
Как работают системы распознавания речи
В русскоязычном сегменте интернета не так много информации о том, как устроены системы распознавания речи. В этой статье мы, команда проекта Amvera Speech, расскажем нюансы технологии и опишем путь создания собственного решения. В конце статьи – бесплатный телеграм-бот для теста системы распознавания речи, построенной на архитектуре, описанной в статье.
Сложности, с которыми сталкиваются разработчики систем распознавания речи:
Есть распространенное мнение, что распознавание речи — давно решенный кейс, но это не совсем так. Действительно, задача решена для определенных ситуаций, но универсального решения пока не существует. Это происходит из-за ряда проблем, с которыми сталкиваются разработчики.
-
Зависимость от домена
a) Разные дикторы
b) «акустический» канал записи звука: кодеки, искажения
c) Разное окружение: шум в телефоне, в городе, фоновые дикторы
d) Разный темп и подготовленность речи
e) Разная стилистика и тематика речи
-
Большие и «неудобные» наборы данных
-
Не всегда интуитивно понятная метрика качеств.
Метрика качества
Качество распознавания измеряется по метрике WER (Word Error Rate).

Insertions – вставки слов, которых нет в исходной аудиозапис.
Substitutions – замены слов на некорректные
Deletions – система слово не распознала и сделала пропус.
Пример расчета
Исходные данные: Стационарный (неразборчивая речь) телефон зазвонил поздней ночью
Гипотеза: Стационарный синийi айфонs прозвонилs поздней ночь.
WER = 100*(1+2+0)/5 = 60% (т.е. ошибка равна 60%).
При этом есть как простые заблуждения при подсчете метрики, так и более сложные.
Пример простых заблуждений при подсчете метрики
— Е/е с точками. Система переводит речь в текст и везде использует букву Е без точек, в то время как эталон, с которым сравнивается транскрипция, содержит Е с точками. Это неправомерно увеличивает количество Substitutions и увеличивает WER на 1%.
— разное написание таких слов, как алло, але, алле и т.д.
— строчные и заглавные букв.
— усреднение по текстам, а не подсчет общего количества слов. Бывает, что в одном тексте WER 0,6, в другом 0,5, а в третьем – 0,8. Неверно будет вывести WER как среднее арифметическое из этих значений. Правильнее – подсчитать общее количество слов на всех текстах и на основе этого рассчитать WER.
Более сложные заблуждения могут быть вызваны тем, что на разных тестовых выборках WER будет разным. Иногда на одной конкретной аудиодорожке испытываемое решение работает лучше или хуже, чем решения конкурентов. Но делать из этого общий вывод о качестве работы решения – некорректно. Необходимы результаты на большом объеме данных.
Типы систем распознавания речи
Системы распознавания речи бывают двух видов – гибридные и end2end. End2end переводят последовательность звуков в последовательность букв. Гибридные системы содержат акустическую и языковую модель, работающие независимо. Решение Amvera Speech построено на гибридной архитектуре.
Устройство гибридной системы распознавания речи
Принцип работы гибридной системы распознавания речи.
• Нейронная сеть классифицирует каждый конкретный фрейм звука,
• HMM моделирует «динамику», «лексикон», «лексику», опираясь на постериоры NN,
• Алгоритм Viterbi (Viterbi decoder, beam-search) занимается поиском по HMM оптимального пути, с учетом постериоров классификатора.

Первым шагом в гибридной модели распознавания речи выделяются признаки. Как правило, это MFCC коэффициенты.
Затем акустическая модель решает задачу классификации фреймов. Далее используется Viterbi-decoder (поиск по лучу). Он использует предсказание акустической модели и статистику языковой модели, которая по ngram показывает вероятность встречаемости звуков и слов. Затем производится рескоринг и выдается наиболее вероятное слово.

