
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd
- Веселая Квартусель, или как процессор докатился до такой жизни
- Методы оптимизации кода для Redd. Часть 1: влияние кэша
- Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин
- Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы
- Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI
- Работа с нестандартными шинами комплекса Redd
- Практика в работе с нестандартными шинами комплекса Redd
- Проброс USB-портов из Windows 10 для удалённой работы
- Использование процессорной системы Nios II без процессорного ядра Nios II
- Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM
- Разработка простейшего логического анализатора на базе комплекса Redd
- Разработка логического анализатора на базе Redd – проверяем его работу на практике
Пожалуй, я сегодня даже нарушу традицию и буду отлаживать проект не на комплексе Redd, а на обычной макетке. Во-первых, я отдаю себе отчёт, что у подавляющего большинства читателей нет доступа к такому комплексу, но есть доступ к Ali Express. Ну, а во-вторых, мне просто лень городить огород с подключением пары из USB-устройства и хоста, а также бороться с возникающими наводками.
В далёком 2017-м году я искал в сети готовые решения и нашёл вот такую замечательную вещь, вернее, её предка. Сейчас у них всё уже на специализированной плате, а тогда везде были фотографии простой макетки от Xilinx, к которой была подключена плата от WaveShare (узнать про неё можно тут). Давайте посмотрим на фотографию этой платы.

На ней имеется сразу два разъёма USB. Причём из схемы видно, что они запараллелены. В розетку типа A можно вставлять свои USB-устройства, а к разъёму mini USB можно подключить кабель, который будем втыкать в хост. А в описании проекта OpenVizsla говорится, что этот путь работает. Жаль только, что сам проект довольно трудно читаемый. Его можно взять на github, но я дам ссылку не на тот аккаунт, который указан на странице, его все и так найдут, но он переделан для MiGen, а тот вариант, который я нашёл в 2017-м: http://github.com/ultraembedded/cores, он на чистом Verilog, а там — ветка usb_sniffer. Там всё идёт не напрямую через ULPI, а через преобразователь ULPI в UTMI (оба этих неприличных слова — это такие микросхемы физического уровня, согласующие скоростной канал USB 2.0 с шинами, понятными процессорам и ПЛИС), а уже потом – работа с этим UTMI. Как там всё работает, я так и не разобрался. Поэтому предпочёл сделать свою разработку с нуля, благо мы скоро увидим, что там скорее всё страшно, чем трудно.
На каком железе можно работать
Ответ на вопрос из заголовка прост: на любом, где есть ПЛИС и внешняя память. Разумеется, в этом цикле мы рассматриавем только ПЛИС Altera (Intel). Правда, имейте в виду, что данные из микросхемы ULPI (именно она стоит на той платочке) идут на частоте 60 МГц. Длинные провода тут неприемлемы. Ещё важно подключать линию CLK к входу ПЛИС из группы GCK, иначе всё будет то работать, то сбоить. Лучше не рисковать. Программно пробрасывать не советую. Я пробовал. Кончилось всё проводом к ноге из группы GCK.
Для сегодняшних опытов по моей просьбе знакомый спаял мне вот такую систему:

Микромодуль с ПЛИС и SDRAM (ищите его на АЛИ экспресс по фразе FPGA AC608) и та самая плата ULPI от WaveShare. Вот так выглядит модуль на фотографиях от одного из продавцов. Просто мне лень его отвинчивать от корпуса:

Кстати, вентиляционные отверстия, как на фото моего корпуса, делаются очень интересно. На модели рисуем сплошной слой, а в слайсере ставим заполнение, скажем, 40% и говорим, что снизу и сверху надо сделать ноль сплошных слоёв. В итоге, 3D принтер сам рисует эту вентиляцию. Очень удобно.
