Затем я нашёл это видео. И… Это истинный голос, который использовался в станции Gongs and Chimes? Меня удивило, насколько маленькой, аккуратной и сложной казалась эта машина. В ней определённо был микроконтроллер, она имела ЖК-дисплей, а в целом выглядела как довольно элегантное устройство.

Sprach-Morse-Generator (фото Mfs-sammler)
Однако самым важным было то, что я наконец-то узнал, что ищу. Запрос «Sprach-Morse-Generator» («голосовой-генератор-Морзе») быстро привёл меня на страницу об этой машине в музее криптографии, на которой упоминается и её официальное название: «Gerät 32620» (устройство 32620). На странице также есть замечательная информация об истории устройства и записанном в нём голосе.
Но больше всего меня восхитило то, что там были ссылки на техническую документацию по голосовому генератору и сопровождающему его устройству, Gerät 32621, которое можно использовать для оцифровки голосовых аудиодорожек и для их записи на EPROM-картриджи, которые используются в Gerät 32620.
Руководство по 32620
Я не хочу подробно описывать всё, что написано в этих руководствах; если вы читаете на немецком, то рекомендую прочитать их самостоятельно; однако хочу рассказать о том, мне показалось примечательным.
В качестве ввода можно использовать бумажную перфоленту, клавиатуру или последовательный интерфейс (RS-232). С последним не всё ясно, он упоминается в начале, однако в дальнейших частях документа представлен как возможное будущее дополнение. Как бы то ни было, сообщения передаются в ОЗУ, откуда их затем можно транслировать. ОЗУ может хранить до 3791 символа.
Языковые образцы загружаются с заменяемого картриджа, который может содержать до 96 килобайт, где они хранятся в несжатом формате PCM. В документации с гордостью говорится, что картриджи можно заменять всего за 10 секунд.

Количество слов в минуту и высоту голоса можно изменять, и это объясняет, почему некоторые записи номерных станций с звуком того же голоса звучат немного иначе.
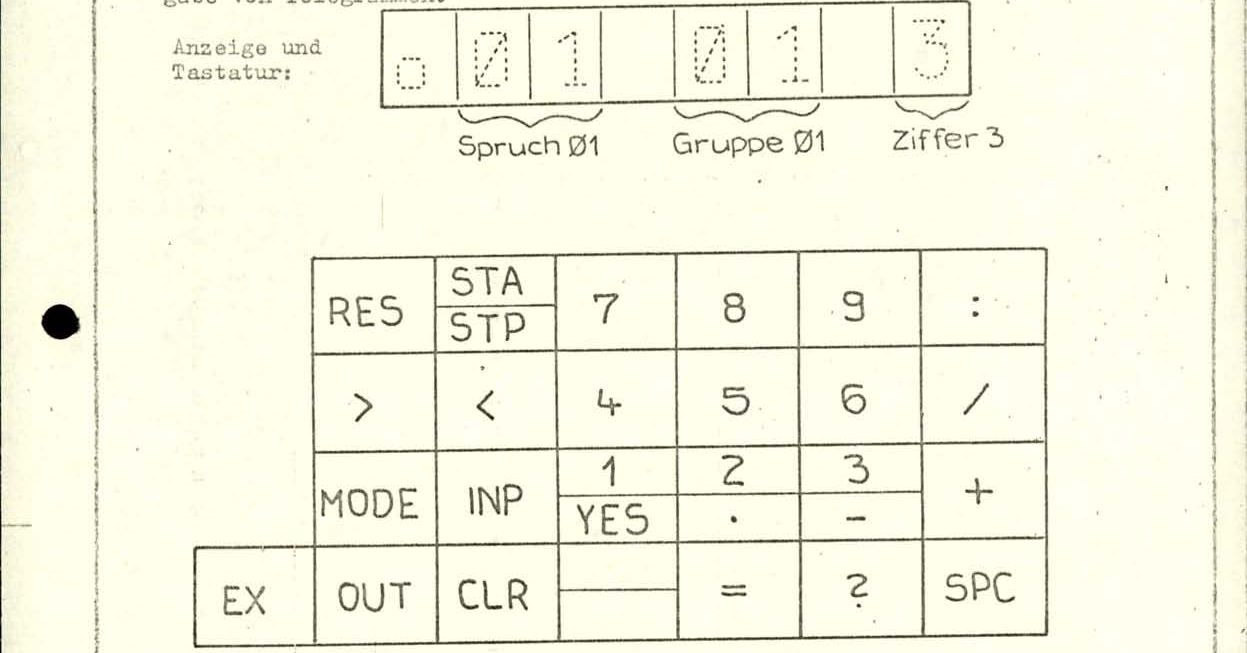
Технический чертёж дисплея и клавиатуры. Дисплей может отображать номера сообщений, группы и цифры, воспроизводимые в текущий момент.
