
Data Science «на пальцах». Статистика — это наука менять свой взгляд на вещи в условиях неопределенности
Что такое статистика? Какой-то устаревший способ погрязнуть в данных. Ага. На 100% технически правильное определение. Теперь давайте посмотрим, что есть статистика как дисциплина.
Статистика — это наука о том, как менять свои представления.
Принимать решения, основываясь на фактах (параметрах), и так достаточно сложно, но — проклятие! — иногда у нас даже фактов нужных нет. Вместо этого то, что мы знаем (выборка), отличается от того, что мы хотели бы знать (совокупность). Вот что значит попасть в неопределенность.
Статистика — это наука о том, как менять свои решения в условиях неопределенности. Как вы можете думать? Выбирать действия по умолчанию или следовать по пути априорных убеждений. Но что делать, если у вас в голове чистый лист? Почитайте лучше это.
Байесианцы меняют свое мнение насчет представлений.
Байесовская статистика это школа мысли, которая использует данные, чтобы обновить ваше представление. Байесианцы предпочитают сообщать результаты, используя доверительный интервал (два числа, которые интерпретируются как “Я считаю, что ответ находится где-то между этим и этим”).
Приверженцы частотной статистики меняют свое мнение насчет действий.
Частотная статистика использует данные, чтобы изменить ваше мнение о действиях. Вам не нужно иметь каких-либо представлений, чтобы совершить действия по умолчанию. Это в принципе то, как вы поступите, если не проанализируете данные. Частотная (она же классическая) — это статистика, с которой вы чаще сталкиваетесь в природе, поэтому давайте присвоим ей имя классической до конца этой статьи.
Гипотезы — это описания того, как может выглядеть мир.
Нулевая гипотеза описывает все миры, где выбор в пользу действия по умолчанию будет иметь удачным исход; альтернативная гипотеза описывает все остальные миры. Если я смогу вас убедить — используя данные! — что вы живете в мире не нулевых гипотез, то вам лучше передумать и предпринять альтернативные действия.
Например: “Мы можем пойти на занятие вместе (действие по умолчанию), если вам обычно требуется меньше 15 минут, чтобы подготовиться (нулевая гипотеза), но если доказательства (данные) предполагают, что вам нужно больше времени (альтернативная гипотеза), вы можете пойти один, потому что я пошел (альтернативное действие).”
Быстрая проверка: “Мои доказательства превращают нулевую гипотезу в нелепость?”
Вся проверка гипотез сводится к вопросу: делают ли мои доказательства нулевую гипотезу нелепой? Отказ от нулевой гипотезы означает, что мы что-то узнали и должны изменить свое мнение. Не опровержение значит, что мы не узнали ничего интересного. Это как оказаться в лесу, не встретить там людей и сделать вывод, что на планете нет больше людей. Это всего лишь значит, что мы не узнали ничего интересного о существовании людей. Вам грустно, что мы ничего не узнали? Так быть не должно, потому что у вас есть прекрасный страховой полис: вы точно знаете, какие действия предпринять. Если вы ничему не научились, у вас нет причин менять свои представления — продолжайте следовать действиям по умолчанию.
Итак, как мы поймем, что узнали нечто интересное… нечто не соответствующее миру, в котором мы хотим продолжать выполнять наши действия по умолчанию? Чтобы получить ответ, мы можем взглянуть на p-значение или на достоверный интервал.
Р-значение в периодической таблице — элемент неожиданности.
P-значение говорит: «Если я живу в мире, в котором должен принимать такое-то действие по умолчанию, насколько тогда не удивительны мои доказательства?” Чем ниже p-значение, тем больше данные кричат: „Ого, это же удивительно! Может, вам стоит изменить ваше мнение!”
Чтобы пройти тест, сравните p-значение с порогом, называемым уровнем значимости. Это рычаг, с помощью которого вы можете регулировать количество риска. Максимальная вероятность — по глупости покинуть уютное, нагретое местечко в виде действия по умолчанию. Если установите уровень значимости равным 0, значит вы не хотите совершать ошибку и неоправданно отказываться от действия по умолчанию. Крутим рычаг вниз! Не анализируйте данные, просто выполняйте действия по умолчанию. (Но это также может значит, что вы в конечном итоге тупо НЕ откажетесь от плохого действия по умолчанию.)
