Биометрическая идентификация человека – это одна из самых старых идей для распознавания людей, которую вообще попытались технически осуществить. Пароли можно украсть, подсмотреть, забыть, ключи – подделать. А вот уникальные характеристики самого человека подделать и потерять намного труднее. Это могут быть отпечатки пальцев, голос, рисунок сосудов сетчатки глаза, походка и прочее.

Конечно же, системы биометрии пытаются обмануть! Вот об этом мы сегодня и поговорим. Как злоумышленники пытаются обойти системы распознавания лица, выдав себя за другого человека и каким образом это можно обнаружить.
Согласно представлениям режиссеров Голливуда и писателей-фантастов, обмануть биометрическую идентификацию довольно просто. Нужно всего лишь предъявить системе «требуемые части» настоящего пользователя, как по отдельности, так и взяв его в заложники целиком. Или же можно “надеть личину” другого человека на себя, например, с помощью физической пересадки маски или вообще, предъявления фальшивых генетических признаков
В реальной жизни злоумышленники тоже пытаются представиться кем-то другим. Например, ограбить банк, надев маску чернокожего мужчины, как на картинке ниже.

Распознавание по лицу выглядит очень перспективным направлением для использования в мобильном секторе. Если к использованию отпечатков пальцев все уже давно привыкли, а технологии работы с голосом постепенно и довольно предсказуемо развиваются, то с идентификацией по лицу ситуация сложилась довольно необычная и достойная небольшого экскурса в историю вопроса.
Как все начиналось или из фантастики в реальность
Сегодняшние системы распознавания демонстрируют огромную точность. С появлением больших наборов данных и сложных архитектур стало возможным добиться точности распознавания лица вплоть до 0,000001 (одна ошибка на миллион!) и они уже сейчас пригодны для переноса на мобильные платформы. Узким местом стала их уязвимость.
Для того, чтобы выдать себя за другого человека в нашей технической реальности, а не в фильме, чаще всего используют маски. Компьютерную систему тоже пытаются одурачить, представив вместо своего лица чье-то еще. Маски бывают совершенно разного качества, от распечатанного на принтере фото другого человека, которое держат перед лицом, до очень сложных трехмерных масок с подогревом. Маски могут как предъявляться отдельно в виде листа или экрана, так и надеваться на голову.
Большое внимание к теме привлекла успешная попытка обмануть систему Face ID на iPhone X с помощью довольно сложной маски из каменного порошка со специальными вставками вокруг глаз, имитирующими тепло живого лица с помощью инфракрасного излучения.
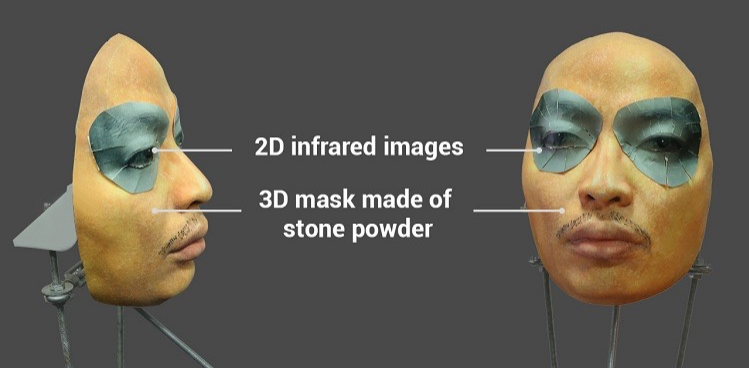
Утверждается, что помощью такой маски удалось обмануть Face ID на iPhone X. Видео и немного текста можно найти здесь
Наличие таких уязвимостей очень опасно для банковских или государственных систем аутентификации пользователя по лицу, где проникновение злоумышленника влечет за собой значительные потери.
Терминология
Область исследования face anti-spoofing довольно новая и пока еще не может похвастаться даже сложившейся терминологией.
Условимся называть попытку обмана системы идентификации путем предъявления ей поддельного биометрического параметра (в данном случае — лица spoofing attack.
Соответственно, комплекс защитных мер, чтобы противостоять такому обману, будем называть anti-spoofing. Он может быть реализован в виде самых разных технологий и алгоритмов, встраиваемых в конвейер системы идентификации.
В ISO предлагается несколько расширенный набор терминологии, с такими терминами, как presentation attack — попытки заставить систему неверно идентифицировать пользователя или дать ему возможность избежать идентификации, с помощью демонстрации картинки, записанного видео и так далее. Normal (Bona Fide) – соответствует обычному алгоритму работы системы, то есть всему, что НЕ является атакой. Presentation attack instrument означает средство совершения атаки, например, искусственно изготовленную часть тела. И, наконец, Presentation attack detection — автоматизированные средства обнаружения таких атак. Впрочем, сами стандарты все еще находятся в разработке, поэтому говорить о каких-либо устоявшихся понятиях нельзя. Терминология на русском языке отсутствует почти полностью.
Для определения качества работы системы часто пользуются метрикой HTER (Half-Total Error Rate – половина полной ошибки), которую вычисляют в виде суммы коэффициентов ошибочно разрешенных идентификаций (FAR – False Acceptance Rate) и ошибочно запрещенных идентификаций (FRR – False Rejection Rate), деленной пополам.
HTER=(FAR+FRR)/2
Стоит сказать, что в системах биометрии обычно самое большое внимание уделяют FAR, с целью сделать всё возможное, чтобы не допустить злоумышленника в систему. И добиваются в этом неплохих успехов (помните одну миллионную из начала статьи?) Обратной стороной оказывается неизбежное возрастание FRR – количества обычных пользователей, ошибочно классифицированных как злоумышленников. Если для государственных, оборонных и прочих подобных систем этим можно пожертвовать, то мобильные технологии, работающие с их огромными масштабами, разнообразием абонентских устройств и, вообще, user-perspective ориентированные, очень чувствительны к любым факторам, которые могут заставить пользователей отказаться от услуг. Если вы хотите уменьшить количество разбитых об стену телефонов после десятого подряд отказа в идентификации, стоит обратить внимание на FRR!
Виды атак. Обманываем систему

Давайте, наконец, узнаем, как именно злоумышленники обманывают системы распознавания, а также как этому можно противопоставить.
Самым популярным средством обмана являются маски. Нет ничего более очевидного, чем надеть маску другого человека и представить лицо системе идентификации (часто именуется Mask attack).
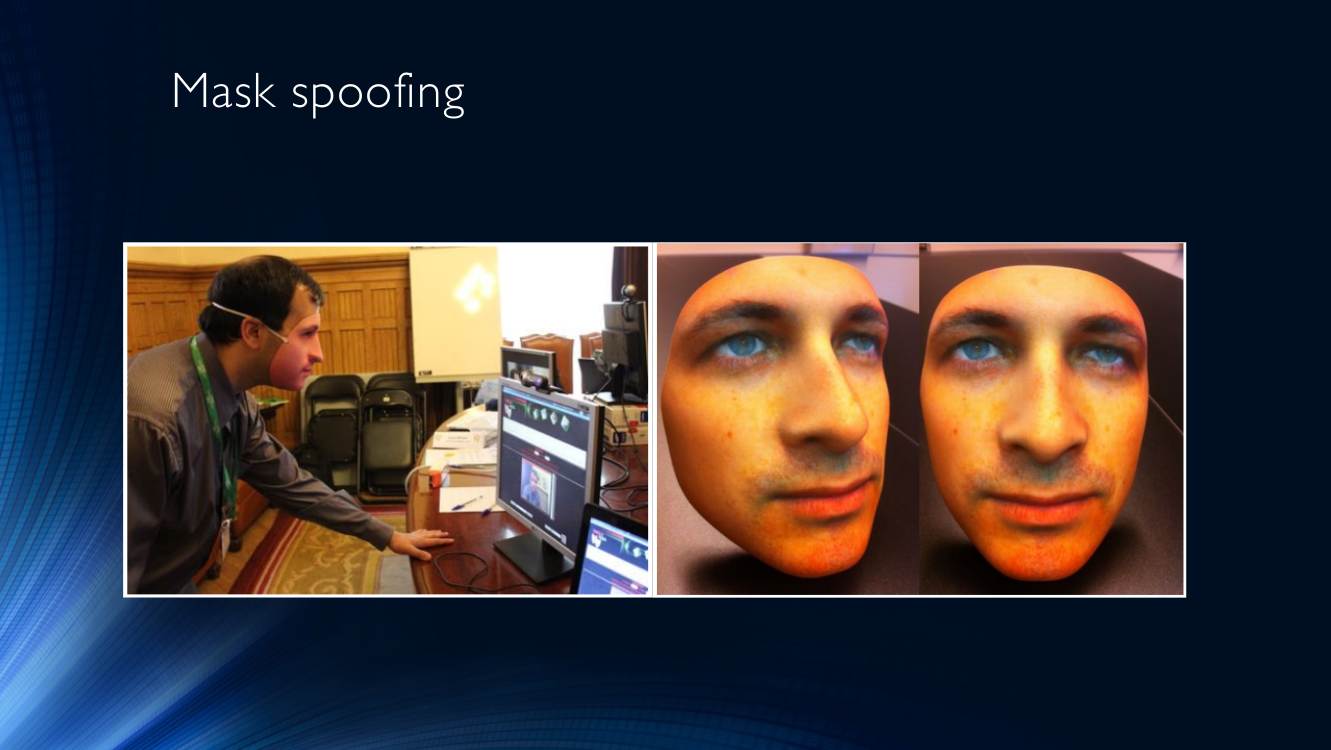
Еще можно распечатать фото себя или кого-то еще на листе бумаге и поднести его к камере (условимся называть такой тип атаки Printed attack).

