При запуске новых плат и устройств с PCIe-соединениями недостаточно просто вставить карту в слот. Нужно так настроить эквалайзеры, редрайверы, пресеты и ретаймеры, чтобы на каждой YADRO. В статье я расскажу, как можно оценить качество PCIe-соединения без специальной аппаратуры и о наших патчах для пакета pciutils, которые могут упростить эту задачу.

Epic Win
Для оценки качества установленного линка инструментально снимается так называемая глазковая диаграмма сигнала (далее «глаз» для простоты). Это может быть либо полноценная двухмерная диаграмма, либо ее примитивное упрощение до ромба, либо, в худшем случае, хотя бы одна из ее точек. Четвертое поколение стандарта PCIe не только удвоило скорость передачи с 8 GT/s до 16 GT/s, но и ввело обязательное требование поддержки измерения упрощенного «глаза» от каждого узла дерева. Как корневого порта и портов промежуточных мостов, так и конечного устройства:
-
без дополнительного оборудования,
-
в любой момент времени,
-
без необходимости остановки или паузы системы,
-
без потери работоспособности системы,
-
доступное не только на системах уровня Enterprise, но и для любого домашнего ПК при линке 16 GT/s и выше.
Этот функционал назвали Lane Margining (at Receiver): определение запаса на ошибку на полосе со стороны приемника. LM расширяет возможности с привычного QA/QC до непрерывной самодиагностики развернутых в полях систем.
Процедура определения границ проводится для каждой полосы отдельно и дважды: сначала на приемнике (Rx) порта, затем на приемнике (Rx) устройства. Если обе стороны поддерживают фичу, то ни одна диффпара не уйдет неощупанной. Таким образом, для «толстой» карты PCIe Gen4x16 будет выполнено 32 итерации LM.
Eye makeup
«Глаз» (eye) — это многократно наложенные друг на друга сигналы. Они показывают фактическую разницу между высоким и низким уровнями сигнала на приемнике, а также «ширину», то есть длительность принятого сигнала во времени — он становится короче отправленного.



Среда распространения сигнала и терминация (согласование) на стороне приемника и передатчика вносят искажения, как и амплитудные, так и временны́е. «Глаз» нужен для количественной оценки того, что дошло до приемника. Ниже приведены примеры широко открытого и смазанного «глаза».

 и смазанный (справа) сигналы, обозначения размеров. Источник.")
Хороший «глаз» должен быть открыт широко. Иначе при изменении уровня из высокого в низкий и обратно сигнал не успеет стабилизироваться и продержаться достаточно для надежного захвата приемником, а низкий уровень может оказаться неразличим от высокого. Но насколько именно широко?
Минимальный допустимый размер на коннекторе, который указан в таблице ниже, задает базовая спецификация в разделе 8.4.2 Stressed Eye Test. Приемник должен успешно работать в таких условиях, обеспечивая частоту битовых ошибок не хуже 10-12. Другой нормативный документ — спецификация тестов PHY — в тестах Transmitter Electrical Compliance задает минимальный размер «глаза» со стороны передатчика. Мы посчитали эти значения подходящими, чтобы взять их как рекомендованные для стороны приемника.
Горизонтальный размер традиционно указывается в пикосекундах либо в процентах от интервала передачи (UI — unit interval). 100% UI равно 62.5 пс для четвертого поколения PCIe и 31.25 пс для пятого. Интервал вычисляется из скорости передачи (16 GT/s и 32 GT/s). Высота «глаза» указывается в милливольтах, максимальная амплитуда ограничена 1 В.
Производители оборудования могут добавить свои уточнения к минимальным и рекомендуемым критериям.
