
Богатая история человечества оставила после себя огромное количество исторических документов и артефактов. Однако практически все документы, содержащие рассказы и записанный опыт, имеющие существенное значение для нашего культурного наследия, понятны только специалистам по причине языковых и письменных изменений, происходящими со временем. Специально к старту нового потока курса по Машинному Обучению делимся статьёй Алекса Лэмба – аспиранта Монреальского университета и Монреальского института алгоритмов обучения (MILA), посвящённой использованию ML для распознавания древних рукописных текстов.
Относительно недавно были обнаружены десятки тысяч глиняных таблеток из Древнего Вавилона [1], но только несколько сотен учёных могут их перевести. Подавляющее большинство этих документов никогда не были прочитаны, даже если они были обнаружены в XIX веке. В качестве дополнительной иллюстрации задачи такого масштаба: в 1851 году в ходе экспедиции была собрана табличка из «Повести о Гильгамеше», но о её значении стало известно лишь в 1872 году. Эта табличка содержит добиблейское повествование о потопе, имеющее огромное культурное значение как предвестник повествования о Ноевом ковчеге. Это глобальная проблема, но одним из наиболее ярких примеров является случай Японии.
С 800 до 1900 года нашей эры в Японии использовалась система письма под названием кудзусидзи, которую исключили из учебной программы в 1900 году, когда было реформировано начальное школьное образование. В настоящее время подавляющее большинство говорящих на японском языке не умеют читать тексты, которым более 150 лет. Объём этих текстов, состоящий из более чем трёх миллионов книг, но читаемый лишь горсткой учёных, прошедших специальное обучение, поражает. Только в одной библиотеке оцифровано 20 миллионов страниц таких документов. Общее количество (включая письма и личные дневники, но не ограничиваясь ими) оценивается более чем в миллиард документов. Учитывая, что очень немногие люди могут понять эти тексты (в основном имеющие докторскую степень по классической японской литературе и японской истории), было бы очень дорого и затратно в смысле времени финансировать учёных для перевода этих документов на современный японский язык. Это мотивировало использовать машинное обучение, чтобы разобраться в таких текстах автоматически.
Это трудная задача. Кудзусидзи пишется шрифтом, который существенно отличается от современного японского, что для современного японца затрудняет даже элементарное распознавание. Однако, как только кудзусидзи был преобразован в современный шрифт, он читается большинством людей, свободно владеющих японским языком. Тем не менее некоторые трудности остаются из-за изменений в грамматике и в лексике.
Учитывая значение кудзусидзи для японской культуры, задачу использования компьютеров для содействия распознаванию кудзусидзи тщательно изучили в [2] посредством использования различных методов в глубоком обучении и компьютерного зрения. Однако эти модели не смогли достичь высоких показателей распознавания кудсусидзи. Это было вызвано недостаточным пониманием японской исторической литературы в сообществе оптического распознавания символов (OCR) и отсутствием стандартизированных наборов данных высокого качества.
Для решения этой проблемы Национальный институт японской литературы (NIJL) создал и выпустил набор данных кудзусидзи, курируемый Центром открытых данных в области гуманитарных наук (CODH). В настоящее время набор данных содержит более 4000 классов символов и миллион символьных изображений. До выхода этого набора данных кудзусидзи исследователи OCR пытались создавать наборы данных самостоятельно. Однако количество символов было очень ограниченным, что заставляло их модели работать плохо, когда они оценивались по всему спектру данных. NIJL-CODH решил эту проблему, предоставив большой и полный набор данных кудзусидзи для обучения и оценки модели.
Есть несколько причин, по которым распознавание кузусидзи является сложной задачей:
- Большое значение имеет учёт как локального, так и глобального контекста. В связи с тем, что некоторые символы написаны в зависимости от контекста, при классификации важно учитывать несколько символов, а не рассматривать каждый символ в отдельности.
- Общее количество символов в словаре очень велико. В частности, набор данных NIJL-CODH содержит более 4300 символов, на самом же деле их гораздо больше. Более того, набор данных следует распределению «длинный хвост», поэтому в наборе данных, содержащем 44 книги, много символов, которые появляются лишь несколько раз или даже один раз.