Чуть более сложной является Replay attack, когда системе предъявляют экран другого устройства, на котором воспроизводится заранее записанное видео с другим человеком. Сложность исполнения компенсируется высокой эффективностью такой атаки, поскольку системы контроля часто используют признаки, основанные на анализе временных последовательностей, например, отслеживание моргания, микродвижений головы, наличие мимики, дыхания и так далее. Все это можно легко воспроизвести на видео.

Оба типа атак имеют ряд характерных признаков, позволяющих их обнаружить, и, таким образом, отличить экран планшета или лист бумаги от реального лица.
Сведем характерные признаки, позволяющие определить эти два типа атак, в таблицу:
| Printed attack | Replay attack |
|---|---|
| Снижение качества текстуры изображения при печати | Муар |
| Артефакты передачи полутонового изображения при печати на принтере | Отражения (блики) |
| Механические артефакты печати (горизонтальные линии) | Плоская картинка (отсутствие глубины) |
| Отсутствие локальных движений (например, морганий) | Могут быть видны границы изображения |
| Могут быть видны границы изображения |
Алгоритмы обнаружения атак. Старая добрая классика

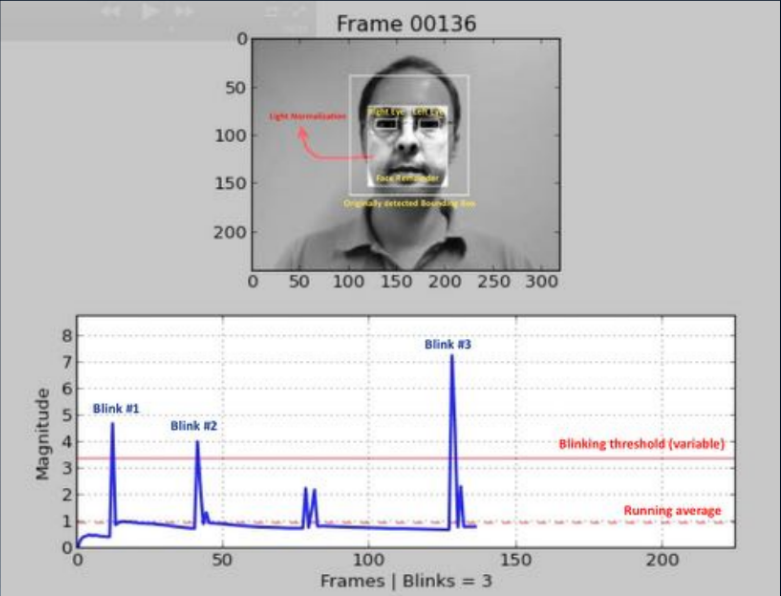
Один из самых старых подходов (работы 2007, 2008 годов) основан на обнаружении морганий человека путем анализа изображения по маске. Смысл заключается в построении какого-либо бинарного классификатора, позволяющего выделить изображения с открытыми и закрытыми глазами в последовательности кадров. Это может быть анализ видеопотока с помощью выделения частей лица (landmark detection), или же использование какой-то простой нейронной сети. И на сегодняшний день чаще всего используется этот метод; пользователю предлагают выполнить какую-то последовательность действий: покрутить головой, подмигнуть, улыбнуться и прочее. Если последовательность случайна, подготовиться к ней злоумышленнику заранее непросто. К сожалению, для честного пользователя этот квест тоже не всегда преодолим, и вовлеченность резко падает.
Еще можно использовать особенности ухудшения качества картинки при печати или воспроизведении на экране. Скорее всего, на изображении будут обнаружены даже какие-то локальные паттерны, пусть и неуловимые глазом. Это можно сделать, например, посчитав локальные бинарные паттерны (LBP, local binary pattern) для различных зон лица после выделения его из кадра (PDF). Описанную систему можно считать основоположником всего направления алгоритмов face anti-spoofing на основе анализа изображения. В двух словах, при расчете LBP последовательно берется каждый пиксель изображения, восемь его соседей и сравнивается их интенсивность. Если интенсивность больше, чем на центральном пикселе, присваивается единица, если меньше – ноль. Таким образом, для каждого пикселя получается 8-битовая последовательность. По полученным последовательностям строится попиксельная гистограмма, которая подается на вход SVM-классификатора.
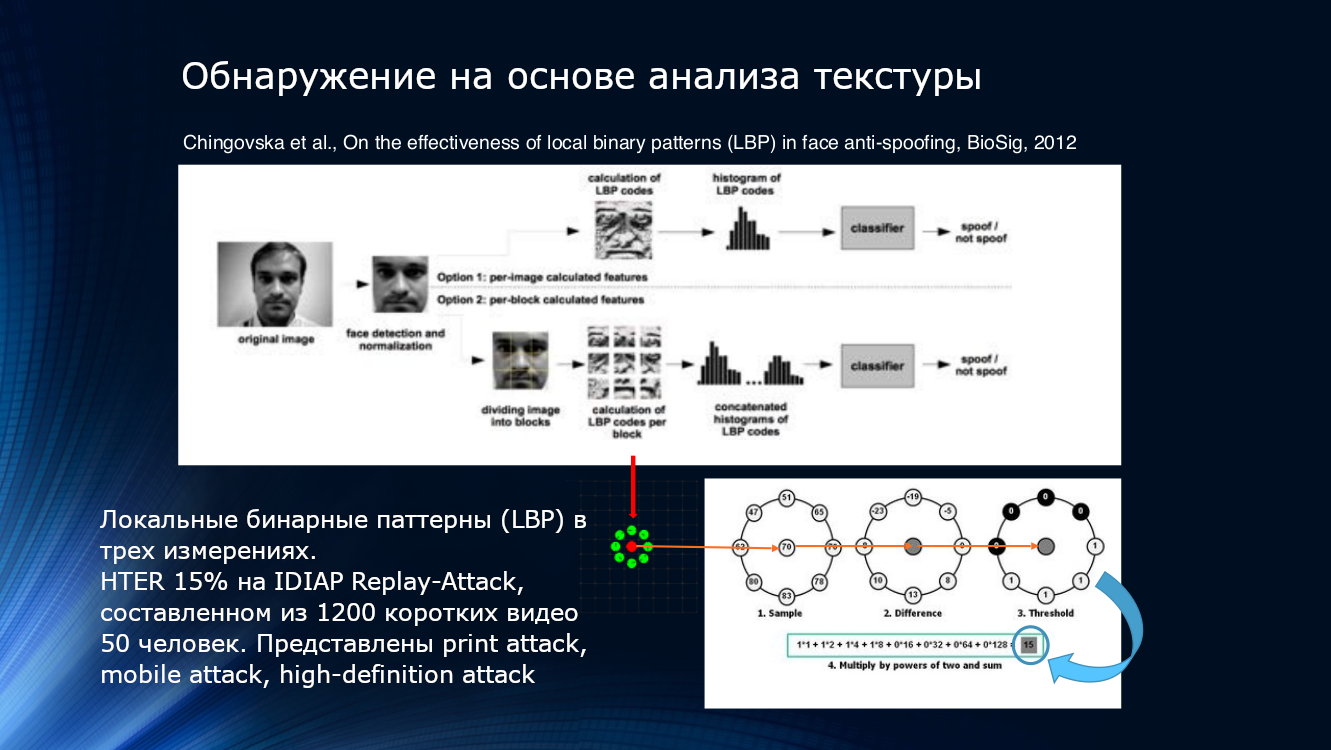
Локальные бинарные паттерны, гистограммирование и SVM. Приобщиться к неустаревающей классике можно по ссылке
Показатель эффективности HTER составляет «целых» 15%, и означает, что значительная часть злоумышленников преодолевает защиту без особых усилий, хотя и следует признать что множество и отсеивается. Алгоритм тестировался на наборе данных Replay-Attack от IDIAP, который составлен из 1200 коротких видео 50 респондентов и трех видов атак – printed attack, mobile attack, high-definition attack.
