1. Я решил проверить 100 пар выборок по 15 (выборка обучения) и 1000 (тестовая выборка) векторов в системах счисления с равномерно распределёнными основаниями от 1,2 до 2 вместо двух заранее известных оснований.
2. Ещё я сделал линейную регрессию не только от расстояния от основания до золотого сечения, но и ещё от самого основания, количества координат в векторе и средней величины координаты в векторе ответа, чтобы учесть нелинейность зависимости ошибки от основания.
3. Также я проверил некоторые выборки на нормальность по критерию Колмогорова — Смирнова, ANOVе, но эти критерии показали, что выборки, скорее всего, отклоняются от гауссианы, поэтому я решил сделать взвешенную линейную регрессию вместо обычной. Однако ANOVA, хотя и показала F чуть-чуть меньшее, чем раньше (в районе 700-800 вместо 800-900), но всё равно результат остался более чем статистически значимым, а, значит, следовало провести ещё дополнительные тесты. В качестве этих тестов я взял гистограмму плотности распределения остатков регрессии и нормальный Q-Q — график функции распределения этих остатков.
Вот эти два графика:

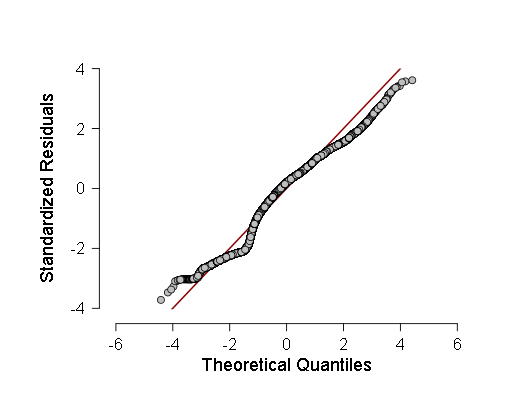
Как видно, хотя отклонение от нормального распределения у распределения остатков статистически значимое (а слева даже небольшая вторая мода видна на гистограмме), на деле оно весьма близко к гауссиане, поэтому можно (с осторожностью и большими доверительными интервалами) на эту линейную регрессию опираться.
Теперь о том, как я генерировал выборки для испытания над ними нейросети. Вот код программы для генерации выборок:
#define _CRT_RAND_S //Определяем нужную переменную для использования rand_s()
#include "main.h" //Включаем заголовочный файл (речь о нём пойдёт далее)
int main(void)
{
FILE *output,*test;
int i;
while (fopen("test.txt","w")==NULL)
i=0;
output=fopen("test.txt","w"); //Начинаем запись в файл с тестовой выборкой
unsigned int p;
p=0;//Создаём и инициализируем переменную для хранения значения rand_s();
rand_s(&p);
double a;
a=0;
a = 1.6+((double) ((double) ((double)p/UINT_MAX)-0.5)*0.8);//Генерируем основание системы счисления
int n;
n=0;//Инициализируем переменную для хранения размера вектора.
bool *t;//Создаём массив с цифрами после запятой в данной системе счисления.
while (malloc(sizeof(bool)*1000)==NULL)
n=0;
t = (bool *) malloc(sizeof(bool)*1000);
rand_s(&p);
double s;
s=0;
s = (double)p/UINT_MAX;//Генерируем случайное число от 0 до 1.
calculus(a,s,t,1000);//Переводим s в a-ичную систему счисления.
double mu;
int q;
mu=0;
q=0;
for (i=0;i<1000;i++)
{
if ((*(t+i))==true)
mu =(double) mu+1;
}//Вычисляем среднюю величину цифры после запятой, т. е. вероятность, что этой цифрой будет единица.
mu=(double) mu/1000;
printf("%10.9lfn",mu);
n = (int) ((double) 14)/(log(mu)*mu/(log((double) 1/2))+log((double) 1-mu)*(1-mu)/log((double) 1/2)); //Вычисляем размерность вектора такого, чтобы он хранил примерно 14 бит информации в a-ичной системе счисления.
printf("%in",n);
free(t);
while (malloc(sizeof(bool)*n)==NULL)
i=0;
t = (bool *) malloc(n*sizeof(bool));//Снова создаём массив для хранения чисел, но уже с другим числом цифр.
double x,y,z;
x=0;
y=0;
z=0;
int j;
j=0;
int m;
m=0;
m=2*n;
fprintf(output,"%i 1000n",m);//Выводим число координат в векторе и число пар векторов слагаемые-ответ.
fprintf(output,"%lfn",a); //Выводим основание системы счисления
for (i=0;i<1000;i++)
{//Вычисляем слагаемые с помощью криптографического ГПСЧ, складываем их, записываеем их в первый вектор, а сумму - во второй.
rand_s(&p);
x = (double) p/UINT_MAX;
rand_s(&p);
y = (double) p/UINT_MAX;
z=x+y;
calculus(a,x,t,n);
for (j=0;jА вот и код заголовочного файла:
#include
#include
#include
int main(void);
void calculus(double a, double x, bool *t, int n);//Определяем функцию для разложения числа x по основанию a в массив t из n элементов.
