Сегодняшний ИИ технически «слабый» – однако он сложный и может значительно повлиять на общество

Не нужно быть Киром Дулли, чтобы знать, насколько пугающим может стать хорошо соображающий искусственный интеллект [американский актёр, исполнявший роль астронавта Дэйва Боумена в фильме «Космическая одиссея 2001 года» / прим. перев.]
ИИ, или искусственный интеллект, сейчас одна из самых важных областей знания. Решаются «нерешаемые» задачи, инвестируются миллиарды долларов, а Microsoft даже нанимает Коммона, чтобы он рассказал нам поэтическим штилем, какая это замечательная штука – ИИ. Вот ведь.
И, как с любой новой технологией, бывает сложно пробраться через всю эту шумиху. Я годами занимаюсь исследованиями в области беспилотников и «ИИ», однако даже мне бывает сложно успевать за всем этим. В последние годы я много времени провёл в поисках ответов даже на простейшие вопросы типа:
- Что подразумевают люди, говоря «ИИ»?
- В чём разница между ИИ, машинным обучением и глубоким обучением?
- Что такого замечательного в глубоком обучении?
- Какие бывшие сложными задачи теперь решать легко, а что до сих пор тяжело?
Я знаю, что не один интересуюсь подобными вещами. Поэтому, если вам интересно, с чем связаны все эти восторги по поводу ИИ на простейшем уровне, пора заглянуть за кулисы. Если вы – эксперт по ИИ, и читаете отчёты с конференции по нейрологической обработке информации (NIPS) для развлечения, в статье ничего нового для вас не будет – однако мы ждём от вас уточнений и исправлений в комментариях.
Что такое ИИ?
В информатике есть такая старая шутка: в чём разница между ИИ и автоматизацией? Автоматизация – это то, что можно делать с помощью компьютера, а ИИ – это то, что мы хотели бы уметь делать. Как только мы узнаём, как что-то делать, это переходит из области ИИ в разряд автоматизации.
Эта шутка справедлива и сегодня, поскольку ИИ не определён достаточно чётко. «Искусственный интеллект» – это просто не технический термин. Если залезть в Википедию, то там написано, что ИИ – это «интеллект, демонстрируемый машинами, в отличие от естественного интеллекта, демонстрируемого людьми и другими животными». Менее чётко и не скажешь.
В целом, есть два типа ИИ: сильный и слабый. Сильный ИИ представляет себе большинство людей, когда слышат об ИИ – это какой-то богоподобный всезнающий интеллект типа Skynet или Hal 9000, способный на рассуждения и сравнимый с человеческим, при этом превосходящий его возможности.
Слабые ИИ – высоко специализированные алгоритмы, разработанные для получения ответов на определённые полезные вопросы в узко определённых областях. К примеру, в эту категорию попадает очень хорошая шахматная программа. То же можно сказать о ПО, очень точно подстраивающем страховые платежи. В своей области такие ИИ достигают впечатляющих результатов, но в целом они весьма ограничены.
За исключением голливудских опусов, сегодня мы даже близко не подошли к сильному ИИ. Пока что любой ИИ – слабый, и большинство исследователей в данной области согласны с тем, что придуманные нами техники создания прекрасных слабых ИИ, скорее всего, не приблизят нас к созданию сильного ИИ.
Так что сегодняшний ИИ представляет собой больше маркетинговый термин, чем технический. Причина, по которой компании рекламируют свой «ИИ» вместо «автоматизации» заключается в том, что они хотят внедрить в общественное сознание голливудский ИИ. Однако это не так уж и плохо. Если отнестись к этому не слишком строго, то компании хотят лишь сказать, что, хотя мы ещё очень далеко от сильного ИИ, сегодняшний слабый ИИ куда как способнее существовавших несколько лет назад.
И если отвлечься от маркетинга, то так оно и есть. В определённых областях возможности машин резко возросли, и в основном благодаря ещё двум модным нынче словосочетаниям: машинное обучение и глубокое обучение.
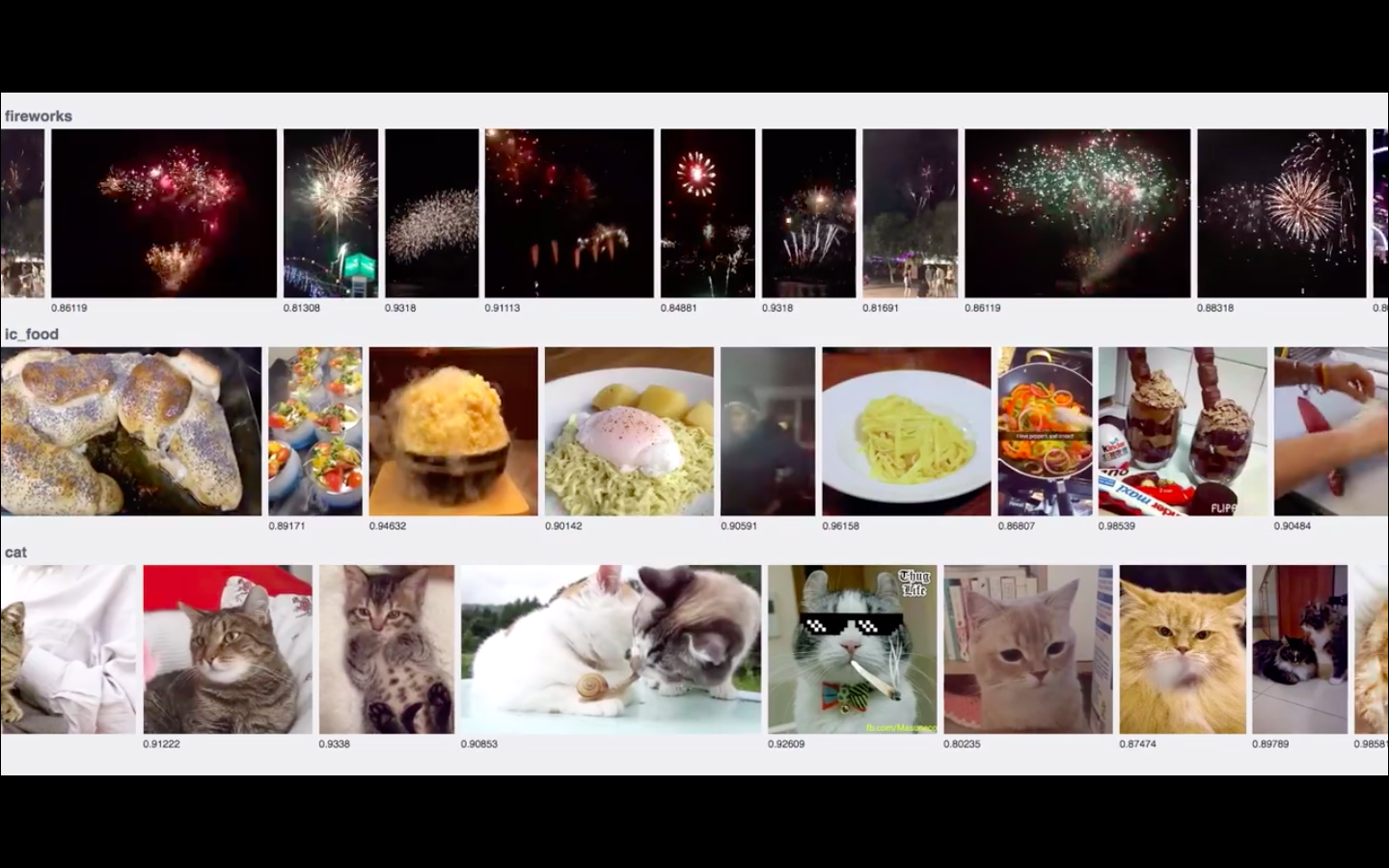
Кадр из короткого видео от инженеров Facebook, демонстрирующего, как ИИ в реальном времени распознаёт кошек (задача, также известная, как святой Грааль интернета)