Идеи анализа текстуры изображения получили продолжение. В 2015 году Букинафит разработал алгоритм альтернативного разбиения изображения на каналы, помимо традиционного RGB, для результатов которого снова подсчитывались локальные бинарные паттерны, которые, как и в предыдущем способе, подавались на вход SVN классификатора. Точность HTER, рассчитанная на датасетах CASIA и Replay-Attack, составила впечатляющие на тот момент 3%.
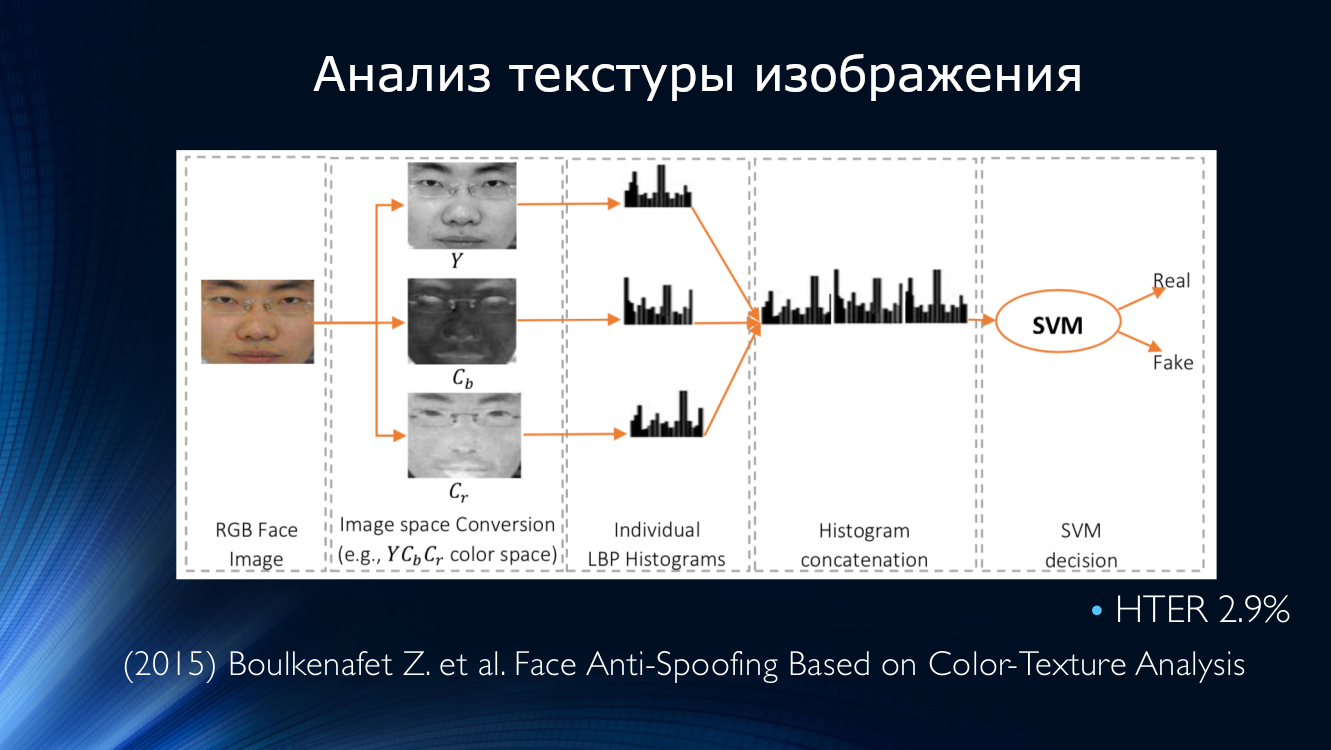
В это же время появились работы по обнаружению муара. Пател опубликовал статью, где предложил искать артефакты изображения в виде периодического узора, вызванные наложением двух разверток. Подход оказался работоспособным, показав HTER около 6% на наборах данных IDIAP, CASIA и RAFS. Это также было первой попыткой сравнить эффективность работы алгоритма на различных наборах данных.

Периодический узор на изображении, вызванный наложением разверток
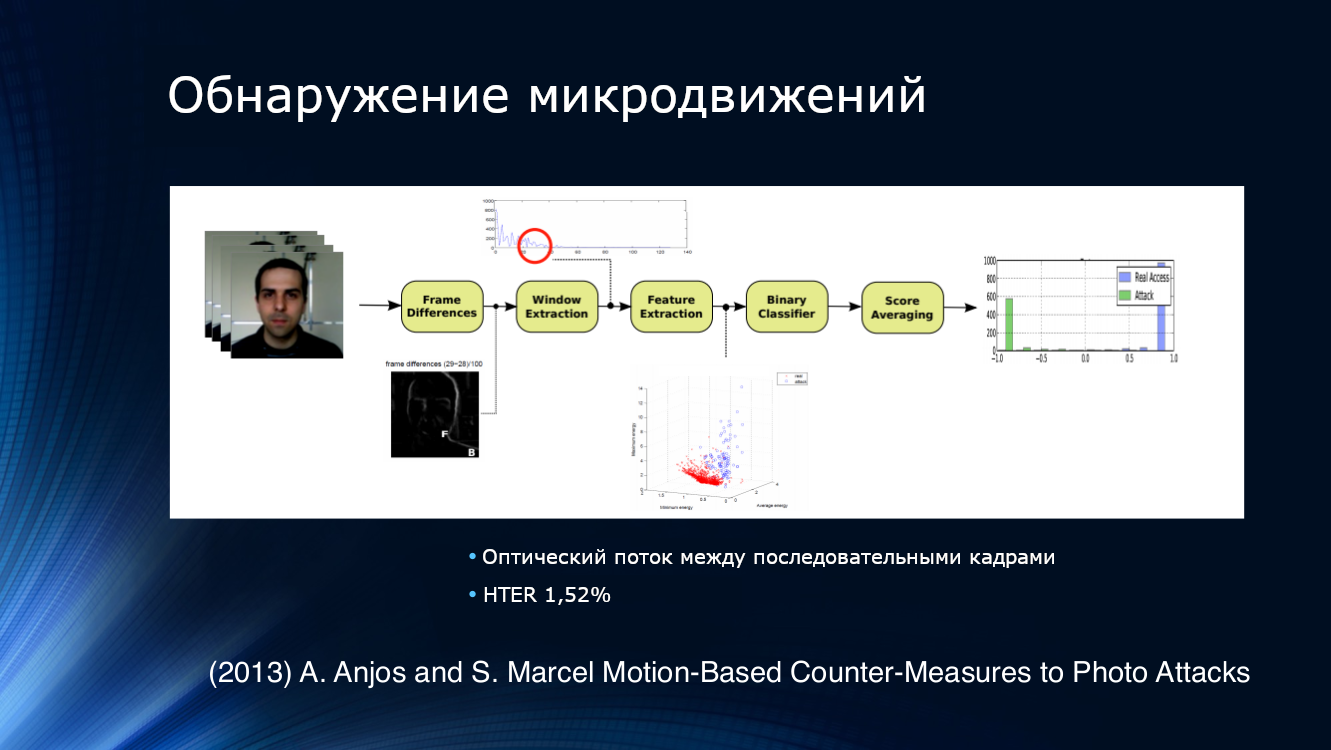
Чтобы обнаружить попытки предъявления фото, логичным решением было попытаться анализировать не одно изображение, а их последовательность, взятую из видео потока. Например, Анжос с коллегами предложили выделять признаки из оптического потока на соседних парах кадров, подавать на вход бинарного классификатора и усреднять результаты. Подход оказался достаточно эффективным, продемонстрировав HTER 1,52% на их собственном наборе данных.
Интересным выглядит метод отслеживания движений, находящийся несколько в стороне от общепринятых подходов. Так как в 2013 году обычного для современных проектов в области глубокого обучения принципа «подать сырое изображение на вход сверточной сети и настраивать слои сетки до получения результата» не было, Бхарадваж последовательно применил более сложные предварительные преобразования. В частности, он применил известный по работам ученых из MIT алгоритм эйлеровского усиления видео Eulerian video magnification, который с успехом применялся для анализа цветовых изменений кожного покрова в зависимости от пульса. Заменил LBP на HOOF (гистограммы направлений оптического потока), верно заметив, что коль скоро мы хотим отслеживать движения, и признаки нам нужны соответствующие, а не просто анализ текстур. В качестве классификатора использовался все тот же SVM, традиционный на тот момент. Алгоритм показал крайне впечатляющие результаты на датасетах Print Attack (0%) и Replay Attack (1,25%)

Давайте уже учить сетки!