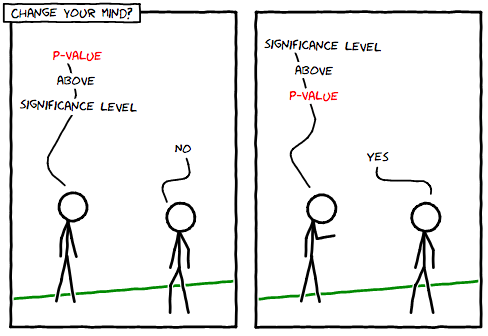
Как использовать p-значения, чтобы узнать результат проверки гипотезы. (Никто не заподозрит, что мой xkcd-подделка)
Достоверный интервал — это просто способ узнать результаты проверки гипотезы. Чтобы его использовать, проверьте, совпадает ли он с вашей нулевой гипотезой. Если да, совпадает, то узнавать нечего. Если нет — примите другое решение.
Меняйте мнение только в том случае, если достоверный интервал не совпадает с вашей нулевой гипотезой.
Хотя техническое значение термина “достоверный интервал” немного странновато (я расскажу вам подробно о нем в следующем посте, он определенно не так прост как доверительный интервал, с которым мы познакомились ранее), он также обладает двумя полезными свойствами, которые аналитики любят использовать при описании своих данных: (1) всегда есть лучшее предположение и (2) с появлением данных интервал становится уже. Берегитесь, ни интервал, ни p-значение не были созданы не для того, чтобы говорить о них было приятно, поэтому не ожидайте содержательных определений. Это просто способ обобщить результаты тестов. (Если вы ходили на занятия и не могли запомнить определения, то вот оно почему. От имени статистики: это не вы, это все я).
Какой в этом смысл? Если вы проводите тестирование так, как я только что описала, математика гарантирует, что ваш риск совершить ошибку ограничен выбранным вами уровнем значимости (именно поэтому важно, чтобы вы, эм, выбирали его… математика и существует для того, чтобы гарантировать выбранные вами параметры риска, и будет немного бессмысленно, если вы не потрудитесь их все-таки выбрать).
Математика — это построение игрушечной модели вселенной нулевых гипотез. Так вы получаете p-значение.
Математика — это все о создании и изучении игрушечных вселенных (как это круто, да, товарищи, одержимые манией величия?! Очень круто!) чтобы проверить, насколько вероятно возникновение наборов данных, подобных вашим. Если едва ли ваша игрушечная модель вселенной нулевой гипотезы даст данные подобные тем, которые вы получили из реального мира, то тогда ваше p-значение будет низким, и в итоге вы отвергнете нулевую гипотезу… надо вам передумать!
К чему все эти безумные формулы, вероятности и распределения? Благодаря им мы излагаем правила, регулирующие вселенную нулевой гипотезы. Мы можем выяснить, является ли эта вселенная местом, которое выдает данные, похожие на те, что вы получили в реальной жизни. Если нет, то вы кричите: “Смешно! Голову с плеч!” А если да, то просто пожимаете плечами и ничего нового не получаете. Подробнее об этом я расскажу в следующем посте. А пока, просто поразмыслите о математике, как об инструменте создания маленьких игрушечных миров, чтобы мы могли посмотреть, выглядит ли наш набор данных в них разумным. P-значение и достоверный интервал — это способы обобщить всю эту информацию для, поэтому вам не нужно жмуриться от многословного описания вселенной. Здесь кроется развязка: используйте их, чтобы проверить, стоит ли следовать действиям по умолчанию. И работа сделана!
А мы сделали домашнее задание? Вот в чем меры мощности.
Подождите-ка, а мы выполнили домашнюю работу, чтобы убедиться, что действительно собрали достаточно доказательств, чтобы появилась честная возможность изменить свое мнение? Вот в чем заключается концепция мощности в статистике. Очень легко не найти никаких меняющих мнение доказательств… просто не искать их. Чем выше мощность, тем больше возможностей изменить свое мнение, в случае, если это будет правильным. Мощность — это вероятность правильного отказа от действия по умолчанию.
Когда мы не узнаем ничего нового и продолжаем делать, что делали, то, имея большую мощность, нам становится проще относится к нашему процессу. По крайней мере, мы сделали домашнее задание. Если бы у нас не было вообще никакой мощности, мы бы знали, что нет нужды менять свое мнение. С таким же успехом можно не утруждать себя анализом данных.
Используйте анализ мощности, чтобы проверить, достаточно ли данных вы предусмотрели, прежде чем начинать.