Машинное обучение
МО – это особый способ создания машинного интеллекта. Допустим, вы хотите запустить ракету, и предсказать, куда она попадёт. В общем и целом это не так уж и сложно: гравитация довольно неплохо изучена, вы можете записать уравнения и рассчитать, куда она отправится, на основании нескольких переменных – таких, как скорость и начальная позиция.
Однако такой подход становится неуклюжим, если мы обращаемся к той области, правила которой не так хорошо известны и ясны. Допустим, вы хотите, чтобы компьютер сказал вам, есть ли на каких-то изображениях из выборки кошки. Как вы будете записывать правила, описывающие вид во всех возможных точек зрения на все возможные комбинации усов и ушей?
Сегодня МО-подход хорошо известен: вместо того, чтобы пытаться записать все правила, вы создаёте систему, способную самостоятельно вывести набор внутренних правил после изучения огромного количества примеров. Вместо того, чтобы описывать кошек, вы просто показываете своему ИИ кучу фотографий кошек, и даёте ему самостоятельно понять, что является кошкой, а что – нет.
И на сегодня это идеальный подход. Систему, самостоятельно обучающуюся правилам на основе данных, можно улучшать, просто добавляя данных. А если наш вид что-то и умеет очень хорошо делать, так это генерировать, хранить и управлять данными. Хотите научиться лучше распознавать кошек? Интернет генерирует миллионы примеров прямо в эту минуту.
Всё возрастающий поток данных – одна из причин взрывного роста алгоритмов МО в последнее время. Другие причины связаны с использованием этих данных.
Кроме данных, для МО есть ещё два связанных с этим вопроса:
- Как мне запомнить изученное? Как хранить и представлять на компьютере связи и правила, которые я вывел из данных?
- Как мне обучаться? Как изменять сохранённую репрезентацию в ответ на поступление новых примеров, и улучшаться?
Иначе говоря, что именно обучается на основе всех этих данных?
В МО вычислительным представлением обучения, которое мы храним, является модель. Тип используемой модели очень важен: он определяет то, как учится ваш ИИ, на каких данных он может обучаться, и какие вопросы можно будет ему задавать.
Давайте посмотрим на очень простой пример. Допустим, мы покупаем в продуктовом магазине инжир, и хотим сделать ИИ с МО, который говорил бы нам, спелый ли он. Это должно быть легко сделать, поскольку в случае инжира, чем он мягче, тем слаще.
Мы можем взять несколько образцов спелого и неспелого инжира, посмотреть, насколько они сладкие, а потом разместить их на графике и подстроить под него прямую. Эта прямая будет нашей моделью.

Зародыш ИИ в виде «чем они мягче, тем слаще»

С добавлением новых данных задача усложняется
Посмотрите-ка! Прямая неявным образом следует идее о том, что «чем они мягче, тем слаще», и нам даже не пришлось ничего записывать. Наш зародыш ИИ не знает ничего о содержании сахара или созревании фруктов, но может предсказывать сладость фрукта, сжимая его.
Как натренировать модель, чтобы она стала лучше? Мы можем собрать ещё больше образцов и провести ещё одну прямую, чтобы получить более точные предсказания (как на второй картинке выше). Однако проблемы сразу становятся очевидными. Пока что мы обучали наш инжирный ИИ на качественных ягодах – а что, если мы возьмём данные из фруктового сада? Внезапно у нас появляются не только спелые, но и гнилые фрукты. Они очень мягкие, но определённо не подходят для еды.
Что нам делать? Ну, раз это модель МО, мы просто можем скормить ей больше данных, правильно?
Как показывает первая картинка внизу, в этом случае мы получим совершенно бессмысленные результаты. Прямая просто не подходит для описания того, что происходит, когда фрукт становится слишком спелым. Наша модель уже не вписывается в структуру данных.
Вместо этого нам придётся её поменять, и использовать более хорошую и сложную модель – возможно, параболу, или что-то похожее. Это изменение усложняет обучение, потому что для рисования кривых требуется более сложная математика, чем для рисования прямой.