В общем, подход к поиску железа понятен. Теперь начинаем проектировать анализатор. Вернее, сам анализатор мы уже сделали в прошлых двух статьях (тут работали с железом, а тут — с доступом к нему), сейчас же просто спроектируем проблемно-ориентированную голову, которая ловит данные, приходящие из микросхемы ULPI.
Что должна уметь делать голова
В случае с логическим анализатором всё было легко и просто. Есть данные. Мы к ним подключились и начали паковать, да слать в шину AVALON_ST. Здесь всё сложнее. Спецификацию ULPI можно найти тут . Девяносто три листа занудного текста. Лично меня такое вгоняет в уныние. Чуть более простым выглядит описание на микросхему USB3300, которая стоит в плате от WaveShare. Его можно взять тут . Хотя я всё равно копил смелость с того самого декабря 2017-го года, иногда почитывая документ и сразу закрывая его, как чувствовал приближение депрессии.
Из описания ясно, что у ULPI имеется набор регистров, которые следует заполнить перед началом работы. В первую очередь, это связано с подтягивающими и терминирующими резисторами. Вот рисунок, поясняющий суть:

В зависимости от роли (хост или устройство), а также выбранной скорости, надо включать разные резисторы. Но мы не являемся ни хостом, ни устройством! Мы должны все резисторы отключить, чтобы не мешать основным устройствам на шине! Это делается через запись в регистры.
Ну, и скорость. Надо выбрать рабочую скорость. Для этого также надо произвести запись в регистры.
Когда мы всё настроили, можно приступать к ловле данных. Но в названии ULPI буквы «LP» означают «Low Pins». И вот это самое уменьшение числа ножек привело к такому зубодробительному протоколу, что только держись! Давайте рассмотрим протокол подробнее.
Протокол ULPI
Протокол ULPI несколько непривычен для простого человека. Но если посидеть с документом и помедитировать, то начинают проявляться некоторые более-менее понятные черты. Становится ясно, что разработчики приложили все усилия, чтобы действительно уменьшить число используемых контактов.
Я не буду здесь перепечатывать полную документацию. Ограничимся самыми важными вещами. Наиважнейшая из них — направление сигналов. Его невозможно запомнить, лучше каждый раз смотреть на рисунок:

ULPI LINK — это наша ПЛИС.
Временная диаграмма приёма данных
В состоянии покоя мы должны выдавать на шину данных константу 0x00, что соответствует команде IDLE. Если из шины USB приходят данные, протокол обмена будет выглядеть так:
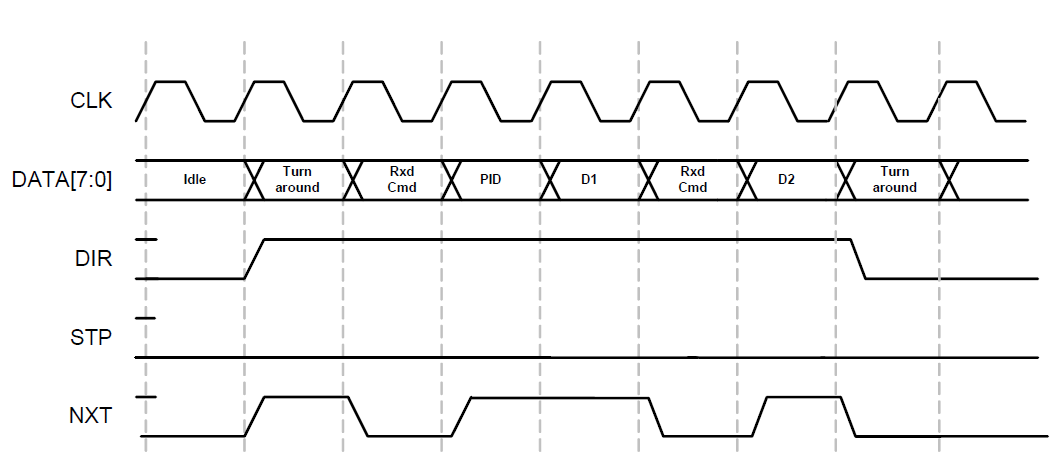
Цикл начнётся с того, что в единицу взлетит сигнал DIR. Сначала, он там будет находиться один такт, чтобы система успела переключить направление шины данных. Дальше — начинаются чудеса экономии. Видите имя сигнала NXT? Это он при передаче от нас значит NEXT. А здесь — это совсем другой сигнал. Когда DIR равен единице, NXT я бы назвал C/D. Низкий уровень — перед нами команда. Высокий — данные.
