
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd
- Веселая Квартусель, или как процессор докатился до такой жизни
- Методы оптимизации кода для Redd. Часть 1: влияние кэша
- Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин
- Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы
- Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI
- Работа с нестандартными шинами комплекса Redd
- Практика в работе с нестандартными шинами комплекса Redd
- Проброс USB-портов из Windows 10 для удалённой работы
- Использование процессорной системы Nios II без процессорного ядра Nios II
- Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM
- Разработка простейшего логического анализатора на базе комплекса Redd
- Разработка логического анализатора на базе Redd – проверяем его работу на практике
- Делаем голову шинного USB-анализатора на базе комплекса Redd
- Моделируем поведение Quartus-проекта на Verilog в среде ModelSim
- Моделирование прошивки в среде ModelSim с использованием моделей на языке SystemC
- Проводим моделирование системы для проверки работоспособности головы USB-анализатора
Доработка кода головы
Я опущу часть опытов, скажу только, что при прикидках боевой системы выяснилась три вещи, которые я не мог предусмотреть заранее.
Первое — тактирование. Сначала я планировал тактировать систему от основного генератора, удвоив его частоту (с 50 до 100 МГц), как мы это делали для логического анализатора, а голову — от выходной частоты ULPI (60 МГц). Для этого я предусмотрел два тактовых домена. Жизнь внесла свои коррективы. Эти тактовые домены потребовали таких пространных объяснений, что статья стала не про USB-анализатор, а про них. Поэтому я избавился от двух тактовых частот. Но как всё тактировать? Решено было, что источником тактовых сигналов станет сама голова! Поэтому ей был добавлен новый порт:
output clk60,
И добавлена буквально одна строка текста:
assign clk60 = ulpi_clk;
В верилоговской части — всё. Хотя, при упаковке в компонент, мы к тактам ещё вернёмся.
Вторая доработка – сигнал GO. В логическом анализаторе в том виде, в каком он пошёл в статью, имеется одна весёлая вещь — заполнение FIFO. Давайте я покажу фрагмент готового рисунка из статьи, где мы делали логический анализатор (Разработка простейшего логического анализатора на базе комплекса Redd). Детали реализации (ширина шины) там чуть отличаются, но суть проблемы ясна.

Мы включаем DMA, в итоге сначала пробегают не данные из головы, а данные, накопившиеся в FIFO. А когда они там копились, кто же знает? Надо, как минимум, добавить операцию Flush. Здесь же я сделал сигнал, являющийся ключом, запирающим выход данных из самой головы. Пока он не взведён, голова не выдаёт данные в AVALON_ST, а значит, они не попадут и в FIFO. Соответственно, теперь вместо прямого управления сигналом шины source_valid есть внутренний флаг ядра:
logic source_valid_priv;
Именно его взводит или сбрасывает автомат. А внешний сигнал формируется с учётом бита GO:
logic go;
assign source_valid = source_valid_priv & go;
Ну, и сам бит Go формируется регистром управления:
// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
...
if (write == 1)
begin
case (address)
...
2 : begin
...
// Бит 1 - запуск анализа,
// Без него данные наружу не выйдут
go <= writedata [1];
...
Ну, и третья доработка — чисто для красоты. Но эта красота была одной из причин, почему пришлось отказаться от двух тактовых доменов. Я хотел отображать текущий адрес DMA на экране PC при работе TCL-скрипта. Возможно, это как-то даже и можно сделать, но я не нашёл правильного решения. Не вижу я порта, который можно читать через шину AVALON_MM на лету, чтобы видеть текущий адрес записи, и всё тут. Запутавшись в документе, описывающем типовые AVALON-устройства (включая и все виды DMA-контроллеров), я решил подойти к решению вопроса кардинально. Если я не могу узнать, какой адрес сейчас обрабатывается, то кто мне мешает сообщать, сколько данных отправлено в него из источника? Пусть будет так (я опять беру схему от логического анализатора, но кроме ширины шин она ничем не отличается):
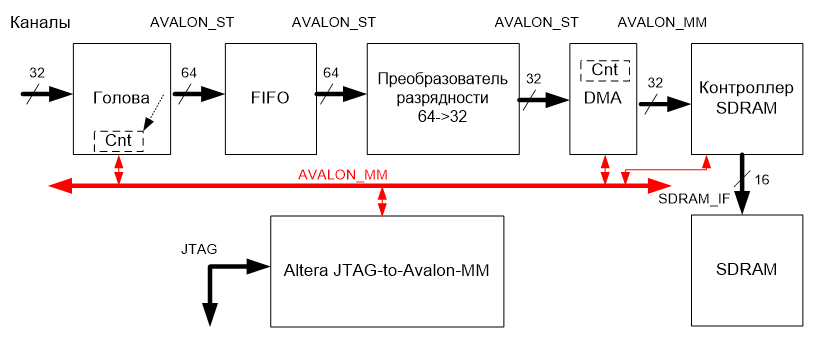
На рисунке показано, что счётчик (cnt) блока DMA не имеет выхода на шину AVALON_MM. А новый счётчик (cnt) блока «Голова» подсчитывает число транзакций записи в шину AVALON_ST и позволяет считать своё значение через шину AVALON_MM. Ну, а мы можем получить ему доступ через порт JTAG и блок Altera HTAG-to-Avalon_MM, а дальше – отобразить считанное значение на экране пусть в абсолютном виде, пусть в процентах от размера буфера. Так делают все приличные анализаторы!
Приступаем к внедрению. Добавим в ядре головы ещё один порт. Но адресное пространство шины уже всё занято четырьмя портами. Поэтому я расширил шину адреса. Теперь она выглядит так:
input [2:0] address,
Читаем счётчик так:
// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
...