С какого-то момента стало очевидно, что назрел переход к глубокому обучению. Пресловутая «революция глубокого обучения» настигла и face anti-spoofing.
«Первой ласточкой» можно считать метод анализа карт глубины на отдельных участках («патчах») изображения. Очевидно, карта глубины является очень хорошим признаком для определения плоскости, в которой расположено изображение. Хотя бы потому что у изображения на листе бумаги «глубины» нет по определению. В работе Атаума 2017 года из изображения извлекалось множество отдельных небольших участков, для них рассчитывались карты глубины, которые затем сливались с картой глубины основного изображения. При этом указывалось, что десяти случайных патчей изображения лица достаточно для надежного определения Printed Attack. Дополнительно авторы сливали вместе результаты работы двух сверточных нейросетей, первая из которых рассчитывала карты глубины для патчей, а вторая – для изображения в целом. При обучении на наборах данных с классом Printed Attack связывалась карта глубины, равная нулю, а с трехмерной моделью лица – серия случайно отбираемых участков. По большому счету, сама по себе карта глубины была не так важна, от нее использовалась лишь некоторая индикаторная функция, характеризующая «глубину участка». Алгоритм показал значение HTER 3,78%. Для обучения были использованы три публичных набора данных — CASIA-MFSD, MSU-USSA и Replay-Attack.

К сожалению, доступность большого количества прекрасных фреймворков для глубокого обучения привело к появлению огромного количества разработчиков, которые пытаются «в лоб» решить задачу face anti-spoofing хорошо знакомым способом ансамблирования нейросетей. Обычно это выглядит как стек карт признаков на выходах нескольких сетей, предобученных на каком-либо широко распространенном датасете, который подается на бинарный классификатор.
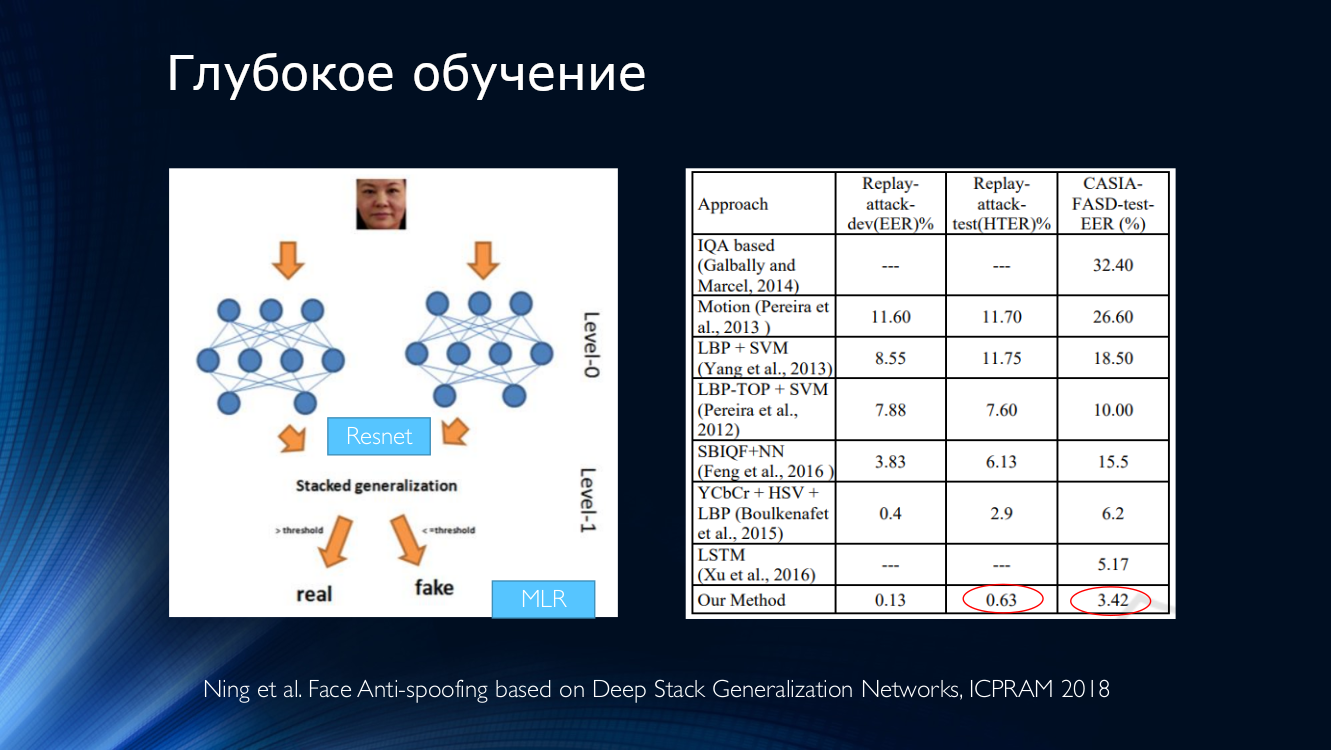
В целом стоит заключить, что к настоящему моменту опубликовано довольно много работ, которые в целом демонстрируют неплохие результаты, и которые объединяет всего одно небольшое «но». Все эти результаты продемонстрированы в рамках одного конкретного датасета! Ситуация усугубляется ограниченностью имеющихся наборов данных и, например, на пресловутом Replay-Attack уже никого не удивить HTER 0%. Все это приводит к появлению очень сложных архитектур, например, вот таких, с использованием различных мудрёных признаков, вспомогательных алгоритмов, собранных в стек, с несколькими классификаторами, результаты которых усредняются и так далее… На выходе авторы получают HTER =0,04%!
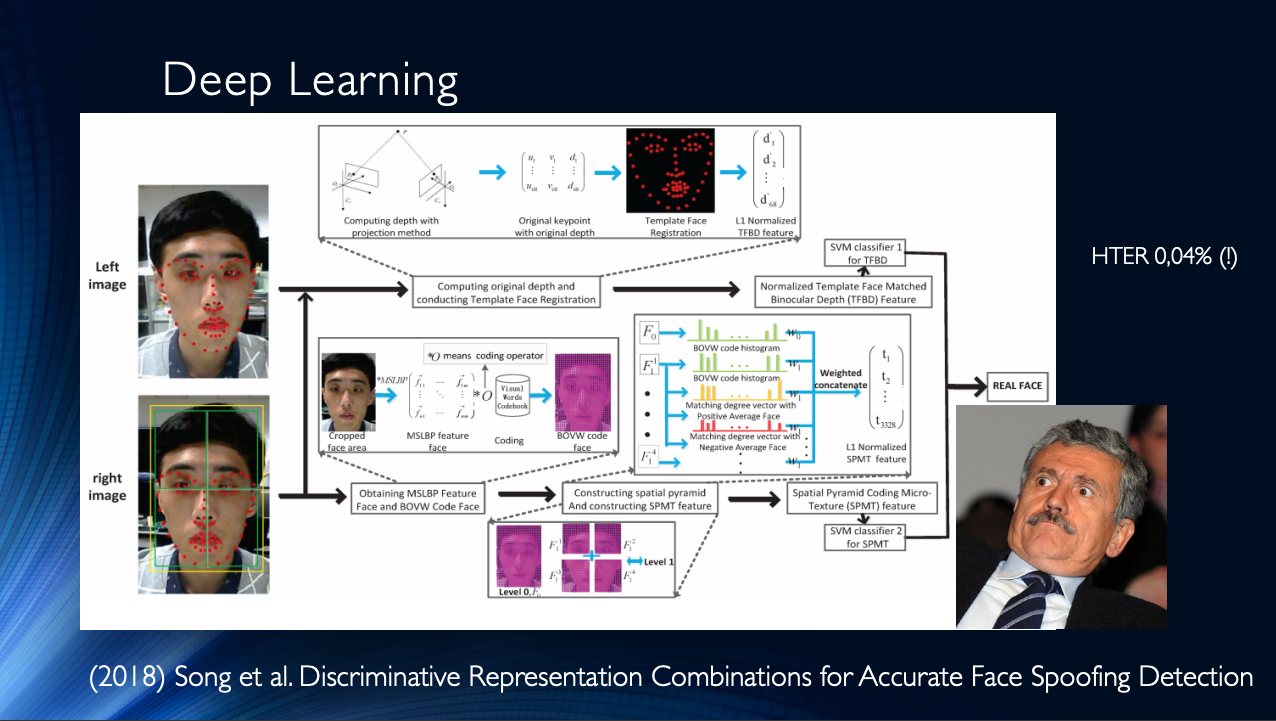
Это наводит на мысль о том, что задача face anti-spoofing в рамках конкретного датасета решена. Сведем в таблицу различные современные методы на основе нейросетей. Как легко увидеть, «эталонных результатов» удалось достигнуть очень разнообразными методами, которые только возникли в пытливых умах разработчиков.
