
Про оптимизацию изданы толстые книжки. Часть этих книжек полезна, часть уже устарела, так как описанные в них принципы давно перекочевали на этап автоматической оптимизации при сборке кода… Но существуют некоторые вещи, которые не имеют никакой ценности при разработке обычных программ под обычные процессоры, поэтому в типовых книжках обычно не описывается. Их мы сейчас и начнём рассматривать.
Введение
До сих пор я писал по принципу «одна проблема — одна статья». И статьи получались в формате лекций, затрагивая сразу несколько тем, объединённых общей проблемой. Но некоторые читатели сказали, что такие статьи невозможно прочесть за один заход. Поэтому теперь попробуем в одной статье рассказывать только об одной теме. Мне же тоже проще так писать. Посмотрим, вдруг будет удобней для всех.
Также, порадуем таинственных минусаторов. Если статья публикуется утром, то первый минус за неё прилетает через промежуток времени, за который весь текст прочесть невозможно. Кто-то делает это чисто из принципа, пощадив только темы про UDB и балалайку. Если публикация прошла не утром, а днём, то он кидает минус с задержкой. Второй минус прилетает в течение дня (и тот товарищ, кстати, тоже пощадил темы про UDB и про балалайку). В новом формате будет больше статей, а значит — больше приятных моментов для этой парочки (хотя, лично мне, как автору, от их действий становится грустно и обидно).
Предыдущие статьи цикла:
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.
- Веселая Квартусель, или как процессор докатился до такой жизни.
Таинственное поведение типовой системы
Давайте сделаем самую что ни на есть простейшую процессорную систему, включив в неё тактовый генератор, процессор Nios II/f, контроллер SDRAM и порт вывода. Вот так по-спартански эта система выглядит в Platform Designer
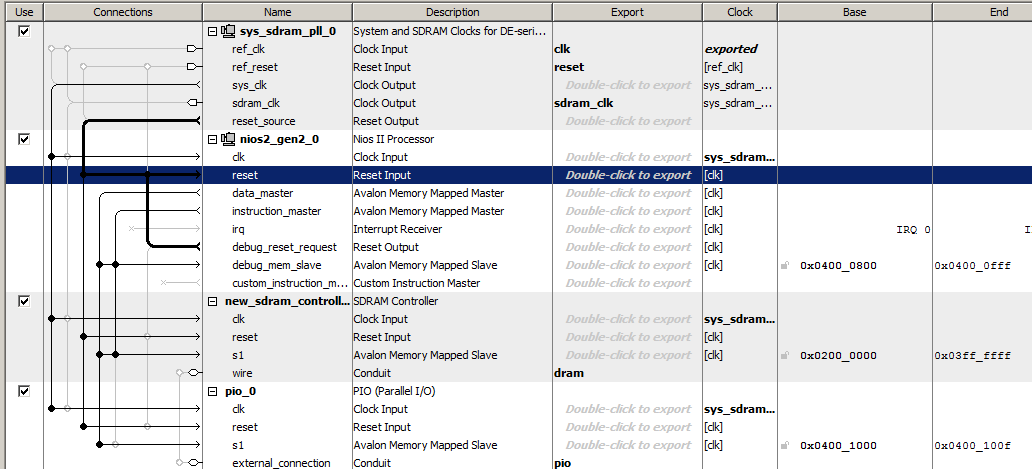
Программный код для неё будет содержать всего одну функцию, тело которой выглядит несколько странно, так как содержит много повторяющихся строк, но нам это пригодится.