// Счётчик переданных данных для красивого отображения
4: readdata <= transfer_cnt;
а формируем по перепаду GO. Типовое решение для тех, кто собрался ловить перепад – добавить в код задержку на шаг и сравнение прямого и задержанного значений. Итого:
// Это - для красоты. Счётчик переданных данных
logic [31:0] transfer_cnt = 0;
// Его красивое формирование:
logic go;
logic go_prev;
always_ff @(posedge ulpi_clk)
begin
// Для ловли перепада нам надо знать
// предыдущее значение бита "go"
go_prev <= go;
// Если анализ только что запустился - сбросили счётчик
if ((!go_prev) && (go))
transfer_cnt <= 0;
// Иначе - считаем каждый такт, когда данные уехали в AVALON_ST
else if (go & source_valid_priv)
transfer_cnt <= transfer_cnt + 1;
end
У нас ещё будут доработки головы, поэтому справочный полный текст модуля я приведу в конце статьи.
Упаковка головы в компонент
Компонент с USB-головой довольно сложен. В нём имеется целых две шины, плюс шина conduit, плюс ещё источник тактовых импульсов. Давайте потихоньку рассмотрим все особенности. Начнём с источника тактовых сигналов:
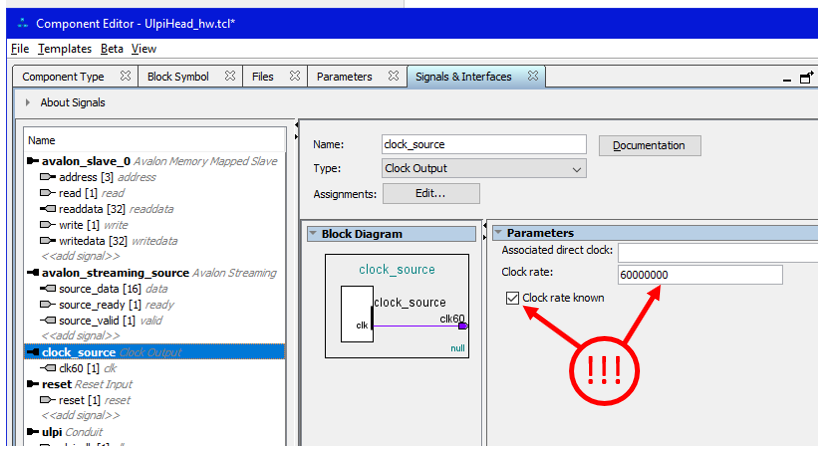
Обратите внимание, что я прописал параметр Clock rate и взвёл флажок Clock rate known. Без этого не будет собираться ядро контроллера SDRAM (оно ведь тоже будет тактироваться от этого источника). А вот так выглядит не шина, а единственный её сигнал (выделение в левом списке отличается на один уровень):
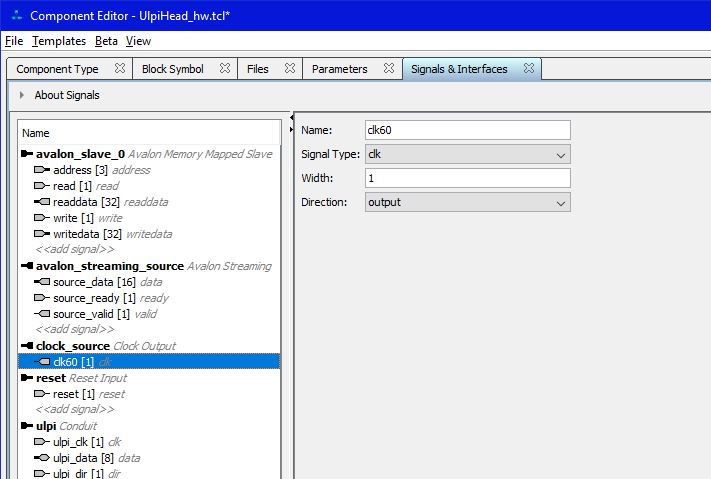
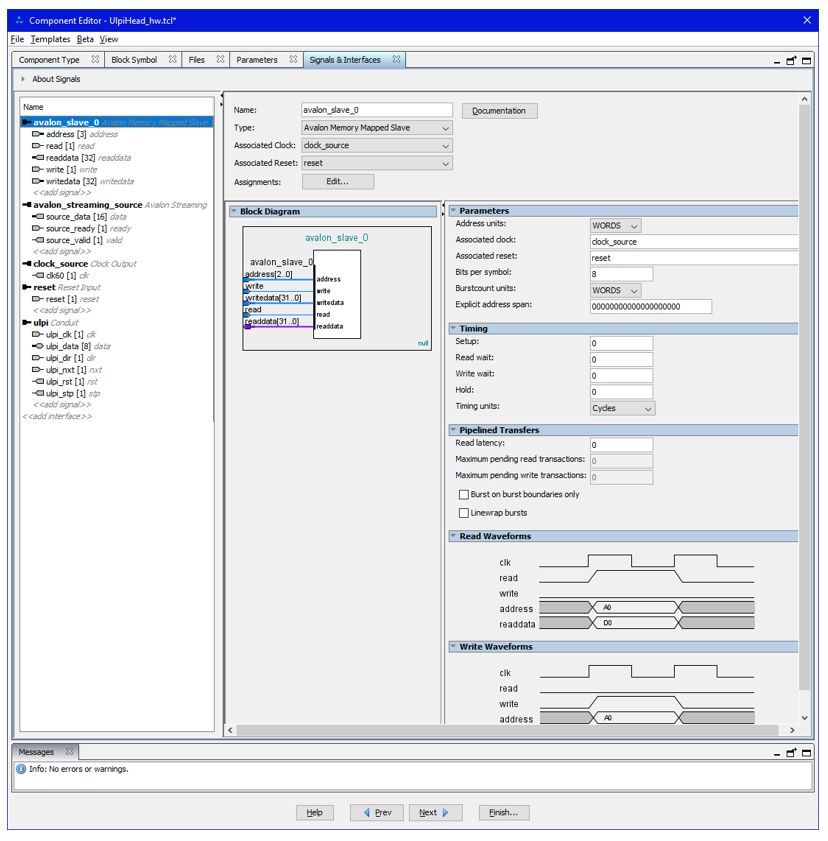
С этим понятно. Теперь шина AVALON_MM. Обратите внимание на времянку чтения. Исходно она была другой. Если я ничего не путаю, исходно параметр Read Wait был равен единице. В целом, вы всегда можете сравнивать свои настройки с моими и добиваться идентичности. Ну, и мы видим, что сопоставленным тактовым источником является тот самый clock_source, который мы только что создали.