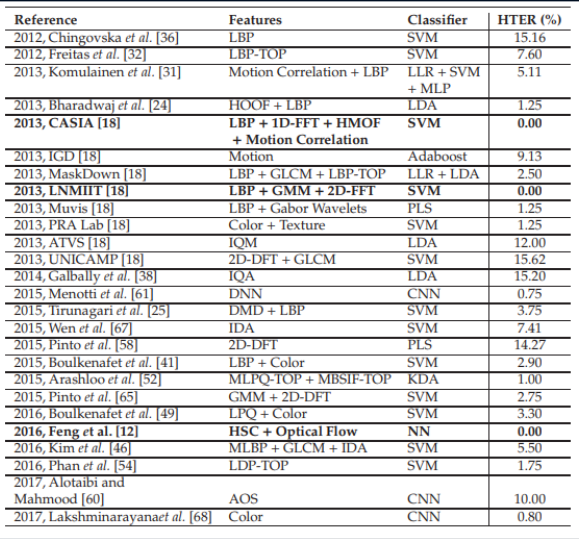
Сравнительные результаты различных алгоритмов. Таблица взята отсюда.
К сожалению, благостную картину борьбы за десятые доли процента нарушает все тот же «маленький» фактор. Если попытаться обучить нейросеть на одном наборе данных, а применить – на другом, то результаты окажутся… не столь оптимистичными. Хуже того, попытки применить классификаторы в реальной жизни не оставляют и вовсе никакой надежды.
Для примера, возьмем данные работы 2015 года, где для определения подлинности предъявленного изображения использовалась метрика его качества. Взгляните сами:
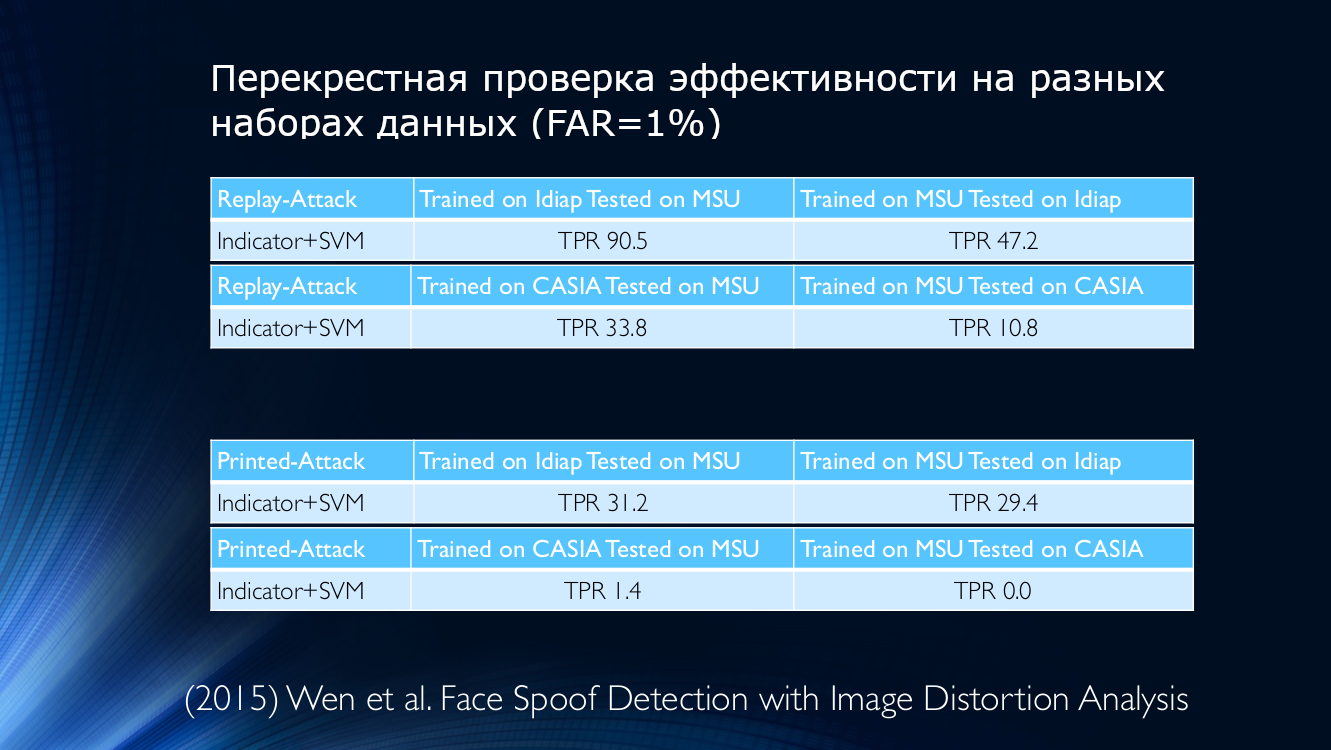
Иными словами, алгоритм, натренированный на данных Idiap, а примененный на MSU, даст коэффициент истинно положительных обнаружений 90,5%, а, если сделать наоборот (обучить на MSU, а проверить – на Idiap), то верно удастся определить только 47,2%(!) Для других сочетаний ситуация ухудшается еще больше, и, например, если натренировать алгоритм на MSU, а проверить – на CASIA, то TPR составит 10,8%! Это означает, что к атакующим было ошибочно причислено огромное количество честных пользователей, что не может не удручать. Ситуацию не смогло переломить даже cross-database обучение, что вроде бы кажется вполне разумным выходом из положения.
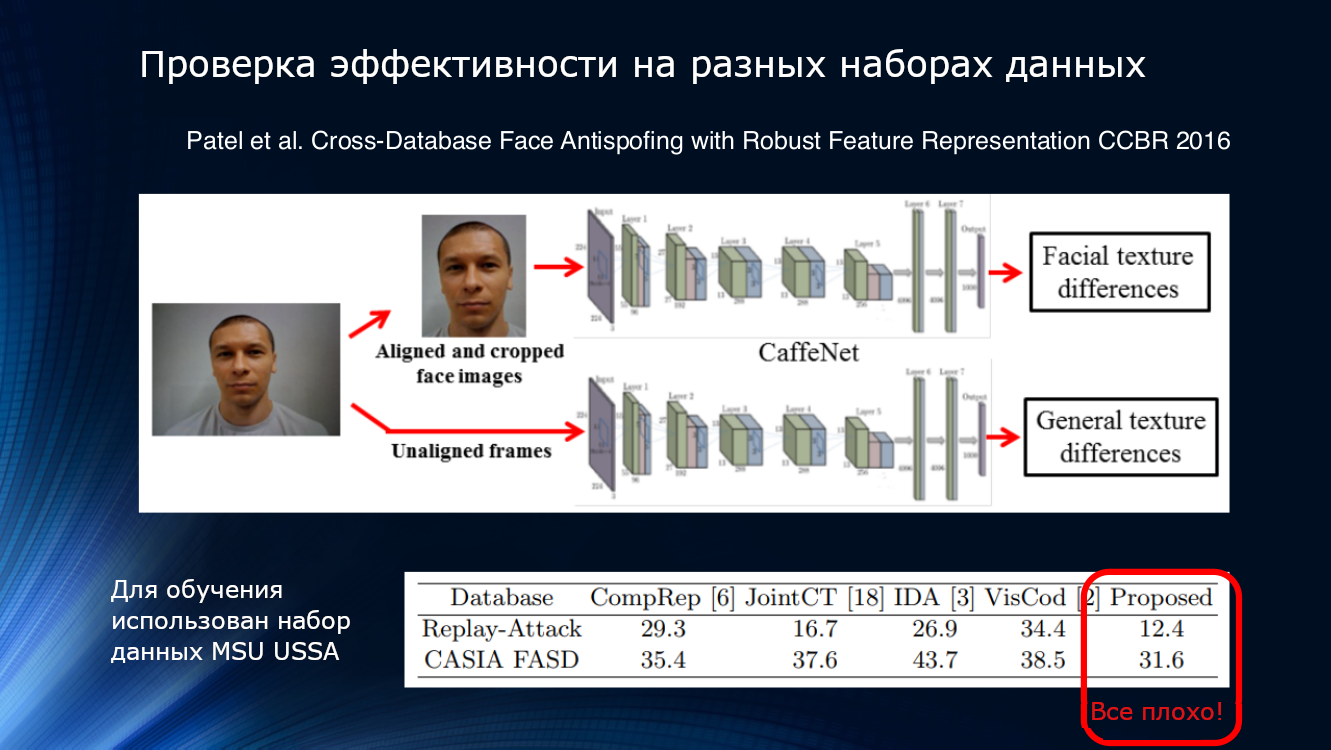
Посмотрим еще. Результаты, приведенные в статье Патела 2016 года, показывают, что даже при достаточно сложных конвейерах обработки и выделении таких надежных признаков, как моргание и текстура, результаты на незнакомых наборах данными не могут считаться удовлетворительными. Итак, в какой-то момент стало вполне очевидно, что предложенных способов отчаянно не хватает для обобщения результатов.