extern "C" { #include "sys/alt_stdio.h" #include #include } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; } Поставим точку останова на последнюю из строк:
IOWR (PIO_0_BASE,0,0);в функции MagicFunction и запустим программу. Что мы получили на выходе порта? Очень рваные импульсы:
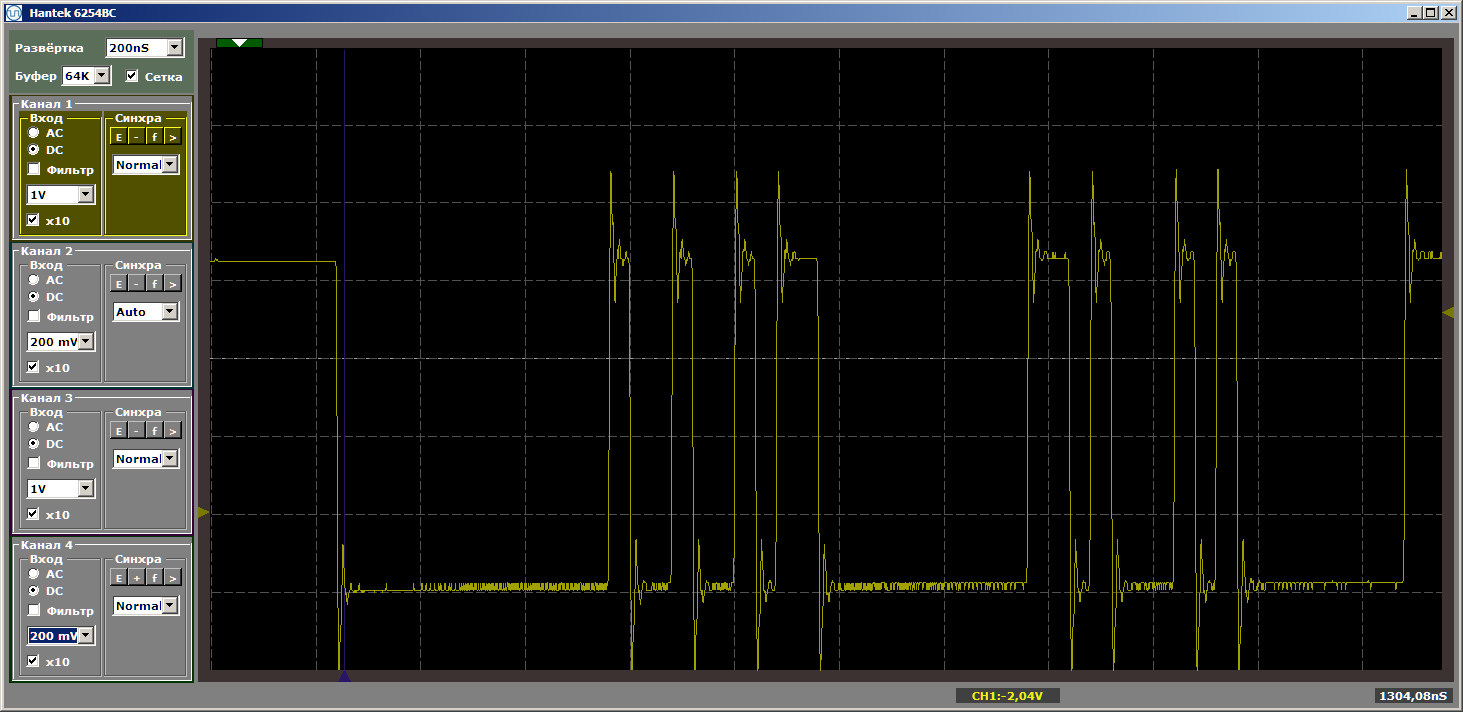
Ужас? Ну да. Однако нажмём на «запуск» ещё раз, чтобы отработала ещё одна итерация цикла. И теперь на выходе видим красивый ровный меандр:
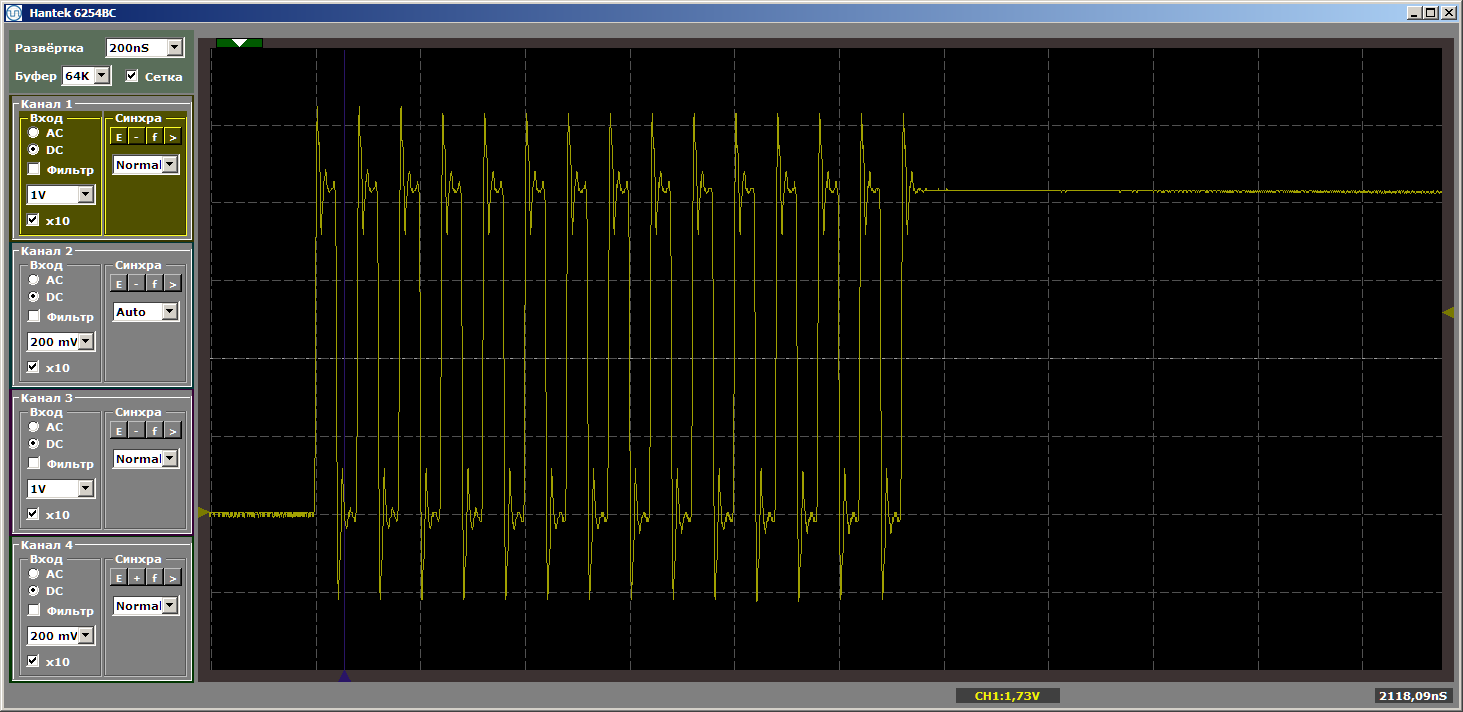
Ещё одна итерация. И ещё одна… Стабильный меандр. Снимаем точку останова и смотрим работу в динамике — больше подобных разрывов нет. Идут бесконечные пачки импульсов.
Почему же у нас были рваные импульсы при первом проходе? Случайность? Нет. Останавливаем отладку и запускаем её заново. И вновь получаем рваные импульсы. Разрывы у нас возникают всегда при входе в программу.