С AVALON_ST всё проще. Но на всякий случай, покажу детали её настройки. А так, просто надо будет перетащить нужные сигналы к этой шине, но мы этим уже столько раз занимались, что уже ни для кого это не должно вызвать трудностей. Кто не занимался, советую начать с простых примеров из старых статей цикла, так как в каждом из них мы набивали руку для освоения конкретной технологии.

При подготовке шины ULPI типа conduit, возникает одна особенность, которую мы также уже проходили в статье про логический анализатор. Вот настройки шины в целом:

А особенность состоит в том, что для каждого её сигнала надо вручную прописать уникальное имя signal_type. Вот пример для линии dir:
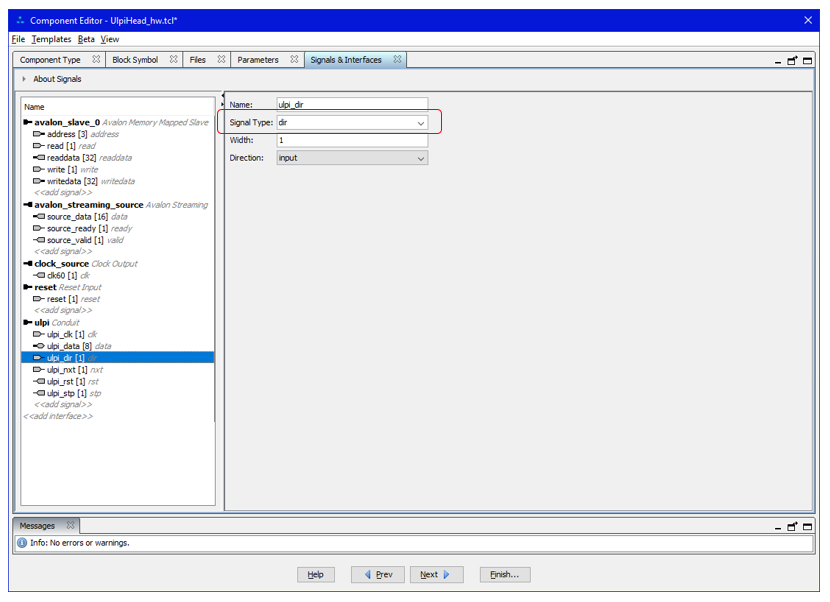
Вроде, всё. Все особенности учтены. Сохраняем компонент и строим процессорную систему с его использованием.
Внешний вид процессорной системы
Оказывается, прямо в редакторе Platform Designer можно менять цвета связей. Жаль только, что число контрастных цветов не так велико, поэтому основные линии я подкрасил вновь обнаруженными средствами редактора, а на какие контрастных цветов не хватило – по старинке, вручную.
Схема процессорной системы максимально похожа на ту, которую мы делали для логического анализатора. Поэтому рассмотрим только отличия. Первое отличие — в тактировании. Как видно, в финальном варианте блок clk_60 вообще не используется. Его можно даже удалить, но у меня просто рука не поднялась, вдруг ещё пригодится. А так, ни один из его выходов не используется, так что его выкинет оптимизатор.
Источником сброса (красная линия) является блок JTAG_TO_AVALON_MM. А источником тактового сигнала (синяя линия) — наша USB-голова.
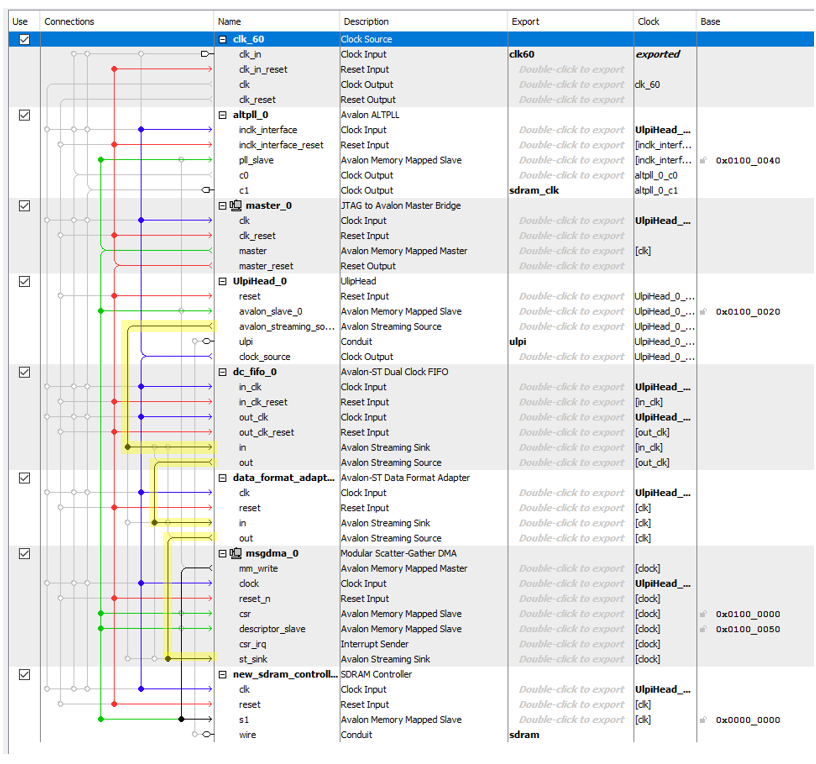
Зелёная линия — это AVALON_MM.