То есть, мы должны фиксировать 9 бит (шину DATA и сигнал NXT) либо всегда при высоком DIR (затем программно отфильтровывая первый такт), либо начиная со второго такта после взлёта DIR. Если линия DIR упала в ноль — переключаем шину данных на запись и снова начинаем вещать команду IDLE.
С приёмом данных — понятно. Теперь разбираем работу с регистрами.
Временная диаграмма записи в регистр ULPI
Для записи в регистр используется следующая времянка (я специально перешёл на жаргон, так как чувствую, что меня клонит в сторону ГОСТ 2.105, а это – скучно, так что отойду от него):
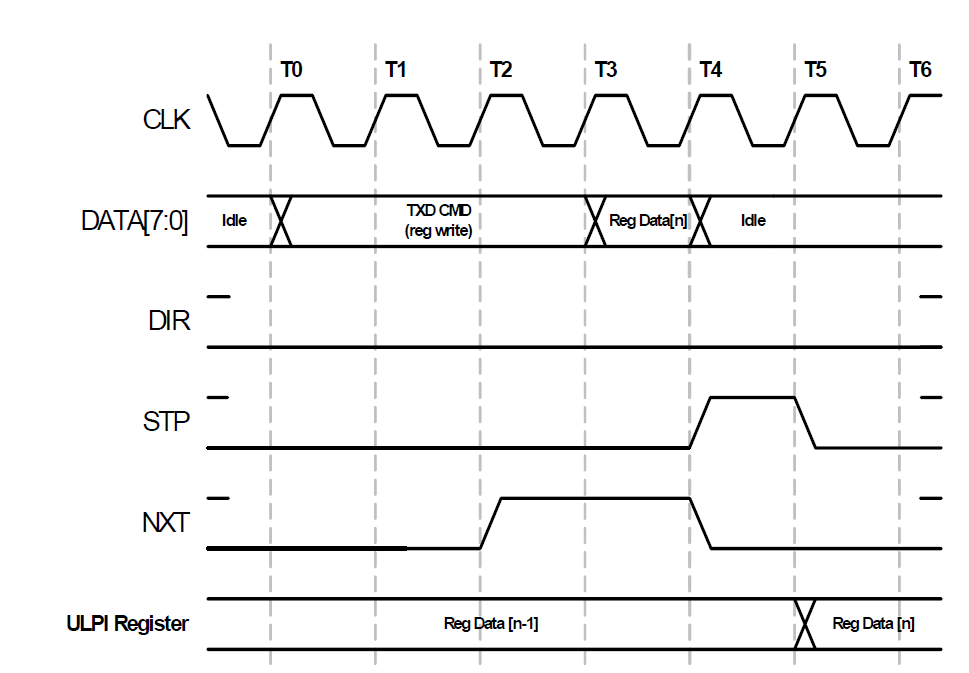
Перво-наперво, мы должны дождаться состояние DIR=0. На такте T0, мы должны выставить на шину данных константу TXD CMD. Что это значит? Сразу и не разберёшь, но если чуть покопаться по документам, выясняется, что нужное значение можно найти тут:

То есть, в старшие биты данных следует положить значение «10» (для всего байта получится маска 0x80), а в младшие — номер регистра.
