
Я начал писать этот текст уже давно, так что он не планировался как политически актуальный. Но так вышло, что именно в эти дни у СМИ появился инфоповод, связанный с малыми (миноритарными) языками России. Возможно, что исследование, о котором я пишу ниже, что-то кому-то в этом смысле прояснит.
Сколько в России языков?
Это не так просто осознать, но в России говорят на внушительном числе языков. Более того, в России говорят на таких языках, которые больше нигде не распространены. Скажем, в России обитают миллионы украинцев и узбеков, вместе с тем существуют и суверенные государства Украина и Узбекистан, где соответствующие языки являются государственными. А вот в России говорят на башкирском, тувинском, удмуртском и многих (действительно многих) других языках, у которых своего государственного статуса больше нигде нет.
Государственный статус — это важно. В эпоху глобализации языкам, чтобы выжить, нужна поддержка, которая позитивно влияет на печать, масс-медиа, искусство, в конечном счёте — на желание и возможность людей говорить на родном языке.
А насколько эти языки адаптировались к новым цифровым реалиям? Правда ли, что на них говорят только в отдалённых горных аулах? Или всё-таки они являются полноправным способом онлайн-общения? Несколько лет назад мы с коллегами решили это выяснить.
Сначала это было исследование в рамках ныне уже не существующего Центра изучения Интернета и общества РЭШ (сейчас он благополучно преобразован в Клуб любителей Интернета и общества), затем мы организовали исследовательский проект в магистратуре Школы лингвистики НИУ ВШЭ, и, в общем, добились успеха. Все результаты представлены на специальном сайте Языки России, но о самом интересном, о том, что мы делали и как (а также о том, что получилось), я расскажу здесь.
Прежде всего, требовалось установить, сколько вообще в России языков, и что это за языки. Никакого общепринятого списка у лингвистов не оказалось: про некоторые языки неизвестно, жив ли ещё хоть один носитель, про некоторые нет согласия, действительно ли это язык, или на самом деле он диалект другого языка. Да и чётких критериев отличения одного от другого нет. Есть шуточный: «язык — это диалект с армией и флотом», но при всём остроумии этого высказывания Вайнрайха есть достаточно контрпримеров: у Бразилии есть армия и флот, но нет своего языка (бразильцы пользуются португальским, языком своей бывшей метрополии), более того, всего лишь диалектом, а никаким не собственным языком пользуются и американцы — обладатели самой мощной армии в мире. Ни армии, ни флота нет у Исландии (только корабли береговой охраны), зато на особость их языка никто не покушается (хотя никто не спорит и с тем, что он родственник современного норвежского).
Словом, задача оказалась непростой. Особенную сложность составили языки Дагестана. Языков (настоящих языков, не диалектов! их носители не понимают друг друга) там так много, что разобраться в этом можно только после консультаций со специалистами.
Ещё мы решили вывести за пределы своего списка титульные языки других государств. Действительно, если целая страна за пределами России говорит на каком-то языке, то, скорее всего, государственный ресурс используется и для поддержки языка. Считать такой язык языком России можно, но оценивать его представленность в Интернете по сравнению с другими языками, не подпитывающимися из-за границы, было бы некорректно: ингушский и казахский будут в совсем разных весовых категориях. Так, за бортом нашего исследования оказался осетинский: несмотря на то, что в России есть целый титульный регион, где говорят на осетинском, существует и признанная Россией отдельная страна, Южная Осетия, для которой этот язык государственный. Строго говоря, в Южной и Северной Осетии говорят на разных диалектах, иронском и дигорском. Но автоматически, компьютерно, различить их очень сложно. Так что лучше считать их одним языком, не принадлежащим к классу языков России.
Ещё один казус связан с идишем. В России номинально тоже есть регион, в котором должны проживать носители идиша — Еврейская автономная область. В то же время наши эксперты разъяснили нам, что в ЕАО носителей идиша почти не осталось, а все тексты в Интернете на этом языке пишутся почти исключительно в Израиле и в США. Так что анализировать представленность идиша в Интернете как языка России глупо. Это помимо того, что мы бы столкнулись с головной болью, связанной с многообразием вариантов правописания. Вот несколько релевантных ссылок про это: [1], [2], [3].
Итак, с языками мы определились. Их получилось 96.
абазинский
аварский
агульский
адыгейский
алеутский
алюторский
амузги-ширинский
андийский
арчинский
ахвахский
багвалинский
башкирский
бежтинский
ботлихский
бурятский
вепсский
верхневуркунский
водский
гапшиминский
гинухский
годоберинский
горномарийский
гунзибский
ижорский
ингушский
ительменский
кабардино-черкесский
кадарский (возможно, наречие даргинского)
кайтагский
калмыцкий
каратинский
карачаево-балкарский
карельский
кетский
кольско-саамский
коми-зырянский
коми-пермяцкий
корякский
кубачи-аштинский
кумыкский
лакский
лезгинский
лесной ненецкий
лугово-восточный марийский
мансийский
мегебский
мокша-мордовский
муиринский
нанайский
нганасанский
негидальский
нивхский
ногайский
орокский
рутульский
санжи-ицаринский
северноалтайский
северноюкагирский (тундровый, вадульский)
северодаргинский (вкл. литературный даргинский)
селькупский
сойотско-цатанский
табасаранский
танты-сирхинский (возможно, один язык с верхневуркунским)
татарский
татский (под угрозой исчезновения)
тиндинский
тофаларский
тубаларский
тувинский
тундровый ненецкий
удинский
удмуртский
удэгейский
ульчский
усиша-цудахарский
хакасский
хантыйский
хваршинский
цахурский
цезский
цыганский
чамалинский
чеченский
чирагский
чувашский
чукотский
чулымский
шорский
эвенкийский
эвенский
энецкий
эрзя-мордовский
эскимосский
южноалтайский
южноюкагирский (колымский, одульский)
якутский
Как теперь их искать в Сети? Можно выкачать весь Интернет и попробовать найти нужные тексты в получившейся коллекции… Но постойте, ведь на самом деле нельзя выкачать весь Интернет. То есть можно, если ты крупная IT-компания с соответствующим серверным парком и командой разработчиков. А если в твоём распоряжении маленький университетский коллектив, то тут и думать не о чем. С другой стороны, и скачивать ничего на этом этапе не нужно, ведь всю сеть уже обошли поисковые роботы. Нужно только задать поисковикам правильные запросы. Правда, поисковики не любят автоматические обращения. Но если очень попросить, то можно воспользоваться, например, Яндекс.XML, который имеет ограничения на число запросов, но всё-таки это уже не то же самое, что руками работать с поисковой выдачей.