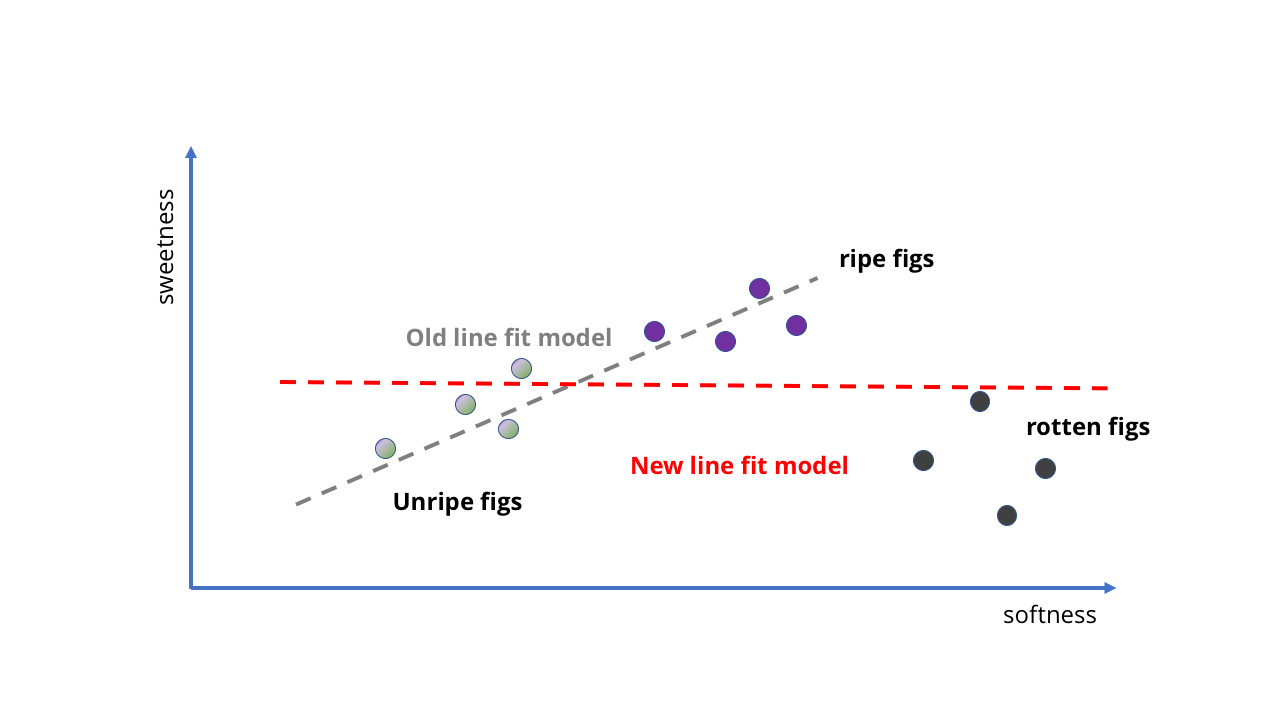
Ладно, наверное, идея использовать прямую для сложного ИИ была не очень удачной
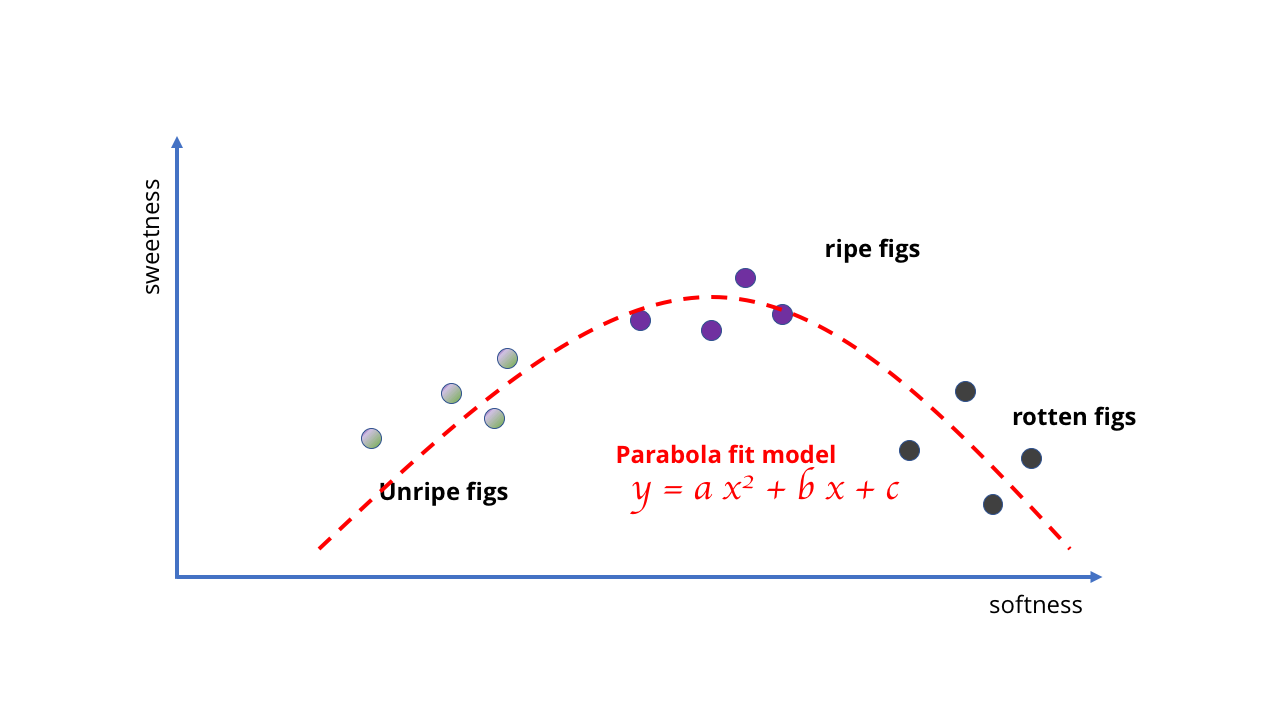
Требуется математика посложнее
Пример довольно глупый, но он показывает, что выбор модели определяет возможности обучения. В случае инжира данные простые, и модели могут быть простыми. Но если вы пытаетесь обучиться чему-то более сложному, требуются более сложные модели. Точно так же, как никакое количество данных не заставит линейную модель отражать поведение гнилых ягод, так невозможно подобрать простую кривую, соответствующую куче картинок, чтобы создать алгоритм компьютерного зрения.