Далее, следует дождаться взлёта сигнала NXT. Этим сигналом микросхема подтверждает, что услышала нас. На рисунке выше мы дождались его на такте T2 и выставили на следующем такте (T3) данные. На такте T4 ULPI примет данные и снимет NXT. А мы отметим конец цикла обмена единицей в STP. На также T5 данные будут защёлкнуты во внутренний регистр. Процесс завершён. Вот такая расплата за малое число выводов. Но нам надо будет записать данные только при старте, так что помучиться с разработкой, конечно, придётся, но на работу особо всё это влиять не будет.
Временная диаграмма чтения из регистра ULPI
Честно говоря, для практических задач чтение регистров не так и важно, но давайте рассмотрим и его. Чтение будет полезно хотя бы для того, чтобы убедиться, что мы верно реализовали запись.
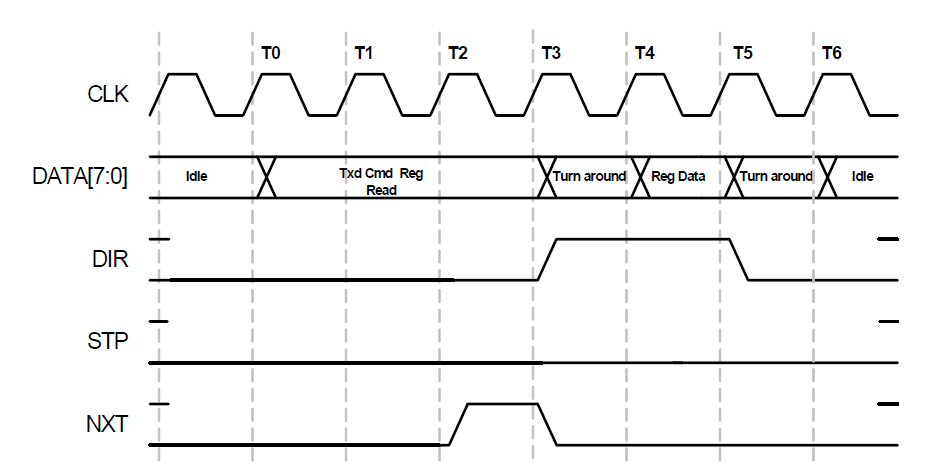
Мы видим, что перед нами гремучая смесь из предыдущих двух времянок. Адрес мы задаём так, как это делали для записи в регистр, а данные забираем по правилам чтения данных.
Ну, что? Приступаем к проектированию автомата, который будет нам всё это формировать?
Структурная схема головы
Как видно из описания выше, голова должна быть подключена сразу к двум шинам: AVALON_MM для доступа к регистрам и AVALON_ST для выдачи данных на сохранение в ОЗУ. Главное в голове — это мозг. И вот им должен стать конечный автомат, который будет формировать временные диаграммы, рассмотренные нами ранее.

Начнём его разработку с функции приёма данных. Здесь следует учитывать, что мы никак не можем повлиять на поток из шины ULPI. Данные оттуда если начали идти, то будут идти. Им всё равно, есть готовность у шины AVALON_ST или её нет. Поэтому мы просто будем игнорировать неготовность шины. В реальный анализатор можно будет добавить индикацию аварии в случае выдачи данных без готовности. В рамках статьи всё должно быть просто, поэтому просто запомним это на будущее. А обеспечивать наличие готовности шины, как в логическом анализаторе, нам будет внешний блок FIFO. Итого, граф переходов автомата для приёма потока данных получается таким:
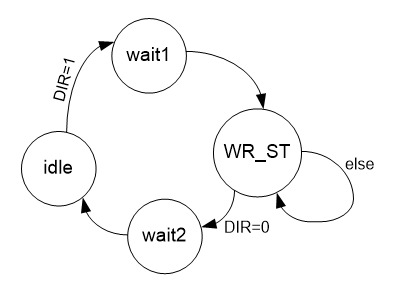
Взлетел DIR – начали приём. Один такт повисели в wait1, затем – принимаем, пока DIR равен единице. Упал в ноль – через такт (правда, не факт, что он нужен, но пока заложим состояние wait2) вернулись в idle.