Разгадка кроется в кэше
Собственно, разгадка такого поведения кроется в кэше. Программа у нас хранится в SDRAM. Выборка кода из SDRAM — дело не быстрое. Надо подать команду чтения, надо подать адрес, причём адрес состоит из двух частей. Надо немного подождать. Только потом микросхема выдаст наружу данные. Чтобы не возникало подобных задержек каждый раз, микросхема может выдать не одно, а несколько подряд идущих слов. Временные диаграммы сегодня рассматривать не будем, отложим это на следующие статьи.
Ну, а со стороны процессорного ядра нам по умолчанию был создан кэш. Вот его настройки:
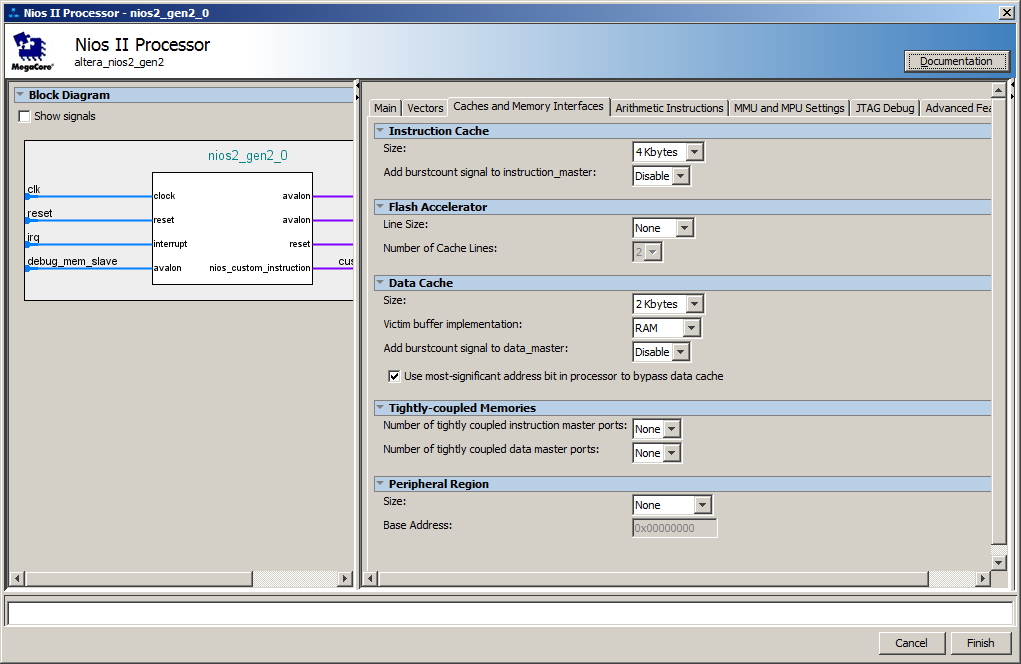
Собственно, задержки возникают в момент, когда идёт пакетная загрузка инструкций из SDRAM в кэш-память. При следующих итерациях код уже находится в кэше, так что подгрузка уже не требуется.