Поэтому трудность для МО состоит в создании и выборе правильных моделей для соответствующих задач. Нам нужна модель, достаточно сложная для того, чтобы описать на самом деле сложные связи и структуры, но достаточно простая для того, чтобы с ней можно было работать и тренировать её. Так что, хотя интернет, смартфоны и так далее породили невероятные горы данных, на которых можно обучаться, нам всё равно нужны правильные модели, чтобы воспользоваться этими данными.
Именно тут и вступает в игру глубокое обучение.

Глубокое обучение
Глубокое обучение – это машинное обучение, использующее модель определённого вида: глубокие нейросети.
Нейросети – это тип модели МО, использующей структуру, напоминающую нейроны в мозге, для вычислений и предсказаний. Нейроны в нейросетях организуются послойно: каждый слой выполняет набор простых вычислений и передаёт ответ следующему.
Послойная модель позволяет проводить более сложные вычисления. Простой сети с небольшим количеством слоёв нейронов достаточно для воспроизводства использовавшейся нами выше прямой или параболы. Глубокие нейросети – это нейросети с большим количеством слоёв, с десятками, или даже сотнями; отсюда и их название. С таким количеством слоёв можно создавать невероятно мощные модели.
Эта возможность – одна из основных причин огромной популярности глубоких нейросетей в последнее время. Они могут обучаться различным сложным вещам, не заставляя человека-исследователя определять какие-то правила, и это позволило нам создать алгоритмы, способные решать самые разные задачи, к которым раньше компьютеры не могли подступиться.
Однако в успех нейросетей сделал свой вклад и ещё один аспект: обучение.
«Память» модели – это набор числовых параметров, определяющий то, как она выдаёт ответы на задаваемые ей вопросы. Обучать модель – значит, подстраивать эти параметры так, чтобы модель выдавала наилучшие ответы из возможных.
В нашей модели с инжиром мы искали уравнение прямой. Это задача простой регрессии, и существуют формулы, которые дадут вам ответ за один шаг.

Простая нейросеть и глубокая нейросеть
С более сложными моделями всё не так просто. Прямую и параболу легко представить несколькими числами, но глубокая нейросеть может иметь миллионы параметров, а набор данных для её обучения также может состоять из миллионов примеров. Аналитического решения в один шаг не существует.
К счастью, существует один странный трюк: можно начать с плохой нейросети, а потом улучшать её при помощи постепенных подстроек.
Обучение модели МО таким способом похоже на проверку ученика при помощи тестов. Каждый раз мы получаем оценку, сравнивая то, какие ответы должны быть по мнению модели, с «правильными» ответами в обучающих данных. Затем мы проводим улучшение и запускаем проверку снова.
Как мы узнаем, какие параметры надо подстраивать, и насколько? У нейросетей есть такое прикольное свойство, когда для многих видов обучения можно не только получить оценку в тесте, но и подсчитать, насколько именно она изменится в ответ на изменение каждого параметра. Говоря математическим языком, оценка – это функция значения, и для большинства таких функций мы легко можем подсчитать градиент этой функции относительно пространства параметров.
Теперь мы точно знаем, в какую сторону надо подстраивать параметры для увеличения оценки, и можно подстраивать сеть последовательными шагами во всё лучших и лучших «направлениях», пока вы не дойдёте до точки, в которой уже ничего нельзя улучшить. Это часто называют восхождением на холм, поскольку это действительно похоже на движение вверх по холму: если постоянно двигаться вверх, в итоге попадёшь на вершину.

Видали? Вершина!
Благодаря этому нейросеть улучшать легко. Если ваша сеть обладает хорошей структурой, получив новые данные, вам не нужно начинать с нуля. Можно начать с имеющихся параметров, и заново обучиться на новых данных. Ваша сеть будет постепенно улучшаться. Наиболее видные из сегодняшних ИИ – от распознавания кошек на Facebook до технологий, которые (наверное) использует Amazon в магазинах без продавцов – построены на этом простом факте.
Это ключ ещё к одной причине, по которой ГО распространилось так быстро и так широко: восхождение на холм позволяет взять одну нейросеть, обученную какой-то задаче, и переобучить её на выполнение другой, но сходной. Если вы обучили ИИ хорошо распознавать кошек, эту сеть можно использовать для обучения ИИ, распознающего собак, или жирафов, без необходимости начинать с нуля. Начните с ИИ для кошек, оценивайте его по качеству распознавания собак, и потом забирайтесь на холм, улучшая сеть!
Поэтому в последние 5-6 лет произошло резкое улучшение возможностей ИИ. Несколько кусочков головоломки сложились синергетическим образом: интернет сгенерировал огромный объём данных, на котором можно учиться. Вычисления, особенно параллельные вычисления на графических процессорах сделали возможной обработку этих огромных наборов. Наконец, глубокие нейросети позволили воспользоваться преимуществами этих наборов и создать невероятно мощные модели МО.
И всё это означает, что некоторые вещи, бывшие ранее крайне сложными, теперь делать очень легко.
И что мы теперь можем делать? Распознавание образов
Возможно, глубочайшее (пардон за каламбур) и скорейшее влияние глубокое обучение оказало на область компьютерного зрения – в особенности, на распознавание объектов на фотографиях. Несколько лет назад этот комикс от xkcd прекрасно описывал передний край информатики:

Сегодня распознавание птиц и даже определённых видов птиц – тривиальная задача, которую может решить правильно мотивированный старшеклассник. Что поменялось?
Идею визуального распознавания объектов легко описать, но сложно реализовать: сложные объекты состоят из наборов более простых, которые в свою очередь состоят из более простых форм и линий. Лица состоят из глаз, носов и ртов, а те состоят из кружочков и линий, и так далее.
Поэтому распознавание лиц становится вопросом распознавания закономерностей, в которых расположены глаза и рты, что может потребовать распознавания форм глаза и рта из линий и кружочков.
