В преддверии супер-интенсива «ELK» подготовили для вас перевод полезной статьи.
Данные Twitter можно получить множеством способов — но кому хочется заморачиваться и писать код? Особенно такой, который будет работать без перебоев и перерывов. В Elastic Stack вы можете с легкостью собирать данные из Twitter и анализировать их. Logstash может в качестве входных данных собирать твиты. Инструмент Kafka Connect, которому посвящена недавняя статья, тоже предоставляет такую возможность, но Logstash может отправлять данные во многие источники (включая Apache Kafka) и проще в использовании.
В этой статье мы рассмотрим следующие вопросы:
-
Сохранение потока твитов в Elasticsearch через Logstash
-
Визуализации в Kibana (сравнение Xbox и PlayStation)
-
Удаление HTML-тегов для ключевого слова с использованием механизма стандартизации
Окружение Elastic Search
Все необходимые компоненты находятся в одном Docker Compose. Если у вас уже есть кластер Elasticsearch, вам понадобится только Logstash.
version: '3.3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.2
restart: unless-stopped
environment:
- discovery.type=single-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata:/usr/share/elasticsearch/data
restart: unless-stopped
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:7.9.2
restart: unless-stopped
depends_on:
- elasticsearch
ports:
- 5601:5601
logstash:
image: docker.elastic.co/logstash/logstash:7.9.2
volumes:
- "./pipeline:/usr/share/logstash/pipeline"
environment:
LS_JAVA_OPTS: "-Xmx256m -Xms256m"
depends_on:
- elasticsearch
restart: unless-stopped
volumes:
esdata:
driver: localКонвейер Logtash
input {
twitter {
consumer_key => "loremipsum"
consumer_secret => "loremipsum"
oauth_token => "loremipsum-loremipsum"
oauth_token_secret => "loremipsum"
keywords => ["XboxSeriesX", "PS5"]
full_tweet => false
codec => "json"
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "tweets"
}
}Чтобы получить токены и ключи, вам понадобится аккаунт разработчика и приложения Twitter. Этим кодом вы «улаживаете все формальности».
Конфигурация самого конвейера очень проста. Поток твитов будет подбираться по словам в keywords. Если вам нужно больше метаданных, просто присвойте параметру full_tweet value значение true.
Данные
Спустя некоторое время после выполнения команды docker-compose up -d в индексе tweets появляются данные. На момент написания этой статьи мои данные собирались примерно два дня. Весь индекс весил около 430 МБ, что не так уж и много. Возможно, другая лицензия позволила бы получить больший поток данных. Визуализации в этой статье отображают данные, собранные за два дня.
![[Перевод] Анализ данных Twitter для ленивых в Elastic Stack (сравнение Xbox и PlayStation)](https://habrastorage.org/getpro/habr/upload_files/780/d6a/5de/780d6a5deffae21f9511e8555495da4b.png "[Перевод] Анализ данных Twitter для ленивых в Elastic Stack (сравнение Xbox и PlayStation)")
Итак, у нас уже есть индекс tweets. Чтобы иметь возможность использовать собранные данные в Kibana, необходимо добавить шаблон индекса.

Облако тегов — Xbox и PlayStation
Простое облако тегов с агрегацией hashtags.text.keyword. PS5, судя по всему, выигрывает, но рассмотрим и другие варианты визуализации.