На осциллограмме видно в среднем 8 записей в порт (4 раза пишется единица и 4 раза — ноль) на одну операцию подгрузки. Одна запись — одна команда ассемблера, что можно выяснить, выбрав пункт меню Window->Show View->Other:
а затем — Debug->Disassembly:
Вот наши сишные строки и соответствующий им ассемблерный код:
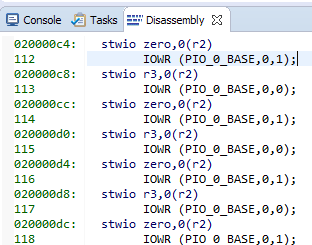
8 команд по 4 байта. Получаем 32 байта на строку кэша… Заглядываем в наш любимый справочный файл C:WorkCachePlaysoftwareCachePlay_bspsystem.h и видим:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5 Практически вычисленные данные совпали с теорией. Причём из документации следует, что размер строки не может быть изменён. Он всегда равен тридцати двум байтам.
Чуть более сложный эксперимент
Попробуем спровоцировать кэш на перезагрузку во время устоявшейся работы. Давайте чуть изменим тестовую программу. Сделаем две функции и будем вызывать их из функции main(), поместив цикл в неё. Точку останова я ставить не буду. Кстати, если сделать функции полностью идентичными, оптимизатор заметит это и уберёт одну из них, так что хотя бы одной строкой, а различаться они должны… Это к тому, что я писал в начале: оптимизаторы нынче очень умны.
