![[Перевод] Секретный сопроцессор Apple M1: что это, зачем и как работает](https://miro.medium.com/max/700/1*VlTqk3Wqux8dx7MOdxhiCQ.png "[Перевод] Секретный сопроцессор Apple M1: что это, зачем и как работает")
Публикаций о сопроцессоре Apple Matrix (AMX) уже довольно много. Но большинство не особо понятны всем и каждому. Я же попытаюсь объяснить нюансы работы сопроцессора понятным языком.
Почему Apple не слишком распространяется об этом сопроцессоре? Что в нем такого секретного? И если вы читали о Neural Engine в SoC M1, у вас могут возникнуть затруднения в плане понимания, что такого необычного в AMX.
Но для начала вспомним базовые вещи (если вы хорошо знаете, что такое матрицы, а таких читателей, уверен, на Хабре большая часть, то первый раздел можете пропускать, — прим. перев.).
Что такое матрица?
Если по-простому, то это таблица с числами. Если вы работали в Microsoft Excel, то, значит, вы имели дело с подобием матриц. Ключевым отличием матриц от обычных таблиц с числами — в операциях, которые можно с ними выполнять, а также специфической сути. Матрицу можно представить в виде самых разных форм. Например, в виде строк, тогда это вектор-строка. Или в виде столбца, тогда это, что вполне логично, вектор-столбец.

Мы можем складывать, вычитать, масштабировать и умножать матрицы. Сложение — самая простая операцияо. Вы просто добавляете каждый элемент отдельно. Умножение немного сложнее. Вот простой пример.
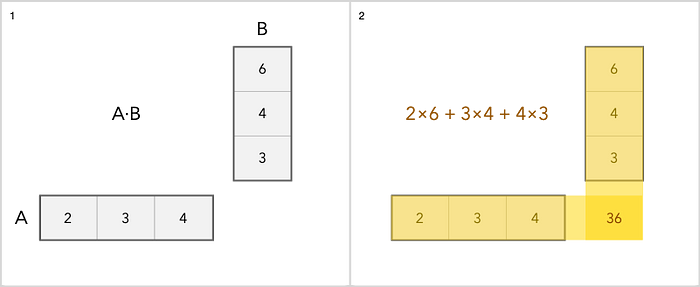
Что касается прочих операций с матрицами, об этом можно почитать здесь.
Почему мы вообще заговорили о матрицах?
Дело в том, что они повсеместно используются в:
• Обработке изображений.
• Машинном обучении.
• Распознавании рукописного текста и речи.
• Сжатии.
• Работе с аудио и видео.
Что касается машинного обучения, то для этой технологии нужны производительные процессоры. И просто добавить несколько ядер в чип — не вариант. Сейчас ядра «заточены» под выполнение определенных задач.

Количество транзисторов в процессоре ограничено, соответственно, количество задач/модулей, которые можно добавить в чип, тоже ограничено. В целом, можно бы просто добавить еще ядер в процессор, но это просто ускорит выполнение стандартных вычислений, которые и так выполняются быстро. Поэтому в Apple решили пойти другим путем и выделить модули для обработки изображений, декодирования видео и выполнения задач машинного обучения. Эти модули — сопроцессор и ускорители.
В чем разница между сопроцессором Apple Matrix и Neural Engine?
Если вы интересовались Neural Engine, то, вероятно, знаете, что он также выполняет операции с матрицами для работы с задачами машинного обучения. Но если так, то зачем тогда понадобился еще и сопроцессор Matrix? Может быть, это одно и тоже? Я ничего не путаю? Разрешите мне прояснить ситуацию и рассказать, в чем же разница, объяснив, почему нужны обе технологии.
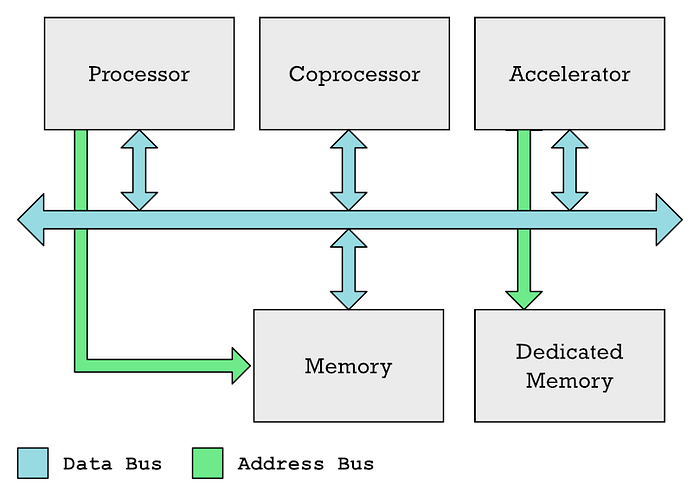
Главный процессор (ЦП), сопроцессоры и ускорители обычно могут обмениваться данными по общей шине данных. ЦП обычно контролирует доступ к памяти, в то время как ускоритель, такой как GPU, часто имеет собственную выделенную память.
Признаю, что в своих прежних статьях я использовал термины «сопроцессор» и «ускорители» в качестве синонимов, хотя это не одно и то же. Так, GPU и Neural Engine — ускорители разных типов.
В обоих случаях у вас есть специальные области памяти, которые ЦП должен заполнить данными, которые он хочет обработать, плюс еще одна область памяти, которую CPU заполняет списком инструкций, которые должен выполнить ускоритель. Процессору требуется время для выполнения этих задач. Приходится все это координировать, заполнять данные, а затем ждать получения результатов.
И подобный механизм годен для масштабных задач, а вот для малых тасков это уже перебор.

