
Как мы тестируем системы микрофонов на STM32: опыт разработчиков устройств Яндекса

Привет, я Геннадий «Крэйл» Круглов из команды аппаратных решений Яндекса.
Подбор микрофонов для микрофонной матрицы — сложная и интересная часть нашей работы: мы тестируем модели с различными параметрами, экспериментируем с разнообразными конфигурациями матриц, совершенствуем алгоритмы обработки звука.
Разработчикам, которые занимаются созданием алгоритмов эхо- и шумоподавления, бывает удобно не просто обрабатывать сырые данные, которые заранее сняты с устройства в лаборатории, но и взаимодействовать, например, с новой микрофонной матрицей в реальном времени, подключив её к своему ноутбуку.
Это кажется несложным только на первый взгляд. В этом материале я объясню, как мы решили задачу передачи звука с семи микрофонов с PDM-интерфейсом на компьютер через USB, с какими аппаратными и программными нюансами столкнулись и как их преодолели (спойлер: этот подход может быть адаптирован для матриц с числом микрофонов ≤ 8). В конце поста поделюсь ссылкой на стрим, где я показываю процесс разработки на микроконтроллере STM32, и расскажу о следующей серии.
Постановка задачи
Немного предыстории: чтобы создать управляемый луч чувствительности, для первой Яндекс.Станции была выбрана схема с семью микрофонами (аналоговыми), для версии Мини — с четырьмя (уже цифровыми). Для других продуктов рассматриваются различные конфигурации, но всё же семимикрофонная матрица для нас основная, классическая.
Итак, дано: семь цифровых микрофонов, необходимость их тестировать. Найти: не слишком сложно реализуемый и гибкий способ взаимодействия с ними. Логично разделить задачу на две:
1. Получить данные с микрофонов.
2. Отправить их в компьютер.
В готовом устройстве при обращении пользователя к Алисе сигналы с цифровых микрофонов подаются прямо в центральный процессор (корректней назвать его SoC — System-on-Chip, но «процессор» привычнее и удобнее), он обладает достаточной мощностью для их обработки. Но для отладки алгоритмов гораздо удобнее получать эти данные напрямую в компьютер разработчика. Самый простой способ – подключиться по USB: таким образом, на плате должен быть микроконтроллер с соответствующим блоком. Мы любим контроллер STM32, но подать звуковой поток с микрофонов непосредственно на него невозможно: нет блока приёма сигнала PDM (модуляция плотностью импульсов) — выходного интерфейса цифровых микрофонов.
Другой вариант — подключить микрофонную плату к отладочной плате от производителя используемого SoC. Но это решение завязано на линуксовый alsamixer, и его параметры сильно влияют на результат преобразования PDM в PCM. Эти блоки могут отличаться не только для процессоров разных производителей, а даже для двух моделей одного вендора. Нам же, напоминаю, требовалось простое решение, прозрачное и предсказуемое.
Аппаратное решение
Смиримся с невозможностью STM32 принять многоканальный PDM. Можно было бы воспользоваться блоком SPI для приема PDM-сигнала, но по одной SPI-шине можно завести только один микрофон. Мы работаем с контроллером STM32L476RC, где таких шин всего три. Дополнительная сложность: PDM-сигнал достаточно высокочастотный, необходимо делать его децимацию, усреднение, обработку, фильтрацию — для семи микрофонов эта задача представляется достаточно сложной.
Поскольку речь идёт об отладочной плате, а не прототипе для массового производства, остановимся на специализированной микросхеме TSDP18xx. Она делает всё необходимое: генерирует нужные частоты и сигналы для PDM, производит усреднение и обработку PDM-сигнала, превращает это всё в I2S-сигнал. Точнее, TDM (Time Division Multiplexing), потому что I2S-шина предполагает два канала, а если по этим же проводам гнать больше, уже не совсем корректно называть это I2S.
Плюс этого подхода в том, что всю работу по подготовке и усреднению берет на себя TSDP. Минус — все алгоритмы намертво зашиты внутри этой микросхемы, и изменить их не получится. В частности, нельзя регулировать громкость путём модификации параметров усреднения. Но для отладки это не критично.
