вырабатывать «чистые» решения, зависящие лишь от входа и выхода, потенциально способный уменьшать точность модели. На конференции DARPA руководитель программы Дэвид Ганнинг [David Gunning] обрисовал текущее положение нейросетей на графике, который демонстрирует, что глубокие сети – это наименее понятные из современных методов. На другом конце спектра – деревья решений, основанные на правилах системы, ценящие объяснимость выше эффективности.
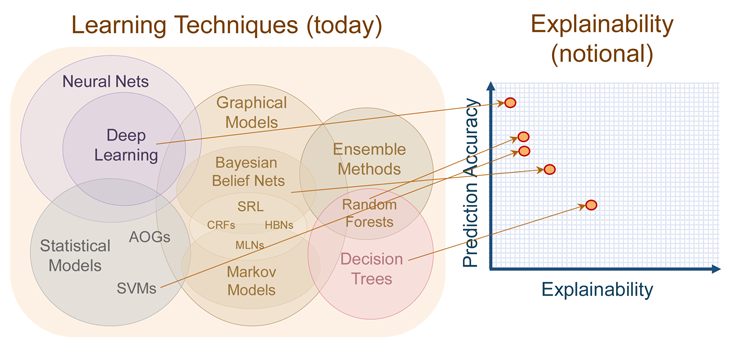
Наиболее точные и наименее понятные методы – глубокие сети. Затем по увеличению понятности и уменьшению точности идут алгоритм «случайный лес», статистические модели, байесовские сети, и деревья решений.
В результате, современное машинное обучение выступает в роли оракула: получить точный ответ о том, что случится, или же понятное, но неточное объяснение того, что случится? Объяснение помогает нам вырабатывать стратегию и адаптироваться, а также знать, когда модель перестанет работать. Знание о том, что случится, помогает нам реагировать соответствующим образом в ближайшем будущем.
Такой выбор может быть сложным. Некоторые исследователи надеются устранить необходимость выбора – чтобы у нас был и слоёный торт, и его понимание. Интересно, что самые многообещающие исследования относятся к нейросетям как к объектам эксперимента – на манер биологических изысканий – вместо того, чтобы рассматривать их, как чисто математические объекты. Йосинский, к примеру, говорит, что он пытается понять глубокие сети «как мы понимаем животных, или даже людей». Он и другие программисты заимствуют технологии исследований из биологических областей, и заглядывают в нутро нейросетей словно неврологи в мозг: пробуя отдельные части, составляя каталоги того, как внутренности сетей реагируют на небольшие изменения ввода, и даже удаляя кусочки и наблюдая за тем, как остальные компенсируют их отсутствие.
Построив интеллект нового типа с нуля, учёные теперь разбирают его на части, применяя к этим виртуальным организмам цифровые микроскопы и скальпели.
Йосинский сидит за компьютером и говорит в веб-камеру. Данные с камеры скармливаются глубокой нейросети, в то время, как сама сеть подвергается анализу в реальном времени при помощи программы Deep Visualization, разработанной Йосинским с его коллегами. Переключаясь между экранами, Йосинский увеличивает один из нейронов сети. «Этот нейрон, судя по всему, реагирует на лица»,- говорит он на видеозаписи взаимодействия (3). В мозгу людей также существуют такие нейроны, многие из которых скапливаются в отделе мозга под названием «веретенообразная лицевая область». Эта область, открытая в различных исследованиях, начавшихся в 1992 году (4, 5), стала наиболее испытанным наблюдением в неврологии. Но если те исследования требовали применения таких сложных вещей, как позитронно-эмиссионная томография, Йосинскому достаточно одного кода.
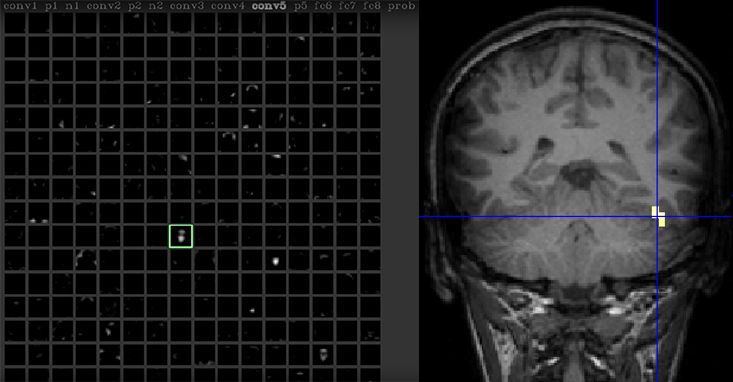
Один нейрон в нейросети реагирует на лицо Йосинского так же, как одна из областей мозга реагирует на лица.