Пока всё просто. Не забываем, что в шину AVALON_ST должны уходить не только линии D0_D7, но и линия NXT, так как она определяет, что сейчас передаётся: команда или данные.
Цикл записи регистра может иметь непредсказуемое время исполнения. С точки зрения шины AVALON_MM, это не очень хорошо. Поэтому сделаем его чуть хитрее. Заведём буферный регистр. Данные будут попадать в него, после чего шина AVALON_MM сразу освободится. С точки зрения разрабатываемого автомата, появляется входной сигнал have_reg (получены данные в регистре, которые следует отправить) и выходной сигнал reg_served (означающий, что процесс выдачи регистра завершён). Добавляем логику записи в регистр на граф переходов автомата.
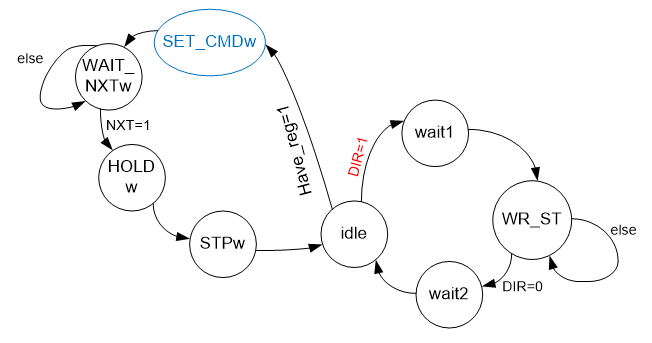
Я выделил условие DIR=1 красным, чтобы было ясно, что оно имеет наивысший приоритет. Тогда можно в новой ветке автомата исключить ожидание нулевого значения сигнала DIR. Вход в ветку с иным его значением будет просто невозможен. Состояние SET_CMDw имеет синий цвет, так как наиболее вероятно, будет чисто виртуальным. Это же просто выполняемые действия! Никто не мешает установить на шине данных соответствующую константу и просто при переходе! В состоянии STPw, среди прочего, можно также на один такт взвести сигнал reg_served, чтобы сбросить сигнал BSY для шины AVALON_MM, разрешив новый цикл записи.
Ну, и осталось добавить ветку чтения регистра ULPI. Здесь же — всё наоборот. Автомат, обслуживающий шину, шлёт нам запрос и ждёт нашего ответа. Когда данные получены, он сможет обработать их. А будет он работать с приостановкой шины или по опросу, это уже проблемы того автомата. Конкретно сегодня я решил работать по опросу. Запросили данные – появился BSY. Как BSY пропал – можно принимать считанные данные. Итого, граф принимает вид:
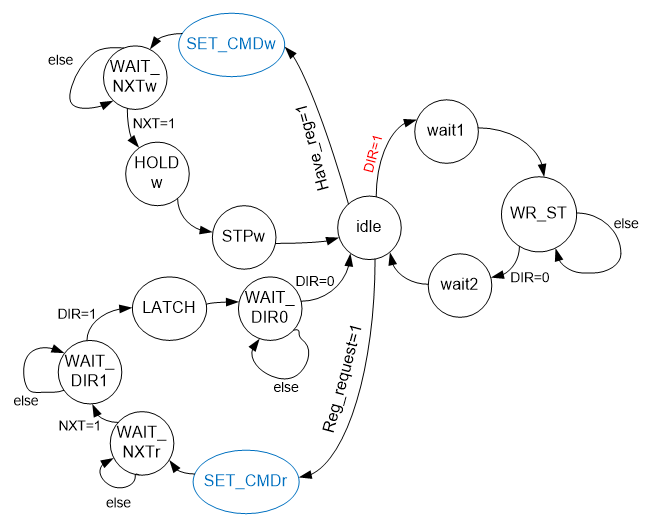
Возможно, по ходу разработки будут какие-то коррективы, но пока — будем придерживаться этого графа. В конце концов, это же не отчёт, а инструкция по методике разработки. А методика такова, что сначала надо нарисовать граф переходов, а затем – делать логику, согласно этому рисунку с поправкой на всплывающие подробности.