- Многие символы могут быть написаны несколькими способами на основе хентайганы. Хэнтайгана – это старый способ написания хираганы или японских фонетических иероглифов с такой спецификой, что сегодня многие иероглифы могут быть нанесены на один иероглиф. Для современных японских читателей принципы хэнтайганы представляются сложными для понимания.
- Тексты кудзусидзи часто пишутся вместе с иллюстрациями и замысловатыми фонами, которые трудно чисто отделить от текста. Они распространены потому, что самой популярной системой печати в современной Японии была печать на ксилографии, которая включает в себя резьбу по целому куску дерева вместе с иллюстрациями. Поэтому макет страницы может быть сложным и художественным, и не всегда его легко представить в виде последовательности.

Техника печати по дереву с использованием чернил и кисти

Текст кудзусидзи, вырезанный на ксилографическом брусе для печати
Чирасигаки был техникой написания, популярной в досовременном японском языке благодаря эстетической привлекательности текста. Этот стиль письма был распространён в личных письмах и стихах. Когда люди читают эти документы, они решают, с чего начать чтение, исходя из размера символов и темноты чернил. Это одна из причин, по которой обычные модели последовательности не имеют возможности хорошо работать со многими документами кудзусидзи.

Образец стиля письма Чирасигаки в документе кудзусидзи
KuroNet
KuroNet – это транскрипционная модель кудзусидзи, которую я разработал совместно с моими коллегами Тарином Клануватом и Асанобу Китамото из Центра открытых данных в гуманитарных науках ROIS-DS при Национальном институте информатики в Японии. Метод KuroNet мотивирован идеей обработки всей страницы текста целиком с целью захвата как большого диапазона, так и локальных зависимостей. KuroNet передаёт изображения, содержащие целую страницу текста, через остаточную архитектуру U-Net (FusionNet) для получения представления признака. Однако общее количество классов символов в нашем наборе данных относительно велико и насчитывает более 4300. Поэтому мы обнаружили, что прогнозирование точного символа в каждой позиции было слишком дорогостоящим с вычислительной точки зрения, и в надежде решить эту проблему ввели аппроксимацию, которая изначально оценивает, содержит ли некая пространственная позиция символ. Оттуда KuroNet рассчитывает только относительно дорогой классификатор символов в позициях, которые содержат символы, в соответствии с наблюдаемой истиной. Эта методика, являющаяся примером Teacher Forcing [обучения с принуждением], помогает значительно снизить использование памяти и сократить вычисления.
Мы также рассмотрели использование аугментации данных для повышения эффективности обобщения, что, как известно, особенно важно в глубоком обучении, когда количество помеченных данных ограничено. Мы исследовали вариант регулятора Mixup.
Работа [3], в которой интерполировали небольшое количество в направлении случайных различных примеров, сохраняя при этом исходную метку. Многие книги написаны на относительно тонкой бумаге, поэтому содержание соседней страницы часто слабо просматривается через бумагу. Изображения, создаваемые Mixup, выглядят несколько похожими на изображения, где слабо просматривается содержимое соседней страницы. Таким образом, Mixup может иметь дополнительное преимущество, помогая побудить модель игнорировать соседнюю страницу.
Для получения дополнительной информации о KuroNet, пожалуйста, ознакомьтесь с нашей работой KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning, которая была принята на Международной конференции по анализу и распознаванию документов (ICDAR) в 2019 году. [4].

Примеры транскрипции KuroNet на страницах со значением F1 выше 0,9
KuroNet может транскрибировать целую страницу кудзусидзи со средним временем 1,2 секунды на страницу, включая конвейер постобработки, который не оптимизировался тщательно. Несмотря на то что производительность всё ещё сильно различается на разных книгах, мы обнаружили, что ксилографические печатные книги периода Эдо (XVII–XIX веков) – это те книги, на которых KuroNet показывает хорошие результаты. Мы обнаружили, что модель борется с необычными размерами и редкими символами. Кроме того, мы оценили модель на контрольном наборе страниц из различных книг и обнаружили, что худшими книгами оказались словари, содержащие много необычных символов, и кулинарная книга с множеством иллюстраций и необычных макетов.
