Усложнённую технику рандомизированного отклика первой применила Google для сбора статистики Chrome. Последует ли Apple этому примеру?
Об авторе. Мэтью Грин: криптограф, профессор университета Джонса Хопкинса, автор блога о разработке криптографических систем
Опубликовано 14 июня 2016 года
![[Перевод] Что такое дифференциальная приватность](https://habrastorage.org/files/abf/406/46d/abf40646d0694fb89c32ca78fc9fed68.jpg "[Перевод] Что такое дифференциальная приватность") Вчера на выступлении WWDC компания Apple представила ряд новых функций для безопасности и защиты конфиденциальных данных, в том числе одну функцию, которая вызвала особое внимание… и замешательство. А именно, Apple объявила об использовании новой техники под названием «дифференциальная приватность» («Differential Privacy», сокращённо: DP), чтобы улучшить защиту приватность при сборе конфиденциальных данных пользователей.
Вчера на выступлении WWDC компания Apple представила ряд новых функций для безопасности и защиты конфиденциальных данных, в том числе одну функцию, которая вызвала особое внимание… и замешательство. А именно, Apple объявила об использовании новой техники под названием «дифференциальная приватность» («Differential Privacy», сокращённо: DP), чтобы улучшить защиту приватность при сборе конфиденциальных данных пользователей.
У большинства людей это вызвало немой вопрос: «что за…???», потому что мало кто раньше слышал о дифференциальной приватности, а уж тем более понимает, что это значит. К сожалению, Apple не отличается кристальной открытостью, когда дело касается секретных инргедиентов, на которых работает их платформа, так что остаётся надеяться, что в будущем она решит опубликовать больше информации. Всё, что мы знаем на данный момент, содержится в руководстве для Apple iOS 10 Preview.
«Начиная с версии iOS 10, Apple использует технологию дифференциальной приватности для помощи в выявлении шаблонов пользовательского поведения большого количества пользователей без угрозы для приватности каждого из них. Для скрытия личности человека дифференциальная приватность добавляет математический шум к маленькому образцу индивидуального шаблона пользовательского поведения конкретного пользователя. Когда больше людей проявляют такой же шаблон, начинают вырисовываться общие шаблоны, которые способны информировать нас и улучшить общий пользовательский опыт. В iOS 10 эта технология поможет улучшить подсказки QuickType и эмодзи, подсказки Spotlight, а также советы Lookup Hints в Notes».
Если вкратце, похоже на то, что Apple хочет собирать гораздо больше данных с вашего телефона.
В основном, они делают это с целью улучшения своих сервисов, а не для сбора информации об индивидуальных привычках и особенностях каждого пользователя. Чтобы гарантировать это, Apple намерена применить сложные статистические техники для гарантии, что совокупная база — результат вычисления статистической функции после обработки всей вашей информации — не выдаёт отдельных участников. В принципе, звучит вполне неплохо. Но конечно, дьявол всегда прячется в деталях.
Хотя у нас нет этих деталей, похоже, сейчас самое время по крайней мере поговорить о том, что такое дифференциальная приватность, как она может быть реализована и что это может значить для Apple — и для вашего iPhone.
Мотивация
В последние несколько лет «обычный пользователь» привык к мысли о том, что с его устройства отправляется огромное количество личной информации в различные сервисы, которые он использует. Опросы общественного мнения также показывают, что граждане начинают чувствовать дискомфорт по этой причине.
Этот дискомфорт имеет смысл, если подумать о тех компаниях, которые используют нашу личную информацию, чтобы заработать на нас. Однако иногда есть пристойные основания, чтобы собирать информацию о действиях пользователя. Например, Microsoft недавно представила инструмент, который способен диагностировать рак поджелудочной железы с помощью анализа ваших поисковых запросов в Bing. Компания Google поддерживает работу известного сервиса Google Flu Trends для предсказания распространения инфекционных заболеваний по частоте поисковых запросов в различных районах. И конечно, все мы получаем выгоду от краудсорсинговых данных, которые повышают качество сервисов, используемых нами, — от картографических приложений до отзывов в ресторанах.
К сожалению, даже сбор данных в благих целях может нанести вред. Например, в конце 2000-х компания Netflix объявила конкурс на разработку лучшего алгоритма рекомендаций для художественных фильмов. В помощь участникам конкурса они опубликовали «анонимизированный» набор данных со статистикой просмотров пользователями фильмов, удалив оттуда всю личную информацию. К сожалению, такой «деидентификации» оказалось недостаточно. В известной научной работе Нараян и Шматиков показали, что такие наборы данных можно использовать для деанонимизации конкретных пользователей — и даже для предсказания их политических взглядов! — просто если вы знаете немного дополнительной информации об этих пользователях.