Таблица критериев прохождения раскрытия «глаза»:
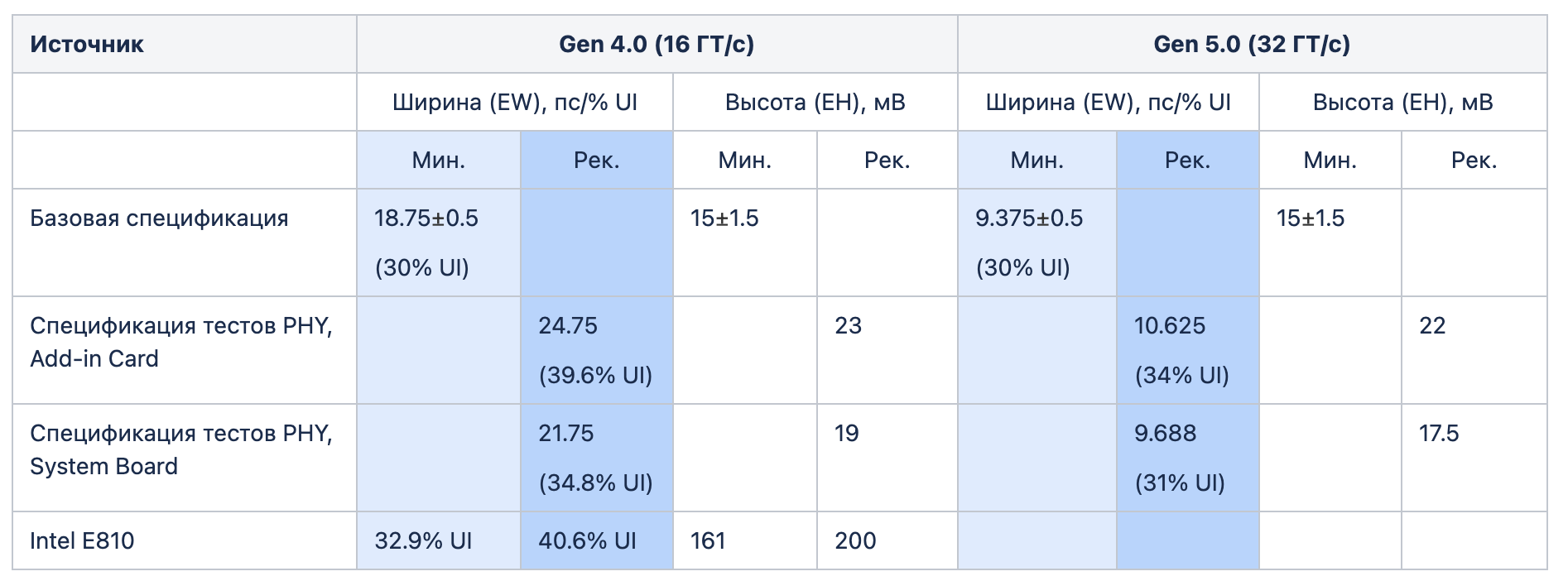
Тесты для PCIe Gen4, проведенные Nvidia на 500+ серверах, показали допустимый уровень в 30% UI на худшей из полос, иначе наблюдался спорадический поток корректируемых ошибок. В качестве же рекомендуемого среднего значения для большого флота машин выбрано 37% UI. При этом значения системы в «хвосте» нормального распределения укладывались в 30% UI и не создавали проблем в эксплуатации.
Если же измеренный «глаз» на конкретной системе меньше этих величин, соединение может пропадать при малейших колебаниях внешних условий, несмотря на поднятый линк, по которому и произвели измерение.
Измерение упрощенного «глаза»
Для построения настоящего «глаза» нужен как минимум осциллограф для частот в десятки ГГц. Но если умерить аппетит и удовольствоваться только шириной и высотой «глаза», то можно обойтись недорогими в изготовлении средствами, наличия которых в каждом приемнике и требует стандарт.

Не всегда везет получить все четыре точки ромба — результат зависит от желания разработчиков конкретного порта или карты реализовать всю полноту. Все перечисленные ниже варианты получения точек разрешены спецификацией Gen4:
-
Ромб, то есть четыре точки на осях координат: Left+Right+Up+Down.
-
Три точки. Если не поддерживается измерение вправо по шкале времени либо вниз по шкале напряжения, вторая половина «глаза» принимается зеркальным отражением полученной: Left+Right+Voltage либо Timing+Up+Down.
-
Две точки:
-
Одна на оси времени, вторая на оси напряжения: Timing+Voltage, при этом их зеркальные отражения достраиваются пользователем.
-
Либо измерение ширины глаза в обоих направлениях от нуля: Left+Right.