Особенности реализации автомата со стороны AVALON_MM
При работе с шиной AVALON_MM, можно пойти двумя путями. Первый — создавать задержки доступа к шине. Мы этот механизм исследовали в одной из предыдущих статей, и я предупреждал, что он чреват проблемами. Второй путь — классика. Ввести регистр состояния. При начале транзакции взводить сигнал BSY, при её завершении — сбрасывать. И возложить ответственность за всё на логику мастера шины (процессор Nios II или мост JTAG). Каждый из вариантов имеет свои достоинства и свои недостатки. Раз мы уже делали варианты с задержками шины, давайте сегодня, для разнообразия, сделаем всё через регистр состояния.
Проектируем основной автомат
Первое, на что хотелось бы обратить внимание — мои любимые RS-триггеры. У нас есть два автомата. Первый обслуживает шину AVALON_MM, второй — интерфейс ULPI. Мы выяснили, что связь между ними идёт через пару флагов. В каждый флаг может писать только один процесс. Каждый автомат реализуется своим процессом. Как быть? С некоторых пор я просто стал добавлять RS-триггер. У нас два бита, значит их должны вырабатывать два RS-триггера. Вот они:
// Формирование регистра статуса
always_ff @(posedge ulpi_clk)
begin
// Приоритет у сброса выше
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
// Приоритет у сброса выше
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
Один процесс взводит reg_served, второй — have_reg. А RS-триггер в своём собственном процессе на их основе формирует сигнал write_busy. Аналогично, из read_finished и reg_request формируется read_busy. Можно это делать и иначе, но на данном этапе творческого пути, мне нравится именно такой метод.
Вот так устанавливаются флаги BSY. Жёлтый – для процесса записи, голубой – для процесса чтения. Верилоговский процесс имеет одну очень интересную особенность. В нём можно присваивать значения не один, а несколько раз. Поэтому, если я хочу, чтобы какой-то сигнал взлетал на один такт, я зануляю его в начале процесса (мы видим, что оба сигнала там занулены), а в единицу выставляю по условию, которое выполняется на протяжении одного такта. Вход в условие, перекроет значение по умолчанию. Во всех остальных случаях – будет работать именно оно. Таким образом, запись в порт данных инициирует взлёт сигнала have_reg на один такт, а запись бита 0 в порт управления – взлёт сигнала reg_request.

// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
// Назначение вещей по умолчанию, они могут быть перекрыты
// внутри условия сроком на один такт
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
// Запись в регистр данных требует сложной работы
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
// Младший бит регистра инициирует процесс чтения
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
Как мы видели выше, одного такта достаточно, чтобы соответствующий RS-триггер установился в единицу. И с этого момента из регистра статуса начинает читаться установленный сигнал BSY:

// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
// Регистр адреса (чисто для самоконтроля)
0 : readdata <= {26'b0, addr_to_ulpi};
// Регистр данных
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - регистр управления, а он - только на запись
// Регистр статуса
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
Собственно, так непринуждённо мы познакомились с процессами, обслуживающими работу с шиной AVALON_MM.