Слова-маркеры
Но что спрашивать? Нужны слова — это ясно. Поисковые индексы формируются из слов, так что необходимо подобрать такие слова для каждого искомого языка, которые бы встречались именно в этом языке и не совпадали по составу букв ни с одним словом в каком-то другом языке. В каком-то смысле поиск языков России должен быть устроен проще, ведь почти все языки из нашего списка обладают письменностью на основе кириллицы, а это случай для мировых языков сравнительно редкий, так что вероятность совпадения двух слов из разных языков резко снижается: можно будет перепутать только слова из языков с постсоветского пространства, а слова из каких-нибудь языков Океании не будут создавать шума.
Но где взять слова? Если опять обратиться к лингвистам, то они подскажут, что есть старое и заслуженное издание — Гиляревский Р. С., Гривнин В. С. Определитель языков мира по письменностям (М., 1961 для второго издания). Каждому языку из описанных (около 200) посвящена одна страничка, где по одному шаблону приводится название языка, два коротких текста на них, алфавит, его основные особенности и сведения о числе носителей и генетической принадлежности.
Вроде бы книжка для наших целей вполне бесполезная, но на стр. 259 есть дополнительный раздел «Характерные буквосочетания и служебные слова некоторых языков». Кажется, это то, что нужно, но к сожалению, слова, которые там приводятся, очень короткие и по буквенному составу совпадают со словами из русского языка. Например, для балкарского это слово «бла», которое при поиске выдаст чудовищное количество мусора, совсем никак с балкарским языком не соотносящегося (не только бла-бла, но и «Беспилотный летательный аппарат»), а для горного марийского — «дон» (в поиске будет ещё хуже). Ну и всё-таки слова в этом разделе, скорее, редкость. А по буквосочетанию в Яндексе не поищешь.
Так предложили бы сделать лингвисты. У компьютерщиков было бы другое решение. Почему бы не взять Википедию (ведь есть же википедии на языках народов России), не сделать из неё частотник, пересечь словари, найти таким образом уникальные токены, и их использовать для поисковых запросов? К сожалению, это тоже не сработает. Во-первых, википедии есть не для всех языков России. «Настоящих» википедийных разделов, не из инкубатора, насчитывается только 22. Инкубатор добавляет ещё 41. Но обычно это максимум несколько десятков очень коротких текстов, то есть статистически значимых результатов они не дадут. Вот инкубатор с табасаранской википедией (5 статей). Вот ногайский инкубатор (23 статьи). Причём в некоторых вообще нет никакого текста, а вот тамошняя статья про башкир. И так далее.
Но и настоящие (не инкубационные) википедии не могут служить хорошим источником. Потому что они… написаны не людьми! Самые большие википедии на языках народов России страдают от того, что википедийщики называют «арахнофилией». то есть автоматическим заполнением раздела сгененированными по шаблону статьями, в которые вставлены какие-нибудь числовые данные из открытой базы или реестра. Скажем, башкирская и татарская википедии на очень маленький процент «человеческие», там десятки тысяч автоматических статей про реки и озёра. Попробуйте пощёлкать ссылку «случайная статья» в башкирской википедии, сколько раз из 10 вы попадёте не на «водную статью» (можно искать по ключевому слову «йылға» “река”)? Сейчас ситуация несколько выправилась, появились ещё статьи про страны и населённые пункты, но пять лет назад «водная» тематика была в 8 случаях из 10. Я прощёлкал сейчас, получилось 7:3 в пользу рек. А что у вас?
Всё бы ничего, но частотные слова в таких текстах вовсе не частотные слова в языке. Как выглядит «нормальный» частотный словарь, составленный на текстах естественного происхождения? Первые пару десятков позиций там занимают разные служебные слова, которые в разы чаще встречаются в речи, чем любые знаменательные. Вот частотный словарь для русского языка. Первое существительное (год) появляется там в конце третьего десятка. А перед этим всё сплошь — союзы, предлоги, местоимения и частицы. А вот частотный словарь татарской википедии за 2013 год:
| № | Словоформа | Перевод/значение | Встречаемость |
|---|---|---|---|
| 1 | елга | река | 132567 |
| 2 | бассейны | бассейн | 75706 |
| 3 | су | вода | 54689 |
| 4 | буенча | по | 48838 |
| 5 | Русия | Россия | 48722 |
| 6 | урнашкан | расположенный | 38043 |
| 7 | км | километр | 36962 |
| 8 | Һәм | и | 27231 |
| 9 | кече | малый | 27203 |
| 10 | дәүләт | государство | 26888 |
Тут только два служебных слова, из них только одно — Һәм “и” — действительно особенно часто встречается в настоящих текстах. Остальные, конечно, попали в перечень только из-за специфики исходной выборки.
Выход перед нами был только один: собрать слова для задания поисковых запросов вручную для каждого языка. Это экспертная работа, нужно смотреть в словари и грамматики, потом вбивать слова-кандидаты в поиск и смотреть на результат и оценивать, насколько много выходит мусора. При этом каждое слово должно удовлетворять двум обязательным критериям. Во-первых, оно должно быть частотным для своего языка. Поэтому татарское Һәм “и” подошло бы. Действительно, это слово есть в большинстве текстов на татарском языке, и запрос, который содержал бы это слово, позволил бы нам получить в выдачу и таким образом отловить большинство сайтов, на которых есть тексты на татарском языке. Во-вторых, такое слово должно быть уникальным, то есть быть в ходу только в этом языке, но ни в каком другом. С этой точки зрения Һәм, увы, «пролетает», потому что точно такое же слово есть и в башкирском.