Ниже – иллюстрация классификации фреймов. Продемонстрированы фонемы в фреймах для слов «да и нет». Вероятность каждой из фонем записана в соответствующую ячейку. .
|
№ фрейма/графема |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Д |
0 |
0 |
0,6 |
0,7 |
0 |
0 |
0 |
0 |
0 |
|
А |
0 |
0.1 |
0 |
0.1 |
0.4 |
0.5 |
0.4 |
0.1 |
0 |
|
Н |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Е |
0 |
0.1 |
0.1 |
0.1 |
0.6 |
0.5 |
0.4 |
0 |
0 |
|
Т |
0 |
0 |
0.3 |
0 |
0 |
0 |
0.1 |
0 |
0 |
|
Тишина (SIL) |
1 |
0.8 |
0 |
0.1 |
0 |
0 |
0.1 |
0.9 |
1
|
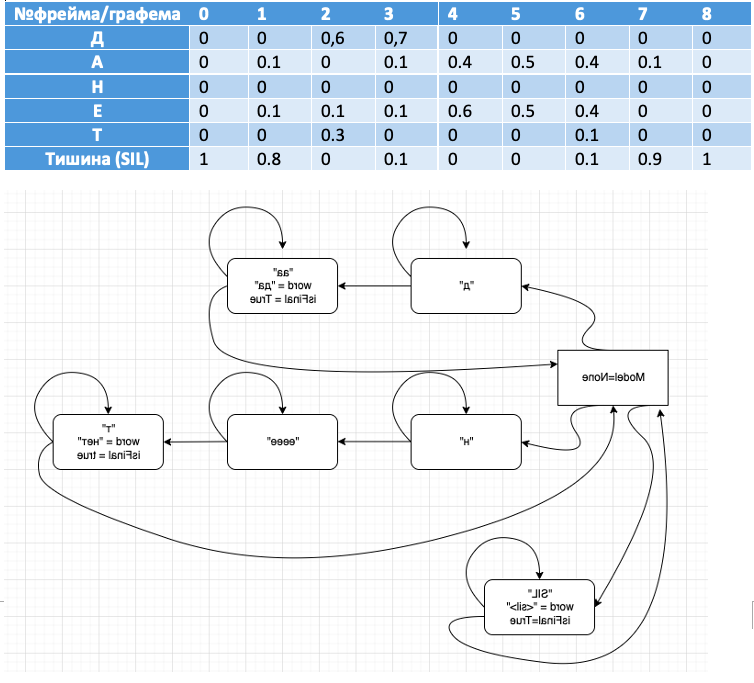
Визуализируем принцип работы вычислительного графа
Представьте, что у вас в первом фрейме классификатор обнаружил фонему «д», и так 10 раз подряд. Цикл будет выполняться, пока не обнаружится фонема «а», и если слово содержится в словаре, оно будет записано.
Аналогично, алгоритм отработает слово «нет» и закончит работу, когда в
канале наступит тишина «SIL».

Совместим визуализацию поискового графа в связке с фреймами для большей наглядности: .
Обучение гибридной системы распознавания речи
Рассмотрим общий принцип обучения классификатора акустической модели, принцип сопоставления фреймов с фонемами, количество классов и способы улучшения решения.
Обучение классификатора акустической модели:
-
Возьмем графемы.
Пример – М, А, Ш, А
-
Представим их в виде фонем, получится m* i1 sh a0
Для русской речи на обучающей выборке в 80 часов фонемы на 1 процент лучше, при 4 тысячах часов – разницы уже нет.
-
Используем бифоны/биграфемы
Моделируют влияние соседних фонем
Левые: SIL (sil)M (м)А (а)Ш (ш)А SIL
Правые: SIL M(a) A(ш) Ш(а) А(sil) SIL
-
Можно использовать трифоны
SIL (sil)M(a) (м)А(ш) (а)Ш(а) (ш)А(sil) SIL
-
Либо использовать многостейтовые фонемы/графемы/трифоны …
Как фрейму приписать фонему?
Проще всего это описать фразой «натянуть сову на глобус».