Анализ мощности — это способ проверить, какую мощность вы ожидаете получить для данного объема данных. Вы используете его, чтобы спланировать свои исследования, прежде чем начать. (Все довольно просто; в следующем посте я покажу вам, что на самом деле нужно всего несколько циклов.)
Неопределенность означает, что вы можете прийти к неправильному выводу, даже если у вас лучшая математика в мире.
Чего нет в статистике? Волшебной магии, которая может неопределенность превратить в определенность. Нет такой магии, которая могла бы сделать это; вы все еще можете допустить ошибку. К слову об ошибках, вот две ошибки, которые вы можете допустить в частотной статистике. (Байесианцы не ошибаются. Шучу! Ну, вроде того.)
Ошибка I типа — отказаться по глупости от действия по умолчанию. Эй, вы же говорили, что вам было удобно следовать действию по умолчанию, и теперь, после всех своих расчетов, отказались от него. Ой! Ошибка II типа — по глупости не отказаться от действий по умолчанию. (Мы, статистики, крайне изобретательны в придумывании названий. Угадайте, какая ошибка хуже. Тип I? Ага. Очень креативно.)
Ошибка I типа — поменять мнения, когда не следовало бы.
Ошибка II типа — не поменять мнения, когда следовало бы.
Ошибка I типа похожа на осуждение невиновного, а ошибка II типа — на неспособность осудить виновного. Это равновесно вероятные ошибки (что упрощает суд над виновным, также упрощает его и над невиновным), если только у вас не будет больше доказательств (данных!), тогда уже вероятность допустить ошибку становится ниже, и дела идут на поправку. Вот почему статистики хотят, чтобы у вас было много, РЕАЛЬНО МНОГО данных! Всё идет хорошо, когда вы располагаете большим количеством данных.
Чем больше данных, тем ниже вероятность прийти к неверному выводу.
Что такое множественная проверка гипотез? Вы должны проводить тестирование другим, скорректированным образом, если собираетесь задавать несколько вопросов одного и того же набора данных. Если вы продолжите снова и снова подвергать невиновных подозреваемых суду (прощупывая почву своих данных), в конце концов, из-за случайного совпадения кто-нибудь да окажется виновным. Термин статистическая значимость не означает, что в рамках вселенной произошло что-то важное. Это всего лишь значит, что мы поменяли мнение. Возможно, на неправильное. Будь проклята эта неопределенность!
Не тратьте время, старательно отвечая на неправильные вопросы. Пользуйтесь статистикой с умом (и только при необходимости).
Что такое ошибка III типа? Это своего рода статистическая шутка: она относится к правильному отклонению неправильной нулевой гипотезы. Другими словами, использование правильной математики для ответа на неправильный вопрос.
Лекарство от задавания неправильных вопросов и неправильных ответов на них можно найти, заглянув в Decision Intelligence. Это новая дисциплина, которая занимается наукой о данных и применяет ее для решения бизнес-задач и поиска правильных решений. С помощью decision intelligence вы повысите свой иммунитет к ошибкам III типа и бесполезной аналитике.
Итак, подытожим: статистика — это наука о том, как менять свои представления. Существует две школы мысли. Наиболее популярная — частотная статистика — проверяет, следует ли отказаться от действия по умолчанию. Байесовская статистика занимается априорным мнением и его модернизацией с помощью новых данных. Если у вас в голове чистый лист, прежде чем начать, взгляните на данные и просто прислушайтесь к своей интуиции.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Курс “Профессия Data Scientist» (24 месяца)
- Курс «Профессия Data Analyst» (18 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
Читать еще
Похожие статьи
 Резервуарные вычисления: как работает нейросеть, которую почти не учат
Резервуарные вычисления: как работает нейросеть, которую почти не учат Подземные города: от древности до недалекого будущего
Подземные города: от древности до недалекого будущего Легендарные краны Demag на Чернобыльской АЭС
Легендарные краны Demag на Чернобыльской АЭС Шейп-динамика: как убрать время из уравнений гравитации
Шейп-динамика: как убрать время из уравнений гравитации Астрофизика: обзор июньских препринтов 2026 года
Астрофизика: обзор июньских препринтов 2026 года Обзор небезынвестного суперстрата Cort G250 Spectrum
Обзор небезынвестного суперстрата Cort G250 Spectrum О микроводорослях, недостижимых идеалах и оплачиваемом веганами будущем
О микроводорослях, недостижимых идеалах и оплачиваемом веганами будущем