Эти закономерности называются особенностями, и до появления глубокого обучения для распознавания было необходимо описать все особенности вручную и запрограммировать компьютер на их поиск. К примеру, есть знаменитый алгоритм распознавания лиц «метод Виолы — Джонса«, основанный на том факте, что брови и нос обычно светлее глазниц, поэтому они формируют яркую Т-образную форму с двумя тёмными точками. Алгоритм, по сути, ищет подобные Т-образные формы.
Метод Виолы-Джонса работает хорошо и удивительно быстро, и служит основой распознавания лиц в дешёвых фотоаппаратах и т.п. Но, очевидно, не каждый объект, который вам нужно распознать, поддаётся подобному упрощению, и люди придумывали всё более сложные и низкоуровневые закономерности. Чтобы алгоритмы работали правильно, требовалась работа команды докторов наук, они были очень чувствительными и подверженными отказам.
Большой прорыв случился благодаря ГО, а в частности – определённому виду нейросетей под названием «свёрточные нейросети». Свёрточные нейросети, СНС – это глубокие сети с определённой структурой, вдохновлённой строением зрительной коры мозга млекопитающих. Такая структура позволяет СНС самостоятельно обучаться иерархии линий и закономерностей для распознавания объектов вместо того, чтобы ждать, пока доктора наук потратят годы на исследования того, какие из особенностей лучше подходят для этого. К примеру, СНС, обученная на лицах, выучит собственную внутреннюю репрезентацию линий и кружочков, складывающихся в глаза, уши и носы, и так далее.
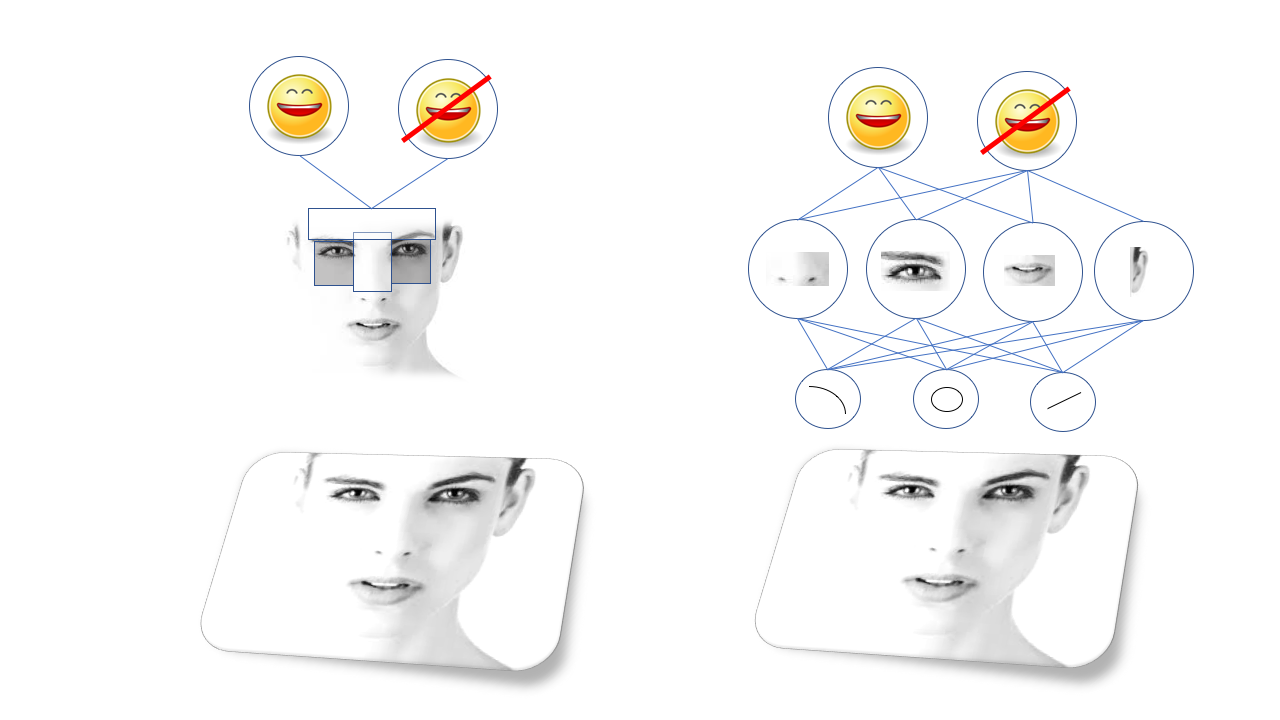
Старые зрительные алгоритмы (метод Виолы-Джонса, слева) полагаются на вручную выделенных особенностях, а глубокие нейросети (справа) на собственную иерархию более сложных особенностей, составленных из более простых
СНС потрясающе хорошо подошли для компьютерного зрения, и вскоре исследователи смогли обучить их на выполнение всяческих задач по визуальному распознаванию, от поиска кошек на фото до определения пешеходов, попавших в камеру робомобиля.
Это всё замечательно, но есть и другая причина такого быстрого и широкого распространения СНС – это то, насколько легко они адаптируются. Помните восхождение на холм? Если наш старшеклассник захочет распознать определённую птицу, он может взять любую из множества зрительных сетей с открытым кодом, и обучить её на собственном наборе данных, даже не понимая, как работает лежащая в её основе математика.
Естественно, это можно расширить и ещё дальше.
Кто там? (распознавание лиц)
Допустим, вы хотите обучить сеть, распознающую не просто лица, но одно определённое лицо. Вы могли бы обучить сеть распознавать определённого человека, потом другого человека, и так далее. Однако на обучение сетей тратится время, и это значило бы, что для каждого нового человека требовалось бы переобучать сеть. Нет уж.
Вместо этого мы можем начать с сети, обученной распознавать лица в целом. Её нейроны настроены на распознавание всех лицевых структур: глаз, ушей, ртов, и так далее. Затем вы просто меняете выходные данные: вместо того, чтобы заставлять её распознавать определённые лица, вы командуете ей выдавать описание лица в виде сотен чисел, описывающих кривизну носа или форму глаз, и так далее. Сеть может делать это, поскольку уже «знает», из каких компонентов состоит лицо.