Давайте я также напомню про принципы работы с шиной ulpi_data. Эта шина двунаправленная. Поэтому следует применять стандартный приём для работы с ней. Вот так объявлен соответствующий порт:
inout [7:0] ulpi_data,
Читать из этой шины мы можем, а вот писать напрямую – нельзя. Вместо этого, мы заводим копию для записи
logic [7:0] ulpi_d = 0;
И подключаем эту копию к основной шине через такой мультиплексор:
// Так традиционно назначается выходное значение inout-линии
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
Логику работы основного автомата я постарался по максимуму прокомментировать внутри Verilog кода. Как я и предполагал по ходу разработки графа переходов, при реальной реализации, логика в несколько изменилась. Часть состояний была выкинута. Тем не менее, сравнивая граф и исходный текст, надеюсь, вы поймёте всё, что там сделано. Поэтому я не буду рассказывать про этот автомат. Лучше приведу для справки полный текст модуля, актуальный на момент до модификации по результатам практических опытов.
module ULPIhead
(
input reset,
output clk66,
// AVALON_MM
input [1:0] address,
input write,
input [31:0] writedata,
input read,
output logic [31:0] readdata = 0,
// AVALON_ST
input logic source_ready,
output logic source_valid = 0,
output logic [15:0] source_data = 0,
// ULPI
inout [7:0] ulpi_data,
output logic ulpi_stp = 0,
input ulpi_nxt,
input ulpi_dir,
input ulpi_clk,
output ulpi_rst
);
logic have_reg = 0;
logic reg_served = 0;
logic reg_request = 0;
logic read_finished = 0;
logic [5:0] addr_to_ulpi;
logic [7:0] data_to_ulpi;
logic [7:0] data_from_ulpi;
logic write_busy = 0;
logic read_busy = 0;
logic [7:0] ulpi_d = 0;
logic force_reset = 0;
// Формирование регистра статуса
always_ff @(posedge ulpi_clk)
begin
// Приоритет у сброса выше
if (reg_served)
write_busy <= 0;
else if (have_reg)
write_busy <= 1;
// Приоритет у сброса выше
if (read_finished)
read_busy <= 0;
else if (reg_request)
read_busy <= 1;
end
// Обслуживание AVALON_MM на чтение
always_comb
begin
case (address)
// Регистр адреса (чисто для самоконтроля)
0 : readdata <= {26'b0, addr_to_ulpi};
// Регистр данных
1 : readdata <= {23'b0, data_from_ulpi};
// 2 - регистр управления, а он - только на запись
// Регистр статуса
3 : readdata <= {30'b0, (reg_request | read_busy), (have_reg | write_busy)};
default: readdata <= 0;
endcase
end
// Обслуживание AVALON_MM на запись
always_ff @(posedge ulpi_clk)
begin
// Назначение вещей по умолчанию, они могут быть перекрыты
// внутри условия сроком на один такт
have_reg <= 0;
reg_request <= 0;
if (write == 1)
begin
case (address)
0 : addr_to_ulpi <= writedata [5:0];
// Запись в регистр данных требует сложной работы
1 : begin
data_to_ulpi <= writedata [7:0];
have_reg <= 1;
end
2 : begin
// Младший бит регистра инициирует процесс чтения
reg_request <= writedata[0];
force_reset = writedata [31];
end
3: begin end
endcase
end
end
// Самый главный автомат
enum {idle,
wait1,wr_st,
wait_nxt_w,hold_w,
wait_nxt_r,wait_dir1,latch,wait_dir0
} state = idle;
always_ff @ (posedge ulpi_clk)
begin
if (reset)
begin
state <= idle;
end else
begin
// Присвоение сигналов по умолчанию
source_valid <= 0;
reg_served <= 0;
ulpi_stp <= 0;
read_finished <= 0;
case (state)
idle: begin
if (ulpi_dir)
state <= wait1;
else if (have_reg)
begin
// Как я и рассуждал в документе, команду
// мы выставим прямо тут, не будем плодить
// состояния
ulpi_d [7:6] <= 2'b10;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_w;
end
else if (reg_request)
begin
// Логика - как для записи
ulpi_d [7:6] <= 2'b11;
ulpi_d [5:0] <= addr_to_ulpi;
state <= wait_nxt_r;
end
end
// Здесь мы просто пропускаем такт TURN_AROUND
wait1 : begin
state <= wr_st;
// Начиная со следующего такта, можно ловить данные
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end
// Пока не изменится сигнал DIR - гоним данные в AVALON_ST
wr_st : begin
if (ulpi_dir)
begin
// На следующем тактеа, всё ещё ловим данные
source_valid <= 1;
source_data <= {7'h0,!ulpi_nxt,ulpi_data};
end else
// В документе было ещё состояние wait2,
// но я решил, что оно - лишнее.