Этот подход позволяет ему связать искусственные нейроны с идеями или объектами, понятными человеку, типа лиц, что в результате может превратить нейросети в понятные инструменты. Его программа может указать, какое из свойств картинки более других стимулирует лицевой нейрон. «Мы можем увидеть, что он ещё сильнее бы отреагировал, если бы, например, глаза были темнее, а губы розовее»,- говорит он.
Для Синтии Рудин [Cynthia Rudin], профессора по компьютерным наукам и электронике из Университета Дюка, эти интерпретации по результатам не нравятся. Её исследование занимается построением систем МО на основе правил, применяемых к таким областям, как приговоры к тюремному заключению или медицинские диагнозы, где человеко-читаемые интерпретации не только возможны, но и критически важны. Но в областях, связанных со зрением, как она говорит, «интерпретации зависят исключительно от наблюдателя». Мы можем упростить ответ сети, определив лицевой нейрон, но как убедиться, что мы не ошиблись? Сомнения Рудин отражает известный афоризм, утверждающий, что для системы зрения может не существовать модели проще, чем сама система зрения. «Можно придумать много объяснений того, что делает сложная модель,- говорит она. – И что же нам, просто выбрать одно из них и признать его правильным?».
Инструмент Йосинского может частично опровергнуть эти сомнения, работая задом наперёд и открывая, что сеть сама по себе «хочет» оказаться правдивой – нечто вроде искусственного идеала. Программа начинает с сырой статики, затем попиксельно уточняет её, обрабатывая изображение при помощи процесса, обратного обучению. В результате она находит картинку, вызывающую максимально возможный ответ у выбранного нейрона. В применении к нейронам AlexNet метод выдаёт карикатурные изображения для отмеченных категорий.

Идеальные версии котов, созданные Deep Visualization.
Это, видимо, подтверждает заявления Йосинского о том, что лицевые нейроны ищут лица, в некоем общем смысле. Но есть проблема – для создания таких изображений процедура полагается на статистические ограничения (естественных предков изображения), которые ограничивают её созданием только изображений, содержащих структуры, встречающиеся в изображениях реального мира. Если убрать эти ограничения, инструменту всё равно удаётся найти картинку, вызывающую максимальный отклик, но эта картинка выглядит, как шум. Йосинский показал, что во многих случаях предпочитаемые AlexNet выглядят для людей, как шум. Он признаёт, что «довольно легко разобраться, как заставить нейросети выдавать что-то экстремальное».
Во избежание этих ловушек, Друв Батра [Dhruv Batra], ассистент-профессор по электронике и компьютерам в Вирджинском технологическом университете использует для интерпретации работы глубоких сетей экспериментальный подход более высокого уровня. Вместо поиска шаблонов в их внутренней структуре – «люди и поумнее меня работали над этим», сомневается он – он исследует поведение сетей через роботизированную версию отслеживания движений глаз. Его группа в проекте под руководством аспирантов Абхишека Даса [Abhishek Das] и Харша Агравала [Harsh Agrawal] задаёт нейросети вопросы об изображении, например, есть ли на картинке на окне шторы (6). В отличие от систем типа AlexNet, сеть Даса разработана так, чтобы работать с небольшой порцией картинки. Она двигает виртуальным глазами по изображению, пока не решает, что набрала довольно информации для ответа. После тренировки такая сеть очень хорошо работает, и отвечает на вопросы не хуже лучших людей.
Дас, Батра и коллеги затем захотели понять, как сеть принимает решения, изучая, на какие части изображений сеть обратила внимание. К удивлению, они обнаружили, что в ответе на вопрос про шторы, сеть даже не смотрит на окно. Она сначала смотрит на низ картинки, и прекращает смотреть, если находит кровать. Видимо, в наборе начальных данных для тренировки сетей, окна со шторами присутствовали в спальнях.
И хотя этот подход открывает некоторые аспекты работы нейросетей, он даже усложняет проблему интерпретации их работы. «Машины учатся не фактам о мире,- говорит Батра. – Они учатся фактам о представленном наборе данных». То, что они так сильно завязаны на предоставленных им данных, затрудняет составление общих правил их работы. Более того, если вы не знаете, как это работает, вы не знаете, когда оно ошибётся. А когда они ошибутся, то, по опыту Батры, «они сделают это ужасно позорно».