Конкурс по распознаванию кудзусидзи на Kaggle

В то время как KuroNet достигла передовых результатов на момент своей разработки и была опубликована на конференции высшего уровня по анализу и распознаванию документов, мы хотели открыть это исследование для более широкого сообщества. Мы сделали это отчасти для того, чтобы стимулировать дальнейшие исследования по кудзусидзи и найти условия, при которых KuroNet недостаточно.
В конечном счёте после трёх месяцев соревнований, в которых приняли участие 293 команды, 338 участников и 2652 заявки, победитель получил оценку F1 в 0,950 баллов. Когда мы оценивали KuroNet в тех же обстоятельствах, то обнаружили, что она получила оценку F1 0,902, с ней нейросеть оказалась бы на двенадцатом месте, что, хотя и приемлемо, намного ниже лучших решений.
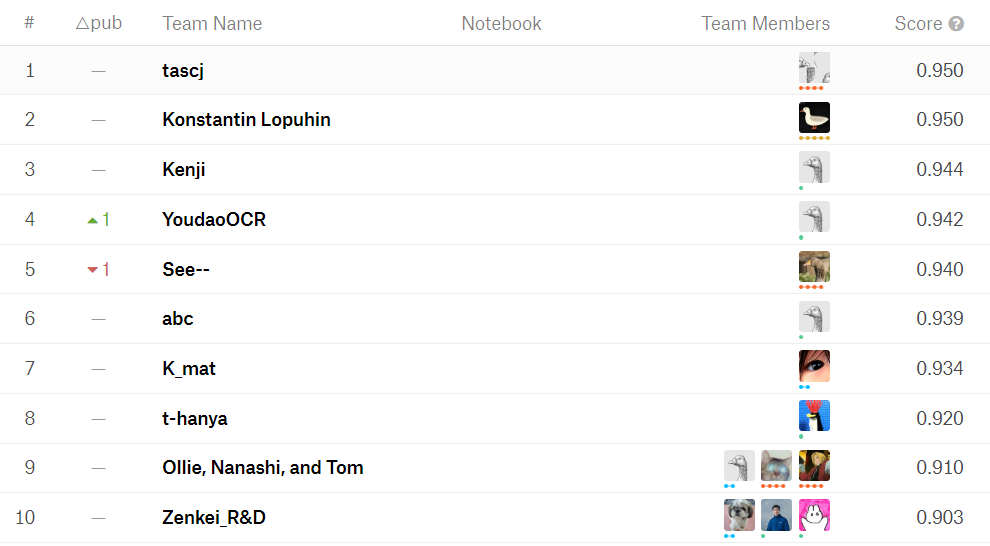
Финал конкурса «Распознавание кудзусидзи на Kaggle» (топ-10)
Есть несколько важных уроков, которые мы извлекли из этого конкурса:
- Некоторые существующие алгоритмы обнаружения объектов достаточно хорошо работают над этой задачей, даже когда применяются как есть, «из коробки». Например, Faster R-CNN и Cascade R-CNN дали отличные результаты без модификаций или каких-либо специфических для кудзусидзи приёмов. Учитывая то, насколько распознавание со страниц с кудзусидзи отличаются от обычных задач по обнаружению объектов, было довольно удивительно, что эти нейросети справляются так хорошо.
- В то же время другие методы без модификации работают плохо. Например, You Only Look Once (YOLO) выполнил задачу довольно плохо, несмотря на значительные усилия. Другие методики, использующие CenterNet, работали хорошо, но требовали больших усилий и специфической для домена настройки, чтобы заставить их работать.
- Несколько ведущих подходов имели модели, которые выполняли обнаружение и классификацию совместно. Которые не использовали искусные методы включения окружающих символов в своём классификационном конвейере.
- Лишь немногие из лучших решений использовали языковые модели или пытались трактовать символы как последовательность.
Будущие исследования
Работа, проделанная CODH, уже привела к значительному прогрессу в транскрибировании документов кудзусидзи, однако общая проблема открытия знаний об исторических документах далека от решения.