Для этого используем связку алгоритмов Flat-start+Viterbi forced alignment: .
-
берем пару звук-текст
-
получаем фонемную запись
-
разбиваем звук на равные части по числу фонем, приписывая соответствующие лейблы
-
обучаем классификатор (обычно GMM).
-
делаем forced alignment, получаем уточненные labels
-
Повторяем пункт 4
После нескольких итераций, получаем labels, пригодные для обучения нейронной сети.
Классы
Если используются {би, три} {фоны, графемы}, то:
Проблема 1: классов слишком много
Бифоны: 57 фонем^2 – 3249
Двустейтовые бифоны: (2 стейта*57 фонем )^2=12996
Трифоны: 57фонем^3 = 185193
Проблема 2: размеры классов не сбалансированы
Решение – кластеризация
Объединяет похожие классы (5-10 тыс. классов)
Балансирует размеры классов
(класс называют сеноном для фонемных, ченоном для графемных моделей)
Улучшаем распознавание
Используем MMI или MPE/sMBR
-
Строится CE-модель
-
Строится «числитель» — множество вариантов распознавания, приводящих к правильному ответу
-
Строится «знаменатель» — много неправильных вариантов распознавания
-
Loss = f(числитель)/f(знаменатель) т.е. «поднять» правильные и «опустить неправильные»
Достоинства: sMBR несколько поднимает качество
Недостатки: стремится оттянуть выдачу label, следовательно портит time-разметку и latency.
Достоинства гибридной архитектуры распознавания речи
-
Акустическая модель отделена от языковой. Языковую модель легко дополнить дополнительной информацией (новые слова и т.д.).
-
Можно быстро получить NBest списки для улучшения с помощью языковой модели.
-
Для обучения достаточно несколько десятков часов аудиозаписей.
Недостатки гибридной архитектуры распознавания речи
-
Тяжеловесны для мобильных устройств.
-
Не умеют распознавать слова, которых нет в словаре.
-
Не модно.
Как итог — мы рассмотрели принцип устройства классической гибридной архитектуры распознавания речи.
Бонус для дочитавших: наш телеграм бот @AmVeraSpeechBot. В боте вы можете проверить качество работы нашего решения по распознаванию речи на основе классической гибридной архитектуры. Просто отправьте в бот короткую аудиодорожку или голосовое сообщение – и получите текстовую расшифровку.
И второй бонус. Сейчас мы проводим бета-тестирование нашего облака для хостинга IT-приложений и приглашаем всех желающих присоединиться к тестированию. Это абсолютно бесплатно: с нас — облачные ресурсы, с вас — обратная связь. Подробности по ссылке.
В следующей статье мы подробнее расскажем о достоинствах и недостатках end2end и гибридных систем распознавания речи.
Похожие статьи
 Genshin Impact 7.0 откроет Снежную 12 августа
Genshin Impact 7.0 откроет Снежную 12 августа Компьютер или консоль: вечный спор, который не смогла разрешить даже Steam Machine
Компьютер или консоль: вечный спор, который не смогла разрешить даже Steam Machine Как радикальное упрощение геймплея принесло миллионы создателям нестандартного шутера
Как радикальное упрощение геймплея принесло миллионы создателям нестандартного шутера Топ дьяблоидов 2026 года в ожидании релиза Path of Exile 2
Топ дьяблоидов 2026 года в ожидании релиза Path of Exile 2 Если ссылки схлопываются, значит, это кому-то нужно
Если ссылки схлопываются, значит, это кому-то нужно Сборка ПК для GTA 6 в 2026 году: мощно и недорого
Сборка ПК для GTA 6 в 2026 году: мощно и недорого Трейлер кооперативной игры SHORE набрал 5,3 млн просмотров за сутки
Трейлер кооперативной игры SHORE набрал 5,3 млн просмотров за сутки Unreal Engine 6: чего ждать от нового движка
Unreal Engine 6: чего ждать от нового движка