Линейный график — Xbox и PlayStation
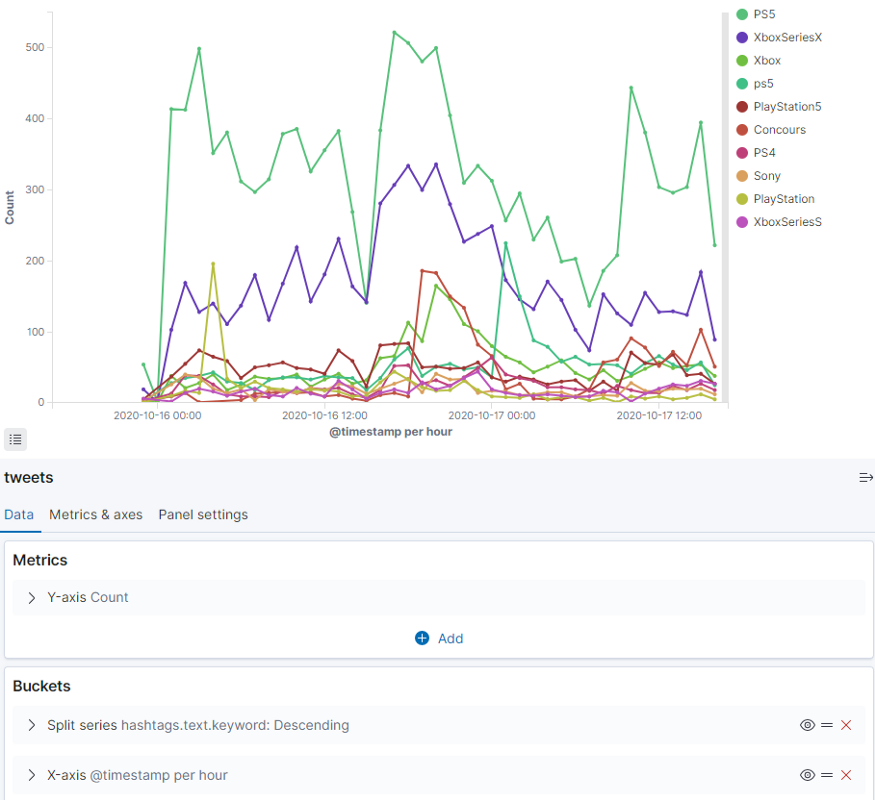
Тут у меня тоже складывается впечатление, что PlayStation встречается чаще, чем Xbox. Чтобы узнать наверняка, попробуем сгруппировать хештеги. Некоторые пишут PS5, другие — ps5, а ведь это один и тот же продукт.
Однако прежде чем двигаться дальше, обратим внимание на один момент. Важен ли порядок бакетов? Разумеется. Вот что произойдет, если изменить гистограмму из Terms.
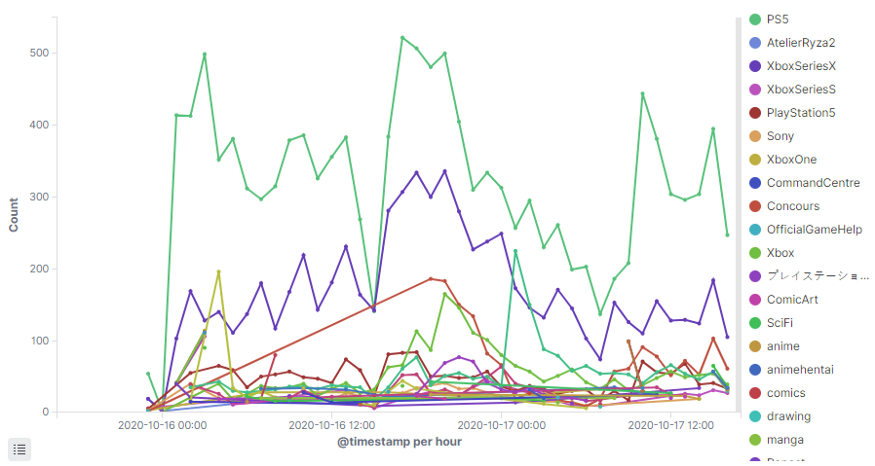
Чтобы сгруппировать хештеги, мы можем использовать агрегированные фильтры. Добавим еще несколько хештегов, намеренно опустив наименее популярные. В поле Filter используется синтаксис KQL — Lucene, только мощнее.