extern "C" { #include "sys/alt_stdio.h" #include #include } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; } Получаем достаточно красивый результат, снятый уже в устоявшемся режиме работы программы.
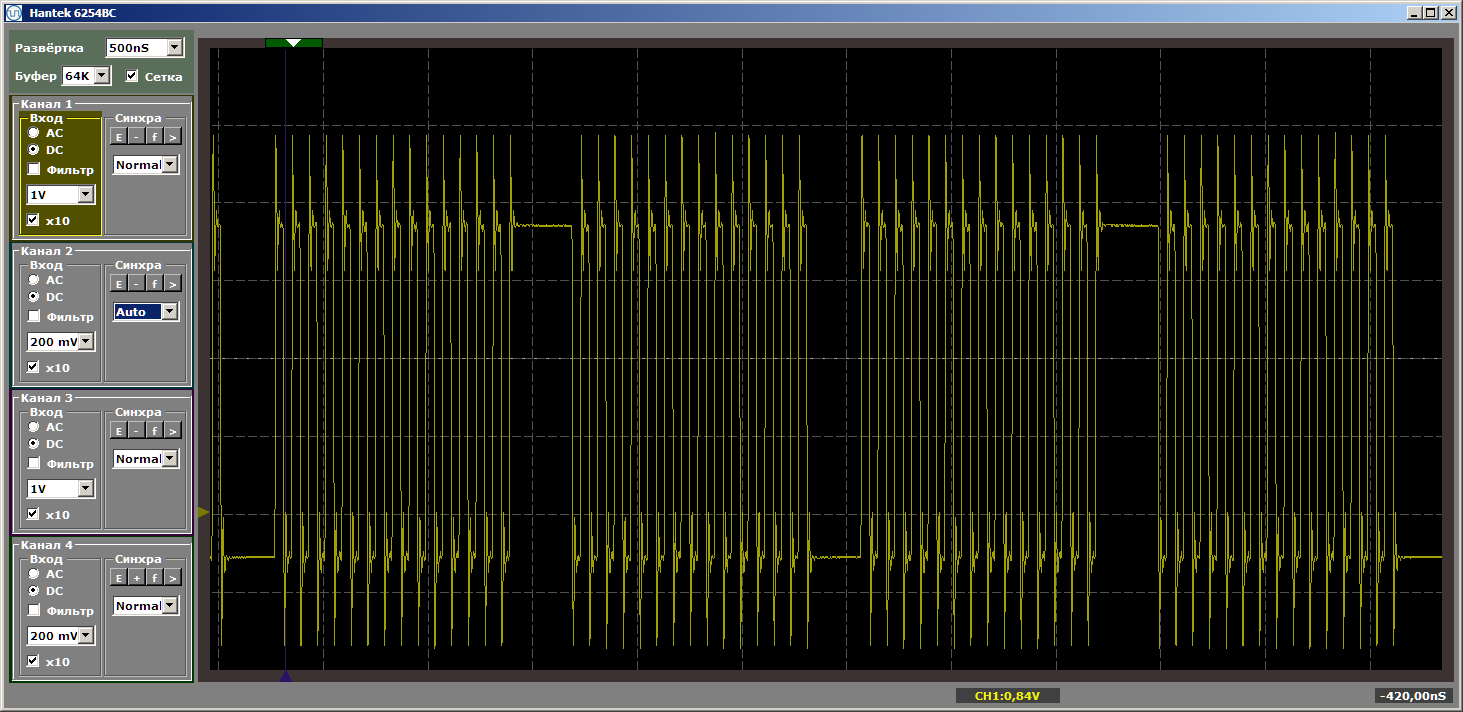
А теперь поместим между этой парой функций какую-нибудь новую, причём вызывать её мы не будем, она просто будет размещаться между ними в памяти. Сейчас попробую сделать так, чтобы она заняла побольше места… Размер кэша у нас равен 4 килобайта, вот и сделаем её равной четырём килобайтам… Просто вставим 1024 NOP-а, каждый из которых имеет размер 4 байта. Я покажу конец первой функции, новую функцию и начало второй, чтобы было ясно, как изменяется программа:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ... Логика работы программы не изменилась, но при прогоне теперь получаем рваные импульсы
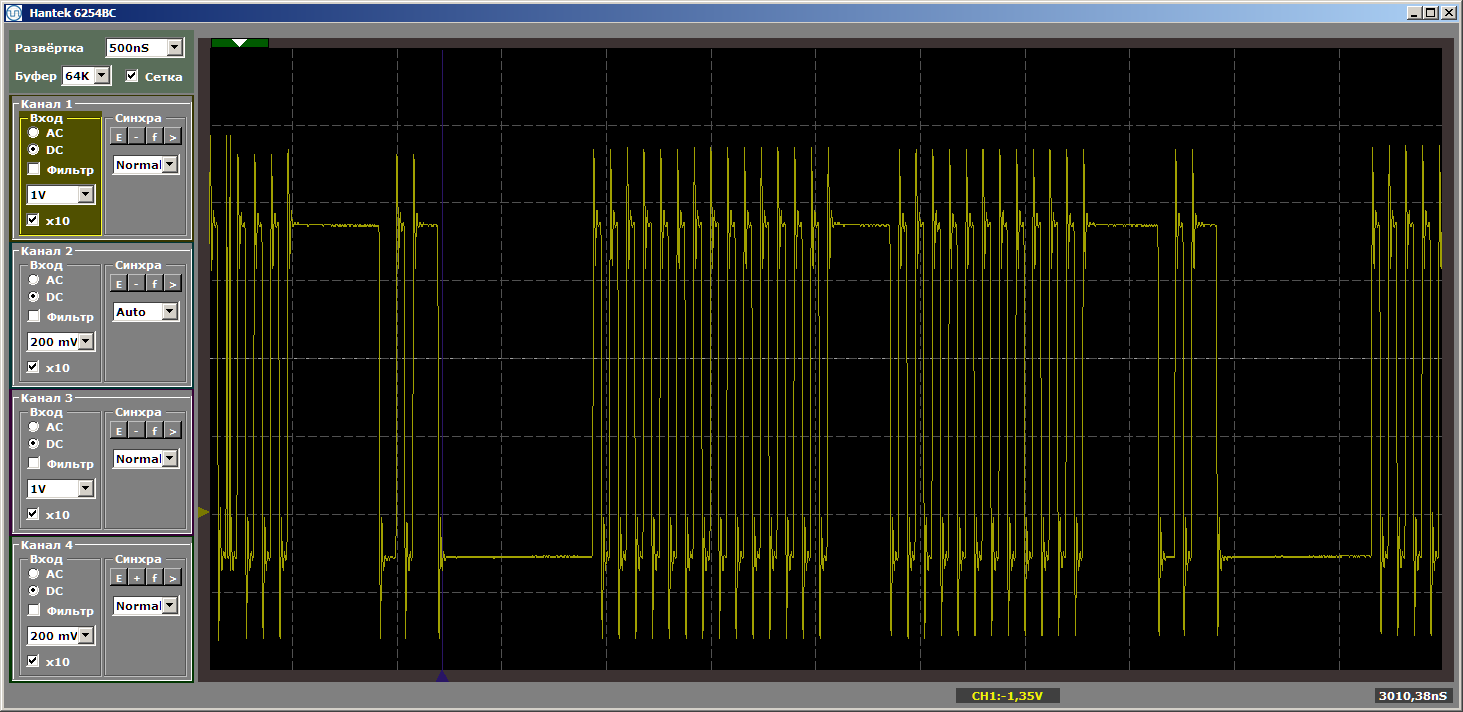
Задам наивный вопрос: мы вылетели за кэш, и теперь, по мере увеличения разрыва, всегда будет идти подгрузка? Вовсе нет! Поменяем размер «плохой» функции, сделав её равной, скажем, пяти килобайтам. Пять больше, чем четыре, мы по-прежнему вылетаем? Или нет? Заменяем вставку на такую:
volatile void FuncBetween() { Nops1024 Nops256 } И вновь получим красоту:
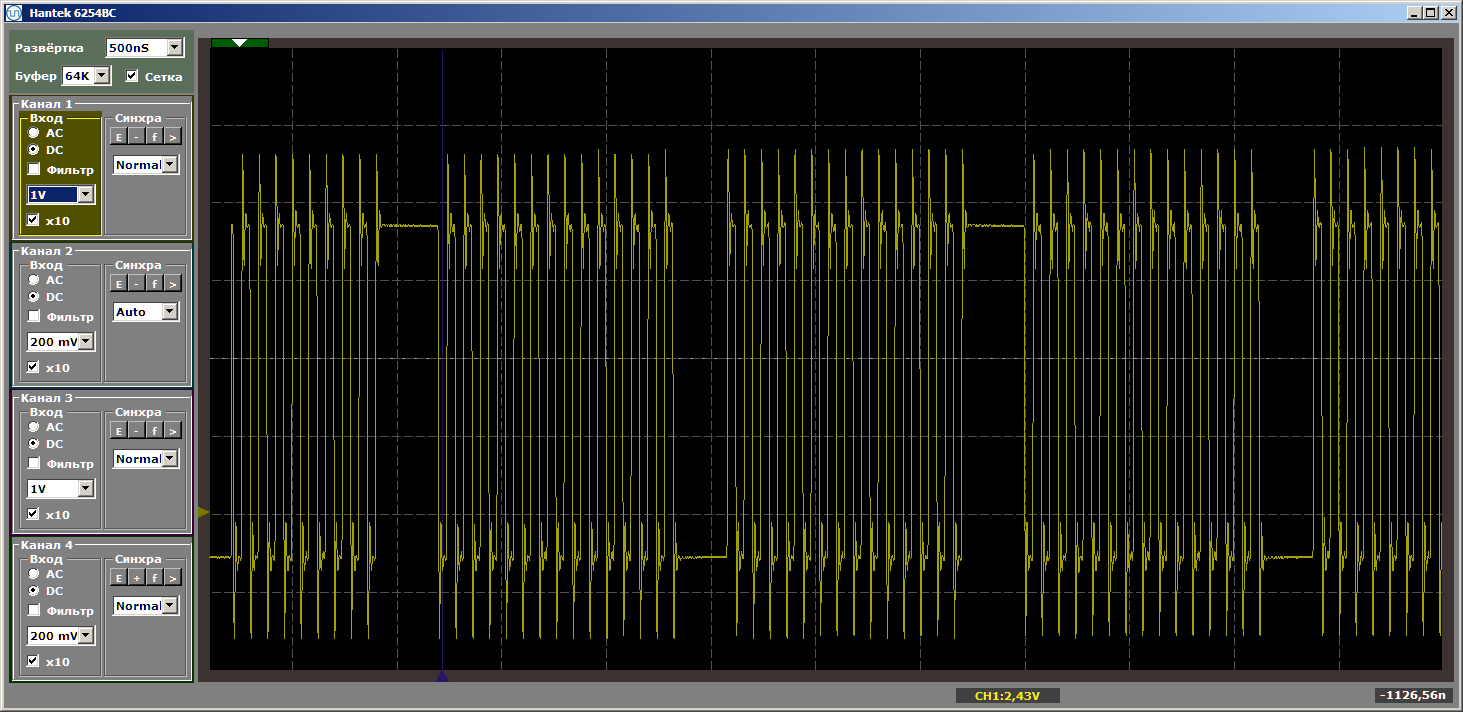
Так от чего же зависит необходимость подгрузки кода в кэш? Можем ли мы предсказать что-либо, или каждый раз надо смотреть по факту? Углубимся в теорию, в чём нам поможет документ Nios II Processor Reference Guide.
Немного теории
Вот так в процессоре расщепляется поле адреса: 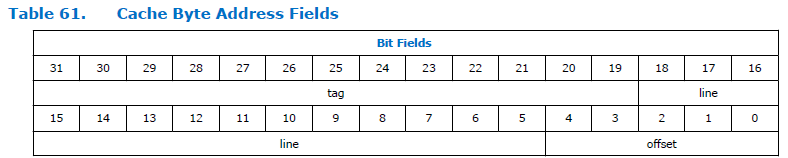
Как видим, адрес разбит на три части. Тэг, строка и смещение. Размерность поля «смещение» постоянна для процессора Nios II и всегда равна пяти битам, то есть она может адресовать 32 байта. Размерность поля «строка» зависит от объёма кэша, заданного при конфигурировании процессора. На приведённом рисунке она достаточно велика. Я не знаю, почему в документе у неё такая огромная размерность. У нас размер кэша равен 4 килобайта, значит суммарная разрядность строки и смещения равна 12 битам. 5 бит занимает смещение, для строки остаётся 12-5=7 бит.
