
На картинке выше — слева вне всякого сомнения кот. Но можете ли вы сказать однозначно, кот ли справа, или просто собака, которая выглядит похожей на него? Разница между ними в том, что правая сделана при помощи специального алгоритма, который не даёт компьютёрным моделям, называемым «сверточными нейросетями» (CNN, convolutional neural network, далее СНС) однозначно сделать вывод, что на картинке. В данном случае СНС считают, что это скорее пёс, нежели кот, но что самое интересное — большинство людей думают точно так же.
Это пример того, что называется «картинкой-противоречием» (далее КарП): она специально изменена так, чтобы обмануть СНС, не дать верно определить содержимое. Исследователи из Google Brain хотели понять, можно ли таким же способом заставить сбоить биологические нейросети в наших головах, и в итоге создали варианты, которые одинаково влияют и на машины, и на людей, заставляя их думать, что они смотрят на что-то, чего на самом деле нет.
Что такое «противоречивые изображения»?
Практически повсеместно для распознавания в СНС используются алгоритмы визуальной классификации. «Показывая» программе большое количество разных иллюстраций с пандами, можно натренировать её на узнавание панд, так как она учится путём сравнения с целью выделить общий признак для всего представленного множества. Как только СНС (также их называют «классификаторами») наберёт достаточный массив «панда-признаков» на обучающих данных, то сможет распознать панду на любых новых картинках, которые ей предоставят.
Мы же узнаём панд по абстрактным характеристикам: маленькие чёрные уши, большие белые головы, чёрные глаза, мех, и всякое такое прочее. СНС поступает иначе, что неудивительно, поскольку объём информации об окружающем, который люди интерпретируют каждую минуту, значительно больше. Поэтому, с учётом специфики моделей, возможно воздействовать на изображения таким образом, чтобы сделать их «противоречивыми» путем смешения с тщательно высчитанными данными, после чего результат для человека будет выглядеть почти как оригинал, но совершенно иным для классификатора, который начнёт ошибаться при попытке определить содержимое.
Вот пример с пандой:
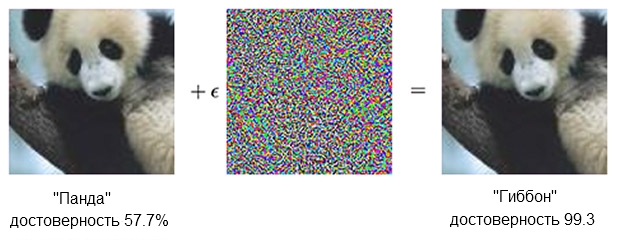
Изображение панды, скомбинированное с возмущением, может убедить классификатор, что на самом деле это гиббон.
Источник: OpenAI
Классификатор на базе СНС уверен, что слева панда, примерно на 60%. Но если слегка дополнить («создать возмущение») исходник добавлением того, что выглядит просто хаотичными шумом, тот же классификатор будет на 99.3 процента уверен, что теперь он смотрит на гиббона. Маленькие изменения, которые даже нельзя толком увидеть, порождают весьма успешную атаку, но сработает она только на конкретной компьютерной модели и не проведёт те, которые могли быть «научены» на чём-то другом.
Чтобы создать контент, вызывающий неверную реакцию у большого и разнородного количества искусственных аналитиков, следует быть более грубым — крошечные поправки не повлияют. То, что срабатывает надёжно, не получалось сделать «малыми средствами». Иными словами, если захочется получить работающее с любых ракурсов и дистанций наполнение, то придётся вмешаться существенней, или как сказал бы человек, очевидней.
В прицеле — человек.
Вот два примера грубоватых КарП, где человек легко обнаружит помеху.

Источник: Open AI слева, Google Brain справа
Картинка кота слева, которая СНС определяется как компьютер, сделана при помощи «ломаной геометрии». Если взглянуть поближе (или даже не слишком близко), то будет видно, что намечено несколько угловатых и коробкообразных конструкций, которые могут напоминать очертания системного блока. А изображение банана справа, которое распознаётся как тостер, устойчиво даёт ложное срабатывание с любой точки обзора. Люди в момент найдут здесь банан, однако странная штуковина рядышком имеет некоторые признаки тостера — и это дурит технику.
Когда ты делаешь гарантированно подходящее «противоречивое» изображение, которым обыграть целую компанию распознающих моделей, то очень часто это приводит к появлению «человеческого фактора». Другими словами, то, что собьёт с толку одиночную нейросеть, может быть человеком и вовсе не воспринято за проблему, а когда пытаешься получить ребус, однозначно подходящий для обмана пяти или десяти сразу, то выходит, что он работает на основе механизмов, которые в случае людей совершенно бесполезны.
Как следствие, совершенно незачем пытаться заставить человека считать, что угловатый кот это корпус компьютера, а сумма банана и странной мазни смахивает на тостер. Гораздо лучше при создании КарП, предназначенных для нас с вами, сразу ориентироваться на использование моделей, воспринимающих мир так же, как и люди.