А если устроить соревнование…
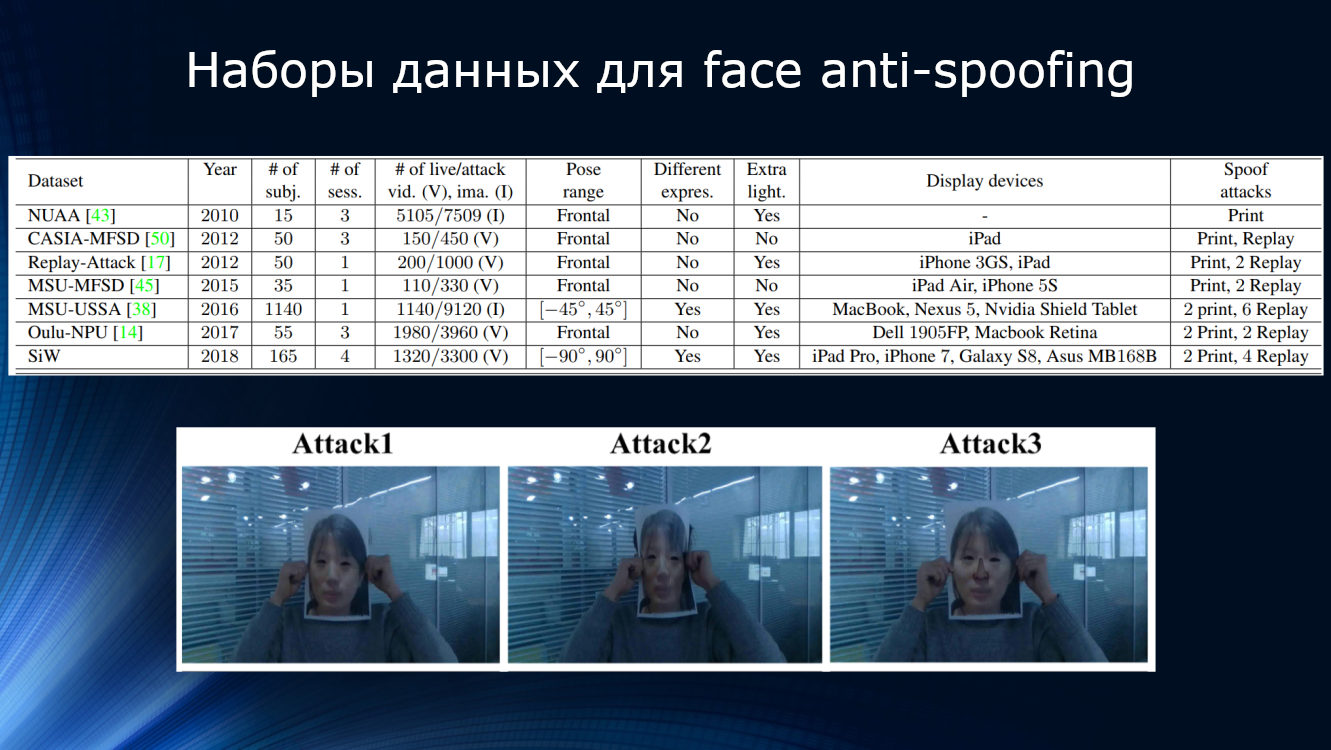
Конечно же, в области face anti-spoofing не обошлось без соревнований. В 2017 году в университете Оулу в Финляндии состоялся конкурс на собственном новом наборе данных с достаточно интересными протоколами, ориентированными, как раз, на использование в области мобильных приложений.
-Протокол 1: Имеется разница в освещении и фоне. Наборы данных записаны в различных местах и отличаются фоном и освещением.
-Протокол 2: Для атак использованы различные модели принтеров и экранов. Так, в проверочном наборе данных использована техника, которая не встречается в обучающем наборе
-Протокол 3: Взаимозаменяемость датчиков. Видео настоящего пользователя и атак записываются на пять различных смартфонов и используются в наборе данных для обучения. Для проверки алгоритма используется видео с еще одного смартфона, который в обучающем наборе не включен.
-Протокол 4: включает все вышеуказанные факторы.
Результаты оказались достаточно неожиданными. Как и в любом соревновании, времени придумывать гениальные идеи не было, поэтому практически все участники взяли знакомые архитектуры и доработали их тонкой настройкой, работой с признаками и попытками как-то использовать для обучения другие наборы данных. Призовое решение показало ошибку на четвертом, самом сложном протоколе, около 10%. Краткое описание алгоритмов победителей в таблице чуть ниже:
-
GRADIENT
- Выполняется слияние признаков по цвету (используя цветовые пространства HSV и YCbCr), текстуре и движению.
- Информация о динамике извлекается по данной последовательности видео и картам изменений по времени в отдельном кадре.
- Эта последовательность раздельно применяется по всем каналам в цветовых пространствах HSV и YCbCr, дающих вместе пару трехканальных изображений. Для каждого изображения ROI (region-of-interest) обрезается на основе положения глаз в последовательности кадров и масштабируется до 160×160 пикселей..
- Каждая ROI делится на 3×3 и 5×5 прямоугольных областей, по которым извлекаются равномерные LBP гистограммы признаков, которые объединяются в два вектора признаков размерностью 6018.
- С помощью рекурсивного удаления признаков (Recursive Feature Elimination) размерность уменьшается с 6018 до 1000.
- Для каждого вектора признаков выполняется классификация на основе SVM с последующим усреднением.|
-
SZCVI
- Из каждого видео извлекается выборка кадров, берется каждый шестой
- Масштабирование кадров до 216×384
- Пять VGG-подобных слоев
- Результаты отдельных кадров внутри выборки усредняются
-
Recod
- SqueezeNet обучается на Imagenet
- Transfer learning на двух наборах данных: CASIA и UVAD
- Сначала лицо обнаруживается и масштабируется до 224×224 pixels. Из каждого видео обучающего датасета извлекается, примерно, каждый седьмой кадр, который направляется на десять CNN.
- Для получения итогового результата показатели отдельных кадров усредняются.
- Для улучшения эффективности полученные показатели сводятся в обобщенный результат базового метода
-
CPqD
- Сеть Inception-v3, обученная на ImageNet
- Cигмоидная функция активации
- На основании определения положения глаз выполняется обрезка участков изображения, содержащих лицо, которые затем масштабируются до кадров 224×224 RGB |
Хорошо видно, что новых идей появилось не так много. Все те же LBP, предобученные сетки, анализ текстуры и цвета, попарный анализ кадров и т.д. GRADIANT выглядит наиболее грамотно спроектированным с системной точки зрения, в нем смешиваются различные признаки, идет работа в различных цветовых пространствах, проводится чистка признаков. Он и победил в соревновании.
Соревнование очень ярко показало существующие ограничения. В первую очередь, это ограниченность и несблансированность существующих датасетов для обучения. Во-первых, в них представлено довольно ограниченное количество людей (от 15 человек в NUAA до 1140 в MSU-USSA) и сессий, разнице внешнего освещения, выражениям лица, применяемым устройствам записи, углам съемки и видам атак. При этом в реальных условиях модель камеры, качество матрицы, условия съемки, фокусное расстояние и выдержка, фон и обстановка часто оказываются определяющими для анализа изображений. Во-вторых, сами методы анализа гораздо больше ориентированы на анализ отдельных участков изображения без существенной обработки самой обстановки сцены. Например, в наборе CASIA множество примеров атак представлены в виде изображения человека, который держит перед лицом фотографию. Очевидно, что видно характерное положение рук, границы листа с фото, могут быть видны волосы, шея и голова и так далее… Но решений, использующих анализ всей сцены и положения человека, представлено не было, все алгоритмы работали только с выделенным из всей сцены участком лица.
Недавно был предложен еще один многообещающий конкурс на новом наборе данных собственной разработки размером 30 Гб. Согласно условиям конкурса, должно быть выполнено обнаружение надетой на лицо маски, факта съемки распечатанной фотографии и предъявления видеозаписи на экране вместо настоящего лица. Вполне вероятно, что по его результатам мы и увидим концептуально новое решение.