-
-
Одна точка. Если поддерживается только измерение ширины глаза в направлении вправо от нуля: Timing плюс зеркальное отражение.
Но на практике иногда нельзя получить ни одну точку, несмотря на всю обязательность стандарта:
-
бит Margining Ready не взведен,
-
любые команды завершаются отказом,
-
возвращаются фейковые данные.
Спецификация Gen5 сделала обязательными измерение как времени, так и напряжения. Но поддержка независимого измерения в обоих направлениях (вверх+вниз, влево+вправо) остается опциональной.
Как именно процедура LM производится на электрическом уровне — выбор производителя. Спецификация лишь вкратце предлагает в качестве примера постепенно смещать от центра точку семплирования либо контролируемо подмешивать плавно возрастающую помеху — шаг за шагом, пока количество ошибок на линии не превысит заданный порог в единицу времени. Обычно это 3-5 ошибок на протяжении секунды. Прерывать процедуру при возникновении первой же ошибки нецелесообразно, поскольку одиночные ошибки (BER 10-12) допускаются и корректируются двумя CRC без участия пользователя, без разрыва и/или замедления соединения.
Максимальные значения, которые позволяет измерить LM:
-
±500 мВ по напряжению,
-
±0.5 UI по времени.
Каждый приемник в праве сузить эти диапазоны: скажем, уметь измерять напряжение только в диапазоне ±190 мВ. Спецификация задает и минимальные требования к умениям измерителя:
-
от нуля до ±20% UI по времени,
-
от нуля до ±50 мВ по напряжению (опционально для Gen4, обязательно для Gen5).
Одновременно измерять и по высоте, и по ширине спецификация запрещает, а жаль. Можно было бы получить двухмерную карту плотности ошибок, которую дают некоторые проприетарные аппаратные отладчики, как на примере ниже.

Краткое описание процедуры измерения «глаза»
Измеряется «глаз» в несколько шагов.
-
Выбираем, какую из границ упрощенного «глаза» будем сейчас измерять: высоту (напряжение) или ширину (время).
-
Устанавливаем начальное значение этой границы в ноль.
-
Засекаем одну секунду и считаем количество ошибок на шине.
Дальше действуем по ситуации:
-
Если соединение прервалось из-за количества ошибок, дожидаемся автоматического восстановления приемника со сбросом границы в ноль и заканчиваем это направление со статусом LIM (limit). Дальше переходим к следующему направлению и шагу 2.
-
Если количество ошибок ниже заданного порога (как правило, 3-5):
-
если граница еще не достигла максимума, то отодвигаем ее дальше на единицу и повторяем шаг,
-
иначе заканчиваем текущее направление со статусом THR (threshold), переходим к следующему направлению и шагу 2.
-
-
Иначе заканчиваем текущее направление со статусом LIM (limit), переходим к следующему направлению и шагу 2.
После снятия показаний со своих устройств сравниваем их с эталонными. Если не достигли рекомендуемых границ, можно подправить эквалайзеры/пресеты/внести аппаратные исправления и измерить LM заново.
Как процедура выглядит на практике
Приведем пример того, как выглядят результаты измерения нашей утилитой pcilmr для NVMe WD SN770 (PCIe Gen4) шириной в 4 полосы, сначала половина данных. Подробности о самой утилите будут чуть дальше в статье.
Rx(F) Lane 0: Perfect (W 46.9% UI - 29.30ps, H 239.1 mV) (L 28.1% UI - 17.58ps - 18st LIM) (R 18.8% UI - 11.72ps - 12st LIM) (U 124.7 mV - 36st LIM) (D 114.3 mV - 33st LIM)
Rx(F) Lane 1: Perfect (W 48.4% UI - 30.27ps, H 242.5 mV) (L 28.1% UI - 17.58ps - 18st LIM) (R 20.3% UI - 12.70ps - 13st LIM) (U 124.7 mV - 36st LIM) (D 117.8 mV - 34st LIM)
Rx(F) Lane 2: Perfect (W 42.2% UI - 26.37ps, H 207.9 mV) (L 25.0% UI - 15.62ps - 16st LIM) (R 17.2% UI - 10.74ps - 11st LIM) (U 103.9 mV - 30st LIM) (D 103.9 mV - 30st LIM)
Rx(F) Lane 3: Perfect (W 43.8% UI - 27.34ps, H 207.9 mV) (L 25.0% UI - 15.62ps - 16st LIM) (R 18.8% UI - 11.72ps - 12st LIM) (U 117.8 mV - 34st LIM) (D 90.1 mV - 26st LIM)Результаты измерений приводятся в разных единицах для удобства отладки и сравнения полученных данных с разнородными эталонными таблицами:
-
в первую очередь это число пройденных шагов (steps, Xst в выводе утилиты) — «сырые» данные после LM, которые затем пересчитываются в физические величины,
-
милливольты (mV) для напряжения,
-
пикосекунды (ps) для времени и эквивалентные проценты от интервала передачи сигнала (% UI).