Есть и ещё один нюанс. В алфавитах национальных языков много «специальных» символов, то есть букв, которые отсутствуют в алфавите русского языка, с помощью этих символов (как говорят лингвисты, «графем») записываются особые звуки (как говорят лингвисты, «фонемы») этих языков. Например, коми-зырянское слово таштöм содержит такой символ, далеко не самый экзотический из тех, что могут быть (другие примеры можно видеть в татарском списке «водных» слов выше).
Дело в том, что поскольку всей этой графической роскоши нет на стандартной русской клавиатуре, на которой все, в основном, и печатают, то и реальные пользователи не вводят на самом деле этих букв, заменяя их другими, похожими по написанию или по звучанию. Слово «таштöм» передают как «таштэм» или «таштом». В башкирском букву «ә» передают как «э» или «а», а букву «ҙ» как «з». Вот на КДПВ как раз слово «менан» на самом деле должно писаться «менән». Такой орфографический режим мы вслед за лингвистом А. А. Зализняком называем «бытовой системой письма». Примерно те же процессы (только без клавиатур и прочего ПО) Зализняк описал для древненовгородского диалекта, зафиксированного на берестяных грамотах.
Что это значит на практике? Что в идеале нужны не просто слова-маркеры, уникальные для этого языка и частотные в этом языке. Нужны ещё и такие слова, чтобы они не содержали этих «спецсимволов». Потому что в реальности такие символы пишут не все, и если отправлять поисковику запрос со словом в «правильной» графике, то полнота ответа получится так себе: нам не попадётся огромное число текстов, которые написаны в бытовой системе.
Кроме того, есть и более хитрые символы, например, «I»: «палочка Яковлева» (в разных кавказских языках он обозначает или гортанную смычку, или т.н. «абруптивный» звук). Часто в бытовой системе её заменяют единицей, но бывает, что пишут и символ «|», вертикальная черта, который используется как поисковый оператор «или» (поиск страниц содержащих любое из слов связанных этим оператором.).
Короче, это не просто. Но мы составили такие списки слов-маркеров для большинства интересовавших нас языков. И это единственное, что мы не выкладываем в открытый доступ, потому что такие слова ещё могут пригодиться для поиска текстов, а этот список очень легко вандализировать, например, если кто-нибудь захочет использовать их для генерации поискового спама.
Поиск
Итак, у нас есть поисковые термины, отправляем их по очереди в Яндекс.XML и получаем выдачу. Тут тоже не всё так просто. Во-первых, Яндекс.XML ограничивает наши аппетиты 10 000 запросами в сутки. Не так уж и мало? Да, но выдаёт-то он ссылки постранично (по 10 на страницу) и переход на следующую страницу считается отдельным запросом…
Кроме того, мы всё равно получаем на выходе мусор. Даже по «хорошим» маркерам. Что у нас есть? Зеркала и дубли. Особенно много дублей Википедии. А зачем нам считать Википедию, если наша цель собрать все тексты на некотором языке? Ведь Википедию можно скачать одним кликом! Что ещё? Лингвистические научные статьи. Некоторый лингвист пишет статью на русском языке и приводит в пример предложение на каком-нибудь рутульском, и это предложение содержит наше слово-маркер. Такое тоже не годится, ведь перед нами на самом-то деле текст на русском языке. Или ещё это может быть словарь. Там тоже будет слово, которое мы искали, но не будет текста. Неожиданностью для нас стали музыкальные сайты. На них лежат mp3 многочисленных народных или авторских песен на малом языке. Текстов там тоже нет, но есть подходящие под запрос короткие фразы — названия музыкальных произведений. Для некоторых языков эти сайты настолько многочисленны, что забивают всю выдачу. Мы решили, что раз мы ищем тексты, это тоже не наши клиенты.
Надо как-то отсечь лишнее. Первый фильтр можно ввести ещё на этапе обращения к поисковику. Если маркеров для языка у нас несколько, то поймав какой-то домен подному, мы можем спросить у поисковой машины, встречаются ли на том же сайте и другие слова из нашего списка. Если да, то есть вероятность, что мы попали на тот самый, нужный нам сайт. Если же один маркер там есть, а остальные не представлены, то мы с высокой вероятностью держим в руках пустышку. Есть, например, замечательное хакасское слово «пазох» («опять»). Оно удовлетворяет всем перечисленным выше критериям слова-маркера. Но вот в чём штука. Когда пишут по-русски, иногда ошибаются и печатают вместо «пазух» (носа) — «пазох». Наш фильтр поможет понять, опечатка это в русском тексте, или и правда хакасский текст. Штука в том, что это дополнительные запросы, которых и так-то мало.
Не всё однозначно и со списком сайтов, на которых нашлись нужные нам тексты. Если мы планируем не просто найти эти сайты, но и выкачать их, чтобы составить корпус, то нам надо знать глубину, на которую потом следует производить выкачку. Мы поделили все найденные домены на три категории (всё это тоже можно узнать, задавая правильные запросы Яндексу).
В первую попали те, на которых много (предположительно — большинство) страниц содержат тексты на интересующем нас языке.
Во второй оказались те, на которых есть несколько (не слишком много по сравнению с общим числом страниц) документов на интересующем нас языке.
К третьей мы отнесли те огромные сайты с миллионами страниц, на которых в том числе есть и интересующий нас контент. Это Youtube (в подписи к какой-нибудь видеозаписи есть текст на «нашем» языке) или stihi.ru (там публикуются, например, чеченские поэты).
Кроме того, мы специально спрашивали у Яндекса про то, где он находит интересующие нас слова в социальной сети VK.com. Из полученных страниц отбирали только сообщества, потому что считали, что в среднем двуязычный пользователь, скорее, будет общаться на своём языке в специальном месте (в этом самом сообществе), а на собственной стене будет писать, скорее, по-русски, уважая чувства русскоязычных друзей. Это, конечно, не всегда так. Но в целом так.
Определение языка
В результате мы получили списки сайтов и сообществ в VK.com. Сейчас эти списки уже устарели: какие-то сайты пропали, какие-то добавились, гораздо интенсивнее происходит жизнь в vk.com. Но по состоянию на начало 2016 года это довольно правдивая информация о том, как устроен Интернет на малых языках России.
Следующим шагом было всё это скачать. С задачей мы в полной мере не справились. Выкучку многих десятков разнообразных сайтов для крупных языков вроде татарского или удмуртского, нам так и не удалось поставить на поток. Scrapy ломался, зависал. А вот сообщества из VK мы выкачали по API все и полностью.