Конечно, есть решения, основанные на «нестандартных подходах». Перейдем к ним с надеждой на улучшение текущего положения дел. Например, было предложено воспользоваться методом дистанционной фотоплетизмографии (rPPG – remote photoplethysmography), позволяющим обнаружить биение пульса человека по видеоизображению. Идея состоит в том, что при попадании света на живое лицо человека часть света отразится, часть-рассеется, а часть – поглощается кожей и тканями лица. При этом картина будет разной в зависимости от степени наполненности тканей кровью. Таким образом, можно отследить пульсацию крови в сосудах лица и, соответственно, обнаружить пульс. Конечно, если закрыть лицо маской или предъявить экран телефона, никакой пульсации обнаружить не получится. На этом принципе Лю с соавторами предложили разбивать изображение лица на участки, детектировать пульс методом дистанционной фотоплетизмографии, попарно сравнивать различные участки для подсчета пульса и строить карты с целью обнаружения наличия или отсутствия маски, а также сравнения пульса на разных участках лица.


Работа показала значение HTER около 10%, подтвердив принципиальную применимость метода. Имеется еще несколько работ, подтверждающих перспективность этого подхода
(CVPR 2018) J. H.-Ortega et al. Time Analysis of Pulsebased Face Anti-Spoofing in Visible and NIR
(2016) X. Li. et al. Generalized face anti-spoofing by detecting pulse from face videos
(2016) J. Chen et al. Realsense = real heart rate: Illumination invariant heart rate estimation from videos
(2014) H. E. Tasli et al. Remote PPG based vital sign measurement using adaptive facial regions
В 2018 году Лю с коллегами из университета Мичигана предложили отказаться от бинарной классификации в пользу подхода, который они назвали “binary supervision” – то есть использование более сложной оценки на основе карты глубины и дистанционной фотоплетизмографии. Для каждого из настоящих изображений лица реконструировали трехмерную модель с помощью нейросети и назвали ее с картой глубины. Фальшивым изображениям была присвоена карта глубины, состоящая из нулей, в конце концов это ведь просто лист бумаги или экран устройства! Эти характеристики были приняты за «истину», нейросети обучались на собственном наборе данных SiW. Затем, на входное изображение накладывалась трехмерная маска лица, для нее высчитывались карта глубины и пульс, и все это связывалось вместе в довольно сложном конвейере. В итоге, метод показал точность около 10 процентов на конкурсном наборе данных OULU. Интересно, что победитель соревнования, организованного университетом Оулу, построил алгоритм на бинарных паттернах классификации, отслеживании морганий и прочих признаках «конструированных вручную», и его решение тоже имело точность около 10%. Выигрыш составил всего лишь около половины процента! В пользу новой комбинированной технологии говорит то, что алгоритм был обучен на собственном наборе данных, а проверен на OULU, улучшив результат победителя. Что говорит о некоторой переносимости результатов с датасета на датасет, и чем черт не шутит, возможно и на реальную жизнь. Однако, при попытке выполнить обучение на других датасетах – CASIA и ReplayAttack, снова был получен результат около 28%. Конечно, это превосходит показатели других алгоритмах при обучении на различных наборах данных, но при таких значениях точности ни о каком промышленном использовании речи быть не может!
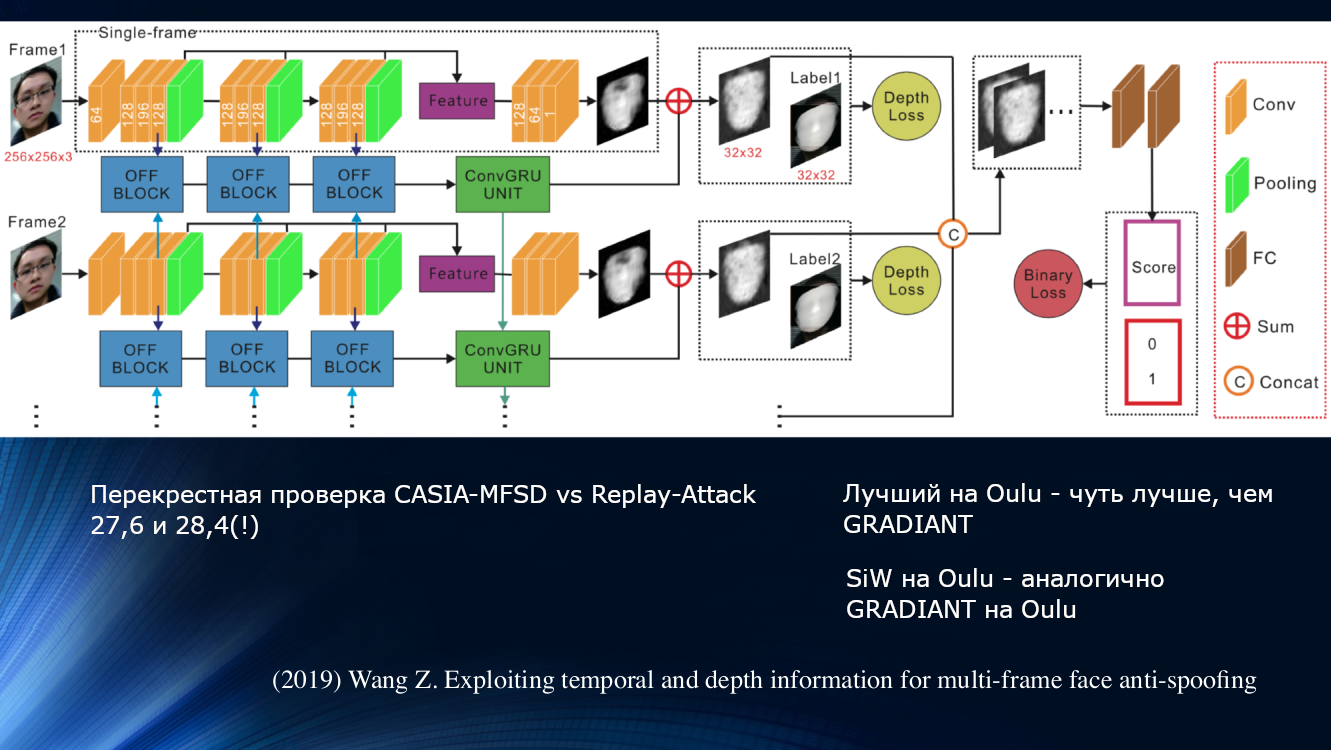
Другой подход был предложен Вангом с коллегами в свежей работе 2019 года. Было отмечено, что при анализе микродвижений лица заметны повороты и смещения головы, приводящие к характерному изменению углов и относительных расстояний между признаками на лице. Так при смещении лица в стороны по горизонтали угол между носом и ухом увеличивается. Но, если таким же образом сместить лист бумаги с картинкой, угол уменьшится! Для иллюстрации стоит процитировать рисунок из работы.