Вы, конечно, не определяете всё это напрямую. Вместо этого вы обучаете сеть, показывая ей набор лиц, а потом сравнивая выходные данные. Вы также обучаете её так, чтобы она давала схожие друг с другом описания одного и того же лица, и сильно отличающиеся друг от друга описания разных лиц. Математически говоря, вы обучаете сеть на построение соответствия изображениям лиц точки в пространстве особенностей, где картезианское расстояние между точками можно использовать для определения их схожести.

Изменение нейросети с распознавания лиц (слева) до описания лиц (справа) требует лишь изменения формата выходных данных, без смены её основы

Теперь можно распознавать лица, сравнивая описания каждого из лиц, создаваемые нейросетью
Обучив сеть, вы уже легко можете распознавать лица. Вы берёте изначальное лицо и получаете его описание. Затем берёте новое лицо и сравниваете описание, выдаваемое сетью, с вашим оригиналом. Если они находятся достаточно близко, вы говорите, что это одно и то же лицо. И вот вы перешли от сети, способной распознавать одно лицо, к тому, что можно использовать для распознавания любого лица!
Подобная структурная гибкость – ещё одна причина такой полезности глубоких нейросетей. Было разработано уже огромное количество разнообразных МО-моделей для компьютерного зрения, и хотя они развиваются в очень разных направлениях, базовая структура многих из них основана на таких ранних СНС, как Alexnet и Resnet.
Я даже слышал истории о людях, использующих визуальные нейросети для работы с данными временного ряда или измерениями датчиков. Вместо того, чтобы создавать специальную сеть для анализа потока данных, они обучали предназначенную для компьютерного нейросеть с открытым кодом буквально смотреть на формы линий графиков.
Подобная гибкость – дело хорошее, но не бесконечное. Чтобы решать некоторые другие проблемы, требуется использовать другие типы сетей.

И даже до этой точки виртуальные ассистенты добирались очень долго
Что ты сказал? (Распознавание речи)
Каталогизация картинок и компьютерное зрение – не единственные области возрождения ИИ. Ещё одна область, в которой компьютеры продвинулись очень далеко – это распознавание речи, особенно в переводе речи в письменность.
Базовая идея в распознавании речи довольно похожа на принцип компьютерного зрения: распознавать сложные вещи в виде наборов более простых. В случае с речью распознавание предложений и фраз строится на распознавании слов, которое основано на распознавании слогов, или, если быть более точным, фонем. Так что, когда кто-то говорит «Bond, James Bond», на самом деле мы слышим BON+DUH+JAY+MMS+BON+DUH.
В зрении особенности организованы пространственно, и эту структуру обрабатывают СНС. В слухе эти особенности организованы во времени. Люди могут говорить быстро или медленно, без чёткого начала и конца речи. Нам нужна модель, способная воспринимать звуки по мере поступления, как человек, вместо того, чтобы ждать и выискивать в них законченные предложения. Мы не можем, как в физике, сказать, что пространство и время – это одно и то же.
Распознавать отдельные слоги довольно легко, однако их сложно изолировать. К примеру, «Hello there» может звучать похоже на «hell no they’re»… Так что для любой последовательности звуков обычно существует несколько комбинаций слогов, произнесённых на самом деле.
Чтобы во всём этом разобраться, нам нужна возможность изучать последовательность в определённом контексте. Если я слышу звук, то что более вероятно – что человек сказал «hello there dear» или «hell no they’re deer?» Здесь опять на помощь приходит машинное обучение. С достаточно большим набором образцов произнесённых слов можно выучить наиболее вероятные фразы. И чем больше примеров у вас есть, тем лучше это будет получаться.
Для этого люди используют рекуррентные нейросети, РНС. В большинстве типов нейросетей, как, например, в СНС, занимающихся компьютерным зрением, связи между нейронами работают в одном направлении, от входа к выходу (математически говоря, это направленные ациклические графы). В РНС выход нейронов может быть перенаправлен обратно на нейроны этого же уровня, на них самих или даже ещё дальше. Это позволяет РНС иметь свою память (если вам знакома двоичная логика, то эта ситуация похожа на работу триггеров).
СНС работает за один подход: скармливаем ей изображение, и она выдаёт какое-то описание. РНС поддерживает внутреннюю память о том, что ей давали раньше, и выдаёт ответы на основе того, что она уже видела, плюс того, что видит сейчас.
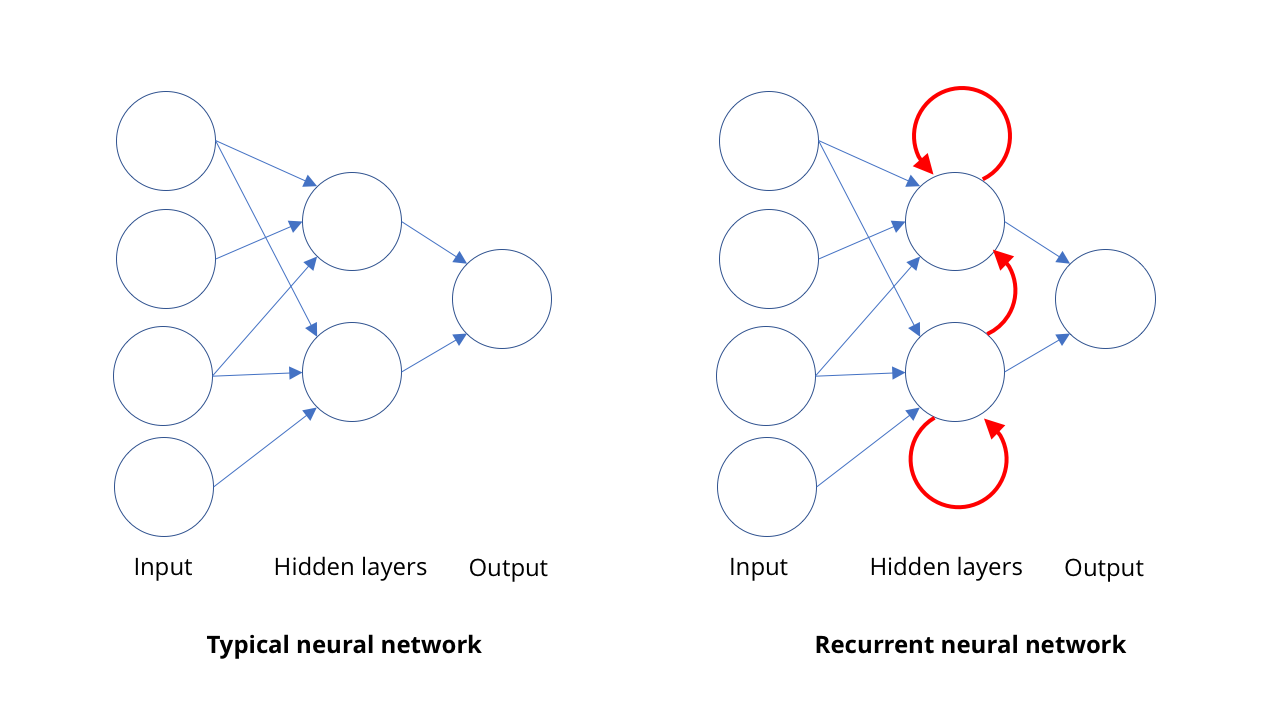
Такое свойство памяти у РНС позволяет им не только «слушать» слоги, поступающие к ней один за другим. Это позволяет сети обучаться тому, какие слоги идут вместе, формируя слово, и тому, насколько вероятны определённые их последовательности.