void calculus(double a, double x, bool *t, int n)
{
int i,m,l;
double b,y;
b=0;
m=0;
l=0;
b=1;
int k;
k=0;
i=0;
y=0;
y=x;
//Очищаем массив t от предыдущих данных.
for (i=0;i1)
{
b=1;
l=0;
while ((b*ay)&&(m Также я решил выложить полный код нейросети:
#include "main.h" //В заголовочном файле нет ничего, кроме включения других, стандратных заголовочных файлов и определения функции main(void).
int main(void)
{
FILE *input, *output, *test;
int i,j,k,k1,k2,l,q,n,m,r;
double *x,*y,*z,*a,s,s1,h,h1,d,mu,buffer;
d=0;
mu=0;
r=0;
unsigned int p;
n=0;
while (fopen("input.txt","r")==NULL)
i=0;
while (fopen("output.txt","w")==NULL)
i=0;
input = fopen("input.txt","r");
output = fopen("output.txt","w");
fscanf(input,"%i %i",&n,&m);//Считываем количество координат и количество пар векторов.
buffer=0;
fscanf(input,"%lf",&buffer);//Считываем основание просто чтобы дальше можно было считывать вектора.
while (malloc(sizeof(double)*n*m)==NULL)
i=0;
x = (double *) malloc(sizeof(double)*n*m);//Создаём массив для хранения слагаемых
while (malloc(sizeof(double)*n*m)==NULL)
i=0;
z = (double *) malloc(sizeof(double)*n*m);//Создаём массив для хранения произведения матрицы на вектор.
while (malloc(sizeof(double)*n*m)==NULL)
i=0;
y = (double *) malloc(sizeof(double)*n*m);//Создаём массив для хранения сумм.
for (k=0;k0.01)||(q<10))//Цикл выполняется, пока разница между произведением на матрицу вектора слагаемых и его же, но отклонённого в случайную сторону, не станет колебаться у какого-то среднего значения.
{
s=0;
for (k=0;k Далее поговорим о том, как я проводил взвешенную линейную регрессию. Для этого я просто вычислил среднеквадратические отклонения результатов работы нейросети, а затем поделил на них единицу. Вот исходный код программы, с помощью которой я это сделал:
#include
#include
#include
int main(void)
{
int i;
FILE *input,*output;
while (fopen("input.txt","r")==NULL)
i=0;
input = fopen("input.txt","r");//У меня результаты для каждого основания были в отдельном файле.
double mu,sigma,*x;
mu=0;
sigma=0;
while (malloc(1000*sizeof(double))==NULL)
i=0;
x = (double *) malloc(sizeof(double)*1000);
fscanf(input,"%lf",&mu);
mu=0;
for (i=0;i<1000;i++)
{
fscanf(input,"%lf",x+i);
}
for (i=0;i<1000;i++)
{
mu = mu+(*(x+i));
}
mu = mu/1000;
while (fopen("WLS.txt","w") == NULL)
i=0;
output = fopen("WLS.txt","w");
for (i=0;i<1000;i++)
{
sigma = sigma + (mu - (*(x+i)))*(mu - (*(x+i)));
}
sigma = sigma/1000;
sigma = sqrt(sigma);
sigma = 1/sigma;
fprintf(output,"%10.9lfn",sigma);
fclose(input);
fclose(output);
free(x);
return 0;
};
Далее я добавил получившиеся веса в таблицу, куда свёл все данные, полученные в результате работы программы, а также значения переменных для вычисления регрессии, а затем вычислил её в JASP. Вот результаты:
Results
Linear Regression
| Model Summary | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | R | R² | Adjusted R² | RMSE | |||||
| 1 | 0.175 | 0.031 | 0.031 | 0.396 | |||||
| ANOVA | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Sum of Squares | df | Mean Square | F | p | ||||||||
| 1 | Regression | 494.334 | 4 | 123.584 | 789.273 | < .001 | |||||||
| Residual | 15657.122 | 99995 | 0.157 | ||||||||||
| Total | 16151.457 | 99999 | |||||||||||
| Coefficients | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Unstandardized | Standard Error | Standardized | t | p | 0.5% | 99.5% | ||||||||||
| 1 | (Intercept) | -0.104 | 0.059 | -1.751 | 0.080 | -0.256 | 0.049 | ||||||||||
| Расстояние между основанием и золотым сечением | -0.113 | 0.010 | -0.080 | -11.731 | < .001 | -0.138 | -0.088 | ||||||||||
| Число измерений в векторе | 0.008 | 2.328e -4 | 0.529 | 32.568 | < .001 | 0.007 | 0.008 | ||||||||||
| Средняя величина координаты вектора в ответе | -0.951 | 0.181 | -0.332 | -5.255 | < .001 | -1.417 | -0.485 | ||||||||||
| Основание системы счисления | 0.489 | 0.048 | 0.687 | 10.252 | < .001 | 0.366 | 0.611 | ||||||||||
Далее у меня идёт гистограмма плотности распределения стандартизированных остатков регрессии:
А также нормальный квантиль-квантильный график стандартизированных остатков регрессии:
Затем я применил средние значения коэффициентов регрессии, получившиеся в её ходе, к переменным, и провёл свой статистический анализ по поиску наиболее вероятного минимума функции ошибки от основания системы счисления (насколько она связана с этими переменными), используя лемму Ферма, теорему Байеса и теорему Лагранжа следующим образом:
Дело в том, что распределение оснований системы счисления в выборке было заведомо равномерным, поэтому, если некое основание в промежутке (1,2;2) — минимум среднеквадратической ошибки, то так как по лемме Ферма она будет иметь нулевую производную, то плотность вероятности значений функции будет бесконечной. Тогда по теореме Байеса вычисляем бета-распределение функции распределения значений функции среднеквадратичных ошибок от основания, вычисляем её [функции распределения] доверительные интервалы в 99% в каждом значении функции среднеквадратических ошибок, а затем вычисляем доверительные интервалы уже в 98% (используем поправку Бонферрони) разницы между каждым значением функции распределения и значением в минимуме значения функции среднеквадратичных ошибок от основания системы счисления, затем делим крайние точки этого интервала на разницу между соответствующими аргументами функции распределения, и по теореме Лагранжа производная функции распределения в интервале между этими аргументами должна равняться хоть в одной точке получившемуся значению. Но эта производная и есть плотность вероятности, поэтому её максимум должен быть не меньше максимума из получившихся значений. Вот код программы, которой я этот анализ проводил, с пояснениями:
#include "main.h" //Включаем заголовочный файл.
int main(void)
{
FILE *input,*output;
int i,n,k,dFmax;
double *x,*y,*F1,*F2,*F,*dF,*dF1,*dF2,t1,t2,xmin,xmax,ymin,ymax;
t1=0;
t2=0;
while ((input=fopen("input.txt","r"))==NULL)
i=0;
while ((output=fopen("output.txt","w"))==NULL)
i=0;
n=0;
while (fscanf(input,"%i",&n)==NULL)
i=0;
while ((x = (double *) malloc(sizeof(double)*n))==NULL) //Массив для оснований системы счисления.
i=0;
while ((y = (double *) malloc(sizeof(double)*n))==NULL) //Массив для ошибок, вычисленных по коэффициентам.
i=0;
while ((F = (double *) malloc(sizeof(double)*n))==NULL) //Массив для медиан бета-функции функции распределения ошибок.
i=0;
while ((F1 = (double *) malloc(sizeof(double)*n))==NULL) //Массив для левых концов доверительных интервалов бета-распределений.
i=0;
while ((F2 = (double *) malloc(sizeof(double)*n))==NULL)//Массив для правых концов доверительных интервалов бета-распределений.
i=0;
for (i=0;i(*(dF1+dFmax)))&&((*(dF2+i))>(*(dF2+dFmax))))
dFmax=i;
}
xmin=0;
xmax=0;
ymin=0;
ymax=0;
xmin=(*x);
xmax=(*x);
ymin=(*y);
ymax=(*y);
//Вычисляем промежутки в, которых лежат минимальное значение функции распределения ошибок, и аргумент этой функции, от которого она имеет это значение:
for (i=0;i<=dFmax;i++)
{
if ((*(x+i))>xmax)
xmax=(*(x+i));
if ((*(x+i))ymax)
ymax=(*(y+i));
if ((*(y+i)) А вот и код заголовочного файла:
#include
#include
#include
int main(void);
double Bayesian(int n, int m, double x);//Вычисляем плотность вероятности бета-распределения с n "успехами" и m "неудачами", в нашем случае это "значение случайной величины не больше" и "значение случайной величины больше" точки, в которой вычисляется функция распределения:
double Bayesian(int n, int m, double x)
{
double c;
c=(double) 1;
int i;
i=0;
for (i=1;i<=m;i++)
{
c = c*((double) (n+i)/i);
}
for (i=0;i
Вот результат работы этой программы, когда я ей дал основания системы счисления и результаты регрессии:
x (- [1.501815; 1.663988]
y (- [0.815782; 0.816937]
("(-" в данном случае просто запись знака «принадлежит» из теории множеств, а квадратные скобки обозначают интервал.)
Таким образом, у меня получилось, что наилучшее основание системы счисления в плане наименьшего количества ошибок при передаче информации лежит в интервале от 1.501815 до 1.663988, то есть золотое сечение в него попадает вполне. Правда я сделал одно допущение при вычислении минимума и ещё одно при вычислении количества информации в разных системах счисления: Во-первых, я допустил, что функция ошибок от основания непрерывно дифференциируема, во-вторых, что вероятность того, что равномерно распределённое число от 1,2 до 2 будет иметь цифрой единицу в какой-то конкретной цифре, будет примерно одинаковой после какой-то цифры после запятой.
Если что-то я сделал совсем не так, или просто неправльно, я открыт для критики и предложений. Надеюсь эта попытка была более удачной.