Но выкачать мало. Нужно ещё определить, что именно мы скачали. Сайты, которые содержат интересующий нас контент, почти никогда не бывают моноязычными. Чтобы получить корпус текстов, которые затем смогли бы использовать лингвисты, а также чтобы понять, насколько тот или иной язык представлен в Интернете, нужно очистить полученные веб-страницы от обвязки и от текстов на других языках. Обычно в компьютерной лингвистике для этого применяется статистика распределения знаков (чаще — последовательностей знаков, ngram) в тексте. Если у нас уже есть какой-то корпус текстов на разных языках, мы можем натренировать на нём модель, и дальше успешно определять, какой язык перед нами. Но проблема в том, что у нас как раз такого заранее заданного корпуса нет. Мы только пытаемся его сделать.
Но если вдуматься, то всё-таки всё не совсем так. У нас, скорее всего, есть два языка, отличия между которыми мы должны найти. Один язык — некоторый малый язык (без разницы, якутский или чувашский), а второй — русский. Их мы и должны отделить друг от друга. В таком виде задача уже приобретает выполнимые очертания. Ведь русский-то язык у нас есть в качестве «подопытного» в большом количестве. То есть нам нужно про каждый, скажем, абзац текста сказать, написан он на русском языке или нет. Если не на русском, значит, это наш клиент.
Определялка не везде и не всегда работала хорошо, но в целом, скорее, удовлетворительно.
Результаты
Итак, у нас есть тексты. У нас есть данные о сайтах и сообществах. Что с ними теперь можно сделать?
Как минимум, можем выполнить самую базовую программу и отдать собранные тексты лингвистам. У нас уже есть корпуса бурятского, удмуртского, татарского, хакасского языков. Их можно пополнить «настоящими» текстами из дикой природы. Лингвисты такие любят.
Но ещё можно что-то попробовать понять про представленность самого языка в Сети. Много там текстов на этом языке или мало? А если сравнить с тем, как живёт язык в оффлайне, то его интернет-самочувствие выглядит так же или не так?
Сайты
Для начала посчитаем, сколько вообще сайтов (доменных имён) получается на каждый язык.
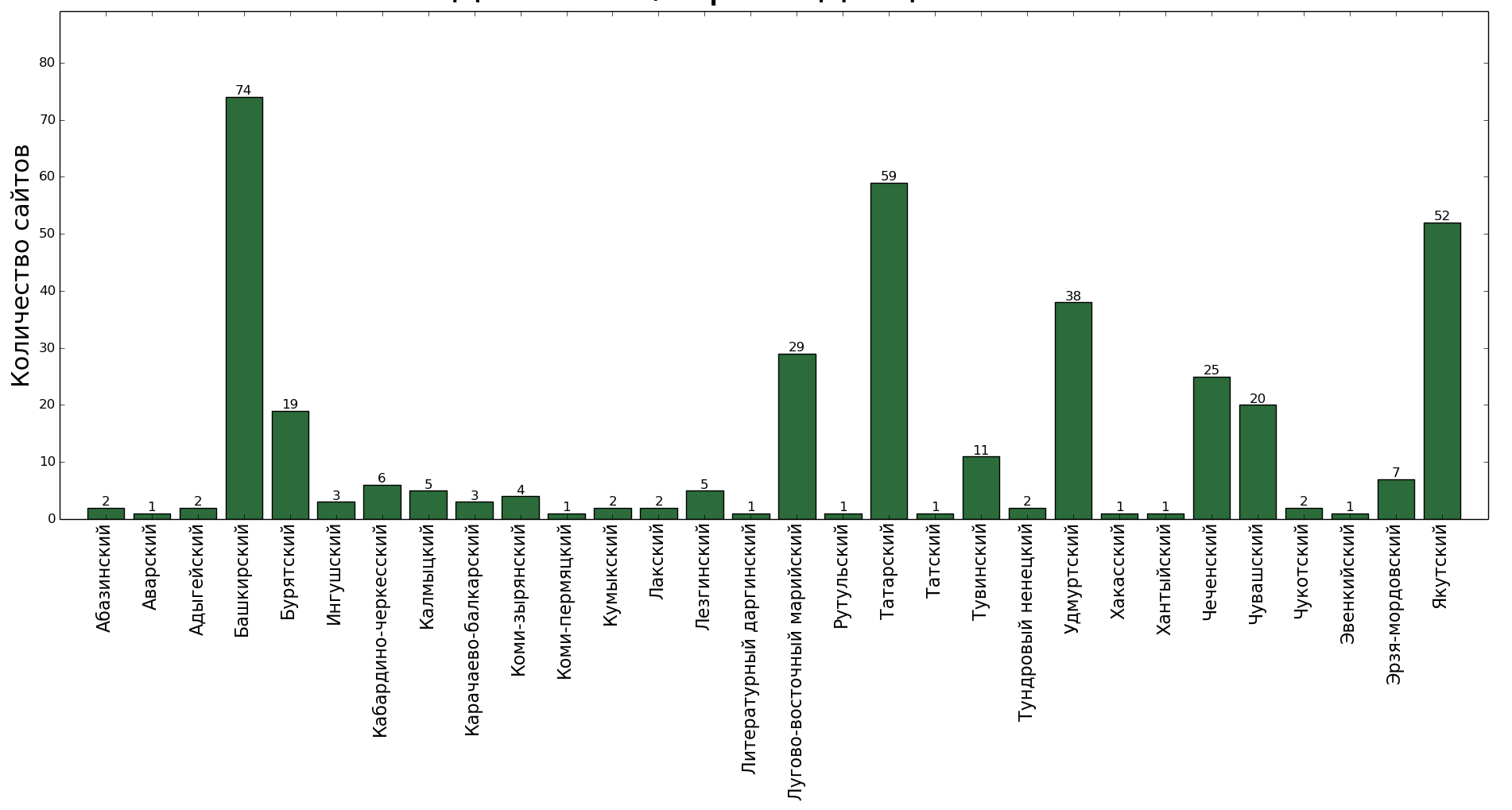
А кем они регистрируются? Это вообще всё частная или государственная инициатива — выкладывать тексты на малых языках в Интернете?