Блок PLL хоть и настроен на два выхода c0 и c1, но реально c0 не используется. c1 по-прежнему тактирует микросхему SDRAM. Настройки PLL просты: входная частота 60 МГц, выход c0 — 60 МГц, сдвиг 0, выход c1 — 60 МГц, сдвиг — минус 60 градусов. Приведу скриншот для настройки именно этого выхода. Вообще, про настройку PLL рассказывается тут Ускорение программы для синтезированного процессора комплекса Redd без оптимизации: замена тактового генератора.

Голова настроек не имеет. Отмечу только, что шина ULPI у нас экспортируется. Из головы начинается поток данных, идущий по жёлтым стрелкам. Поток проходит те же блоки, что и в логическом анализаторе. Можно сказать, что у анализаторов полностью идентичные туловища с поправкой на некоторые параметры.
FIFO, в отличие от логического анализатора, настроено на 16-битную шину (2 символа на слово). Именно такой выход у нашей головы.

Соответственно, преобразователь формата данных работает по схеме 16->32 (2 символа на слово на входе и 4 — на выходе):

Ну, а настройки DMA и контроллера DSRAM идентичны таковым из статьи про логический анализатор Разработка простейшего логического анализатора на базе комплекса Redd. Не будем перегружать этот текст дублями скриншотов.
Черновая проверка
Вспомогательные функции
Черновая проверка позволит нам набросать необходимую базу TCL скрипта и убедиться, что он в принципе работает. Функции для доступа к DMA я взял из кода для проверки логического анализатора. Единственно, что заменил базовые адреса на те, которые автоматически назначались для новой схемы:
variable ULPI_BASE 0x1000020
variable DMA_BASE 0x1000000
variable DMA_DESCR_BASE 0x1000050
# Чтение регистра блока DMA.
#
proc dma_reg_read { address } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
return [master_read_32 $m_path $address 1]
}
# Запись регистра блока DMA
proc dma_reg_write { address data } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
master_write_32 $m_path $address $data
}
# Запись регистра дескрипторов блока DMA
proc dma_descr_reg_write { address data } {
variable DMA_DESCR_BASE
variable m_path
set address [expr {$address * 4 + $DMA_DESCR_BASE}]
master_write_32 $m_path $address $data
}
proc prepare_dma {sdram_addr sdram_size} {
# Остановили процесс, чтобы всё понастраивать
# Да, мне лень описывать все константы,
# я делаю всё на скорую руку
dma_reg_write 1 0x20
# На самом деле, тут должно быть ожидание фактической остановки,
# но в рамках теста, оно не нужно. Точно остановимся.
# Добавляем дескриптор в FIFO
# Адрес источника (вообще, это AVALON_ST, но я всё
# с примеров списывал, а там он зануляется)
dma_descr_reg_write 0 0
# Адрес приёмника.
dma_descr_reg_write 1 $sdram_addr
# Длина
dma_descr_reg_write 2 $sdram_size
# Управляющий регистр (взводим бит GO)
dma_descr_reg_write 3 0x80000000
# Запустили процесс, не забыв отключить прерывания
dma_reg_write 1 4
}
Новые функции — это функции доступа к регистрам ULPI. Вообще, по уму там нужно ждать снятия сигнала BSY. Но я утверждаю, что шина JTAG настолько медленная, что BSY на ULPI снимется гарантированно медленнее, чем скрипт успеет сделать обращение к регистру. Поэтому я не трачу на эту заведомо бесполезную работу силы и время. Так что при записи просто положили адрес, положили данные, вышли:
proc ulpi_reg_write {reg_addr reg_data} {
variable ULPI_BASE
variable m_path
set port_addr [expr {$ULPI_BASE + 0}]
set port_data [expr {$ULPI_BASE + 4}]
# Задали адрес регистра
master_write_32 $m_path $port_addr $reg_addr
master_write_32 $m_path $port_data $reg_data
# Надо бы дождаться готовности, но JTAG точно медленнее,
# поэтому практического смысла в этом нет.
}
При чтении — положили адрес, инициировали процесс чтения, считали результат без ожидания:
proc ulpi_reg_read {reg_addr} {
variable ULPI_BASE
variable m_path
set port_addr [expr {$ULPI_BASE + 0}]
set port_data [expr {$ULPI_BASE + 4}]
set port_ctrl [expr {$ULPI_BASE + 8}]
# Задали адрес регистра
master_write_32 $m_path $port_addr $reg_addr
# Запустили процесс чтения регистра
master_write_32 $m_path $port_ctrl 1
# Ждать я не буду, JTAG стопудово медленней работает
return [master_read_32 $m_path $port_data 1]
}
Все желающие могут добавить процесс ожидания готовности самостоятельно.
В дальнейшем я просто делаю файлы, в которых сверху размещаются указанные функции, а под ними идёт основной текст скрипта. Ниже будет приводиться только основной текст.