Получаем некую таблицу из 128 строк, по 32 байта длиной каждая. Я приведу, скажем, первые 6 строк:
| Поле «тэг» | Поле «строка» | Младшие биты адреса | Куда попадёт |
|---|---|---|---|
| Не важно | 0x00 | От 0x000 до 0x01F | В строку 0 кэша |
| Не важно | 0x01 | От 0x020 до 0x03F | В строку 1 кэша |
| Не важно | 0x02 | От 0x040 до 0x05F | В строку 2 кэша |
| Не важно | 0x03 | От 0x060 до 0x07F | В строку 3 кэша |
| Не важно | 0x04 | От 0x080 до 0x09F | В строку 4 кэша |
| Не важно | 0x05 | От 0x0A0 до 0x0BF | В строку 5 кэша |
| … | … | … | … |
| Не важно | 0x7F | От 0xFE0 до 0xFFF | в строку 127 кэша |
И вот мы обратились к адресу 0x123004. Если отбросить часть «не важно», пара «строка + смещение» равны 0x004. Это диапазон нулевой строки. Данные будут загружены в эту строку. И дальше работа с данными из диапазона 0x123000 до 0x12301F будет работать через кэш. При каких условиях строка будет перегружена? При обращении к любому другому адресу, кончающемуся на диапазон от 0x000 до 0x01F. Ну, то есть, если мы обратимся к адресу 0xABC204, всё останется на месте, ведь диапазон младших адресов не пересекается с нашим. И 0xABC804 ничего не испортит. А вот при исполнении кода с адреса 0xABC004 приведёт к тому, что в строку кэша будет загружено новое содержимое. И уже переход на адрес 0x123004 вновь приведёт к перегрузке. Если постоянно прыгать между 0xABC004 и 0x123004, перегрузка будет происходить постоянно.
Попробуем изобразить это в виде рисунка. Пусть у нас в кэше есть всего 8 строк, так удобнее раскрасить их в разные цвета. Размер строки я сделаю 0x10, так удобнее расписать адреса на рисунке (помним, что в реальном Nios II размер строки всегда 0x20 байт). Память бьётся на условные страницы, имеющие такой же размер, что и строки кэша. Красная страница памяти всегда попадёт в красную строку кэша, оранжевая — в оранжевую, ну и так далее. Соответственно, старое содержимое будет выгружено.

Ну, собственно, теперь понятно поведение программы при эксперименте. Когда функции были разнесены строго на 4 килобайта, они попали в страницы сходных цветов. Поэтому код
while (1) { MagicFunction1(); MagicFunction2(); } приводил к загрузке кэша то ради одной, то ради другой функции. А когда разнос составил не 4, а 5 килобайт, функции были разнесены в блоки разных цветов. Конфликт отсутствовал, всё работало без задержек.
Выводы
Когда много лет назад я прочёл, что существуют линейки ядер Cortex A, Cortex R и Cortex M, рассчитанные на производительные вещи, на работу в реальном времени и на работу в дешёвых системах соответственно, сначала я не понял, а в чём, собственно, разница. Нет, дешёвые системы — это понятно, но вот первые два чем различаются? Однако, поиграв в ядро Cortex A9, имеющееся в ПЛИС Cyclone V SoC, я прочувствовал все недостатки кэша при работе с железом. В ядре Cortex A кэшей много… И предсказуемость поведения системы практически нулевая. Но зато кэш поднимает производительность. Иногда лучше, если всё работает не предсказуемо с точностью до такта, но быстро, чем предсказуемо медленно. Особенно это касается вычислений или, скажем, отображения графики.
Самая же главная проблема состоит не в том, что описанные в статье вещи возникают, а в том, что от сборки к сборке поведение системы будет изменяться, так как, на какие адреса ляжет функция после добавления или удаления кода, не знает никто. 15 лет назад в проекте эмулятора игровой приставки Sega для декодера кабельного телевидения нам пришлось делать целый препроцессор, который после каждой правки двигал функции, эмулирующие команды ассемблера Motorola на ядре SPARC-8 так, чтобы у них время выполнения было всегда одним и тем же (там за счёт кэша иначе всё сильно плавало).
Но когда нам нужна предсказуемость? Разумеется, при формировании временных диаграмм программным путём (помним, что вообще в ПЛИС можно поручить это и аппаратуре, но при быстрой разработке бывают и частности). А вот при работе вычислительных алгоритмов она не так важна. Разве что алгоритм сложный, тогда надо быть уверенным, что критичные участки не вызывают постоянной перегрузки кэша. В большинстве же случаев, кэш проблем не создаёт, а производительность — повышает.