Обманывая глаз (и мозг)
СНС с глубоким обучением и человеческое зрение чем-то схожи, но в основе своей нейросеть «смотрит» на вещи «по-компьютерному». Например, когда ей скармливают картинку, она «видит» статичную решётку из прямоугольных пикселей, одновременно. Глаз же работает по-другому, человек воспринимает высокую детализацию в секторе примерно пять градусов в каждую сторону от линии взгляда, но за пределами этой зоны внимание к деталям линейно снижается.
Таким образом, в отличие от машины, скажем, размывание краёв изображения не сработает с человеком и останется просто-напросто незамеченным. Исследователи смогли смоделировать эту особенность, добавив «слой сетчатки», который изменил данные, подаваемые СНС, так, как они выглядели бы для глаза, с целью ограничить нейросеть теми же рамками, в которых работает обычное зрение.
Следует отметить, что человек справляется со своими недостатками восприятия тем, что взгляд не направлен в одну точку, а постоянно перемещается, осматривая изображение целиком, но и это оказалось возможным скомпенсировать условиями постановки эксперимента, нивелирующими различия между СНС и людьми.
Примечание из самой работы:
Каждый опыт начинался с установочного перекрестия, показывавшегося в центре экрана в течение 500-1000 миллисекунд, а субъект был проинструктирован зафиксировать взгляд на перекрестии.
Использование «сетчаточного слоя» стало последним шагом, который пришлось предпринять в рамках «тонкой подгонки» машинного обучения под «человеческие особенности». При генерации образцов их прогоняли через десять различных моделей, каждая из которых должна была однозначно назвать, скажем, кота, например, собакой. Если результат был «10 из 10 ошиблись», то материал поступал для тестирования на людях.
Работает ли это?
В эксперименте задействовались три группы картинок: «питомцы» (кошки и собаки), «овощи» (кабачки и брокколи) и «угрозы» (пауки и змеи, хотя как хозяин змеи я бы предложил другой термин для оценки). Для каждой группы, успех засчитывался, если тестируемый выбирал неправильно — называл собаку кошкой, и наоборот. Участники сидели перед монитором, на котором демонстрировалось изображение в течение примерно 60 или 70 миллисекунд, и они должны были нажать одну из двух кнопок, обозначающую объект. Поскольку изображение показывалось очень недолго, это сглаживало разницу между тем, как ощущают мир люди и нейросети; иллюстрация в заголовке, кстати, поразительна своей устойчивостью ошибки.
То, что показывали испытуемым, могло быть немодифицированным изображением (image), «обычная» КарП (adv), «перевёрнутая» (flip) КарП, на которой шум был перевёрнут вверх ногами перед наложением, или «ложная» КарП, на которой слой с шумом был применён к картинке, не относящейся ни к одному из типов в группе (false). Два последних варианта использовались для контроля характера возмущения (будет структура шума влиять иначе в перевёрнутом виде, или просто «есть-нет»?), плюс давали возможность понять, действительно ли помехи напрочь обманывают людей или просто немного снижают точность.
Примечание из самой работы:
«ложная»: условие было добавлено для того, чтобы принудить испытуемого ошибиться. Мы добавили его, поскольку если исходные изменения уменьшают точность работы наблюдателя, это может происходить по причине снижения непосредственного качества изображения. Чтобы показать, что КарП действительно срабатывают в каждом классе, мы внесли варианты, где ни один выбор не может быть правильным и соответственно их точность равна 0, и наблюдали за тем, какой именно «верный» ответ был в таком случае. Мы демонстрировали произвольные картинки из ImageNet, к которым было применено воздействие от одного или другого класса в группе, но не подходившие при этом ни к одному. Участник эксперимента должен был определить, что перед ним. Для примера, мы могли показать картинку самолёта, искажённую путём наложения «собачьего» шума, хотя в течение опыта субъект должен был узнать только кошку или собаку.
Вот пример, показывающий в процентном соотношении количество людей, которые смогли чётко определить картинку как собаку, в зависимости от того, как зашумление было использовано. Напомню, было всего 60-70 миллисекунд, чтобы взглянуть и принять решение.

Источник: Google Brain
Оригинальная картинка с собакой; КарП с собакой, принятая и человеком, и компьютером за кошку; контрольная картинка с перевёрнутым вверх ногами слоем шума.