Некоторые преграды, с которыми встречаются исследователи, знакомы учёным, изучающим человеческий мозг. Вопросы интерпретации изображений работы мозга сейчас очень популярны, хотя и не так сильно известны. В обзоре от 2014 года когнитивный невролог Марта Фара [Martha Farah] писала, что «беспокоит то, что изображения работающего мозга больше похожи на изобретения исследователей, чем на наблюдения» (7). Появление этих проблем в очень разных видах интеллектуальных систем может говорить о том, что эти проблемы являются препятствиями не в изучении того или иного вида мозга, а в изучении самого понятия интеллекта.
Являются ли поиски понимания работы сетей бесплодной затеей? В блогпосте от 2015 года «Миф об интерпретируемости моделей» Захари Липтон [Zachary Lipton] из Калифорнийского университета в Сан-Диего предложил критичный взгляд как на мотивацию, стоящую за попытками понять работу нейросетей, так и на ценность создания интерпретируемых моделей МО на больших массивах данных. Он подал свою работу на симпозиум по дисциплине «интерпретируемость с точки зрения человека» (организованный Малютовым с коллегами) на конференции по машинному обучению (ICML), проходящей в этом году. (8)
Липтон указывает, что многие учёные не согласны с самой концепцией интерпретируемости, что, по его мнению, означает, что либо интерпретируемость плохо понимают, или что у этого понятия много разных значений. В любом случае поиски интерпретируемости могут не дать нам простых и прямых объяснений того, почему нейросеть выдала такой результат. В блогпосте Липтон аргументирует, что в случае гигантских наборов данных исследователи могут подавить своё желание интерпретировать результаты и просто «поверить в эмпирический процесс». Он считает, что одной из целью этой области является «построение моделей, способных обучаться на большем количестве параметров, которое когда-либо сможет обработать человек», и требование интерпретируемости может ограничить модели и не дать им развить весь свой потенциал.
Но такая возможность будет и преимуществом, и недостатком: если мы не понимаем, как сеть создаёт выходные данные, мы не знаем, какие особенности входных данных были важны, или что вообще можно рассматривать, как входные данные. Например, в 1996 году Адриан Томпсон [Adrian Thompson] из Сассекского университета использовал программу для разработки электронного контура, основанную на принципах, схожих с работой нейросетей. Контур должен был просто различать две разных тональности звука. После тысячи итераций по размещению и смене местами радиокомпонентов, программа нашла решение, работающее почти идеально.
Но Томпсон удивился, узнав, что контур использовал меньше компонентов, чем понадобилось бы инженеру-человеку. При этом несколько из них не были соединены с остальными, но они, каким-то образом, всё равно нужны были для правильной работы контура.
Он начал разбирать контур на части, и после нескольких экспериментов понял, что в его работе использовались небольшие помехи, возникавшие в соседних компонентах. Не участвовавшие в контуре компоненты влияли на него, приводя к малым флюктуациям в местных электрических полях. Инженеры обычно стремятся избавиться от таких взаимодействий из-за их непредсказуемости. Естественно, при попытке скопировать этот контур с участием другой партии таких же компонентов, или даже при смене окружающей температуры, контур переставал работать.
Этот контур продемонстрировал типичный признак результата работы тренированных машин: он компактный и наиболее упрощённый, очень хорошо приспособлен для своего окружения, и вовсе неработоспособен в других условиях. Они выбирают невидимые для инженеров свойства, но не могут знать о том, есть ли эти свойства где-то ещё. Исследователи МО пытаются избежать таких явлений, названных ими «сверхспециализацией», но при увеличении случаев использования таких алгоритмов в жизненных задачах их уязвимость станет видна.
Для Санджеев Арора [Sanjeev Arora], профессора информатики из Принстонского университета, эта проблема служит основной мотивацией для поиска интерпретируемых моделей, позволяющих людям вмешаться и подстроить сеть. Арора отмечает, что в отсутствие интерпретируемости у МО есть две очень серьёзные проблемы. Первая – пригодность для компоновки, когда при решении задачи нужно принимать так много решений (игра в го или вождение автомобиля), что не всегда понятно, какие из них привели к неудаче. «Обычно когда мы что-то разрабатываем, мы понимаем, что делают отдельные части, а затем собираем их вместе»,- говорит он. Это позволяет людям подстраивать компоненты, не соответствующие данному окружению.