Что мне показалось довольно удивительным: на клавиатуре и в выводе устройства в основном используются английские слова. Немного неожиданно для устройства, разработанного в восточной Германии для использования в Советском Союзе; я бы скорее ожидал здесь русский язык.
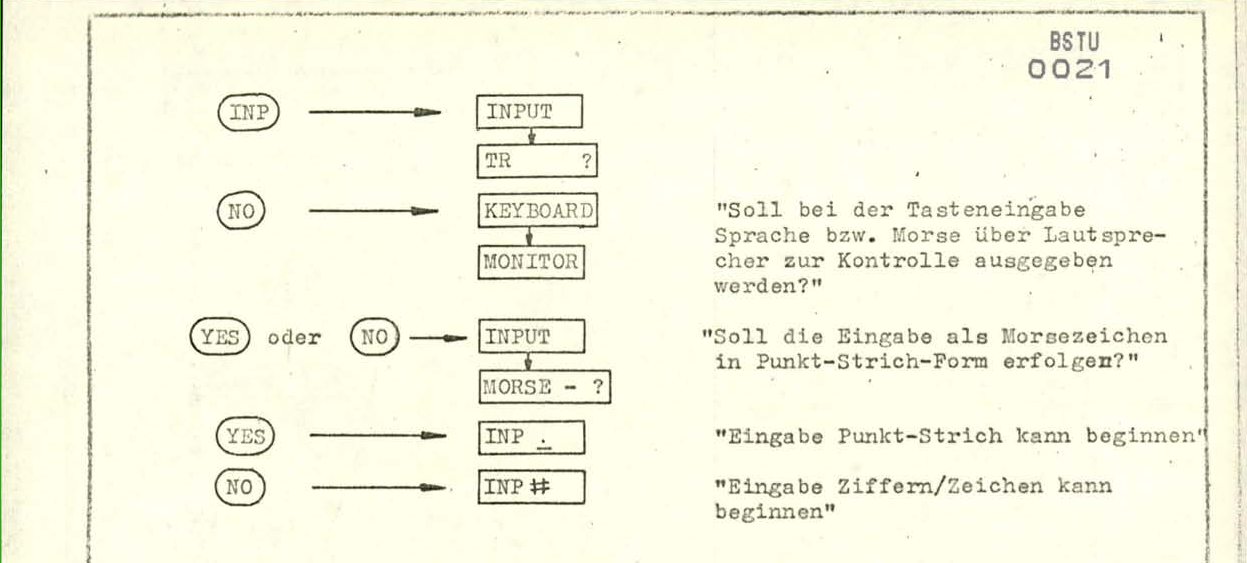
В документации есть очаровательные диаграммы, демонстрирующие примеры взаимодействия с устройством.
