Пакет NSS, также как и OpenSSL, предоставляет возможность использования для реализации различных функций PKI (генерация ключей, выпуск сертификатов x509v3, работа с электронной подписью, поддержка TLS и т.д.) утилиты командной строки. Одна из таких утилит, а именно Pretty-print (PP), позволяет просматривать в удобном виде содержимое как сертификата x509 v3, так и электронную подпись (pkcs#7) и т.д. При чем сертификат может быть как в DER, так и PEM-кодировках:
bash-4.3$ pp -h Usage: pp [-t type] [-a] [-i input] [-o output] [-w] [-u] Pretty prints a file containing ASN.1 data in DER or ascii format. -t type Specify input and display type: public-key (pk), certificate (c), certificate-request (cr), certificate-identity (ci), pkcs7 (p7), crl or name (n). (Use either the long type name or the shortcut.) -a Input is in ascii encoded form (RFC1113) -i input Define an input file to use (default is stdin) -o output Define an output file to use (default is stdout) -w Don't wrap long output lines -u Use UTF-8 (default is to show non-ascii as .) bash-4.3$Более того, наличие параметра –u (кодировка UTF-8) позволяет просматривать сертификата в русской кодировке. Но вот внимательно вглядываясь в скриншоты графического интерфейса к утилитам командной строки пакета NSS замечаешь, что часть данных сертификата просто исчезла:

Начался поиск пропавшей информации. Утилита «симпатичной печати» (а именно так переводится Pretty-print) для просмотра корневого сертификата Головного УЦ Минкомсвязи была запущена в командной строке:
$pp – certificate –u –i ГУЦ_Минкомсвязи.cer … Subject: "CN=Головной удостоверяющий центр ,INN=007710474375,OGRN=1047702026701,O=Минкомсвязь Р� �ссии,STREET="125375 г. Москва, ул. Тверская , д. 7",L=Москва,ST=77 г. Москва,C=RU,E=dit@minsvya z.ru" …. $Полученный результат подтвердил пропажу данных. Более того, на экране появились два неотображаемых символа (раносторонний ромб черного цвета со знаком вопроса? внутри). Проведенный анализ показал, что эти неотображаемые символы имеют коды 0xD0 и 0xBE соответственно:
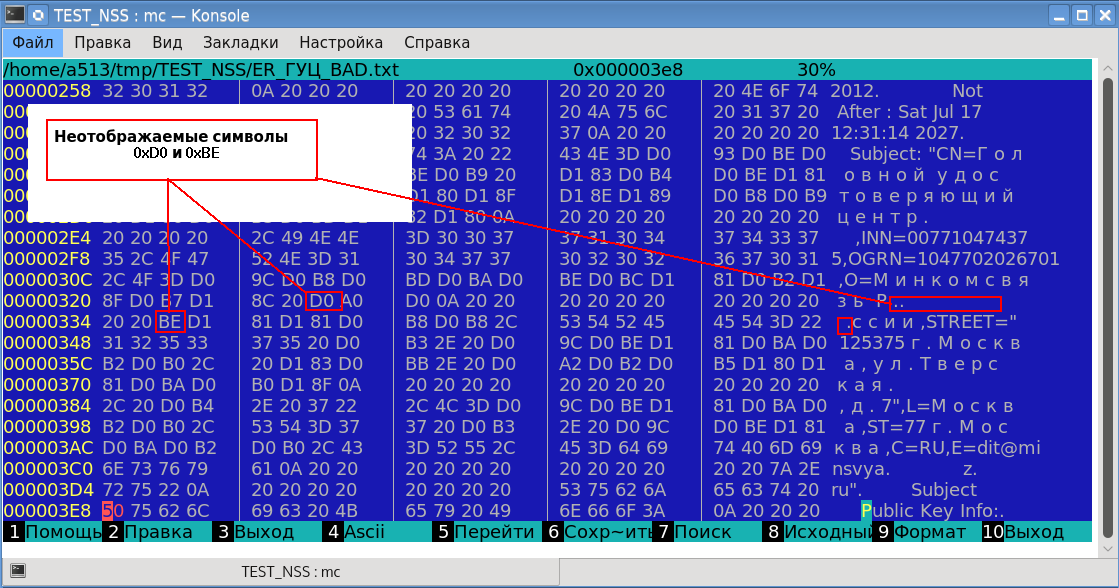
Пропала русская буква «о» с шестнадцатеричном представлении в кодировке UTF-8 как 0xD00xBE. А коды 0xD0 и 0xBE и есть наши неотображаемые символы. А что за символы появились между этими байтами? А это и есть «симпатичная» печать – символы выравнивания печатаемого текста.