Вторая проблема – «территориальная приспособляемость», то есть, возможность гибко применять знания, полученные в одном месте, к другому. У людей это получается хорошо, но машины могут ошибаться весьма неожиданно. Арора описывает случаи, в которых машины совершенно не способны подстраиваться под самые малые изменения контекста, в отличие от людей, делающих это с лёгкостью. К примеру, сеть, обученная чтению формальных документов, типа статей Википедии, оказывается неспособной понимать сообщения в твиттере.
С этой точки зрения интерпретируемость необходима. Но понимаем ли мы значение этого слова? Пионер компьютерных исследований, Марвин Минский, придумал фразу «сознание как чемодан» для понятий вроде сознания или эмоций, используемых нами при описании нашего интеллекта (9). Эти слова отражают работу множества разных процессов, спрятанных в «чемодане». И пока мы будем изучать эти слова-замены более фундаментальных концепций, мы будем ограничены возможностями языка. Может ли при изучении ИИ интерпретируемость оказаться таким же словом?
И хотя многие исследователи, с которыми я общался, оптимистично полагают, что теоретики когда-нибудь откроют чемодан и обнаружат простой набор правил, управляющих машинным (и, возможно, человеческим) обучением, нечто вроде «Математических начала натуральной философии» Ньютона, другие предупреждают, что этого вряд ли стоит ожидать. Массимо Пиглюччи [Massimo Pigliucci], профессор философии Нью-Йоркского городского университета предупреждает, что понимание естественных наук – и ИИ в том числе – может оказаться тем, что философ Людвиг Витгенштейн [Ludwig Wittgenstein] называл «сборной концепцией», такой, которая допускает множество различных определений. Если «понимание» и придёт, оно может оказаться похожим не на физические концепции, а на понятия из эволюционной биологии. Вместо «Начал» у нас в руках может оказаться «Происхождение видов».
Это, конечно, не значит, что глубокие сети станут предвестниками некоего нового типа жизни. Но они могут оказаться так же сложны для понимания, как жизнь. Инкрементальные, экспериментальные подходы и интерпретация по результатам могут оказаться не отчаянными метаниями в темноте в поисках света. Наоборот, это может быть единственный доступный нам свет. Интерпретируемость может открыться по частям, как набор примеров-прототипов «видов», систематизированных по контекстно-зависимым объяснениям.
На конференции ICML некоторые докладчики призывали определить «интерпретируемость». Вариантов было столько же, сколько и выступающих. Подискутировав, участники пришли к соглашению, что для интерпретируемости модели она должна быть простой. Но при попытке определить «простоту» группа опять разделилась. Будет ли простейшей та модель, что полагается на минимальный набор свойств? Та, что делает наиболее чёткие разделения? Наименьшая из программ? Симпозиум закрылся без согласия участников, заменивших одну зарождающуюся концепцию другой.
Как говорит Малютов, «простота – это не так просто».
Ссылки
1. Caruana, R., et. al Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 1721-1730 (2015).
2. Metz, C. Artificial Intelligence Is Setting Up the Internet for a Huge Clash with Europe. Wired.com (2016).
3. Yosinski, J., Clune, J., Nguyen, A., Fuchs, T., & Lipson, H. Understanding neural networks through deep visualization. arXiv:1506.06579 (2015).
4. Sergent, J., Ohta, S., & MacDonald, B. Functional neuroanatomy of face and object processing. A positron emission tomography study. Brain 115, 15–36 (1992).
5. Kanwisher. N., McDermott, J., & Chun, M.M. The fusiform face area: A module in human extrastriate cortex specialized for face perception. The Journal of Neuroscience 17, 4302–4311 (1997).
6. Das, A., Agrawal, H., Zitnick, C.L., Parikh, D., & Batra, D. Human attention in visual question answering: Do humans and deep networks look at the same regions? Conference on Empirical Methods in Natural Language Processing (2016).
7. Farah, M.J. Brain images, babies, and bathwater: Critiquing critiques of functional neuroimaging. Interpreting Neuroimages: An Introduction to the Technology and Its Limits 45, S19-S30 (2014).
8. Lipton, Z.C. The mythos of model interpretability. arXiv:1606.03490 (2016).
9. Brockman, J. Consciousness Is a Big Suitcase: A talk with Marvin Minsky. Edge.org (1998).
Источник