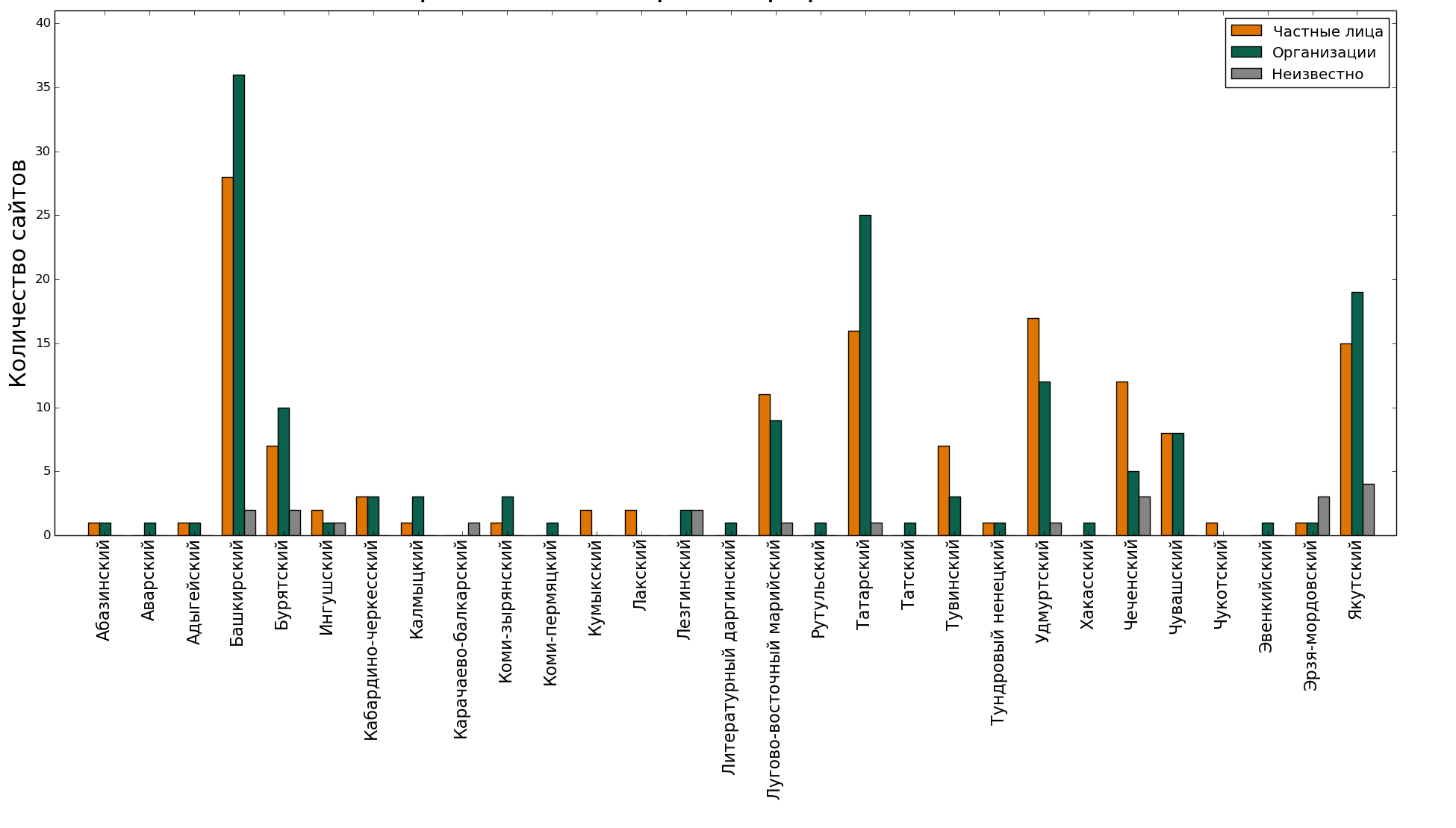
В принципе, какие-то активисты есть, но большей частью ответственность здесь на организациях.
А когда сайты регистрировались?
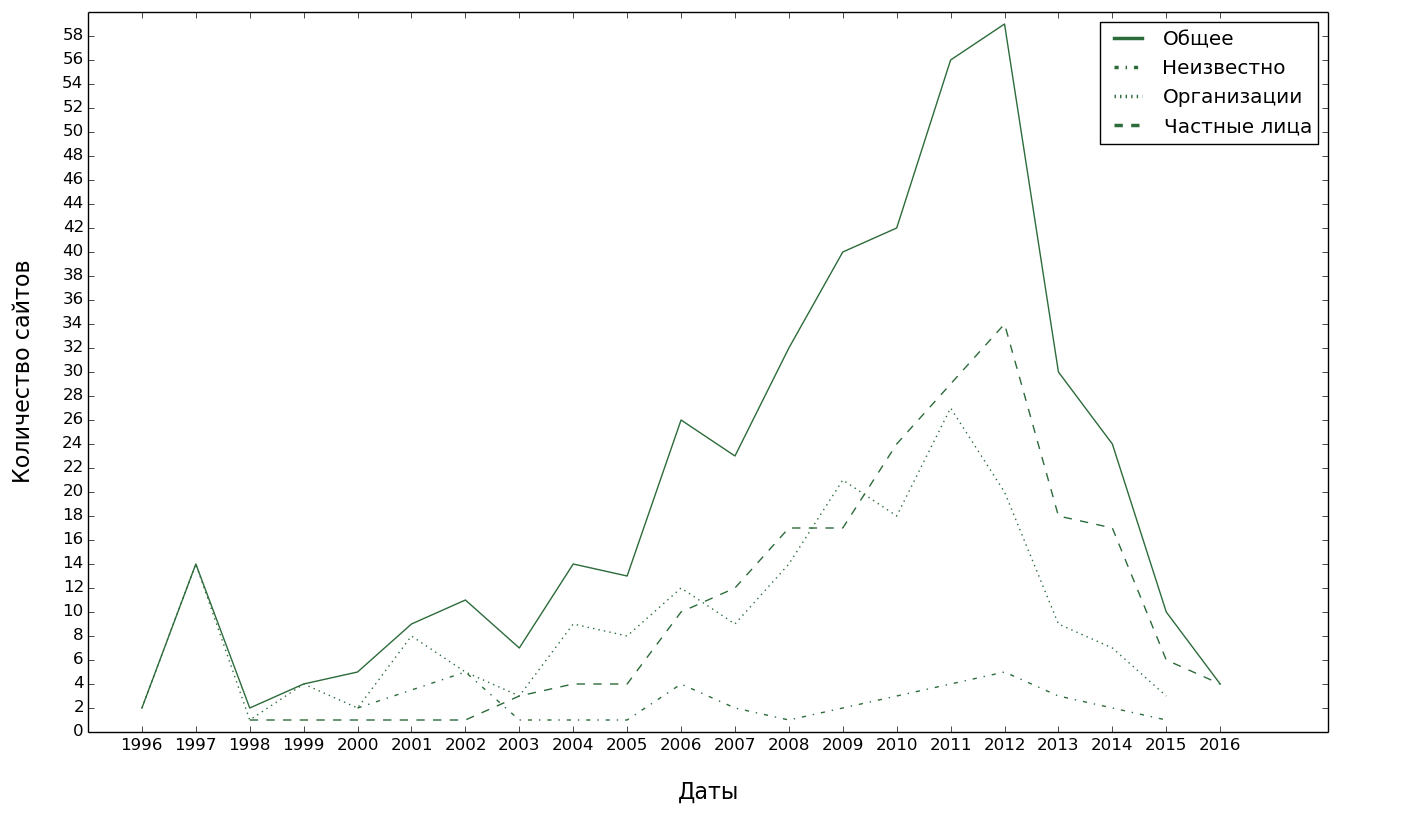
Видно, что процесс шёл по нарастающей, но после 2012 года наступил резкий спад. Почему? Наверное, потому что вся активность подобного рода перетекла в набравшие авторитет социальные сети. Прежде всего, в vk.com.
Теперь попробуем анализ данных. Вот у нас есть показатели для языка в онлайне: количество статей в Википедии, данные из Вконтакте (количество сообществ, объём текстов). И у нас есть показатели для языка в оффлайне (прежде всего, число носителей, но не только, ещё есть кое-какие экономические показатели регионов, в которых большей частью живут носители языка). Есть ли между этими группами показателей корреляция? А есть ли корреляция внутри группы показателей?
Оказывается, что между всеми онлайн-параметрами корреляция Спирмена довольно высокая (выше 0.7), а вот онлайн-параметры с оффлайновыми не коррелируют. Это значит, что в онлайне язык живёт по своим законам, и что там