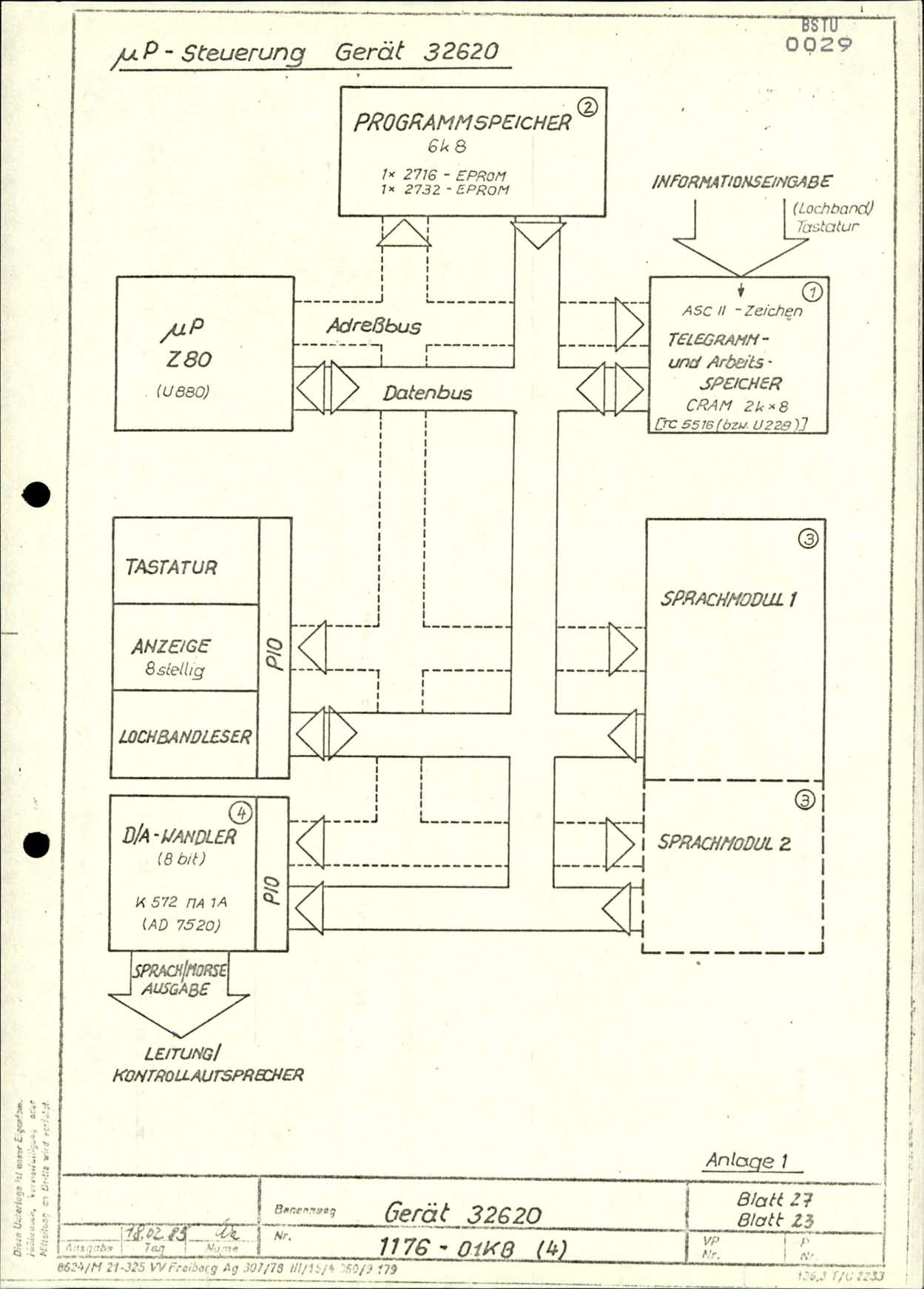
Схема шин всего устройства. Любопытно, что на ней показан второй языковой модуль, однако готовое устройство одновременно поддерживает только один языковой модуль.
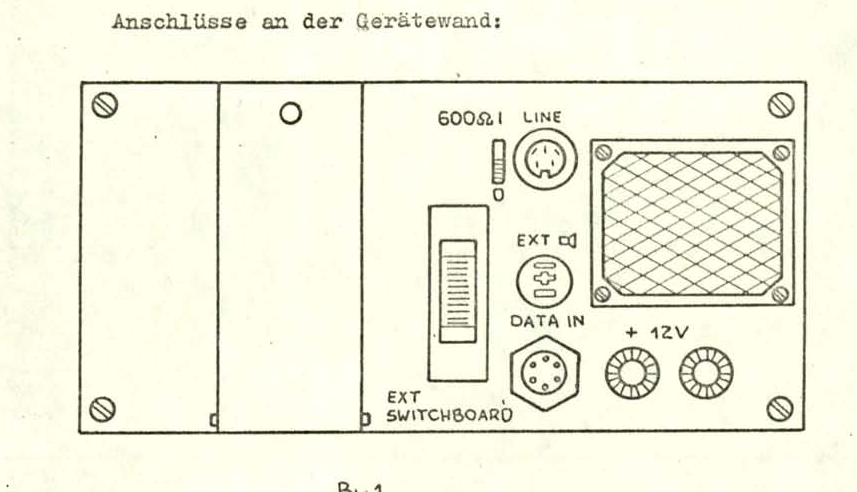
На обратной части динамика есть выводы на передатчик, несколько выводов состояния и вводов дистанционного управления. Вероятно, их использовали, чтобы мелодии и речь не накладывались друг на друга.