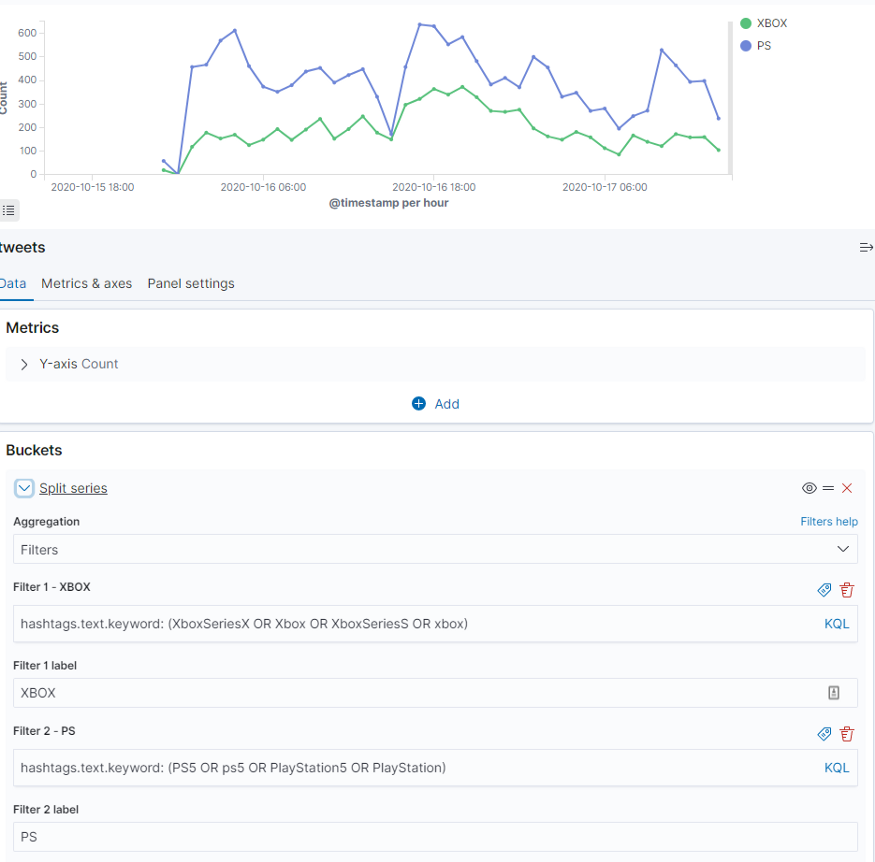
Используем фильтры hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation) и hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox). Теперь мы точно знаем, что PlayStation популярнее в Twitter.
Timelion
XBOX И PLAYSTATION
Еще более полную информацию можно получить с помощью Timelion. Этот интересный инструмент позволяет визуализировать временные ряды. В отличие от предыдущего он может визуализировать данные сразу из множества источников.
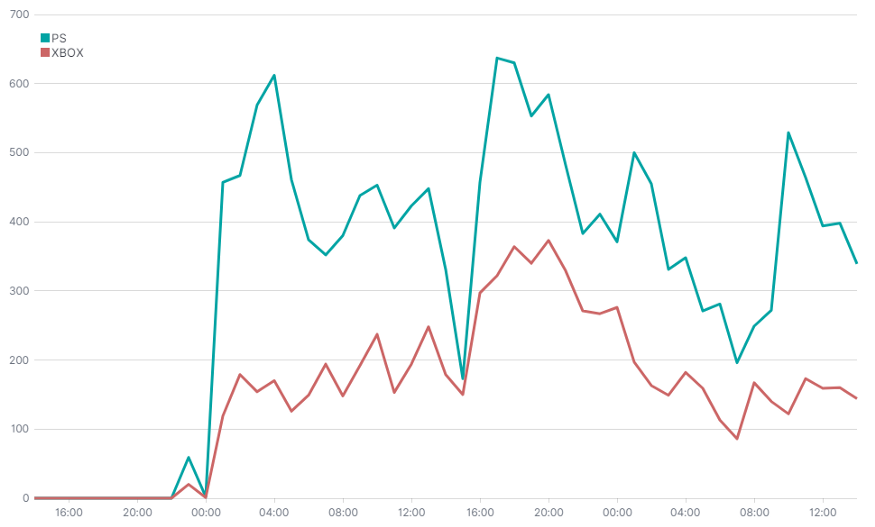
К синтаксису сперва надо привыкнуть. Ниже приведен код, сгенерировавший эту диаграмму.
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)').label("PS"),
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)').label("XBOX")Смещение
Timelion позволяет сдвигать функции с помощью параметра смещения. В примере ниже приведено количество твитов о PlayStation в сравнении с предыдущим днем. Данных у меня немного, так что эффект не особенно интересен.