Такие вещи должны беспокоить нас. Не просто потому что коммерческие компании привычно обмениваются между собой собранной информацией о пользователях (хотя они это делают), а потому что случаются взломы, и потому что даже статистика о собранной базе данных может каким-то образом прояснить детали о конкретных индивидуальных записях, которые использовались для составления аггрегированной выборки. Дифференциальная приватность — это набор инструментов, который спроектирован для решения этой проблемы.
Что такое дифференциальная приватность?
Дифференциальная приватность — определение защиты пользовательских данных, изначально предложенное компанией Cynthia Dwork в 2006 году. Грубо говоря, вкратце её можно описать следующим образом:
Представьте, что у вас есть две во всех остальных отношениях идентичные базы данных, одна с вашей информацией внутри, а другая без неё. Дифференциальная приватность гарантирует, что статистический запрос к одной и второй базе данных выдаст определённый результат с (почти) одинаковой вероятностью.
Это можно представить следующим образом: DP даёт возможность понять, оказывают ли ваши данные какое-то статистически значимое влияние на результат запроса. Если нет, то их можно без опасений вносить в базу, потому что от этого будет практически никакого вреда. Рассмотрим такой глупый пример:
Представьте, что вы активировали на своём iPhone опцию сообщать в компанию Apple о том, что вы часто используете эмодзи  в своих чат-сессиях iMessage. Этот отчёт состоит из одного бита информации: 1 означает, что вам нравится , а 0 — что нет. Apple может получать эти отчёты и вносить их в гигантскую базу данных. В итоге компания хочет иметь возможность узнать количество пользователей, которым нравится определённый эмодзи.
в своих чат-сессиях iMessage. Этот отчёт состоит из одного бита информации: 1 означает, что вам нравится , а 0 — что нет. Apple может получать эти отчёты и вносить их в гигантскую базу данных. В итоге компания хочет иметь возможность узнать количество пользователей, которым нравится определённый эмодзи.
Само собой разумеется, что простой процесс суммирования результатов и их публикации не удовлетворяет определению DP, потому что арифметическая операция суммы значений в базе данных, которая содержит вашу информацию, потенциально выдаст другой результат, чем суммирование значений из базы данных, где отсутствует ваша информация. Поэтому, хотя такие суммы выдадут немного информации о вас, но всё-таки фрагмент персональной информации просочится. Главнейшим выводом исследования дифференциальной приватности является то, что во многих случаях принципа DP можно достичь, если добавить случайный шум к результату. Например, вместо простого сообщения итогового результата отчётная сторона может внедрить распределение Гаусса или Лапласа, так что результат будет не таким точным — но он замаскирует каждое конкретное значение в базе. (Для других интересных функций есть много других техник).
Что ещё более ценно, вычисление количества добавляемого шума может быть сделано без знания содержимого самой базы данных (или даже её размера). Именно так, вычисление с шумом может быть осуществлено на основании только знания самой функции, которая выполняется, и приемлемого уровня утечки данных.
Компромисс между приватностью и точностью
Теперь очевидно, что подсчёт количества любителей среди пользователей — довольно неудачный пример. В случае с DP важно то, что одинаковый общий подход можно применять для гораздо более интересных функций, в том числе для сложных статистических вычислений, как те, которые используются в системах машинного обучения. Его можно применить даже в том случае, если много различных функций вычисляются на одной и той же базе данных.
Но есть один подвох. Дело в том, что размер «информационной утечки» от одного-единственного запроса можно минимизировать в небольших границах, но он не будет равен нулю. Каждый раз, когда вы отправляете запрос к базе данных с какой-нибудь функцией, общая «утечка» увеличивается — и никогда не может быть уменьшена. Со временем, по мере увеличения количества запросов, утечка может начать расти.
Это один из самых сложных аспектов DP. Он проявляется двумя основными способами:
- Чем больше вы намерены «спрашивать» у базы данных, тем больше шума придётся добавить, чтобы минимизировать утечку информации. Это значит, что DP, фактически, представляет собой фундаментальный компромисс между точностью и защитой персональных данных, что может вылиться в большую проблему при тренировке сложных моделей машинного обучения.