Следите за руками: микрофонов семь, каналов у микросхемы восемь. Тот, что не используется, на выходе всё равно есть, поэтому в дальнейшем для простоты я буду говорить о восьмиканальном аудиопотоке.
Итак, поднимаем восьмиканальный TDM на STM32, получаем восьмиканальный аудиопоток. Как двигаются данные:
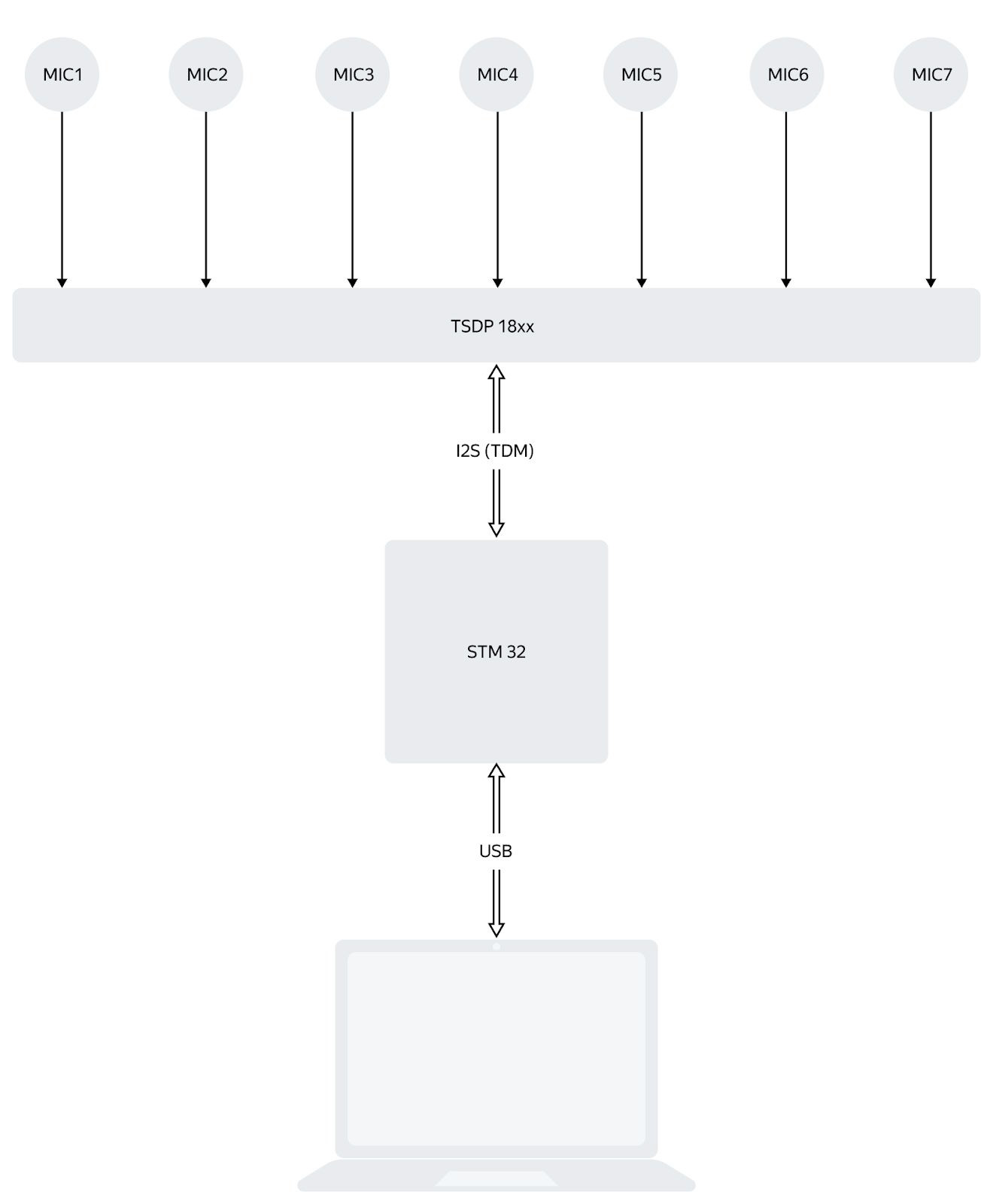
SAI — аппаратный блок STM32 для работы с I2S/TDM. Он весьма гибкий и позволяет реализовать множество вариантов протокола. Но из-за этого легко запутаться в требованиях к частотам.