В конце документа есть довольно подробные схематические чертежи и списки компонентов.
Это сопровождающее устройство, используемое для оцифровки голосов и их записи на картриджи 32620. Потрясающе, насколько сложным является это устройство: оно может записывать слова по отдельности или все за раз, автоматически распознаёт начало и конец слов, способно дублировать картриджи и даже имеет УФ-камеру для очистки EEPROM на картридже для его повторного использования.
Что любопытно: фотографий этого устройства не существует. Непонятно, сколько всего их было произведено, возможно, всего одно или два. Мы знаем о нём только по этому документу.
По своей архитектуре оно довольно близко к 32620, имеет очень похожую клавиатуру и, вероятно, тот же дисплей.
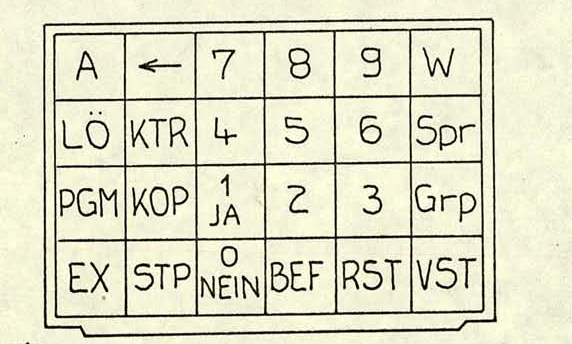
Одно интересное отличие: на клавиатуру нанесены обозначения на немецком. Кроме того, весь текст на дисплее отображается на немецком.
В документации упоминается возможность записи до 20 слов. То же самое говорится и в документации по 32620, однако всегда использовалось только 13 слов: цифры 0-9, «Achtung» («внимание»), «Trennung» («разделение») и «Ende» («конец»).
Устройство имеет управление для регулировки нулевого уровня записей и усиления. На ЖК-дисплее показывается, улавливает ли устройства аудиосигнал и происходит ли его отсечка. Усиление отдельных слов также можно выполнять позже со значением от 0 до 7. Похоже, что эта настройка на самом деле не изменяет записанных сэмплов, а просто управляет уровнем усиления в цифро-аналоговом преобразователе. Данная функция предназначена для того, чтобы сделать все цифры одинаковыми по громкости.
Мне кажется это немного удивительным, ведь всё это можно реализовать при помощи другого оборудования, особенно потому, что известно только два разных голоса для таких машин: немецкий и испанский.
Для проверки записи можно воспроизводить все записанные цифры или только их отдельные сочетания.
При программировании данных в EPROM устройство передаёт адрес начала и усиление каждого слова, а также сэмплы из ОЗУ в ПЗУ, а затем проверяет, совпадают ли считываемые после программирования значения с ожидаемыми.
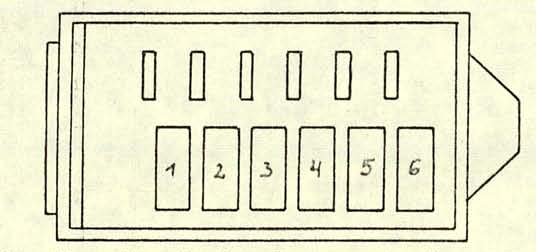
Нумерация EPROM на картридже. Если считываемые значения не совпадают, то оператор может заменить ошибочный чип EPROM.
Существует отдельный режим для стирания картриджей, при котором время обработки их ультрафиолетом можно ввести с клавиатуры. Если картридж ПЗУ двухсторонний, то его нужно перевернуть, чтобы стереть информацию с чипов на другой стороне.