происходит в Интернете, от числа носителей не зависит. В общем, это логично, мы знаем, что есть правило одного процента. И важно не то, насколько этот процент большой, а насколько он активен. Есть небольшие языки с активным процентом, а есть языки побольше, среди носителей которых активистов не так много или они не такие уж и активисты.
Теперь посмотрим, насколько связаны между собой сайты на разных языках. Составляют ли малые языки замкнутую на себя систему или каждый язык представляет отдельную экосистему? Построим граф, в котором будем учитывать ссылки со страниц, на которых мы находим текст на одном языке, на страницы, на которых есть текст на другом языке.
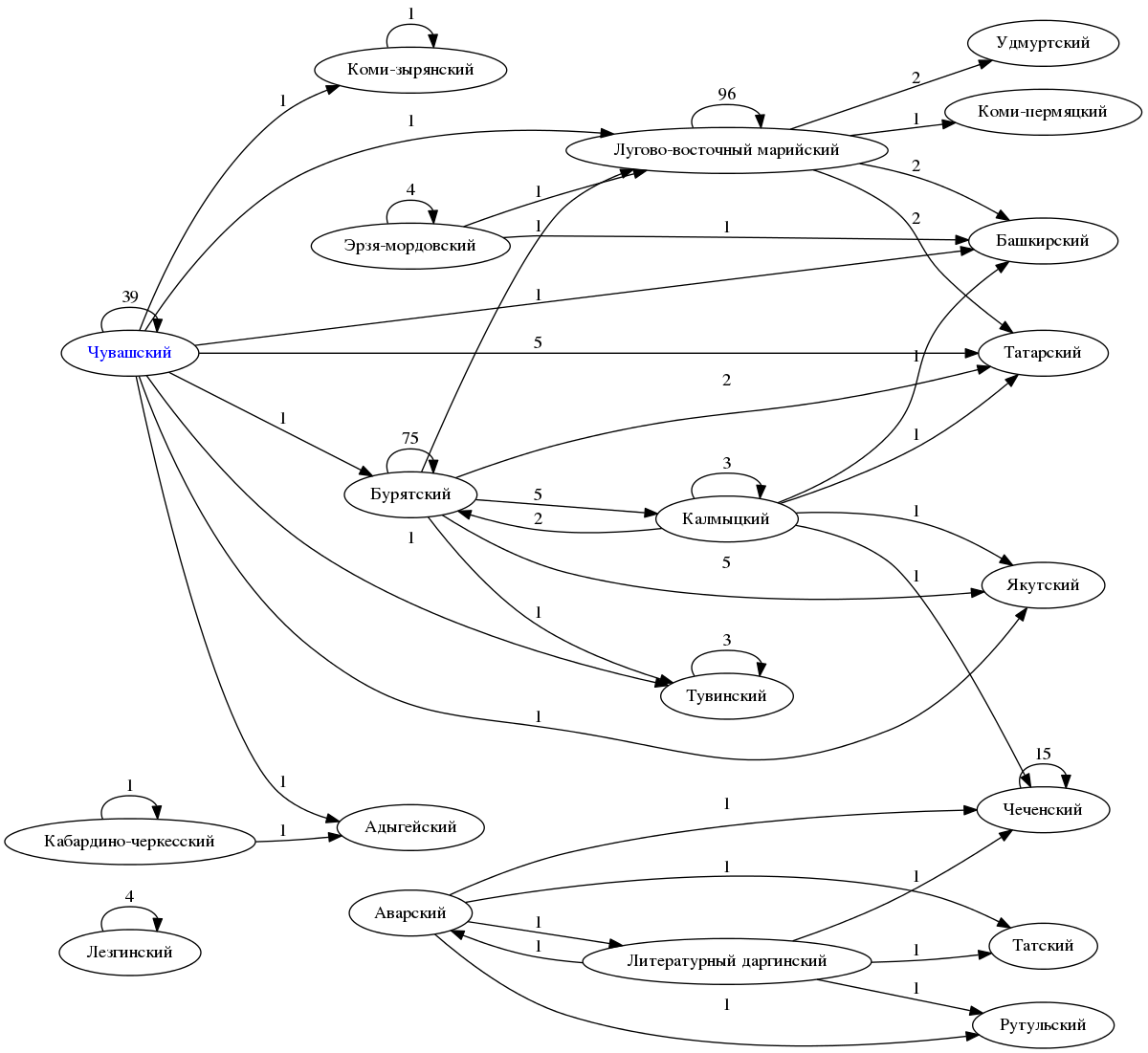
У многих языков-вершин есть «петли», это значит, что для этого языка мы видим сайты, которые дают ссылки на сайты на этом же языке. Но петель нет для больших языков, для которых это было бы ожидаемо: татарский, башкирский, удмуртский, якутский. Этих петель нет не в реальности, а в наших данных, потому что мы сайты на этих языках не выкачивали и не знаем, кто и на что там даёт ссылки.