О других цифрах и сокращениях, которые встречаются в результатах измерений:
-
Проценты проще запомнить: 30% — минимум по спецификации, 37% рекомендовано. Пикосекунды выводятся для сверки с документацией, если там указаны абсолютные значения.
-
Если поддерживается измерение в обоих направлениях, то они будут обозначены раздельно как Left и Right, либо Up и Down.
-
Статус THR означает, что соединение работает без ошибок даже после раздвижения «глаза» до максимального поддерживаемого устройством значения. То есть «глаз» больше, чем умеет измерять данный приемник: например, ограничение в ±190 мВ, в то время как на практике мы неоднократно наблюдали величины ±210 мВ.
-
Статус LIM значит, что нащупана граница, когда соединение начинает портиться.
-
Статус NAK означает, что приемник ответил чем-то невразумительным.
Но в первую очередь выводится обобщенная оценка качества полосы:
-
Perfect: глаз больше рекомендованных величин,
-
Pass: глаз меньше рекомендованных, но больше минимальных величин,
-
Fail: глаз меньше минимально допустимого.
В приведенном примере ширина «глаза» с каждой стороны не ниже 37%, что сильно выше рекомендованных пределов, напряжение тоже отличное. Значит, это подключение считаем хорошим.
Иерархия приемников
Полный вывод утилиты pcilmr содержит в два раза больше информации:
Rx(A) Lane 0: Perfect (W 38.1% UI - 23.81ps, H 88.8 mV) (T 38.1% UI - 23.81ps - 48st LIM) (U 44.4 mV - 47st LIM) (D 44.4 mV - 47st LIM)
Rx(A) Lane 1: Perfect (W 41.3% UI - 25.79ps, H 99.2 mV) (T 41.3% UI - 25.79ps - 52st LIM) (U 49.1 mV - 52st LIM) (D 50.1 mV - 53st LIM)
Rx(A) Lane 2: Perfect (W 38.1% UI - 23.81ps, H 84.1 mV) (T 38.1% UI - 23.81ps - 48st LIM) (U 41.6 mV - 44st LIM) (D 42.5 mV - 45st LIM)
Rx(A) Lane 3: Perfect (W 38.1% UI - 23.81ps, H 87.9 mV) (T 38.1% UI - 23.81ps - 48st LIM) (U 44.4 mV - 47st LIM) (D 43.5 mV - 46st LIM)
Rx(F) Lane 0: Perfect (W 46.9% UI - 29.30ps, H 239.1 mV) (L 28.1% UI - 17.58ps - 18st LIM) (R 18.8% UI - 11.72ps - 12st LIM) (U 124.7 mV - 36st LIM) (D 114.3 mV - 33st LIM)
Rx(F) Lane 1: Perfect (W 48.4% UI - 30.27ps, H 242.5 mV) (L 28.1% UI - 17.58ps - 18st LIM) (R 20.3% UI - 12.70ps - 13st LIM) (U 124.7 mV - 36st LIM) (D 117.8 mV - 34st LIM)
Rx(F) Lane 2: Perfect (W 42.2% UI - 26.37ps, H 207.9 mV) (L 25.0% UI - 15.62ps - 16st LIM) (R 17.2% UI - 10.74ps - 11st LIM) (U 103.9 mV - 30st LIM) (D 103.9 mV - 30st LIM)
Rx(F) Lane 3: Perfect (W 43.8% UI - 27.34ps, H 207.9 mV) (L 25.0% UI - 15.62ps - 16st LIM) (R 18.8% UI - 11.72ps - 12st LIM) (U 117.8 mV - 34st LIM) (D 90.1 mV - 26st LIM)Почему здесь два значения для каждой полосы? Все потому, что каждая полоса состоит из двух диффпар (Rx и Tx), а LM можно провести только на Rx. Следовательно, каждую полосу нужно измерять с двух сторон: для Rx(A) у верхнего порта и для Rx(F) у нижнего в случае простой схемы, изображенной в правой части рисунка ниже.