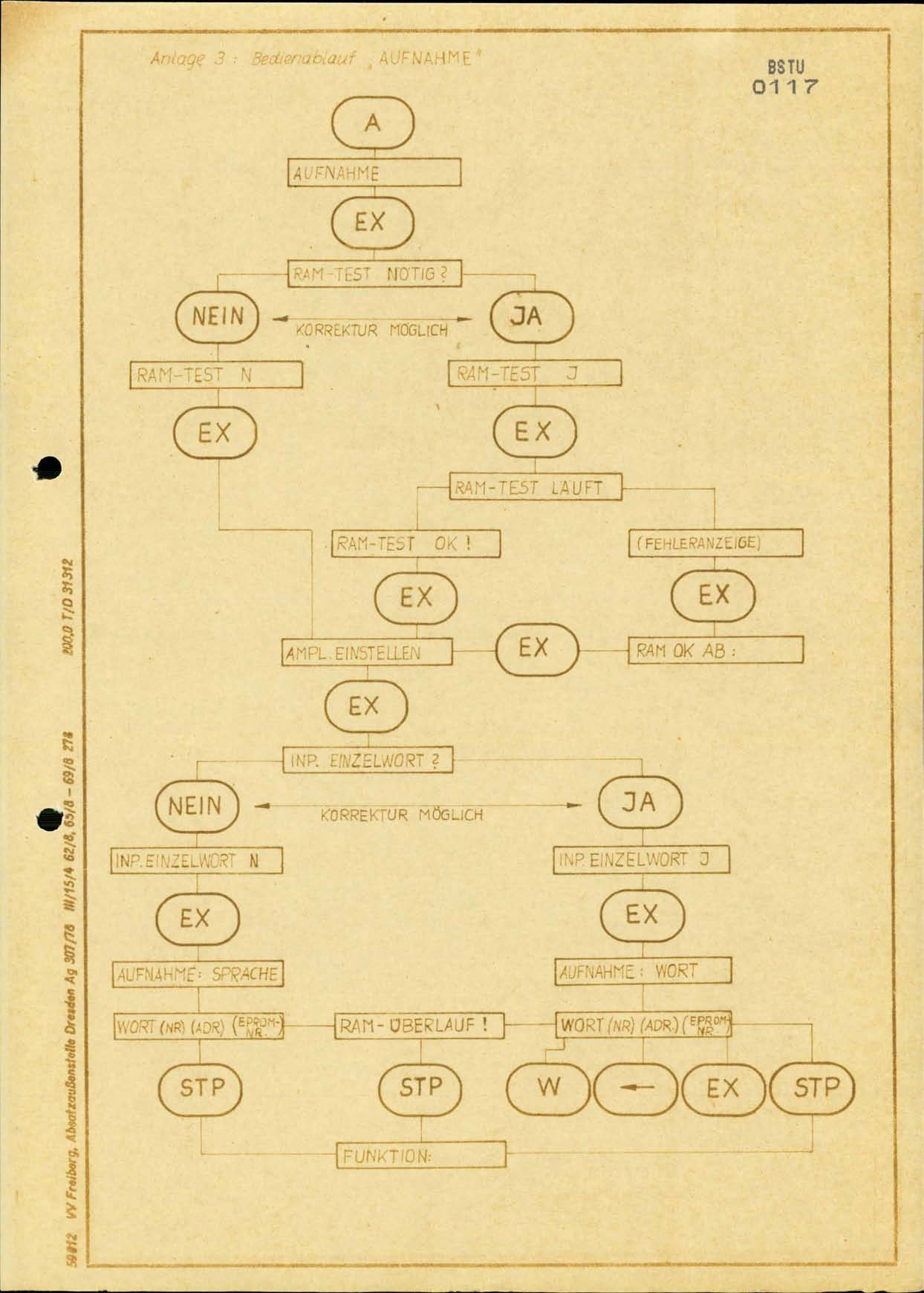
По всем режимам 32621 в документации есть диаграммы интерфейса.