Что же произошло? На вход «симпатичной» печати (файл /nss/cmd/lib/secutil.c, функция secu_PrintRawStringQuotesOptional) приходят данные в виде SECITEM, т.е. адреса на массив байт и его длину:
for (i = 0; i < si->len; i++) { unsigned char val = si->data[i]; unsigned char c; if (SECU_GetWrapEnabled() && column > 76) { SECU_Newline(out); SECU_Indent(out, level); column = level * INDENT_MULT; } if (utf8DisplayEnabled) { if (val < 32) c = '.'; else c = val; } else { c = printable[val]; } fprintf(out, "%c", c); column++; } И если предусмотрена (SECU_GetWrapEnabled() == True) симпатичная печать (отсутствие параметра –w у утилиты PP) и число байт в строке превысило 76 (column > 76), то после очередного символа вставляются новая строка (SECU_Newline) и необходимые отступы (SECU_Indent). При этом никто из разработчиков не задумался над тем, что, если используется кодировка UTF-8 (utf8DisplayEnabled), то красоту можно наводить только после очередного символа, а не байта, так как понятие байта и символа в кодировке UTF-8 могут и не совпадать. Если говорить о русских буквах, то каждая из них кодируется двумя байтами. Именно такой разрыв и произошел с нашей русской буквой «о» (0xD00xBE).
Каков выход? Все очень просто достаточно в функции secu_PrintRawStringQuotesOptional заменить строку:
if (SECU_GetWrapEnabled() && column > 76) {на строку следующего вида:
if (SECU_GetWrapEnabled() && column > 76 && (val <= 0x7F || val == 0xD0 || val == 0xD1)) {Если теперь пересобрать утилиту PP и установить ее в систему, то «симпатичная» печать будет оправдывать свое название и для «великого, могучего, правдивого и свободного русского языка!» (И.С. Тургенев):
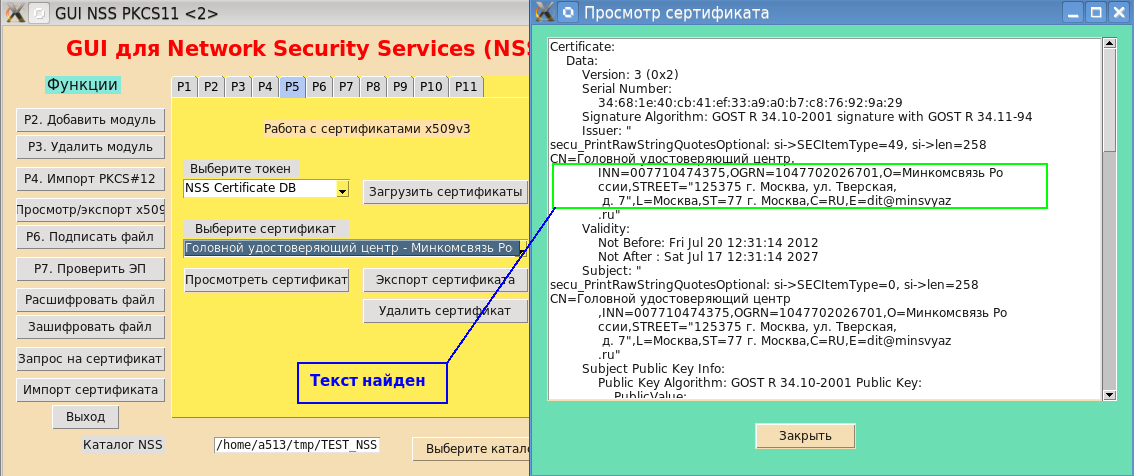
Если говорить о красоте печати, то можно было бы добавить перенос не только по количеству символов в строке, а более корректный, например, по пробелу, по запятой, двоеточию и другим символам. Я уж не говорю про семантический анализ при переносе. Но это уже область искусственного интеллекта.
И в завершение, это уже вторая обнаруженная неточность в утилитах NSS. Первая была обнаружена в утилите oidcalc.
Источник