Если же расстояние между картой и слотом слишком большое, если используются всяческие кабели и адаптеры, то могут применяться ретаймеры — цифровые микросхемы-повторители сигнала. Они прозрачны для топологии PCIe, поскольку адреса устройств не меняются. Между портом и устройством может стоять до двух ретаймеров. Они разрывают собой физический линк, а значит, для каждого звена нужно проводить отдельную процедуру margining’а — и для Rx(B), и для Rx(C), и для Rx(D), и для Rx(E). Пример такой иерархии приведен в левой части рисунка:

Уточнение по терминологии направлений:
-
Верхнее устройство — хост или промежуточный мост (brigde, switch) — называется Upstream Component.
-
Все порты у Upstream Component в контексте этого конкретного соединения смотрят вниз, и потому называются Downstream Ports.
-
Дальше соединение идет вниз к конечному устройству либо промежуточному мосту — Downstream Component.
-
Его порты, участвующие в этом соединении, смотрят вверх, потому называются Upstream Ports.
Пример менее радужной картины вывода:
Rx(A) Lane 0: Fail (W 17.5% UI - 10.94ps) (T 8.8% UI - 5.47ps - 10st LIM)
Rx(A) Lane 1: Fail (W 17.5% UI - 10.94ps) (T 8.8% UI - 5.47ps - 10st LIM)
Rx(A) Lane 2: Fail (W 15.8% UI - 9.84ps) (T 7.9% UI - 4.92ps - 9st LIM)
Rx(A) Lane 3: Fail (W 19.2% UI - 12.03ps) (T 9.6% UI - 6.02ps - 11st LIM)В этом примере тайминги корневого порта (Rx(A)) составляют ~18% UI, что значительно хуже требований спецификации, потому состояние полос справедливо помечено как плохое (Fail). Означает ли это, что обладателю такого стенда нужно немедленно упасть в обморок? Не обязательно: можно свериться с документацией на контроллер приемника, в данном случае это корневой порт встроенного в процессор контроллера PCIe. Может оказаться, что конкретный приемник гораздо чувствительнее, чем того требует спецификация, и способен уверенно работать даже со слабым сигналом.
Мы обратились за публичными критериями pass/fail к Intel и AMD, но первые пока молчат, а вторые на форуме пометили пост как спам. Если мы получим ответы, то добавим информацию в статью позже.
Epic Struggle
Для измерения «глаза» и отладки PCIe есть несколько готовых утилит. Однако их непросто получить или их возможности ограничены. Мы рассмотрели существующие решения и написали свои патчи для одного из них.

Lane Margin Tool
Из готового доступного ПО есть утилита Lane Margin Tool (LMT) for PCIe 4.0/5.0 от Intel в виде закрытого прекомпилированного скрипта на Python, для которого нужно написать конфигурационный файл перед использованием. Получить сам скрипт без исходников и документацию к нему на данный момент не очень сложно, но некоторые препятствия со стороны Intel есть. Пользоваться утилитой можно, но удобство среднее. Потому мы взяли решение Intel как референс и приступили к следующему шагу.
Утилиты пакета pciutils
Одни из самых популярных простых утилит для отладки PCIe — lspci и setpci. Они либо сразу установлены по умолчанию в дистрибутивах Linux общего назначения, либо же их можно запросить у пакетного менеджера. Утилиты входят в пакет pciutils, доступный в виде открытого исходного кода под лицензией GPLv2.