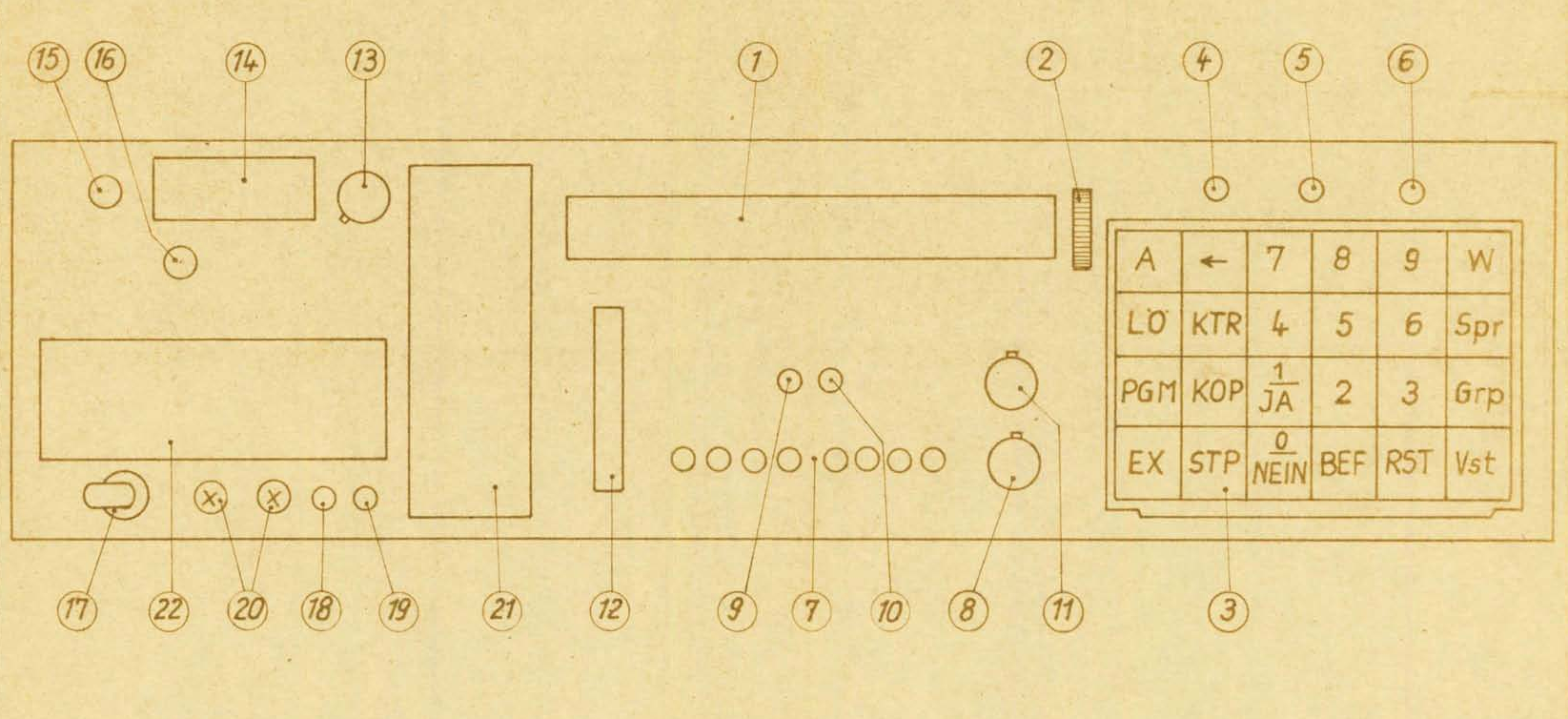
На передней панели также есть несколько других индикаторов, например, разных напряжений в устройстве.
В этом руководстве также содержится схема устройства.
Чипы EPROM
В музее криптографии также есть дампы EPROM немецкого и испанского картриджей.
Прочитав руководства, декодировать их не так сложно: данные хранятся в формате PCM, а в руководстве по 32621 написано, что время между сэмплами составляет 125 мкс, что даёт частоту дискретизации 8000 Гц. Загрузив ПЗУ в Audacity через File>Import>Raw Data, можно наконец-то их прослушать!
[Дополнение: если вам интересно, то вот дампы в виде WAV: немецкий, испанский].Заголовок
В самом начале первого EPROM есть 64 байта информации заголовка, содержащей адрес начала каждого слова и его уровень усиления. При 20 словах остаётся чуть больше 3 байт на слово, однако разработчики, похоже, оставили всего по 3 байта.
Декодирование остальной части заголовка заняло намного больше времени, чем я ожидал. 3 бита значения усиления я довольно быстро нашёл в последнем байте каждого слова. Остальное каким-то образом должно было быть адресом начала или каким-то смещением, и, возможно, длиной. Для доступа к значениям в каждом из чипов по 8 КБ под адрес требуется 13 бит. Для выбора одного из EPROM, которых может быть до двенадцати, требуется ещё 4 бита. В сумме это даёт 17 бит, на один бит больше, чем два байта.