Дерево тактовых частот заслуживает более детального рассмотрения. К микроконтроллеру подключен кварцевый резонатор на 12 МГц. Эту частоту перед подачей на блоки ФАПЧ (PLL) делим на 3 и получаем 4 МГц. Дальше это работает так:
1. Частоту ядра хорошо бы сделать повыше, чтобы всё успевать: например, максимальные для этого контроллера 80 МГц. Используем первый блок ФАПЧ: умножаем 4 МГц на 40 и делим на 2.
2. Для USB потребуется 48 МГц. Для этого используем второй блок ФАПЧ: умножаем 4 МГц на 24 и делим на 2.
3. О микрофонах. В наших тестовых платах используется частота дискретизации Fs = 16 кГц — стандарт, принятый в сфере распознавания речи. Из исходной частоты 4 МГц нужно получить что-то, что можно превратить в 16 кГц частоты фреймов шины TDM (она же LRCK, она же FCK, она же FrameSync). При этом:
[частота битовой синхронизации (BCLK, BitClk, Sync, SCK)] = Fs ∙ [количество каналов] ∙ [количество бит на канал]То есть: SCK = 16 кГц ∙ 8 ∙ 16 = 2048 кГц.
4. В даташите указано, что соотношение между Master Clock и частотой дискретизации Fs следующее: MasterClock = 16 кГц ∙ ДелительMCLK ∙ 256. Тут 256 — константа, а делитель можно задать в регистре. Проверим схему — для нужной функциональности есть коэффициенты деления частоты ФАПЧ на 7 или 17:

Обобщим задачу: нужно подобрать такой набор множителей и делителей ФАПЧ и SAI, чтобы получить частоту дискретизации 16 кГц и битовую частоту в 128 раз больше. Поскольку в наборе был обязательный делитель на 7 (или 17), то получить в точности нужный результат не вышло. Пришлось построить таблицу множителей и делителей, чтобы получить 24.571 МГц. Разделив эту частоту на 6 (ДелительMCLK), а затем на 256 (константа), наконец, получим число достаточно близкое к 16 кГц. Сейчас объясню, почему это так важно.
Работа с USB
Для работы с мультимедийными данными USB использует изохронный тип передачи: в этом случае на шине USB гарантируются определённая полоса пропускания и величина задержки. Доставка данных не гарантируется: если пакет пришёл со сбоем, то он будет считаться потерянным. Это связано с жёсткими ограничениями по времени: нет возможности переспрашивать.
При изохронном типе передачи при скорости USB FullSpeed (это 12 Мбит/с; именно на этой скорости умеет работать USB-блок STM32) компьютер приходит к девайсу за данными каждую миллисекунду: через этот промежуток времени он должен забрать накопившиеся данные. Напомню вводные: частота дискретизации 16 кГц, 8 каналов, каждый канал требует два байта, потому что звук шестнадцатибитный. Итого 16000 ∙ 2 ∙ 8 / 1000 = 256 байт за миллисекунду. Размер одного пакета для для изохронного типа передачи может достигать 1023 байт, так что в этом месте проблем нет.
Итак, размер пакета 256 байт. Казалось бы, все хорошо. Шестнадцать раз получили данные по TDM, положили в буфер, USB пришёл, отдаём ему пакет, повторяем… Но так происходит только в идеальном мире. Проблема в том, что с одной стороны у нас неидеальные 16 кГц (чуть поменьше), и в итоге данные приходят чуть реже, чем раз в миллисекунду. С другой — миллисекунда компьютера тоже плавает, так как он занят: когда смог, тогда и пришёл. То есть и частота опроса микрофона отличается от 16 кГц (но всегда одинаково), и миллисекунда USB тоже отличается по длине (при этом отличие, скорее всего, плавает: получается то чуть больше, то чуть меньше идеальной миллисекунды).