Используя РНС, возможно получить очень хорошую транскрипцию человеческой речи – до такой степени, что по некоторым измерениям точности транскрипций компьютеры сейчас могут превосходить людей. Конечно, звуки – не единственная область, где проявляются последовательности. Сегодня РНС используют также и для определения последовательностей движений для распознавания действий на видео.
Покажи мне, как ты умеешь двигаться (глубокие подделки и генеративные сети)
Пока что мы говорили о МО-моделях, предназначенных для распознавания: скажи мне, что изображено на картинке, скажи мне, что сказал человек. Но эти модели способны на большее – сегодняшние модели ГО можно использовать и для создания контента.
Это имеется в виду, когда люди рассказывают о deepfake – невероятно реалистичных поддельных видеороликах и изображениях, созданных с использованием ГО. Некоторое время назад один сотрудник немецкого телевидения вызвал обширную политическую дискуссию, создав поддельное видео, на котором министр финансов Греции показывал Германии средний палец. Для создания этого видео потребовалась команда редакторов, работавших для создания телепередачи, но в современном мире это может за несколько минут сделать любой человек с доступом к игровому компьютеру средней мощности.
Всё это довольно грустно, но не в этой области так мрачно – вверху показано моё любимое видео на тему этой технологии.
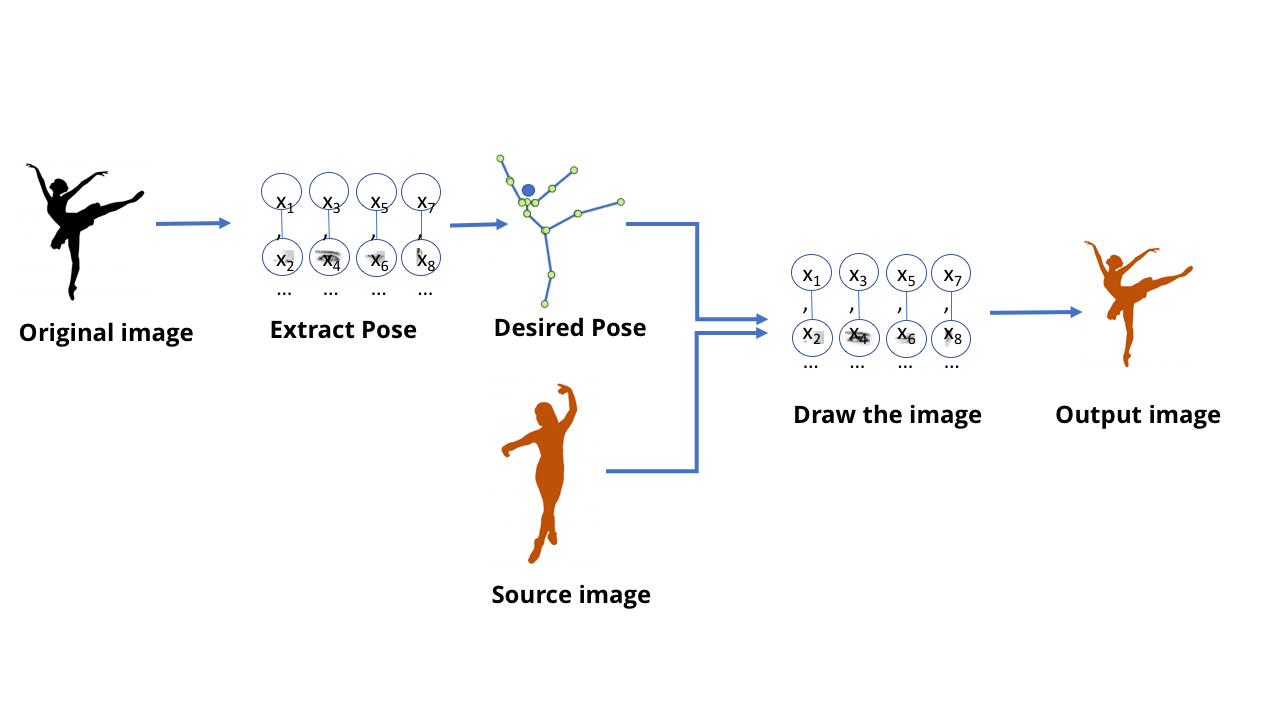
Эта команда создала модель, способная обработать видеоролик с танцевальными движениями одного человека и создать видео с другим человеком, повторяющим эти движения, волшебным образом выполняя их на уровне эксперта. Также интересно почитать сопутствующую этому научную работу.