- Как только данные утекли, они пропали. Когда утечка информации выходит за расчётные пределы, которые говорят, что вы в безопасности, то дальше продолжать нельзя — по крайней мере, без риска для приватности пользователей. В такой ситуации лучшим решением может быть просто уничтожить базу данных и начать всё сначала. Если такое возможно.
Общее количество разрешённой утечки часто обозначается как «бюджет приватности», и он определяет, как много запросов разрешено сделать (и насколько точными будут результаты). Основной урок DP состоит в том, что дьявол прячется в бюджете. Установи его слишком высоким, и произойдёт утечка важных данных. Установи его слишком низким, и полученные результаты запросов могут быть бесполезными.
Сейчас в некоторых приложениях, как большинство приложений в наших «айфонах», недостаточная точность не станет особой проблемой. Мы привыкли, что наши смартфоны делают ошибки. Но временами, когда DP используется в сложных приложениях, таких как тренировка моделей машинного обучения, это действительно важно.
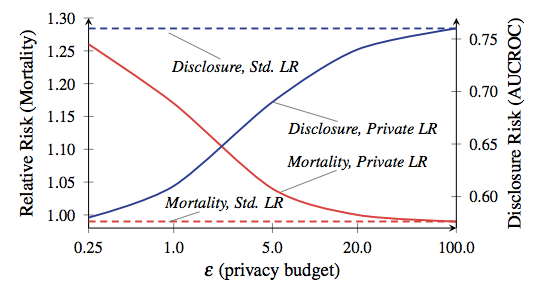
Соотношение смертности и раскрытия информации, из работы Фредериксона и др. от 2014 года. Красная линия соответствует смертности пациентов.
Чтобы дать вам абсолютно сумасшедший пример, насколько важным может быть компромисс между приватностью и точностью, посмотрите на эту научную работу Фредериксона и др. от 2014 года. Авторы начали с того, что соотнесли данные о дозировках лекарств из открытой базы данных Warfarin со специфическими генетическими маркерами. Затем они применили техники машинного обучения для разработки модели расчёта дозировок по данным из базы — но применили DP с различными параметрами бюджета приватности во время обучения модели. Затем они оценили уровень утечки информации и успешность применения модели для лечения виртуальных «пациентов».
Результаты показали, что точность модели сильно зависит от бюджета приватности, установленного во время её обучения. Если бюджет установлен слишком высоким, то из базы происходит утечка значительное количество конфиденциальной информации о пациентах — но полученная модель принимает решения о дозировке, настолько же безопасные, как и стандартная клиническая практика. С другой стороны, когда бюджет уменьшен до уровня, означающего приемлемую приватность, обученная на зашумлённых данных модель склонна убивать своих «пациентов».
До того как вы начали паниковать, позвольте объяснить: ваш iPhone не собирается вас убивать. Никто не говорит, что этот пример хотя бы отдалённо похож на то, что Apple собирается делать на смартфонах. Вывод из данного исследования просто состоит в том, что есть интересный компромисс между эффективностью и защитой приватности в каждой системе на основе DP — этот компромисс в значительной степени зависит от конкретных решений, которые сделали разработчики системы, выбранных параметров работы и т.д. будем надеяться, что Apple скоро скажет нам, какими были эти варианты.
В любом случае, как собирать данные?
вы заметили, что во всех вышеприведённых примерах я предположил, что запросы осуществляются доверенным оператором базы данных, который имеет доступ ко всем исходным «сырым» лежащим в основе данным. Я выбрал эту модель, потому что это традиционный вариант модели, которая используется почти во всей литературе, а не потому что это хорошая идея.
На самом деле, возникнут основания для тревоги, если Apple действительно реализует свою систему подобным образом. Это потребует от Apple собирать всю исходную информацию о действиях пользователей в массивную централизованную базу данных, а затем («верьте нам!») вычислять статистику на ней безопасным способом с защитой приватности пользователей. Как минимум, такой способ делает информацию доступной для получения по судебным повесткам, а также для иностранных хакеров, любопытных топ-менеджеров Apple и так далее.
К счастью, это не единственный способ реализовать систему дифференциальной приватности. Теоретически, статистику можно вычислять с использованием причудливых криптографических техник (таких как протокол конфиденциального вычисления или полностью гомоморфное шифрование). К сожалению, эти техники, вероятно, слишком неэффективны для использования на тех масштабах, которые нужны Apple.