Почему это проблема? Можно потерять пакет. Наверное, излишне объяснять, что для верной отладки алгоритмов необходимы полные данные. Как теряется пакет: накопили 256 байт результатов, положили их в буфер, продолжили измерение. Пришёл компьютер, забрал первые 256, всё ещё продолжаем измерять. Компьютер снова пришёл, но измерение ещё не завершено – компьютер ушёл с пустым пакетом. Дальше заканчиваем заполнять буфер и начинаем заполнять ещё один, следующий, пока компьютер не пришёл снова. Компьютер забирает только последний пакет, в итоге один пакет оказывается потерян.
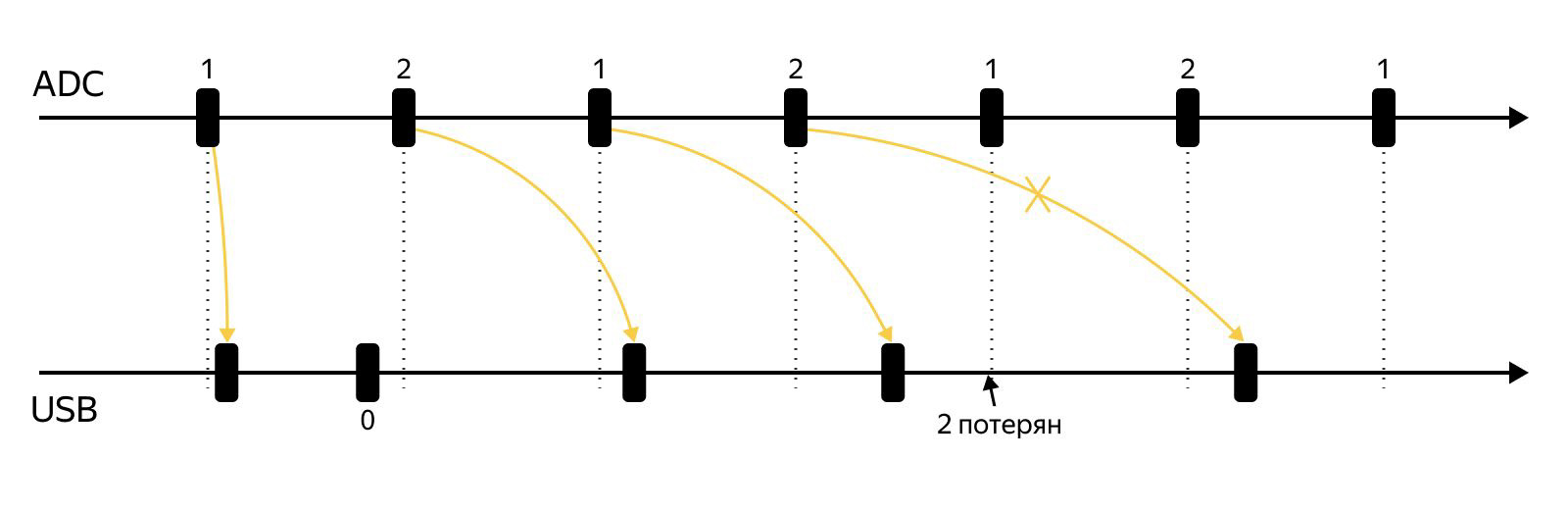
Проблема, на самом деле, известная. Для борьбы с ней существует три подхода:
- Синхронный. Все частоты на стороне девайса генерируются с опорой на миллисекундные сигналы USB. Минус такого подхода — период этих сигналов плавает. Существует понятие «джиттер» — дрожание фазы сигнала. В случае USB джиттер довольно серьёзный и вносит существенное мультипликативное искажение в сигнал. В данной задаче это не очень важно, потому что передаётся не музыка, а голос (снаружи есть шумы, используется 16 бит), но всё равно хочется сделать всё хорошо. Да и генерировать эти частоты не очень просто, ещё и неточность частоты дискретизации никуда в итоге не денется.
- Адаптивный. Девайс должен менять частоту дискретизации в соответствии с частотой опроса на стороне компьютера.
- Асинхронный — лучший для данной задачи. На девайсе есть генератор стабильной частоты. Частота дискретизации поддерживается строго одинаковой без привязки к USB. При этом нужно передавать на девайс данные так, чтобы не возникало существенных расхождений.