Даже в области расшифровки кудзусидзи всё ещё существуют значительные открытые проблемы. Одна из проблем заключается в том, что размеченные данные обучения, как правило, поступают с целых страниц текста, с акцентом на документы из определённого периода (в основном позднего периода Эдо, XVII–XIX веков). Однако есть много других типов текста кудзусидзи, которые человек может захотеть расшифровать. Некоторые документы написаны от руки, а другие напечатаны (обычно с использованием ксилографии). Некоторые типы страниц имеют нетипичное содержание, которое редко встречается, например титульные страницы книг. В Японии я встретил человека, который путешествовал по горам и нашёл каменный указатель пути, написанный на кудзусидзи, и хотел, чтобы его расшифровали. Обобщение этих очень разных типов данных, особенно при изменении носителя записи, может быть довольно трудным, хотя привлекает всё большее внимание как область исследований в машинном обучении (методика минимизации инвариантного риска).
Работа [5] фокусируется именно на этой проблеме.
Ещё одна интересная открытая проблема возникает из-за того, что все предложенные методы только конвертируют документы кудзусидзи в современный японский шрифт. Это делает отдельные символы узнаваемыми, но весь текст по-прежнему довольно трудно читать. Из разговоров с носителями японского языка у меня сложилось впечатление, что обычный японец сможет читать, но это умеренно труднее, чем для современных англоговорящих людей читать Шекспира. Таким образом, захватывающей и самой открытой проблемой машинного обучения будет преобразование старого языка в лексику и грамматику современного японского. Эту проблему можно решить, так как часто устаревшее слово можно заменить более современным, но также эта проблема очень глубокая, поскольку правильно перевести поэзию и красивую прозу с её многочисленными нюансами может быть почти невозможно. Кроме того, отсутствие (или небольшой объем) чётко согласованных парных данных из классического и современного японского может мотивировать воспользоваться недавними исследованиями неконтролируемого машинного перевода с низким уровнем ресурсов.
Я считаю, что это одно из самых эффективных приложений для машинного обучения сегодня, и для достижения прогресса потребуется сотрудничество как между теми, кто имеет опыт работы с историческими документами в конкретной предметной области, так и исследователями прикладного машинного обучения, а также исследователями базовых алгоритмов ML. Это требует междисциплинарных усилий. Историки могут помочь определить наиболее важные подзадачи и интуитивно судить о том, действительно ли полезны метрики. Исследователи прикладного машинного обучения могут создавать модели для оптимизации этих показателей и выявления недостатков современных алгоритмов. Исследователи базового машинного обучения могут помочь улучшить алгоритмы. Например, наша работа по японскому языку требует более совершенных алгоритмов для Few-shot Learning, а также лучшего обобщения для меняющейся среды, и обе эти проблемы всё более широко изучаются в сообществе исследователей ML.
В то же время усилия должны быть международными. Неприступные документы представляют собой проблему для исторических языков во всём мире, и только привлекая исследователей со всего мира, мы можем надеяться добиться прогресса. Также важно взаимодействовать с общинами коренных народов, которые имеют большое историческое наследие, но в определённых областях исследований могут быть представлены недостаточно.
Значение историко-литературного образования сильно недооценивается во многих местах по всему миру. В современном мире всё большего обмана и фейковых новостей как никогда важно более глубокое знание истории. Если сделать исторический документ более доступным и понятным, это может помочь повысить осведомленность о важности такого рода образования, позволяя учащимся взаимодействовать с гораздо более обширным объемом содержимого в более органичной и доступной форме. Что касается Японии, я надеюсь, что наша работа позволит студентам и широкой публике читать исторические рассказы так, как они были задуманы, – наряду с богатыми иллюстрациями и доступным стилем письма. Я также надеюсь, что это позволит им выбирать в гораздо большим разнообразии, включая боевики, комедии и приключения, что сделает исследования приятнее и доступнее.
- Epic of Gilgamesh Lecture (Andrew George).
- ICDAR 2019 List of Accepted Papers.
- Zhang, Hongyi, et al. «mixup: Beyond empirical risk minimization.» ICLR 2018.
- Clanuwat, Tarin, Alex Lamb, and Asanobu Kitamoto. «KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning.» ICDAR 2019.
- Arjovsky, Martin, et al. «Invariant risk minimization.» arXiv preprint arXiv:1907.02893 (2019).
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Курс «Machine Learning и Deep Learning»
- Профессия Data Scientist
- Профессия Data Analyst
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по Data Engineering
- Курс «Python для веб-разработки»
- Курс «Алгоритмы и структуры данных»
- Курс по аналитике данных
- Курс по DevOps