В этом преимущество сопроцессоров перед ускорителями. Сопроцессоры сидят и следят за потоком инструкций машинного кода, которые поступают из памяти (или, в частности, кеша) в ЦП. Сопроцессор вынужден реагировать на конкретные инструкции, которые они были заставлены обрабатывать. Между тем, ЦП в основном игнорирует эти инструкции или помогает облегчить их обработку сопроцессором.
Преимущество заключается в том, что инструкции, выполняемые сопроцессором, можно включить в обычный код. В случае GPU все иначе — программы шейдеров помещаются в отдельные буферы памяти, которые затем нужно явно переносить в GPU. Использовать для этого обычный код не получится. И как раз поэтому AMX отлично подходит для выполнения простых задач, связанных с обработкой матриц.
Нюанс здесь в том, что требуется определить инструкции в архитектуре набора инструкций (ISA) вашего микропроцессора. Таким образом, при использовании сопроцессора применяется более тесная интеграция с процессором, чем при использовании ускорителя.
Создатели ARM, кстати, долгое время сопротивлялись добавлению кастомных инструкций в ISA. И это — одно из преимуществ RISC-V. Но в 2019 году разработчики сдались, заявив однако следующее: «Новые инструкции сочетаются со стандартными инструкциями ARM. Чтобы избежать фрагментации программного обеспечения и поддерживать согласованную среду разработки программного обеспечения, ARM ожидает, что клиенты будут использовать пользовательские инструкции в основном в вызываемых библиотечных функциях».
Это может быть хорошим объяснением отсутствию описания AMX-инструкций в официальной документации. ARM просто ожидает от Apple того, что компания включит инструкции в библиотеках, предоставленных клиентом (в этом случае Apple).
А в чем отличие матричного сопроцессора от векторного SIMD?
В общем-то не так сложно спутать матричный сопроцессор с векторной SIMD-технологией, которая есть в большинстве современных процессоров, включая ARM. SIMD расшифровывается как Single Instruction Multiple Data.

SIMD позволяет увеличить производительность системы в случае необходимости выполнения одной и той же операции над несколькими элементами, что тесно связано с матрицами. В общем-то, инструкции SIMD, включая инструкции ARM Neon или Intel x86 SSE или AVX, часто используются для ускорения умножения матриц.
Но векторный движок SIMD — часть ядра микропроцессора, так же как и ALU (модуль арифметической логики) и FPU (модуль с плавающей запятой) являются частью ЦП. Ну а уже декодер инструкций в микропроцессоре «решает» какой функциональный блок активировать.

А вот сопроцессор — это отдельный физический модуль, а не часть ядра микропроцессора. Раньше, например, Intel’s 8087 был отдельным чипом, который предназначался для ускорения операций с плавающей запятой.

Вам может показаться странным, что кто-то разработал такую сложную систему, с отдельным чипом, который обрабатывает данные, идущие от памяти в процессор, с целью обнаружить инструкцию с плавающей запятой.
Но ларчик открывается просто. Дело в том, что в оригинальном 8086 процессоре было всего 29 000 транзисторов. У 8087 их было уже 45 000. В конечном итоге технологии позволили интегрировать FPU-модули в основной чип, избавившись от сопроцессоров.
Но почему AMX не является частью ядра Firestorm в М1 — не совсем понятно. Может быть, Apple просто решила вывести нестандартные ARM-элементы за пределы основного процессора.
Но почему про AMX не особо говорят?
Если AMX не описан в официальной документации, как мы вообще смогли о нем узнать? Спасибо разработчику Дугаллу Джонсону, кто выполнил прекрасный реверс-инжиниринг M1 и обнаружил сопроцессор. Его работа описана вот здесь. Как оказалось, для математических операций, связанных с матрицами Apple создала специализированные библиотеки и/или фреймворки вроде Accelerate. Все это включает следующие элементы:
• vImage — обработка изображений более высокого уровня, такая как преобразование между форматами, манипулирование изображениями.
• BLAS — своего рода отраслевой стандарт линейной алгебры (то, что мы называем математикой, имеющей дело с матрицами и векторами).
• BNNS — используется для запуска нейронных сетей и обучения.
• vDSP — цифровая обработка сигналов. Преобразования Фурье, свертка. Это математические операции, выполняемые при обработке изображения или любого сигнала, содержащего звук.
• LAPACK — функции линейной алгебры более высокого уровня, например, решение линейных уравнений.
Джонсон понимал, что именно эти библиотеки будут использовать сопроцессор AMX для ускорения вычислений. Поэтому он разработал специализированный софт для анализа и мониторинга действий библиотек. В конечном итоге ему удалось обнаружить недокументированные инструкции машинного кода AMX.
А Apple не документирует все это потому, что ARM LTD. старается не особо афишировать информацию. Дело в том, что если кастомные функции действительно будут широко применяться, это может привести к фрагментации экосистемы ARM, о чем и говорилось выше.
У Apple появляется возможность, не особо афишируя все это, позже изменить работу систем при необходимости — например, удалять или добавлять AMX-инструкции. Для разработчиков достаточно платформы Accelerate, все остальное система сделает сама. Соответственно, Apple может контролировать как оборудование, так и ПО для него.
Преимущества сопроцессора Apple Matrix
Здесь много всего, отличный обзор возможностей элемента сделала компания Nod Labs, которая специализируется на машинном обучении, интеллекте и восприятии. Они, в частности, выполнили сравнительные тесты производительности AMX2 и NEON.
Как оказалось AMX в два раза быстрее выполняет необходимые для выполнения действий с матрицами операции. Это не значит, конечно, что AMX лучше всех, но для машинного обучения и высокопроизводительных вычислений — да.
В качестве вывода можно сказать, что сопроцессор Apple — впечатляющая технология, которая дает Apple ARM преимущество в задачах машинного обучения и высокопроизводительных вычислений.