Оказывается, это очень даже внутренне связанный мир. Приятно знать, что народы, как писал поэт, распри позабыв, в великую семью соединились, и единение это произошло в пространстве Интернета.
Как вообще языки похожи или не похожи друг на друга, если взять всё-всё, что мы про них знаем и по этим параметрам кластеризовать?
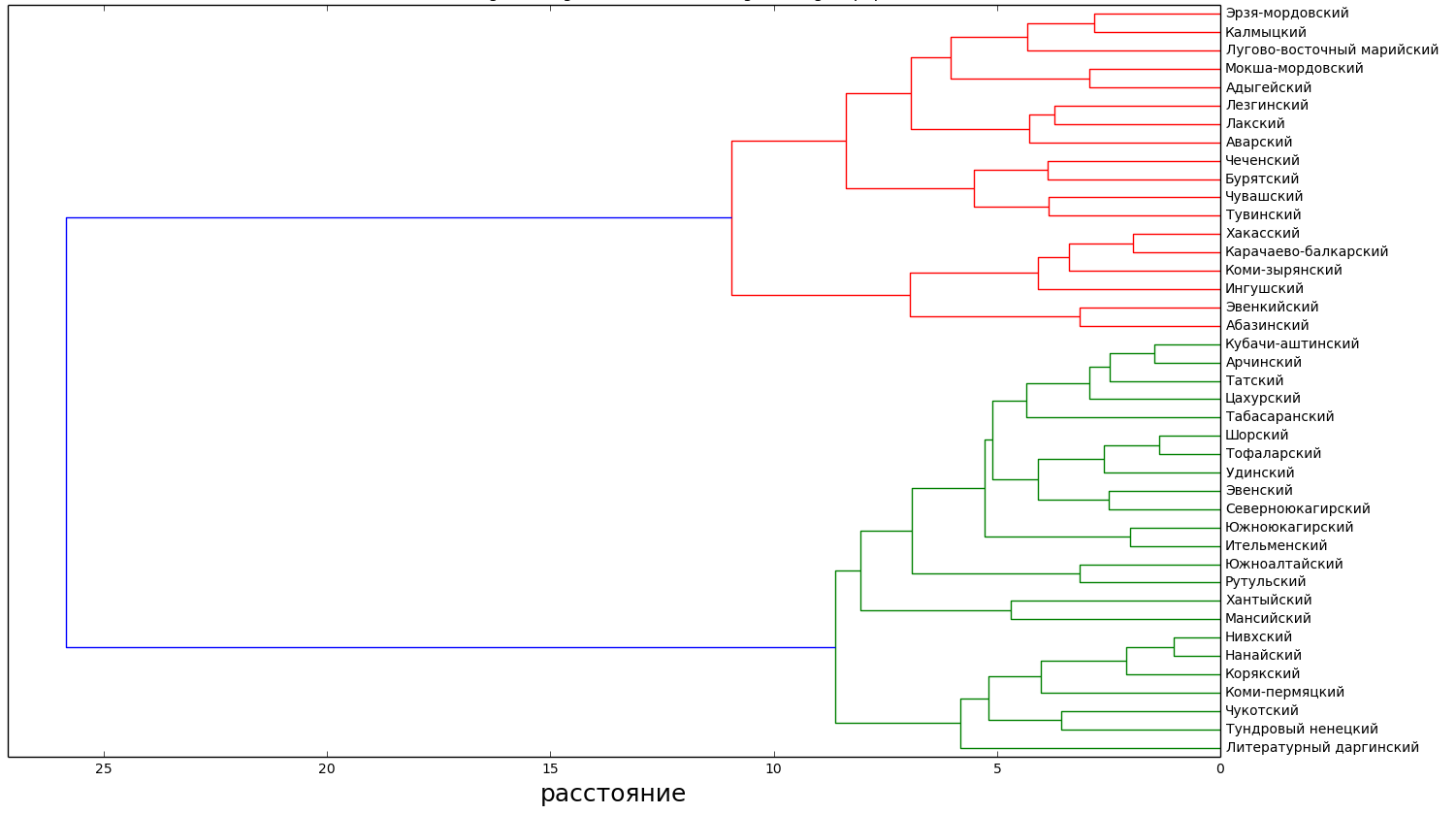
Здесь, в общем, очевидные две группы языков: более-менее благополучные, на которых есть носители, и эти носители пишут что-то в Интернете, и неблагополучные, витальность которых в Интернете слабо заметна.
Социальные сети
Теперь посмотрим на то, что мы знаем из текстов в vk.com.
Узнать оттуда вообще-то можно много чего, ведь пользователи не только пишут на каком-то языке, но и сообщают про себя разную полезную для лингвистов информацию: возраст, место проживания и проч. Так что здесь данных много.
Но выполним хотя бы первый подход к снаряду.