Утилита позволяет декодировать различные свойства устройства: количество и размер BAR’ов, ширину и скорость соединения. Но когда дело доходило до Lane Margining, то еще в летнем релизе v3.10 напротив свойства был лишь стыдливый знак вопроса:
% sudo lspci -vvvs 18:00.0
18:00.0 Non-Volatile memory controller: Sandisk Corp Device 5017 (rev 01) (prog-if 02 [NVM Express])
...
Capabilities: [b0] MSI-X: Enable+ Count=65 Masked-
Vector table: BAR=0 offset=00003000
PBA: BAR=0 offset=00002000
...
LnkSta: Speed 16GT/s, Width x4
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
...
Capabilities: [920 v1] Lane Margining at the Receiver Выглядело логичным обучить утилиту lspci распознавать эту функциональность (Capability в терминах PCIe), этим мы и занялись. Патчи были приняты сообществом, в результате релиз 3.11 уже показывает расшифровку:
% sudo ./lspci -vvvs 18:00.0
...
Capabilities: [920 v1] Lane Margining at the Receiver
PortCap: Uses Driver+
PortSta: MargReady+ MargSoftReady+Информации не так много, но это все, что можно получить, не потревожив устройство: не изменив его внутреннее состояние записью команд и не нарушив тем самым гарантии утилиты lspci.
Самым интересным битовым флагом Margining Ready устройство, а точнее его PHY, сообщает о готовности к приему команд — хороший знак для нас! Бит Margining Uses Driver Software означает необходимость помощи в проведении процедуры со стороны хоста, а флаг Margining Software Ready — что такая помощь в первоначальной инициализации проведена.
Lane Margin Capability
Опрос и настройка PCIe-устройств производится путем обращения к регистрам, спроецированным в конфигурационное адресное пространство (Configuration Space). Именно с ним работают утилиты lspci, setpci и pcilmr, направляя системные вызовы в Linux в /sys/bus/pci/devices/XXX:XX:XX.X/config.
Фиксированные адреса имеются только у самых базовых регистров (номера шин, адреса BAR’ов и пр.), остальные же сгруппированы в плавающие опциональные блоки — так называемые функциональности.
Собственная функциональность есть и у LM: Lane Margining at the Receiver Capability состоит всего из пяти регистров:
-
Margining Extended Capability Header (Offset 00h): стандартный заголовок, Capability ID = 0x27, Capability Version = 1, Next Capability Offset — адрес следующей функциональности в списке.
-
Margining Port Capabilities Register (Offset 04h): содержит единственный бит Margining uses Driver Software.
-
Margining Port Status Register (Offset 06h): позволяет прочесть два бита только для чтения: «Margining Ready» и «Margining Software Ready».
-
Margining Lane Control Register (Offset 08h).
-
Margining Lane Status Register (Offset 0Ah): эти два регистра служат для подачи команд и чтения статуса их выполнения, и имеют симметричное строение.
Давайте посмотрим, за что отвечают биты Margining Lane Status Register:
-
Receiver Number (три бита): выбор приемника в иерархии (верхний порт, порт устройства, порт ретаймера):
-
000b: широковещательный запрос.
-
001b: Rx(A) — верхний порт (downstream-порт хоста или промежуточного моста).
-
010b: Rx(B) — порт ретаймера.
-
011b: Rx(C) — порт ретаймера.
-
100b: Rx(D) — порт ретаймера.
-
101b: Rx(E) — порт ретаймера.
-
110b: Rx (F) — нижний порт (приемник устройства).
-
111b: reserved.
-
-
Margin Type (три бита):
-
001b: семейство команд Report.
-
010b: разное.
-
011b: шаг по времени.
-
100b: шаг по напряжению.
-
101b: под нестандартную специфику производителя.
-
-
Usage Model (один бит): всегда 0, значение 1b зарезервировано.