Можно представить, что, используя все рассмотренные нами техники, возможно обучить сеть, получающую изображение танцора и сообщающую, где находятся его руки и ноги. А в таком случае, очевидно, на каком-то уровне сеть обучилась тому, как связывать пиксели в изображении с расположением конечностей человека. Учитывая то, что нейросеть – это просто данные, хранящиеся на компьютере, а не биологический мозг, должно быть возможно взять эти данные и пойти в обратную сторону – чтобы получить пиксели, соответствующие расположению конечностей.
Начните с сети, извлекающей позы из изображений людей
МО-модели, способные делать это, называются генеративными [англ. generate – порождать, производить, создавать / прим. перев.]. Все предыдущие рассмотренные нами модели называются дискриминационными [англ. discriminate – различать / прим. перев.]. Разницу между ними можно представить себе так: дискриминационная модель для кошек смотрит на фотографии и различает фото, содержащие кошек, и фото, где их нет. Генеративная модель создаёт изображения кошек на основе, допустим, описания того, какая это должна быть кошка.

Генеративные модели, «рисующие» изображения объектов, создаются при помощи тех же СНС-структур, что и модели, использующиеся для распознавания этих объектов. И эти модели можно обучать в основном так же, как и другие модели МО.
Однако хитрость заключается в том, чтобы придумать для их обучения «оценку». При обучении дискриминационной модели есть простой способ оценить правильность и неправильность ответа – типа, правильно ли сеть отличила собаку от кошки. Однако как оценить качество полученного рисунка кошки, или его точность?
И вот тут для человека, любящего теории заговоров и считающего, что мы все обречены, ситуация становится немного страшноватой. Видите ли, лучший из придуманных нами способов для обучения генеративных сетей заключается в том, чтобы не делать этого самостоятельно. Для этого мы просто используем другую нейросеть.
Эта технология называется генеративно-состязательная сеть, или ГСС. Вы заставляете две нейросети состязаться друг с другом: одна сеть пытается создавать подделки, к примеру, рисуя нового танцора на основе поз старого. Другая сеть обучена на поиск разницы между реальными и поддельными примерами с использованием кучи примеров реальных танцоров.
И две эти сети играют в состязательную игру. Отсюда и слово «состязательный» в названии. Генеративная сеть пытается делать убедительные подделки, а дискриминационная пытается понять, где подделка, а где реальная вещь.
В случае видеоролика с танцором в процессе обучения была создана отдельная дискриминационная сеть, выдававшая простые ответы да/нет. Она смотрела на изображение человека и на описание положения его конечностей, и решала, является ли изображение реальной фотографией или картинкой, нарисованной генеративной моделью.

ГСС заставляют две сети состязаться друг с другом: одна выдаёт «фейки», а другая пытается отличать фейк от оригинала
В итоговом рабочем процессе используется только генеративная модель, создающая нужные изображения
Во время повторяющихся раундов обучения модели становились всё лучше и лучше. Это похоже на состязание эксперта по ювелирным подделкам со специалистом по оценке – соревнуясь с сильным соперником, каждый из них становится сильнее и умнее. Наконец, когда работа моделей оказывается достаточно хорошей, можно взять генеративную модель и использовать её отдельно.
Генеративные модели после обучения могут оказаться очень полезными для создания контента. К примеру, они могут генерировать изображения лиц (которые можно использовать для обучения программ по распознаванию лиц), или фонов для видеоигр.
Чтобы всё это работало правильно, требуется большая работа по подстройкам и исправлениям, но по сути человек тут выступает в роли арбитра. Именно ИИ работают друг против друга, внося основные улучшения.
Так что, ждать ли нам в ближайшее время появления Skynet и Hal 9000?
В каждом документальном фильме о природе в конце есть эпизод, где авторы рассказывают о том, как вся эта грандиозная красота скоро исчезнет из-за того, насколько люди ужасны. Думаю, что в том же духе каждая ответственная дискуссия касательно ИИ должна включать раздел о его ограничениях и социальных последствиях.
Во-первых, давайте ещё раз подчеркнём текущие ограничения ИИ: главная мысль, которую вы, как я надеюсь, извлекли из прочтения этой статьи, состоит в том, что успех МО или ИИ чрезвычайно сильно зависит от выбранных нами моделей обучения. Если люди плохо организуют сеть или используют негодные материалы для обучения, то эти искажения могут оказаться весьма явными для всех.
Глубокие нейросети невероятно гибкие и мощные, но не имеют волшебных свойств. Несмотря на то, что вы используете глубокие нейросети для РНС и СНС, их структура сильно отличается, и поэтому всё равно определять её должны люди. Так что, даже если вы можете взять СНС для автомобилей, и переобучить её на распознавание птиц, вы не можете взять эту модель и переобучить её на распознавание речи.
Если описать это в человеческих терминах, то всё выглядит так, будто мы поняли, как работают зрительная кора и слуховая кора, однако понятия не имеем о том, как работает кора головного мозга, и откуда вообще можно начать к ней подступаться.
Это значит, что в ближайшее время мы, вероятно, не увидим голливудского богоподобного ИИ. Но это не значит, что в своём нынешнем виде ИИ не может оказать серьёзное влияние на социум.
Мы часто представляем себе, как ИИ «заменяет» нас, то есть, как роботы буквально делают нашу работу, но на самом деле это будет происходить не так. Взгляните, например, на рентгенологию: иногда люди, смотря на успехи компьютерного зрения, говорят о том, что ИИ заменит рентгенологов. Возможно, мы не дойдём до такой точки, когда у нас вообще не будет ни одного рентгенолога-человека. Но вполне возможно такое будущее, в котором на сотню сегодняшних рентгенологов ИИ позволит пяти-десяти из них делать работу всех остальных. Если такой сценарий реализуется, куда пойдут оставшиеся 90 врачей?
Даже если современное поколение ИИ не оправдает надежд наиболее оптимистичных его сторонников, он всё равно приведёт к весьма обширным последствиям. И эти проблемы нам придётся решать, поэтому неплохим началом, вероятно, будет овладеть основами этой области.
Источник