Чтобы обойти эту проблему, есть два очевидных решения: засунуть один дополнительный бит в байт, в котором хранится уровень усиления или отбросить самый младший бит адреса начала, чтобы в качестве начального мог использоваться только каждый второй сэмпл.
Разобраться во всём этом было сложно по двум причинам: z80 — это машина little endian, то есть для 16-битных значений младший байт хранится перед старшим, но это не значит, что разработчики обязаны хранить значения в таком порядке. Кроме того, двоичное значение выбора чипа для первого EPROM равно не 0, а 2. Понял я это, только взглянув на схему картриджа EPROM (стр. 38 руководства по 32620). Также в схеме есть очень милый демультиплексер, собранный из дискретных затворов AND и NAND для преобразования адресных строк чипа в строки выбора чипа!
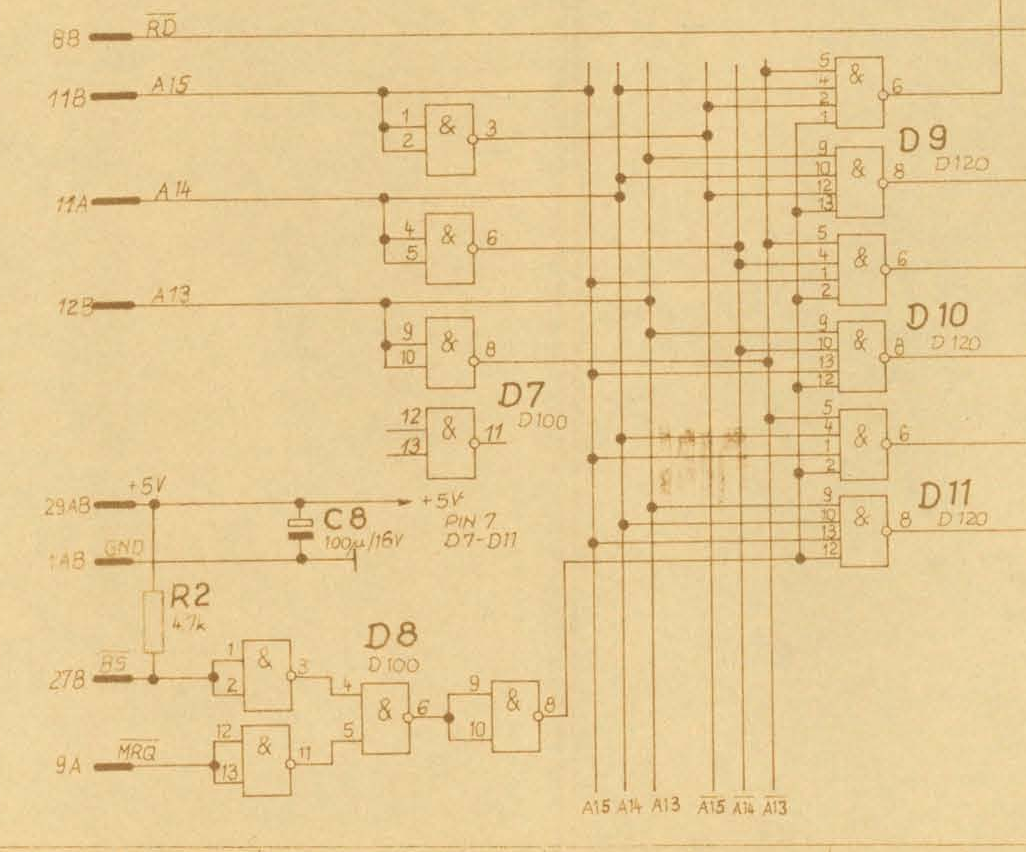
Разве это не великолепно! Обратите внимание, что схема только намекает на присутствие четвёртой адресной строки для выбора чипа при помощи неподключенного NAND.
Могут только предположить, что так получилось потому, что значения 0 и 1 адреса выбора чипа уже использовались для выбора каких-то других компонентов. Но, в конечном итоге, я, кажется, разобрался, как это работает:
Для каждого слова второй байт содержит 3 самых младших бита для выбора чипа и 5 битов адреса. Первый байт содержит оставшиеся 8 битов адреса. Конец каждого слова является адресом начала следующего слова. Именно поэтому после последнего слова есть два дополнительных байта. Такая система работала бы максимум с двадцатью словами, потому что осталось бы 4 запасных байта для хранения адреса конца последнего слова. Третий байт содержит оставшийся бит выбора чипа, несколько загадочных битов и 3 бита уровня усиления.