Проверка доступности ОЗУ
Первый тест просто позволяет убедиться, что ОЗУ доступно. Основной код предельно прост:
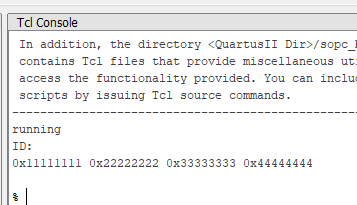
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
puts "ID:"
master_write_32 $m_path 0x00 0x11111111
master_write_32 $m_path 0x04 0x22222222
master_write_32 $m_path 0x08 0x33333333
master_write_32 $m_path 0x0c 0x44444444
puts [master_read_32 $m_path 0 4]
Если результат запуска даёт эталонный результат, значит система начерно работает. Вот такой результат получается у меня:
Проверка чтения регистров
Убедиться, что регистры читаются, удобно на регистрах идентификации. Вот что говорит на эту тему документация:

Делаем простейший скрипт:
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
puts "ID:"
puts [ulpi_reg_read 0]
puts [ulpi_reg_read 1]
puts [ulpi_reg_read 2]
puts [ulpi_reg_read 3]
Прогоняем, проверяем результат:
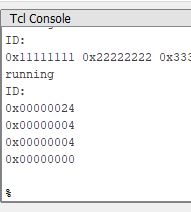
Работает! Регистры читаются верно!
Проверка записи регистров
При записи регистров я воспользуюсь одним интересным свойством. У большинства из них имеется по четыре адреса в адресном пространстве: для чтения, для полноценной записи, для установки и для сброса битов. В документации это показано так:
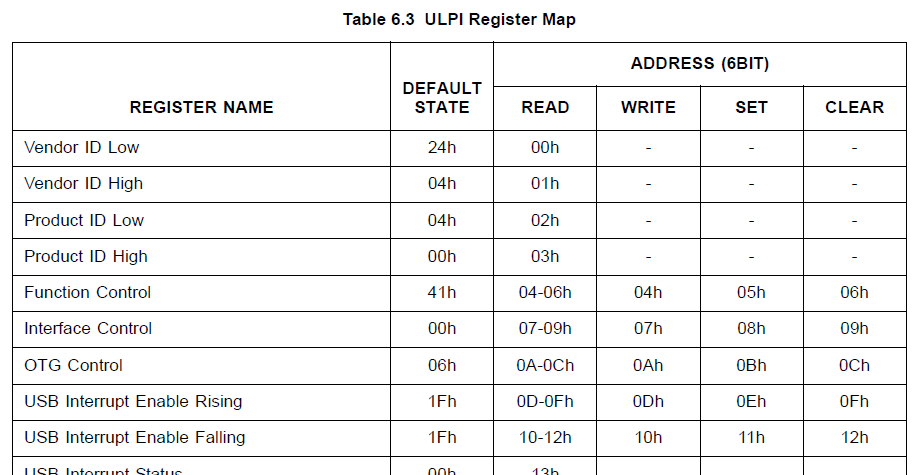
Поэтому я буду читать регистр 0x0A, писать в регистр 0x0C, а в итоге при повторном чтении в регистре 0x0A сбросятся некоторые биты!
Вот текст скрипта:
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
puts "Otg Control Before: [ulpi_reg_read 0x0a]"
# На пробу отключим подтяжку напрочь
ulpi_reg_write 0x0c 7
puts "Otg Control After: [ulpi_reg_read 0x0a]"
Вот результат:

Все кубики системы работают! Можно начинать боевые опыты…
Боевая проверка
Масса команд
Ну что ж. Пришла пора провести боевую проверку. Делаем такое основное тело скрипту (там я отключаю все резисторы шины, перевожу работу в режим FS, настраиваю DMA, взвожу GO и начинаю ждать, когда счётчик заполнения превысит запрошенный мною объём, после чего вывожу на экран начало принятого буфера):
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
# Готовим регистры к анализу
# Отключим подтяжки напрочь
ulpi_reg_write 0x0c 7
# Включаем режим Full Speed (биты 1:0 = 01)
# Зануляем TermSelect (бит 2)
# Включаем режим Non Driving (биты 4:3 = 01)
ulpi_reg_write 0x06 0x1f
ulpi_reg_write 0x05 0x09
# Собственно, всё. Теперь запускаем DMA
prepare_dma 0x00 0x1000
# Взводим бит GO
master_write_32 $m_path [expr {$ULPI_BASE + 8}] 2
# И начинаем отображать адреса
set cur_dma_addr [master_read_32 $m_path [expr {$ULPI_BASE + 0x10}] 1]
while {$cur_dma_addr < 0x100} {
puts -nonewline "$cur_dma_addr r"
after 1000
set cur_dma_addr [master_read_32 $m_path [expr {$ULPI_BASE + 0x10}] 1]
}
puts -nonewline "$cur_dma_addr r"
# Сняли бит GO
master_write_32 $m_path [expr {$ULPI_BASE + 8}] 0
puts [master_read_16 $m_path 0 128]
puts "Finished!"