В следующей статье мы рассмотрим, как можно вынести критичные к предсказуемости функции в некэшируемую память, всегда работающую на максимальной скорости, а также обсудим неявные преимущества ПЛИС перед стандартными системами, вытекающие из применённых при этом технологий.
Для самых внимательных
У въедливого читателя может возникнуть вопрос: «А почему при вставке четырёх килобайт кода осциллограмма была недостаточно рваной?» Всё просто. Если вставлять ровно 4 килобайта, то получаем следующие адреса размещения функций в памяти:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096 Для идеально плохой осциллограммы надо вставить NOP-ов так, чтобы 4 килобайта составил их объём вместе с длиной функции MagicFunction1(). На что ни пойдёшь ради красивой картинки! Меняем вставку на такую:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 } Ещё и ещё раз обращаю внимание, что вставка не получает управления. Она просто меняет положение функций в памяти друг относительно друга. При такой вставке получаем желаемый ужасный ужас:
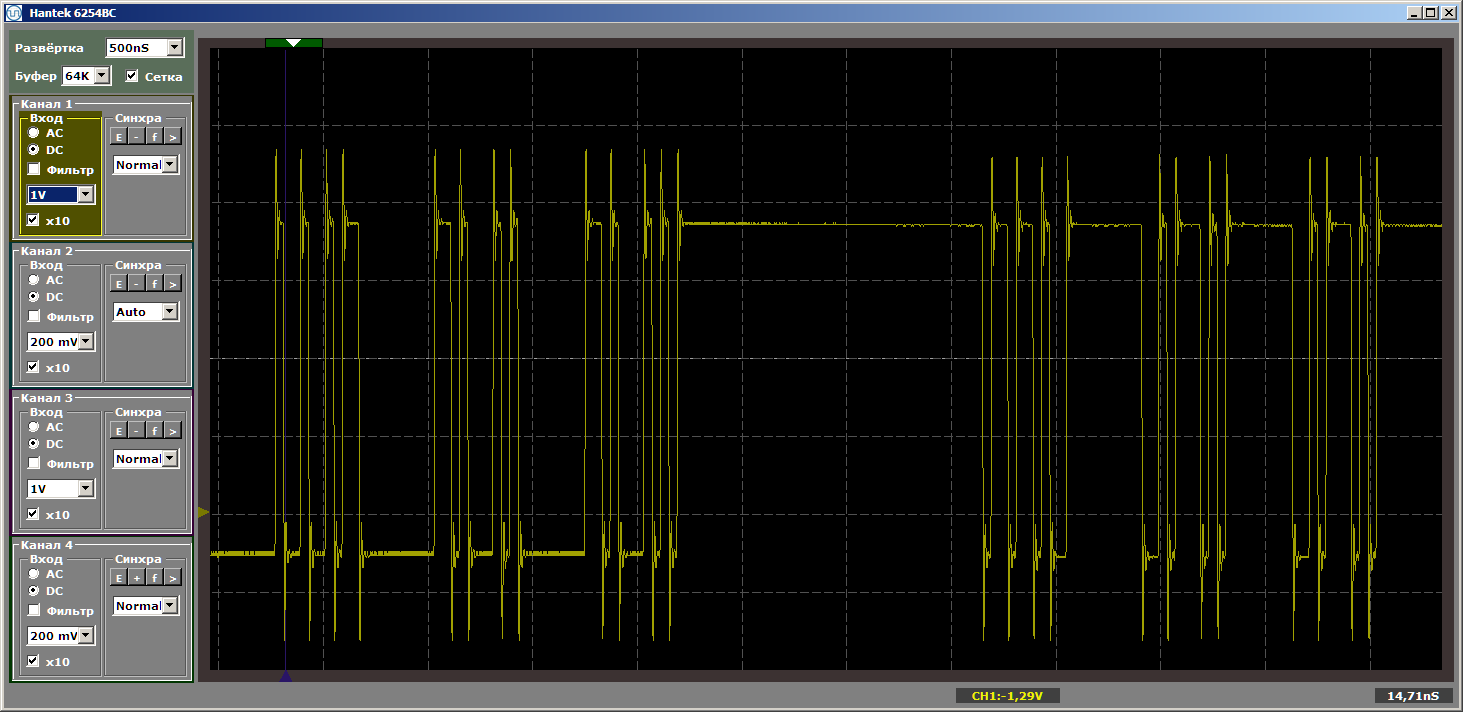
Мне показалось, что такие детали, вставленные в основной текст, отвлекут всех от главного, поэтому я вынес их в постскриптум.
Источник