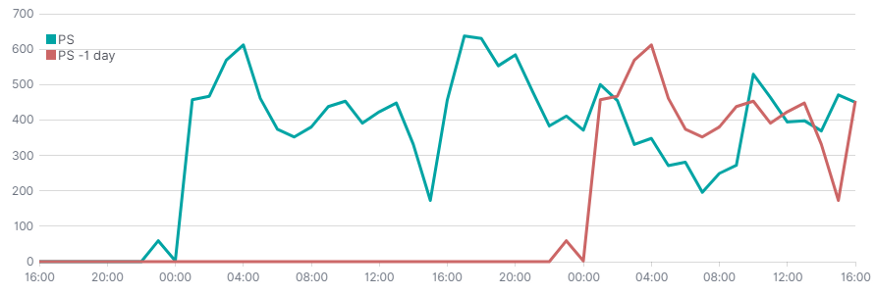
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)').label("PS"),
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)', offset=-1d).label("PS -1 day")Вариативность функции (дельта)
Используя все тот же параметр и метод вычитания, мы можем рассчитать вариативность функции.
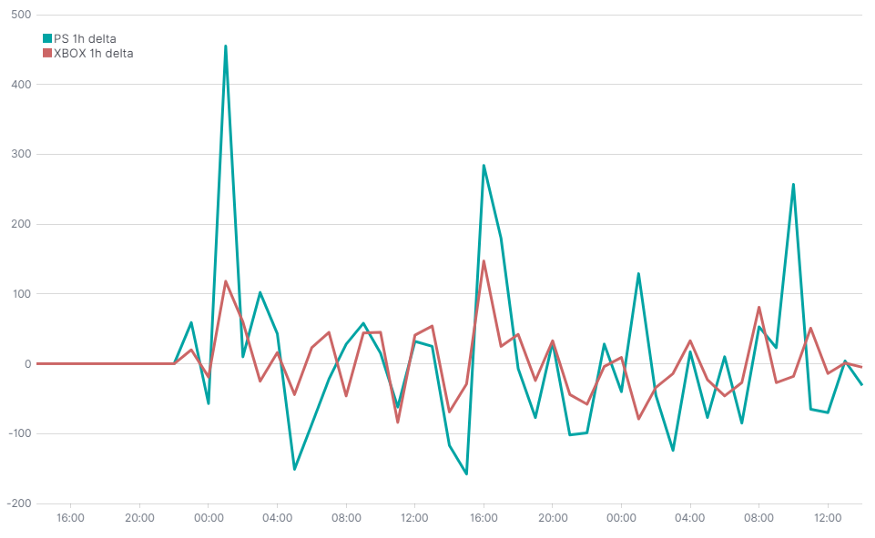
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)')
.subtract(
.es(index=tweets, q='hashtags.text.keyword: (PS5 OR ps5 OR PlayStation5 OR PlayStation)', offset=-1h)
)
.label("PS 1h delta"),
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)')
.subtract(
.es(index=tweets, q='hashtags.text.keyword: (XboxSeriesX OR Xbox OR XboxSeriesS OR xbox)', offset=-1h)
)
.label("XBOX 1h delta")Круговая диаграмма — типы клиентов
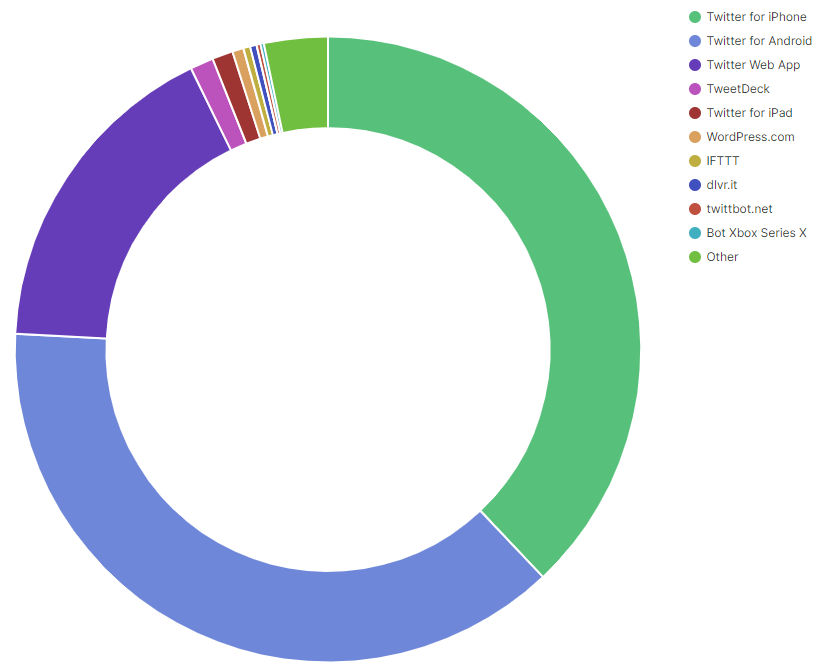
Так себе диаграмма
Теперь давайте выясним, какие клиенты используют для написания твитов. Это, оказывается, не так-то просто. Поле с типом клиента содержит HTML-тег, что уменьшает наглядность диаграммы.