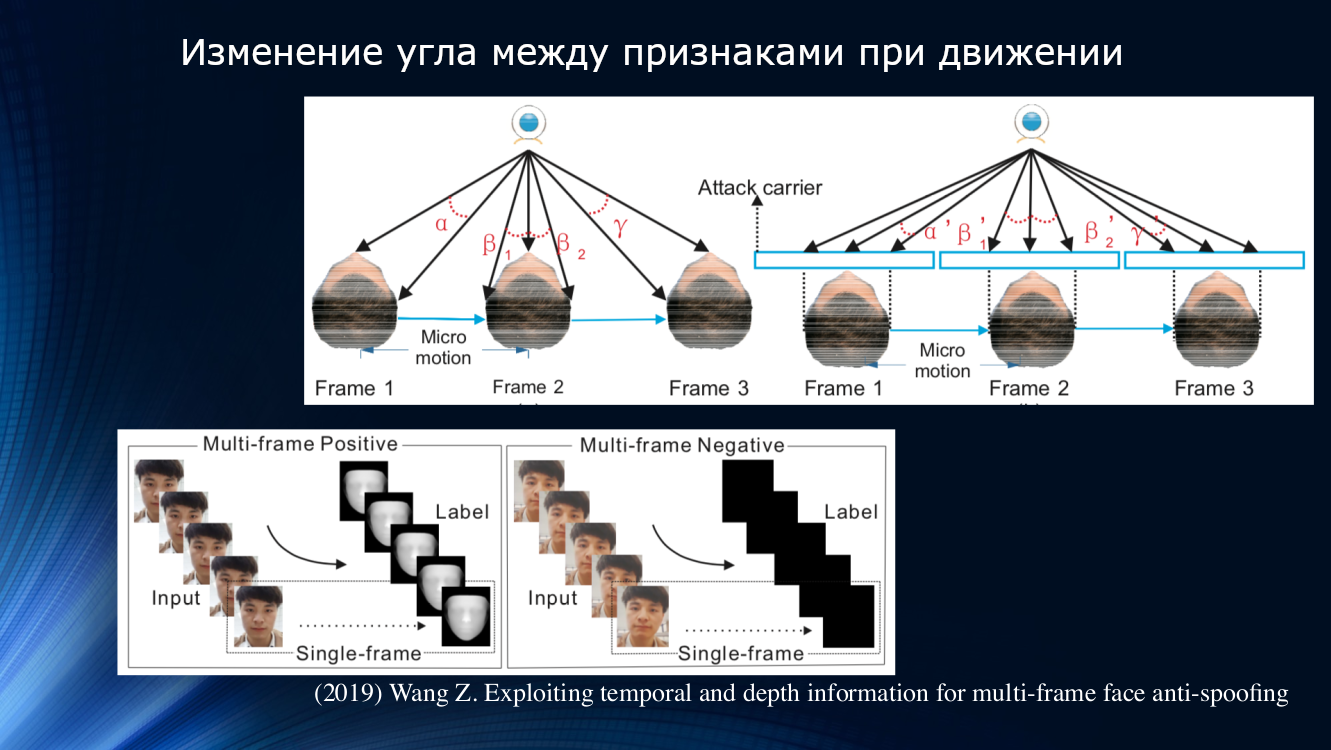
На этом принципе авторы построили целый обучаемый блок для переноса данных между слоями нейронной сети. В нем учитывались «неправильные смещения» для каждого кадра в последовательности из двух кадров, и это позволило использовать результаты в следующем блоке анализа долговременных зависимостей на базе GRU Gated Recurrent Unit. Затем все признаки конкатенировались, подсчитывалась функция потерь и выполнялась итоговая классификация. Это позволило еще слегка улучшить результат на наборе данных OULU, но проблема зависимости от обучающего данных осталась, поскольку для пары CASIA-MFSD и Replay-Attack показатели составили 17,5 и 24 процента, соответственно.
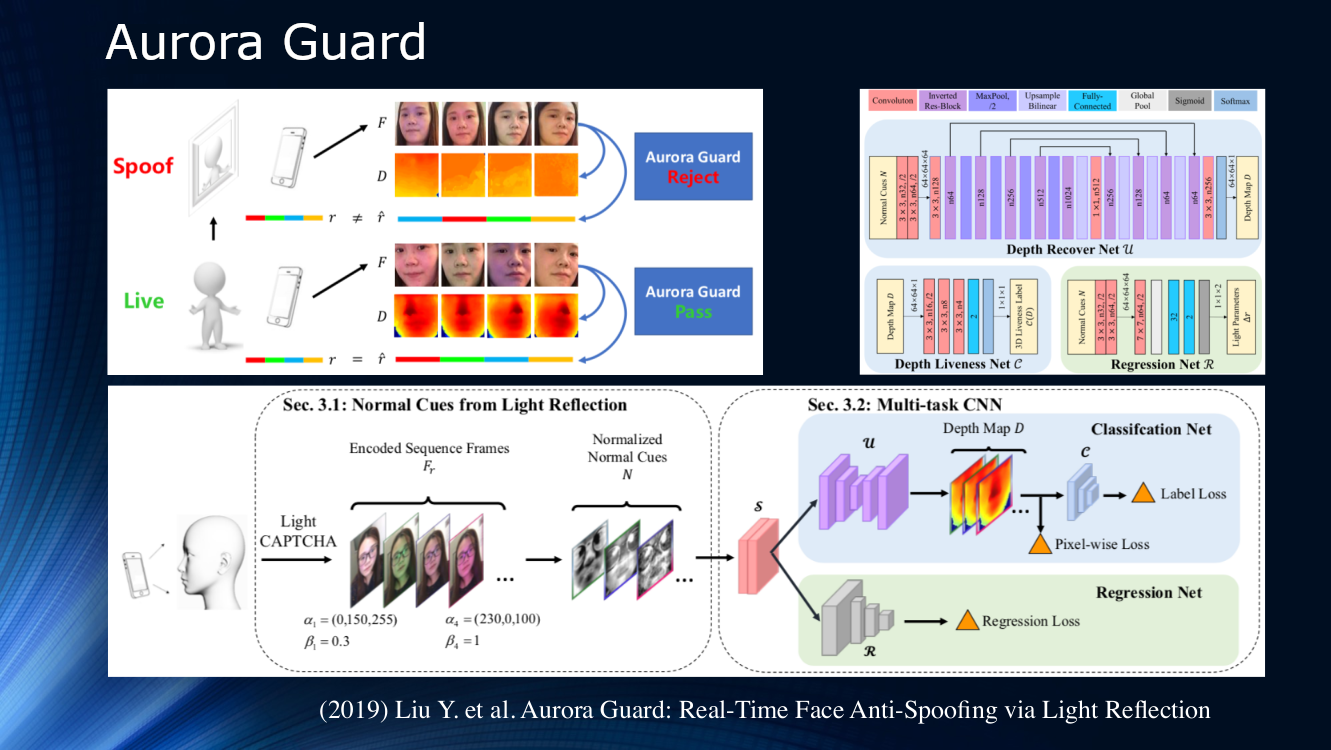
Под занавес стоит отметить работу специалистов Tencent, предложивших изменить сам способ получения исходного видеоизображения. Вместо пассивного наблюдения за сценой они предложили динамически освещать лицо и считывать отражения. Принцип активного облучения объекта уже давно применяется в локационных системах различного рода, поэтому, его использование для изучения лица выглядит весьма логичным. Очевидно, что для надежной идентификации в самом изображении не хватает признаков, и освещение экрана телефона или планшета последовательностью световых символов (light CAPTCHA по терминологии авторов), может сильно помочь. Далее определяется разница в рассеянии и отражении по паре кадров, и результаты подаются на многозадачную нейронную сеть для дальнейшей обработки по карте глубины и вычисления различных функций потерь. В конце выполняется регрессия нормализованных кадров освещенности. Авторы не анализировали обобщающую способность своего алгоритма на других наборах данных и обучали его на собственном закрытом датасете. Результат составляет порядка 1% и сообщается, что модель уже была развернута для реального использования.
До 2017 года область face anti-spoofing была не слишком активной. Зато 2019 уже подарил целую серию работ, что связано с агрессивным продвижением мобильных технологий идентификации по лицу, в первую очередь, компанией Apple. Кроме того, технологиями распознавания по лицу заинтересовались банки. В отрасль пришло много новых людей, что позволяет надеяться на быстрый прогресс. Но пока что, несмотря на красивые названия публикаций, обобщающая способность алгоритмов остается очень слабой и не позволяет говорить о какой-либо пригодности к практическому использованию.
Заключение. А напоследок я скажу, что…
- Локальные бинарные паттерны, отслеживание моргания, дыхания, движений и прочие сконструированные вручную признаки совершенно не потеряли значимости. Это вызвано, прежде все тем, что глубокое обучение в области face anti-spoofing все еще весьма наивно.
- Совершенно очевидно, что в «том самом» решении будет выполняться слияние нескольких методов. Анализ отражения, рассеяния, карты глубины должны использоваться вместе. Скорее всего, поможет добавление дополнительного канала данных, например, запись голоса и какие-то системные подходы, которые позволят собрать несколько технологий в единую систему
- Практически все технологии, используемые для распознавания лица, находят применение в face anti-spoofing (кэп!) Все, что было разработано для распознавания лиц, в том или ином виде нашло применение и для анализа атак
- Существующие датасеты достигли насыщения. Из десяти основных наборов данных в пяти удалось достичь нулевой ошибки. Это уже говорит, например, о работоспособности методов на основе карт глубины, но не позволяет улучшить обобщающую способность. Нужны новые данные и новые эксперименты на них
- Есть явный дисбаланс между степенью развития распознавания лиц и face anti-spoofing. Технологии распознавания существенно опережают системы защиты. Более того, именно отсутствие надежных систем защиты тормозит практическое применение систем распознавания лиц. Так получилось, что основное внимание уделялось именно распознаванию лиц, а системы обнаружения атак остались несколько в стороне
- Есть сильная потребность системного подхода в области face anti-spoofing. Прошедший конкурс университета Оулу показал, что при использовании нерепрезентативного набора данных вполне возможно победить простой грамотной настройкой устоявшихся решений, без разработки новых. Возможно, новое соревнование сможет переломить ситуацию
- С возрастанием интереса к тематике и внедрением технологий распознавания по лицу крупными игроками появились «окна возможностей» для новых амбициозных команд, поскольку есть серьезная потребность в новом решении на уровне архитектуры
Источник