Всё это не раз обсуждалось на просторах интернета для случая воспроизведения с компьютера на динамик через устройство с ЦАП, где девайс в качестве обратной связи сообщает, сколько периодов дискретизации пришло с момента получения прошлого пакета.

Но наша задача обратная, отладка требует получения данных с микрофонов в компьютер, а вопрос записи сигнала с микрофонов на компьютер в лучшем случае только упоминается. Почему бы не сделать аналогично: ввести обратную связь от компьютера? Есть вариант проще.
Вот он
Используем частое добавление отсчетов и два буфера для хранения данных на отправку. 16 раз в миллисекунду добавляем к выбранному буферу очередной отсчет. В некоторый момент времени случается прерывание: USB забрал предыдущий пакет. Если буфер № 1 заполнен, происходит переключение на буфер № 2. Когда USB приходит за следующим пакетом, он оказывается уже подготовлен. Отправляем буфер № 2 и снова переключаемся на № 1.

USB приходит за данными в разные моменты времени, в пакет входит разное число отсчётов. Оно может оказаться и больше, и меньше шестнадцати, поэтому есть шанс превысить пакет размером 256 байт, лучше оставить пространство для манёвра. Пусть будет 384 = 256 + 128: это даст запас в полмиллисекунды, то есть простит плавание фазы USB сигнала на 50% — такого запаса должно быть более чем достаточно. Итого: отправляется то больше, то меньше 256 байт, но никогда не пустой пакет, что позволяет избежать потери данных. То есть проблема неравномерности была решена увеличением пакета, ценой увеличения части пропускной способности шины, выделенной для нашего устройства и уменьшения этой части для остальных устройств.
На этом доставка данных в компьютер подошла к концу. Разработчики могут отлаживаться, а вы — задавать вопросы в комментариях, если для полного понимания не хватило какого-то пакета данных.
Мои стримы и следующая серия
В последнее время я дважды стримил из своей домашней паяльной лаборатории. Сначала просто показал процесс пайки и рассказал, какие устройства я использую. Вторая серия была как раз посвящена разработке на STM32.
Стримы продолжаются. В эту пятницу в 19:00 мой коллега из команды разработки аппаратных решений Андрей Лаптев устроит онлайн-разбор Яндекс.Станции Мини — покажет внутренности и поделится историями производства. Для большего веселья Андрей прикрутит к колонке аккумулятор — не всё же от провода работать. В финале вы получите гайд, который позволит повторить этот опыт самостоятельно или придумать конструкцию поинтереснее.
Зарегистрируйтесь, чтобы смотреть стрим. Вам придёт письмо с файлом для календаря и напоминание в день эфира. Спасибо, что дочитали!
Похожие статьи
 Инсайдер слил характеристики OnePlus 16: батарея 9000 мАч, камера 200 Мп и чип Snapdragon 8 Elite Gen 6 Pro
Инсайдер слил характеристики OnePlus 16: батарея 9000 мАч, камера 200 Мп и чип Snapdragon 8 Elite Gen 6 Pro Началась магнитная буря
Началась магнитная буря Gulfstream G700 вернул статус самого быстрого бизнес-джета в мире, преодолев 8780 км за 8 часов 27 минут
Gulfstream G700 вернул статус самого быстрого бизнес-джета в мире, преодолев 8780 км за 8 часов 27 минут United Airlines отказалась от закупки первых двадцати самолетов Boeing 777-9
United Airlines отказалась от закупки первых двадцати самолетов Boeing 777-9 США могут запретить китайские сетевые инверторы для домашних накопителей энергии
США могут запретить китайские сетевые инверторы для домашних накопителей энергии Рекордная автономность Redmi: прототип Turbo 6 Max тестируют с батареей на 10 000 мАч
Рекордная автономность Redmi: прототип Turbo 6 Max тестируют с батареей на 10 000 мАч Электрический самолет Cosmic One от Cosmic Aerospace: четырехместная новинка с зарядкой от обычной розетки
Электрический самолет Cosmic One от Cosmic Aerospace: четырехместная новинка с зарядкой от обычной розетки Илон Маск уступает: xAI демонтирует 69 газовых турбин энергоцентра Colossus
Илон Маск уступает: xAI демонтирует 69 газовых турбин энергоцентра Colossus