Оставшийся бит выбора чипа по-прежнему для меня непонятен: в немецких записях он не используется, потому что они умещаются всего на 6 EPROM. В испанских пришлось использовать его для последних двух слов, но что-то странное творится со значениями в слове перед последними двумя.
Стоит также упомянуть ещё один аспект: во всех немецких словах используется стандартный уровень усиления 3, а в некоторых испанских используются более высокие и низкие значения. Для полной аутентичности нужно учитывать это при воспроизведении сэмплов.
Меня заинтересовала ещё одна вещь: испанский голос использует одно слово для «Trennung» и «Ende» — «final», и они точно звучат одинаково. То есть это цифровая копия? Или дважды оцифрованная часть магнитной ленты? Глядя на значения в сэмплах, можно легко понять, что верен второй вариант: значения в сэмплах не совпадают.
Вывод
Ого, я забрался намного глубже, чем планировал. Но позвольте сказать, что попытки реверс-инжиниринга двоичного формата без наличия работающей машины, которая способна его считывать — это очень интересно, хоть и довольно сложно.
Эти устройства — загадочная и интересная часть мировой истории и истории компьютеров, но, по моему мнению, именно окружающая их по-прежнему тайна делает их особенно удивительными: непонятно, сколько их существовало, а устройство 32621, похоже, совершенно пропало для истории. Также неясно, существовали ли другие голоса; судя по документации, новые голоса создавать было довольно просто, но я не нашёл никакой информации, дающей намёки на это.
Благодарю за то, что прочитали статью целиком, надеюсь, она была интересной. С радостью услышал бы ваши мысли, поэтому напишите мне твит или на электронную почту.
Приложение: дамп заголовков с аннотацией
german
00 40 43 b7 4a 43 c3 58 43 d9 68 43 fb 75 43 26
| | | | |
84 43 b6 95 43 35 a4 43 4d b1 43 33 c1 43 42 d0
| | | | |
43 84 e3 43 05 f4 43 eb fe ff ff ff ff ff ff ff
| | |
ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff
CHIP SELECT sequence: 1, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6
german, binary:
00000000 01000000 01000011 10110111 01001010 01000011 11000011 01011000
^^^^^^^^ ^^^^^^^^ ^^^^^^^^| |
LIIIIIII LIILIIII I????LII
I I I I +-- Amplification (Default: 3)
I I I +--------- Remaining chip select line? (but not quite?)
I I +----------- Address (HI Byte)
I +---------------- Chip Select lines A15, A14, A13
+-------------------- Address (LO Byte)
01000011 11011001 01101000 01000011 11111011 01110101 01000011 00100110
| | |
10000100 01000011 10110110 10010101 01000011 00110101 10100100 01000011
| | |
01001101 10110001 01000011 00110011 11000001 01000011 01000010 11010000
| |
01000011 10000100 11100011 01000011 00000101 11110100 01000011 11101011
| | |
11111110 11111111 11111111 11111111 11111111 11111111 11111111 11111111
spanish
40 40 42 19 50 43 18 5c 45 ca 70 43 26 81 43 49
| | | | |
95 43 7a a9 43 ff bd 43 d2 d0 43 f7 e3 43 70 f9
| | | | |
c3 13 57 83 6d 6b 83 ba 7f ff ff ff ff ff ff ff
| | | | | |
ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff
| | | |
CS Sequence: 1, 1, 1, 2, 3, 3, 4, 4, 5, 6, 6, 7, 8
_ _
spanish, binary
01000000 01000000 01000010 00011001 01010000 01000011 00011000 01011010
"0" |"1" |"2"
01000101 11001010 01110000 01000011 00100110 10000001 01000011 01001001
|"3" |"4" |"5"
10010101 01000011 01111010 10101001 01000011 11111111 10111101 01000011
|"6" |"7" |
11010010 11010000 01000011 11110111 11100011 01000011 01110000 11111001
"8" |"9" | "Atencion"
11000011 00010011 01010111 10000011 01101101 01101011 10000011 10111010
|"Final" |"Final" |
01111111 11111111