Хорошая диаграмма
У Elasticsearch множество возможностей для обработки текста. Так, фильтр html_strip позволяет удалять HTML-теги. К сожалению, нам он ничего не даст, поскольку анализаторы можно использовать только для полей типа text, а нас интересует поле keyword. Для полей этого типа можно использовать агрегацию.
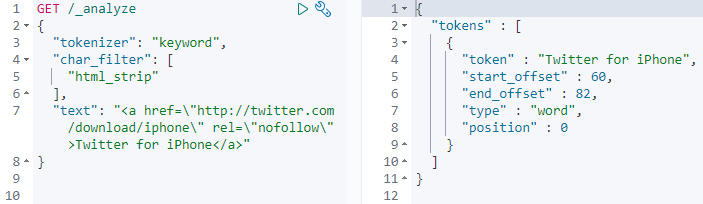
Для полей keyword можно использовать нормализаторы. Они работают аналогично анализаторам, но на выходе выдают одиночный токен.
Ниже представлен код, добавляющий нормализатор в индекс tweets. Поскольку использовать html_strip нельзя, пришлось прибегнуть к регулярным выражениям. Для изменения настроек анализатора в индексе нужно его закрыть. Следующие фрагменты кода вы можете использовать в инструментах разработчика в Kibana.
POST tweets/_close
PUT tweets/_settings
{
"analysis": {
"char_filter": {
"client_extractor": {
"type": "pattern_replace",
"pattern": "]+>([^<]+)",
"replacement": "$1"
}
},
"normalizer": {
"client_extractor_normalizer": {
"type": "custom",
"char_filter": [
"client_extractor"
]
}
}
}
}
POST tweets/_open Добавив нормализатор, мы можем обновить свойство с типом клиента и добавить новое поле значения.
PUT tweets/_mapping
{
"properties": {
"client": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
},
"value":{
"type":"keyword",
"normalizer":"client_extractor_normalizer"
}
}
}
}
}К сожалению, это еще не все. Данные индексируются при их добавлении в индекс (интересно, кстати, почему нельзя было назвать его коллекцией, как в MongoDB? ). Мы можем осуществить повторную индексацию документов с помощью механизма Update By Query.
POST tweets/_update_by_query?wait_for_completion=false&conflicts=proceedЭта операция возвращает task id. Она может отработать небыстро, если у вас много данных. Найти задачу можно с помощью команды GET _cat/tasks?v.

После обновления шаблона индекса в Kibana мы получим значительно более удобочитаемую диаграмму. Здесь мы видим, что примерно одинаковое количество пользователей используют iPhone и устройства Android. Меня крайне заинтриговал клиент Bot Xbox Series X.
Что дальше?
У меня были планы разобраться со Spark NLP, но сначала, пожалуй, займусь потоком данных Twitter. Я собираюсь использовать готовые модели Spark NLP для определения языка, тональности текста и других параметров с помощью Spark Structured Streaming.
Репозиторий
→ Ссылка
Подробнее об интенсиве «ELK» можно узнать здесь