Запускаем скрипт и начинаем играть в любимую игру ослика Иа «Входит-выходит». Аккуратно подключаем какое-нибудь FS-устройство. Лично мне под руку попался китайский клон USB-бластера. Результат меня сильно озадачил. Он был примерно таким:
0x4801 0x4c01 0x4801 0x4c01 0x4d01 0x4c01 0x4d01 0x4c01 0x4d01 0x4c01 0x4d01 0x4c01 0x4d01 0x4c01
Команды, команды, команды… А где данные? Но при одном из прогонов, данные промелькнули. Ровно одна посылка! Тогда я решил, что надо смотреть на данные большого объёма. Поэтому переписал скрипт так, чтобы он принимал целый мегабайт и скидывал его в файл. Тело стало выглядеть следующим образом:
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
# Готовим регистры к анализу
# Отключим подтяжки напрочь
ulpi_reg_write 0x0c 7
# Включаем режим Full Speed (биты 1:0 = 01)
# Зануляем TermSelect (бит 2)
# Включаем режим Non Driving (биты 4:3 = 01)
ulpi_reg_write 0x06 0x1f
ulpi_reg_write 0x05 0x09
# Собственно, всё. Теперь запускаем DMA
prepare_dma 0x00 0x100000
# Взводим бит GO
master_write_32 $m_path [expr {$ULPI_BASE + 8}] 2
# И начинаем отображать адреса
set cur_dma_addr [master_read_32 $m_path [expr {$ULPI_BASE + 0x10}] 1]
while {$cur_dma_addr < 0x100000} {
puts -nonewline "$cur_dma_addr r"
after 1000
set cur_dma_addr [master_read_32 $m_path [expr {$ULPI_BASE + 0x10}] 1]
}
puts -nonewline "$cur_dma_addr r"
# Сняли бит GO
master_write_32 $m_path [expr {$ULPI_BASE + 8}] 0
set fileid [open "ShowMe.txt" w]
puts $fileid [master_read_16 $m_path 0 0x40000]
close $fileid
puts "Finished!"
И вот так выглядят участки с данными:

... 0x5e01 0x5e01 0x5e01 0xa500 0x5e01 0x5e01 ...
... 0x5d01 0x5d01 0x5d01 0x8c00 0x5d01 0x5d01 ...
... 0x5c01 0x5c01 0x5c01 0xba00 0x5d01 0x5d01 ...
... 0x5d01 0x5d01 0x5d01 0xa500 0x5d01 0x5d01 ...
... 0x5e01 0x5e01 0x5e01 0x8d00 0x5e01 0x5d01 ...
... 0x5c01 0x5c01 0x5c01 0x4200 0x5c01 0x5d01 ...
Так получилось, что я знаю суть магического числа 0xA5. Это признак PID. То есть, сначала идёт пакет номер 0x8C, затем — пакет номер 0x8D… Но все они накрыты просто бешеным количеством команд. Зачем эти команды?
И тут меня осенило. Я же работаю с FS-устройством. Оно гонит данные на смешной частоте. А ULPI выдаёт их с той же частотой, с какой бы выдавал и для HS. И чем ему заполнять пустоты? Вот он командами их и заполняет! Хорошо, что я начал проверку с FS-устройства!
Значит, надо производить фильтрацию.
Фильтр номер раз
Сначала я решил, что надо фильтровать поток по факту начала пакета. То есть выводить команду только в этот момент, а остальные команды пакета игнорировать:
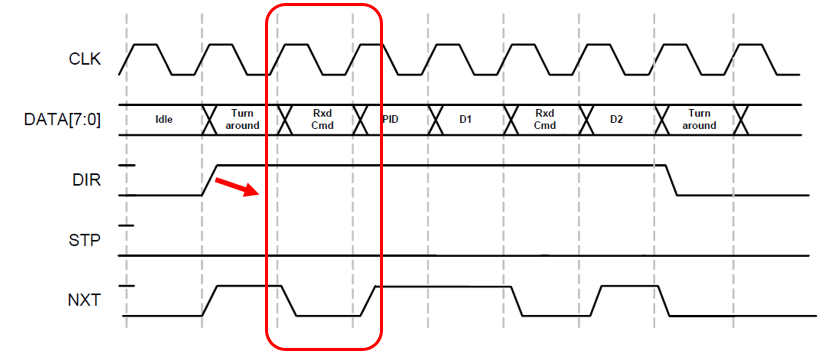
Так как решение ошибочное, я не буду приводить здесь код, который его реализует, но напомню, что это место прекрасно отлавливается, так как в это и только в это время автомат находится в состоянии wait1. Радостный, я добавил ещё один флаг и стал сохранять в памяти только команды, где он взведён. Дамп стал лучше, но всё равно весьма насыщенный:

... 0x4e03 0x4d03 0x5d03 0xa500 0xec00 0x6a00...
... 0x4d03 0x4e03 0x5d03 0xa500 0xed00 0x9200...
Здесь всё понятно. Много пакетов со сброшенным RxActive, и только перед самыми данными RxActive взлетает в единицу. Когда команда равна 5X, биты 5:4 равны 01 (RxActive равны единице). 4X же соответствует значению 00 в этих битах. Вот фрагмент из документации:
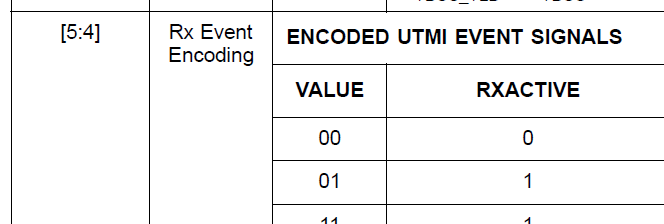
Переделываем фильтр так, чтобы он брал только значения, где RxActive равно единице. Увы и ах. Вот очень характерный участок дампа:

0x5d03 0xa500 0x1800 0x7600
0x5d03 0xa500 0x1900 0x8e00
0x5d03 0xa500 0x1a00 0xce00 0xa500 0x1b00 0x3600
0x5d03 0xa500 0x1c00 0x4e00
0x5d03 0xa500 0x1d00 0xb600
0x5d03 0xa500 0x1e00 0xf600 0xa500 0x1f00 0x0e00
0x5d03 0xa500 0x2000 0x6e00
0x5d03 0xa500 0x2100 0x9600 0xa500 0x2200 0xd600
0x5d03 0xa500 0x2300 0x2e00
0x5d03 0xa500 0x2400 0x5600
0x5d03 0xa500 0x2500 0xae00 0xa500 0x2600 0xee00
0x5d03 0x2d00 0x0000 0x1000
0x5e03 0xc300 0x8000 0x0600 0x0000 0x0100 0x0000 ...