state <= idle;
end
wait_nxt_w : begin
if (ulpi_nxt)
begin
ulpi_d <= data_to_ulpi;
state <= hold_w;
end
end
hold_w: begin
// при моделировании выяснилось, что ULPI может
// быть не готова принимать данные. и снять NXT
// Добавил условие...
if (ulpi_nxt) begin
// Всё, по AVALON_MM можно принимать следующий байт
reg_served <= 1;
ulpi_d <= 0; // Шину в idle
ulpi_stp <= 1; // На один такт взвели STP
state <= idle; // А потом - уйдём в состояние idle
end
end
// От состояния STPw я решил отказаться...
// ...
// Это уже начало чтения. Ждём, когда скажут NXT
// И тем самым подтвердят, что наша команда распознана
wait_nxt_r : begin
if (ulpi_nxt)
begin
ulpi_d <= 0; // Номер регистра можно убирать
state <= wait_dir1;
end
end
// Ждём, когда нам выдадут данные
wait_dir1: begin
if (ulpi_dir)
state <= latch;
end
// Тут мы защёлкиваем данные
// и без каких-либо условий идём дальше
latch: begin
data_from_ulpi <= ulpi_data;
state <= wait_dir0;
end
// Ждём, когда шина вернётся к чтению
wait_dir0: begin
if (!ulpi_dir)
begin
state <= idle;
read_finished <= 1;
end
end
default: begin
state <= idle;
end
endcase
end
end
// Так традиционно назначается выходное значение inout-линии
assign ulpi_data = (ulpi_dir == 0) ? ulpi_d : 8'hzz;
// reset мог прийти извне, а могли его и мы сформировать
assign ulpi_rst = reset | force_reset;
assign clk66 = ulpi_clk;
endmodule
Руководство программиста
Порт адреса регистра ULPI(+0)
В порт со смещением +0 следует помещать адрес регистра ULPI шины, с которым будет идти работа
Порт данных регистра ULPI (+4)
При записи в данный порт: автоматически начинается процесс записи в регистр ULPI, адрес которого был задан в порту адреса регистра. Запрещается писать в данный порт, пока не завершился процесс предыдущей записи.
При чтении: из данного порта будет возвращено значение, полученное в результате последней операции чтения регистра ULPI.
Порт управления ULPI (+8)
На чтение всегда равен нулю. На запись назначение битов следующее:
Бит 0 – При записи единичного значения, инициирует процесс чтения регистра ULPI, адрес которого задан в порту адреса регистра ULPI.
Бит 31 – При записи единицы подаёт сигнал RESET на микросхему ULPI.
Остальные биты зарезервированы.
Порт состояния (+0x0C)
Доступен только на чтение.
Бит 0 – WRITE_BUSY. Если равен единице – идёт процесс записи в регистр ULPI.
Бит 1 – READ_BUSY. Если равен единице – идёт процесс чтения из регистра ULPI.
Остальные биты зарезервированы.
Заключение
Мы познакомились с методикой физической организации головы USB-анализатора, спроектировали базовый автомат для работы с микросхемой ULPI и реализовали черновой SystemVerilog-модуль этой головы. В последующих статьях мы рассмотрим процесс моделирования, проведём моделирование этого модуля, а затем проведём практические опыты с ним, по результатам которых начисто доработаем код. То есть, до конца нам предстоит ещё минимум четыре статьи.