Гораздо более перспективным подходом видится не собирать «сырые» данные вообще. Этот подход недавно первой среди всех использовала компания Google для сбора статистики в браузере Chrome. Их система под названием RAPPOR основана на реализации 50-летней техники рандомизированного ответа. Рандомизированный ответ работает следующим образом:
- Когда пользователь хочет выслать фрагмент потенциально чувствительной информации (придуманный пример: ответ на вопрос «Вы используете Bing?»), они сначала подбрасывают монетку, и если монетка выпадает «орлом», то возвращается случайный ответ — рассчитанный подбросом другой монетки. В противном случае высылается честный ответ.
- Сервер собирает ответы от всей выборки пользователей и (зная вероятность, с которой монета выпадает «орлом»), подстраивается на имеющийся уровень «шума» для вычисления приблизительного ответа для правдивого отклика.
На интуитивном уровне, рандомизированный отклик защищает приватность индивидуальных пользовательских отчётов, потому что ответ «да» может означать или «Да, я использую Bing», или просто быть результатом случайного выпадения монеток. На формальном уровне, рандомизированный отклик действительно обеспечивает дифференцированную приватность, с конкретными гарантиями, которые можно настраивать путём регулировки характеристик монет.
RAPPOR берёт эту относительно старую технику и превращает её в нечто гораздо более мощное. Вместо простого ответа на один вопрос, система может составлять отчёт по сложному вектору вопросов и даже возвращать сложные ответы, такие как строки — например, какая у вас установлена домашняя страница в браузере. Последнее достигается так, что сначала строку пропускают через фильтр Блума — последовательность битов, сгенерированную с использованием хеш-функций очень специфическим образом. Полученные биты затем смешиваются с шумом и суммируются, а ответы восстанавливаются с помощью (довольного сложного) процесса декодирования.
 Хотя нет явных доказательств, что Apple использует систему вроде RAPPOR, на это указывает несколько маленьких подсказок. Например, Крейг Федериги (Craig Federighi, в жизни он выглядит точно так же, как на фото) описывает дифференцированную приватность как «использование хеширования, субсемплирования и зашумления для активации… краудсорсингового обучения при сохранении данных индивидуальных пользователей полностью приватными». Это довольно слабое доказательство чего бы там ни было, наверное, но присутствие «хеширования» в этой цитате по крайней мере наводит на мысль об использовании фильтров в стиле RAPPOR.
Хотя нет явных доказательств, что Apple использует систему вроде RAPPOR, на это указывает несколько маленьких подсказок. Например, Крейг Федериги (Craig Federighi, в жизни он выглядит точно так же, как на фото) описывает дифференцированную приватность как «использование хеширования, субсемплирования и зашумления для активации… краудсорсингового обучения при сохранении данных индивидуальных пользователей полностью приватными». Это довольно слабое доказательство чего бы там ни было, наверное, но присутствие «хеширования» в этой цитате по крайней мере наводит на мысль об использовании фильтров в стиле RAPPOR.
Главной трудностью с системами рандомизированного отклика является то, что они могут выдавать конфиденциальные данные, если пользователь отвечает на один и тот же вопрос несколько раз. RAPPOR пытается решить эту проблему несколькими способами. Один из них — определить статичную часть информации и так вычислить «перманентный ответ» вместо того, чтобы заново рандомизировать его каждый раз. Но возможно представить ситуации, где такая защита не сработает. Ещё раз, дьявол очень часто прячется в деталях — просто нужно их увидеть. Я уверен, много увлекательных научных работ будет опубликовано в любом случае.
Так использование DP компанией Apple — это хорошо или плохо?
Как у учёного и специалиста по информационной безопасности у меня смешанные чувства на этот счёт. С одной стороны, как учёный я понимаю, насколько интересно наблюдать за внедрением передовых научных разработок в реальном продукте. И Apple предоставляет очень большую площадку для таких экспериментов.
С другой стороны, как у специалиста по практической безопасности, мой долг сохранять скептицизм — компания должна при малейших вопросах показывать код, критически важный для безопасности (как Google сделала с RAPPOR), или хотя бы откровенно изложить, что конкретно она реализует. Если Apple планирует собирать массивные объёмы новых данных с устройств, от которым мы так зависим, то мы должны быть действительно уверены, что они делают всё правильно — а не бурно аплодировать им за Внедрение Таких Крутых Идей. (Я уже однажды сделал такую ошибку, и всё ещё чувствую себя дураком из-за этого).
Но возможно, всё это слишком глубокие детали. В конце концов, определённо выглядит так, что Apple честно пытается сделать что-то для защиты конфиденциальной информации пользователей, и с учётом альтернатив, это может быть важнее всего.