0x5e03 0xd200
0x5d03 0x6900 0x0000 0x1000
0x5d03 0x5a00 0x6900 0x0000 0x1000
0x5e03 0x4b00 0x1200 0x0100 0x1000 0x0100 0x0000 ...
0x5e03 0xd200
0x5d03 0xe100 0x0000 0x1000
0x5d03 0x4b00 0x0000 0x0000
0x5e03 0x5a00
Мы видим, что в некоторых местах PIDы склеились, не будучи разделёнными командой (такие приклеившиеся вещи я выделил жёлтым). Значит, решение близкое к верному, но не совсем…
Фильтр номер два
Правильный фильтр я подсмотрел в проекте usbsniffer. Я был почти прав. Оказывается, в пределах одного пакета шины ULPI (то есть без падения линии DIR) может пройти несколько USB-запросов. Поэтому состояние wait1 я зря правил. Надо просто сохранять те команды, где RxActive перешёл из нуля в единицу, в каком бы месте пакета это ни случилось. Замечательно. Если мы ловим переход, то нам нужно защёлкивать прошлое значение. То есть добавить в код процесс, который его защёлкивает. Важно только защёлкивать, когда передаётся команда и не защёлкивать в остальных случаях. Признак команды живёт в source_data[8], защёлкиваемое значение — в source_data[4].
logic active_prev = 0;
always_ff @(posedge ulpi_clk)
begin
if (source_data[8])
active_prev <= source_data[4];
end
Ну, и теперь, имея текущее и предыдущее значение, мы можем написать:
logic activated;
assign activated = (!active_prev) & source_data[4];
Кто заметил, что я здесь не анализирую факт команды? Всё в порядке, это не ошибка. Просто теперь готовность шины AVALON_ST я задаю так:
assign source_valid = source_data[8]?(source_valid_priv & go & activated):(source_valid_priv & go);
Если команда, то анализировать этот флаг. Иначе — не анализировать. В итоге, получился такой симпатичный дамп, в котором все пакеты A5 начинаются после персональной команды (то есть, с начала строки):
0x5d01 0xa500 0x4e00 0x1c00
0x5d01 0xa500 0x4f00 0xe400
0x5d01 0xa500 0x5000 0x0c00
0x5d01 0xa500 0x5100 0xf400
0x5d01 0xa500 0x5200 0xb400
0x5d01 0x2d00 0x0000 0x1000
0x5e01 0xc300 0x8000 0x0600 0x0000 0x0100 0x0000 ...
0x5e01 0xd200
0x5d01 0x6900 0x0000 0x1000
0x5d01 0x5a00
0x5d01 0x6900 0x0000 0x1000
0x5e01 0x4b00 0x1200 0x0100 0x1000 0x0100 0x0000 ...
0x5e01 0xd200
Если что:
- A5 — PID_SOF
- 2D — PID_SETUP
- C3 — PID_DATA0
- D2 — PID_ACK
- 69 — PID_IN
- 4B — PID_DATA1
Вроде, последовательность пакетов вполне себе логичная. То есть, анализатор начерно работает.
Заключение
Мы проверили первичную работу USB-анализатора и убедились, что он принципиально реализуем. Дальше надо развивать его. Добавлять систему фильтрации, сжатие со вставкой временных меток и прочие полезные функции. Но как я уже упоминал раньше, можно дорабатывать быстро, делая код всё более и более непонятным, а можно так, чтобы результаты были понятны в рамках статьи. Описанный участок я оформлял сразу в виде пяти статей, чтобы ничего в будущем не забылось, но при этом поддерживая (насколько это возможно) логическую целостность при кардинальных переделках.
Поэтому в рамках цикла, за эти пять статей мы познакомились с типовой методикой разработки «прошивок» для Redd. Продумали процессорную систему, выявили недостающие блоки, написали их, отмоделировали, сделали реальную систему, содержащую блоки, отладили, выявили и устранили мелкие недостатки. Всё. Если нужно что-то большее – скорее всего, это задача не для Redd, и вам начальство просто не выделит время на самостоятельный проект. Redd – это вспомогательный элемент, а «прошивки» для него помогают отлаживать что-то другое. Так что рекомендуемая последовательность разработки под комплекс – именно такая.
Что же касается самого анализатора, то этот блок статей, как я уже упоминал раньше, был написан в июне. Дальше были сделаны заготовки ещё для пары статей (разумеется, продвинулся и сам анализатор), после чего руководство бросило меня в бой по совершенно другим задачам. И завертелось… Так что пока в теме будет сделана небольшая пауза. Но, во-первых, в планах стоит развитие анализатора, а во-вторых, рейтинг у статей такой, что видно, что они кому-то нужны (в отличие от статей про Линукс, одна из которых собрала один балл рейтинга и жалкое количество просмотров, но я пингвинов тоже не люблю). Поэтому наверняка будет продолжение. Но пока что – перерыв. Однако, все желающие могут начать свои практические исследования, опираясь на полученные знания.
Для справки.