География постов:
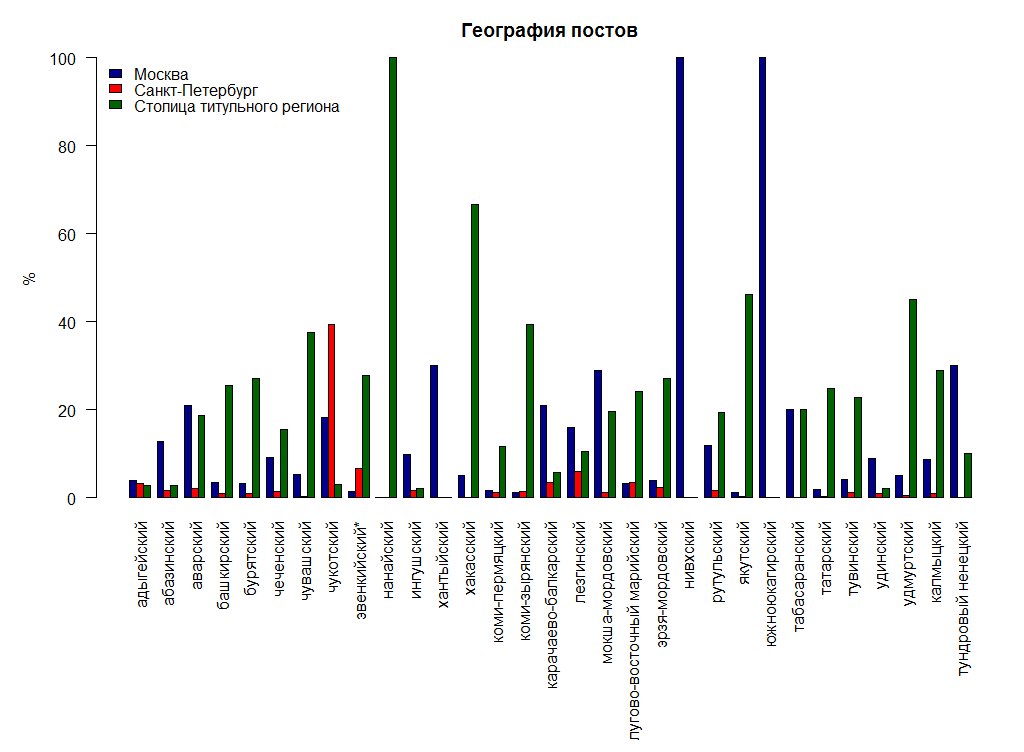
В основном, те, кто пишут на малом языке, живут в своём регионе, вероятнее всего — в столице. То есть пишущие на башкирском живут в Уфе, пишущие на удмуртском — в Ижевске. Это не так для совсем маленьких, почти вымерших языков типа южноюкагирского, их носители живут в Москве. Если это не чукотский. У русского Севера больше связи с Питером, северяне предпочитают северную столицу.
Что мы ещё знаем про типичного пользователя-носителя миноритарного языка?
- Возраст: 19-31;
- Место проживания: титульный регион;
- Являясь носителем миноритарного языка, в основном «говорит» по-русски;
- Вероятнее всего, принимает участие в жизни только одного сообщества.
Типичное сообщество, «говорящее» на миноритарном языке:
- Треть всех постов написана на миноритарном языке;
- Длина текста на миноритарном языке в среднем около пяти слов.
А зависит ли в социальной сети число сообществ от числа говорящих на языке вообще?
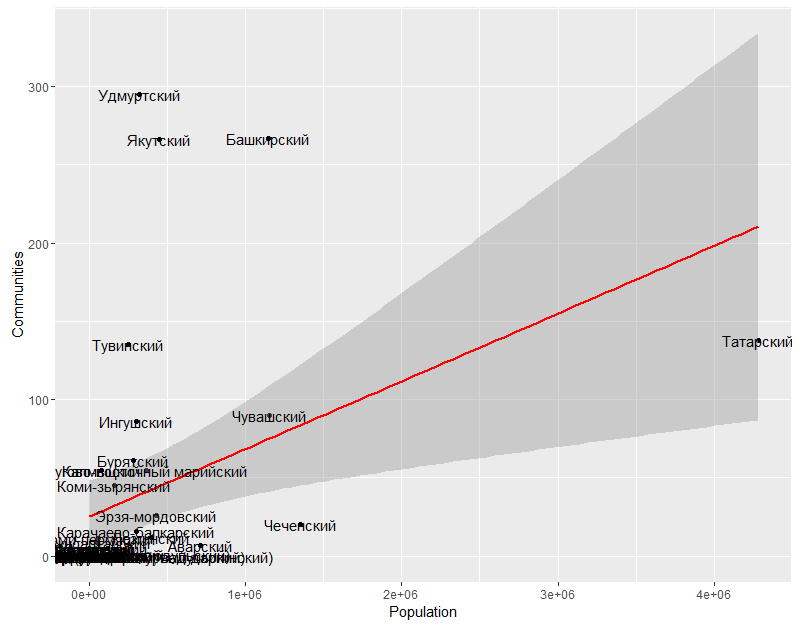
В целом как-то не очень. Много есть башкирских сообществ, больше, чем мы бы ожидали от языка с таким числом носителей. Чеченских сообществ, наоборот, меньше ожидаемого. Но тут надо помнить, что интернетизироваться этот регион стал позже других вследствие известных событий 90-х и начала 2000-х.
Итак, мы узнали, что малые языки России в Интернете есть. Они живут на сайтах и в социальных сетях, а с 2012 года преимущественно в социальных сетях. И там, и там они вынуждены выдерживать жёсткую конкуренцию с «престижным» русским языком. Витальность языка в Интернете мало зависит от того, сколько говорит на этом языке «в жизни». Важнее то, сложилось ли вокруг этого языка активное сетевое сообщество, действующее на престижных интернет-площадках (Википедия, Вконтакте). Если оно сложилось, то это произошло «на местах», в регионе, где живут носители этого языка.
Ну а получится ли у малых языков выжить в ситуации глобализации, нам предстоит узнать ещё при нашей жизни.
Весь код проекта лежит в репозитории. Все текстовые коллекции и списки доменов и сообществ доступны для скачивания.
А ещё не могу не порекомендовать сообщество в vk.com с няшными мемасиками на малых языках с котиками.
Источник