-
Payload (8 бит): код команды и ответ на нее.
pcilmr
Для проведения процедуры LM наш инженер Никита Прошкин добавил в тот же релиз pciutils 3.11 утилиту pcilmr, которой достаточно скормить адрес устройства для начала работы:
% sudo ./pcilmr 0c:00.0
Link 0:3.1 -> c:0.0
Negotiated Link Width: 16
Link Speed: 16.0 GT/s = Gen 4
Available receivers: Rx(A) - 1, Rx(F) - 6
Receiver = Rx(A)
Error Count Limit = 4
Parallel Lanes: 1
Independent Error Sampler: 0
Sample Reporting Method: 0
Independent Left and Right Timing Margining: 1
Voltage Margining Supported: 0
Independent Up and Down Voltage Margining: 0
Number of Timing Steps: 23
Number of Voltage Steps: 0
Max Timing Offset: 50
Max Voltage Offset: 0
Max Lanes: 15
Receiver = Rx(F)
Error Count Limit = 4
Parallel Lanes: 1
Independent Error Sampler: 0
Sample Reporting Method: 1
Independent Left and Right Timing Margining: 1
Voltage Margining Supported: 0
Independent Up and Down Voltage Margining: 0
Number of Timing Steps: 17
Number of Voltage Steps: 0
Max Timing Offset: 49
Max Voltage Offset: 0
Max Lanes: 15Первые строки указывают поколение установленного соединения (16 GT/s, что означает Gen4), ширину (x16) и количество обнаруженных портов (активных ретаймеров нет, потому приемников два). А вот значение остальных строк:
-
Independent Error Sampler: наличие специального обработчика ошибок процесса LM. Без него ошибки могут очень обильно просачиваться в основной поток данных, далее перехватываться механизмом AER и отображаться драйвером — это норма!
-
Sample Reporting Method: поддерживается ли получение числа бит, протестированных по время проведения процедуры LM.
-
Independent Left and Right Timing Margining: поддерживается ли измерение ширины «глаза» с двух направлений от нуля.
-
Voltage Margining Supported: поддерживается ли измерение напряжения.
-
Independent Up and Down Voltage Margining: поддерживается ли измерение напряжения с двух направлений от нуля.
-
Number of Timing Steps: на какое количество шагов поделен диапазон измерения времени.
-
Number of Voltage Steps: на какое количество шагов поделен диапазон измерения напряжения.
-
Max Timing Offset: диапазон измерения времени в процентах от интервала передачи (% UI).
-
Max Voltage Offset: диапазон измерения напряжения в сотых вольта.
-
Max Lanes: к этому числу нужно прибавить единицу, выйдет количество полос, для которого поддерживается проведение параллельной процедуры LM, чтобы чуть меньше ждать завершения процедуры (1 секунда × количество шагов × количество полос). На данный момент эта возможность работает нестабильно, поэтому рекомендуется проводить процедуру LM по одной полосе за раз.
Утилита pcilmr запускает от одного до четырех циклов измерения в зависимости от поддерживаемых направлений (T, L+R, T+V и другие комбинации) — по каждой полосе, последовательно либо параллельно. Максимальное количество шагов при каждом измерении заранее известно из свойств выше, длительность одного шага тоже фиксирована и задана равной одной секунде. Это дает возможность печатать оставшееся до конца процедуры время.
Процесс измерения завершается по достижении любого из критериев:
-
Прошли все шаги, значит, время/напряжение больше, чем может измерить приемник: статус THR.
-
Количество принятых ошибок на этом шагу превысило заданный лимит (обычно 3-5), значит, нащупана искомая граница глаза: статус LIM.
-
Устройство при переходе на следующий шаг ответило статусом NAK.
Но это лишь сырые значения пройденных шагов, которые в случае статуса LIM еще предстоит перевести в физические величины. В этом и помогут значения диапазонов: Max Timing Offset и Max Voltage Offset — или не помогут, если устройство установило их нулями. Тогда не получится обойтись без документации на карту и ручных расчетов. Величина одного шага равна Max Offset / Number of Steps. Дальше нужно умножить его на число пройденных шагов и получить результат в % UI и мВ.
Наконец, последнее действие — пересчет % UI в пикосекунды. Значение единицы зависит от поколения установленного соединения, значения для Gen4 и Gen5 указаны чуть выше.
На апрель 2024 самые последние исправления и уточненные критерии оценки только готовятся к отправке в основной репозиторий pciutils. А пока свежий код с ними можно взять в нашем форке.
Epic Meh
В процессе разработки утилиты мы наткнулись на несколько любопытных нюансов. Где-то достаточно внимательно учесть особенности систем, а где-то внезапно оказалось, что не все оборудование четко следует спецификации.