Исходный код «головы» USB на момент завершения данной статьи выглядит так.
module ULPIhead
(
input reset,
output clk60,
// AVALON_MM
input [2:0] address,
input write,
input [31:0] writedata,
input read,
output logic [31:0] readdata = 0,
// AVALON_ST
input logic source_ready,
output logic source_valid,
output logic [15:0] source_data = 0,
// ULPI
inout [7:0] ulpi_data,
output logic ulpi_stp = 0,
input ulpi_nxt,
input ulpi_dir,
input ulpi_clk,
output ulpi_rst
);
logic have_reg = 0;
logic reg_served = 0;
logic reg_request = 0;
logic read_finished = 0;
logic [5:0] addr_to_ulpi;
logic [7:0] data_to_ulpi;
logic [7:0] data_from_ulpi;
logic write_busy = 0;
logic read_busy = 0;
logic [7:0] ulpi_d = 0;
logic force_reset = 0;
logic active_prev = 0;
logic activated;
assign activated = (!active_prev) & source_data[4];
always_ff @(posedge ulpi_clk)
begin
if (source_data[8])
active_prev <= source_data[4];
end
// Это - для красоты. Счётчик переданных данных
logic [31:0] transfer_cnt = 0;
// Его красивое формирование:
logic go;
logic go_prev;
logic source_valid_priv;
assign source_valid = source_data[8]?(source_valid_priv & go & activated):(source_valid_priv & go);
always_ff @(posedge ulpi_clk)
begin
// Для ловли перепада, нам надо знать
// предыдущее значение бита "go"
go_prev <= go;
// Если анализ только что запустился - сбросили счётчик
if ((!go_prev) && (go))
transfer_cnt <= 0;
// Иначе - считаем каждый такт, когда данные уехали в AVALON_ST
else if (go & source_valid_priv)
transfer_cnt <= transfer_cnt + 1;
end
// Формирование регистра статуса
always_ff @(posedge ulpi_clk)
begin
// Приоритет у сброса выше
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
// Приоритет у сброса выше
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
// Регистр адреса (чисто для самоконтроля)
0 : readdata <= {26'b0, addr_to_ulpi};
// Регистр данных
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - регистр управления, а он - только на запись
// Регистр статуса
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
// Счётчик переданных данных для красивого отображения
4: readdata <= transfer_cnt;
default: readdata <= 0;
endcase
end
// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
// Назначение вещей по умолчанию, они могут быть перекрыты
// внутри условия сроком на один такт
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
// Запись в регистр данных требует сложной работы
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
// Младший бит регистра инициирует процесс чтения
reg_request <= writedata[0];
// Бит 1 - запуск анализа,
// Без него данные наружу не выйдут
go <= writedata [1];
force_reset = writedata [31];
end
default: begin end
endcase
end
end
// Самый главный автомат
enum {idle,
wait1,wr_st,
wait_nxt_w,hold_w,
wait_nxt_r,wait_dir1,latch,wait_dir0
} state = idle;
always_ff @ (posedge ulpi_clk)
begin
if (reset)
begin
state <= idle;
end else
begin
// Присвоение сигналов по умолчанию
source_valid_priv <= 0;
reg_served <= 0;
ulpi_stp <= 0;
read_finished <= 0;
case (state)
idle: begin
if (ulpi_dir)
state <= wait1;
else if (have_reg)
begin
// Как я и рассуждал в документе, команду
// мы выставим прямо тут, не будем плодить
// состояния
ulpi_d [7:6] <= 2'b10;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_w;
end
else if (reg_request)
begin
// Логика - как для записи
ulpi_d [7:6] <= 2'b11;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_r;
end
end
// Здесь мы просто пропускаем такт TURN_AROUND
wait1 : begin
state <= wr_st;
// Начиная со следующего такта, можно ловить данные
source_valid_priv <= 1;
// Бит 9 в единице отмечает начало пакета
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end
// Пока не изменится сигнал DIR - гоним данные в AVALON_ST
wr_st : begin
if (ulpi_dir)
begin
// На следующем тактеа, всё ещё ловим данные
source_valid_priv <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end else
// В документе было ещё состояние wait2,
// но я решил, что оно - лишнее.
state <= idle;
end
wait_nxt_w : begin
if (ulpi_nxt)
begin
ulpi_d <= data_to_ulpi;
state <= hold_w;
end
end
hold_w: begin
// при моделировании выяснилось, что ULPI может
// быть не готова принимать данные. и снять NXT
// Добавил условие...
if (ulpi_nxt) begin
// Всё, по AVALON_MM можно принимать следующий байт
reg_served <= 1;
ulpi_d <= 0; // Шину в idle
ulpi_stp <= 1; // На один такт взвели STP
state <= idle; // А потом - уйдём в состояние idle
end
end
// От состояния STPw я решил отказаться...
// ...
// Это уже начало чтения. Ждём, когда скажут NXT
// И тем самым подтвердят, что наша команда распознана
wait_nxt_r : begin
if (ulpi_nxt)
begin
ulpi_d <= 0; // Номер регистра можно убирать
state <= wait_dir1;
end
end
// Ждём, когда нам выдадут данные
wait_dir1: begin
if (ulpi_dir)
state <= latch;
end
// Тут мы защёлкиваем данные
// и без каких-либо условий идём дальше
latch: begin
data_from_ulpi <= ulpi_data;
state <= wait_dir0;
end
// Ждём, когда шина вернётся к чтению
wait_dir0: begin
if (!ulpi_dir)
begin
state <= idle;
read_finished <= 1;
end
end
default: begin
state <= idle;
end
endcase
end
end
// Так традиционно назначается выходное значение inout-линии
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
// reset мог прийти извне, а могли его и мы сформировать
assign ulpi_rst = reset | force_reset;
assign clk60 = ulpi_clk;
endmodule