Не всегда можно просто взять и сразу же запустить pcilmr. Иногда перед использованием систему нужно подготовить, например, в случае платформы Intel требуется зайти в BIOS и:
-
Отключить Leaky Bucket в разделе Platform Configuration, иначе корневой порт может при получении ошибок принять решение сбросить скорость соединения. Что удержит устройство на плаву, но прервет процедуру LM и замедлит работу.
-
Аналогично отключить опции Re-Equalization и Link Degradation.
-
Полный список можно найти в руководстве pcilmr.man.
Перед проведением процедуры LM нужно онлайн выключать ASPM — динамическое понижение энергопотребления в периоды неиспользования, затем возвращать его в исходное состояние. Утилита pcilmr делает это автоматически.
У pciutils было не принято жаловаться на запуск не из-под root, а ведь при этом выдается только небольшая часть свойств, что может ввести в замешательство. Так происходит из-за того, что доступ к регистрам через sysfs требует прав. Утилита pcilmr в таких условиях работать не сможет, потому пришлось добавить явную проверку.
Для проведения процедуры не обязательна поддержка тестирования соединения обоими устройствами, хватит и одного, например, когда хост готов к проведению тестов, а карта — нет. Но при этом протестирована будет только половина диффпар, а именно приемники тестируемого.
Кроме того, опытным путем мы обнаружили некорректное значение поля MaxVoltageOffset у процессоров семейства Ice Lake. Для таких случаев добавили в утилиту механизм quirks, подобный широко распространенному в драйверах ядра Linux. При его запуске сверяется ревизия PCIe-контроллера (по Vendor ID и Device ID корневого порта) и при надобности в процедуру расчета напряжения вносятся коррективы.
Есть у Ice Lake еще одна особенность. Измерение по оси времени поддерживается только в одном направлении, но результат будет равен полной ширине «глаза», а не ее половине, как предполагается базовой спецификацией и как реализовано в остальных устройствах, в том числе и в последующих поколениях процессоров Intel. Этот нюанс тоже учитывается в pcilmr: как раз для таких случаев явно выводятся полные ширина и высота глаза, рассчитанные из сырых данных.
И последний нюанс. Видеокарты AMD представляются промежуточным мостом (GPP Bridge), внутренние соединения которого (между апстримом, смотрящим в хост, и даунстримами, смотрящими в GPU и HDMI-аудиовыход) тоже предоставляют LM Capability — но фейковый. Процедура LM при этом успешно проводится, но похоже, ее результат предопределен: всегда будет отличный.
Кроме перечисленных нюансов остались еще несколько, которые могут помешать работе утилиты или требуют дополнительного исследования.
Во-первых, спецификация позволяет устройству не указывать MaxTimingOffset и MaxVoltageOffset (диапазон измерения в физических единицах), что делает невозможным точный автоматический расчет абсолютных значений. Если диапазон не указан, непонятно, как масштабировать шаги: брать минимальное значение (20% и 50 мВ), максимальное (50%, 500 мВ) или не брать ничего и смотреть в документацию на устройство. Остается разве что увидеть по количеству шагов возможный перекос по полосам.
Во-вторых, само по себе наличие функциональности LM еще не означает, что функция действительно поддерживается: требуется начать с запроса поля Margining Ready. И даже если этот бит взведен, то чтение остальных полей у некоторых устройств завершается ошибкой. В таких случаях pcilmr вынужден прерывать работу с сообщением «Error during caps reading».
Кроме того, параллельное определение границ по все полосам одновременно на данный момент дает странные результаты: данные как будто «слипаются», и этот нюанс требует дополнительного исследования.
Epic Thanks
Ни утилита, ни инструкции по предварительной настройке машины, ни эта статья не появились бы без вклада департамента разработки аппаратных средств. Многочисленные предложения по улучшению, тщательное тестирование, расшифровка спецификаций, поиск критериев оценки качества соединения, подбор корректных формулировок в тексте: Константин Ворон, Семен Клейман и Петр Беляев (кстати, читайте его статью про шероховатость фольг).
Расскажите в комментариях, пользуетесь ли вы какими-то утилитами для оценки качества PCIe-соединения? Какие плюсы и минусы у них есть?