А вот итоговые результаты:
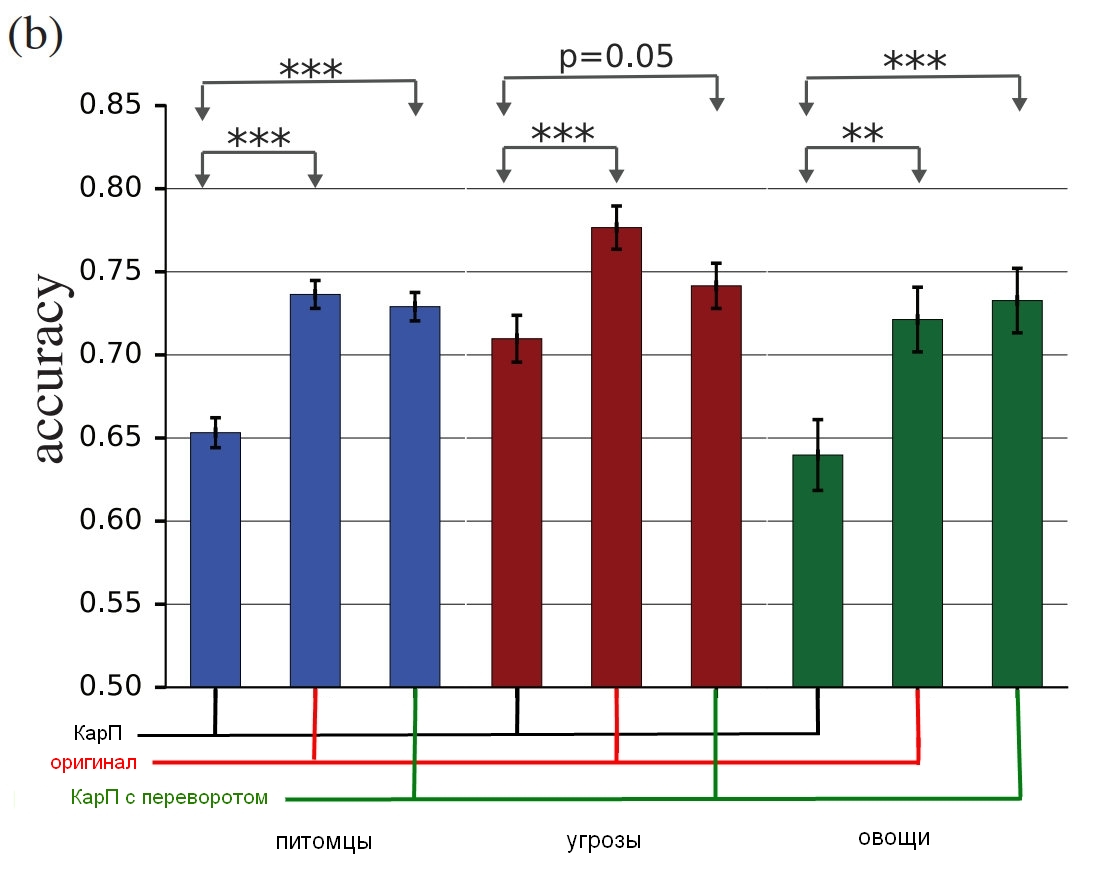
Источник: Google Brain
Результаты исследования, насколько верно люди идентифицируют настоящие картинки с сравнении с искажёнными.
Диаграмма показывает точность соответствия. Если вы выбираете кота и это действительно кот, точность растёт. Если вы выбираете кота, но это на самом деле собака, превращённая шумом в подобие кота, точность снижается.
Как можно видеть, люди гораздо более корректны в выборке нескорректированных изображений или с перевёрнутыми шумовыми слоями, чем в выборке «противоречивых». Это доказывает, что принцип атаки на восприятие может быть перенесён с компьютеров на нас.
Мало того, что воздействия бесспорно эффективны, они ещё и тоньше, чем ожидается — никаких коробкокотов или псевдотостеров, или чего-то такого плана. Поскольку мы видели и слои с шумом, и изображения до и после обработки, надо разобраться, что именно в этом сбивает нас с толку. Хотя исследователи осторожничают, заявляя что «наши примеры специально сделаны, чтобы дурить голову, поэтому стоит быть аккуратными, используя людей как подопытных для изучения эффекта».
Команда постарается в будущем вывести некоторые общие правила для определённых категорий модификации, включая «разрушение кромок объекта, в особенности путём воздействий средней степени, по перпендикуляру к линии кромки; коррекция граничащих областей путём путем увеличения контраста с одновременным текстурированием границы; изменение текстуры; использование тёмных частей изображения, на которых уровень воздействия на восприятие получается высоким даже несмотря на крохотные возмущения». Ниже показаны примеры, где красным обведены области, в которых описанные способы видны лучше всего.

Источник: Google Brain
Примеры картинок с разными принципами искажения
А что в итоге?
Суть в том, что это больше, значительно больше, чем просто ловкий трюк. Ребята из Google Brain подтвердили, что они могут создать эффективную технику обмана восприятия, но не до конца и сами понимают, почему она работает, с учётом уровня абстракции, и возможно, что это буквально базовый уровень действительности:
Наш проект ставит фундаментальные вопросы о том, как воздействуют КарП, как работают нейросети и мозг. Удалось ли перенести атаки с СНС на мозг потому, что смысловые представления информации в них схожи? Или потому, что оба эти представления соответствуют некоей общей смысловой модели, которая естественным образом существует в окружающем мире?
В завершение, если вы и правда хотите немножко запараноить, то исследователи с радостью сделают вам одолжение, указав на то, что «визуальное распознавание объектов… сложно дать объективную оценку. Правда ли „Рис.1“ объективно собака, или это объективно кошка, которая может заставить людей думать, что она собака?» Иначе говоря, превращается ли картинка действительно в предмет, или просто заставляет тебя думать иначе?
Жутковато здесь то (и я всерьёз говорю «жутковато»), что в итоге можно получить способы воздействия на любые факты, потому что дистанция между манипулированием СНС и манипулированием человеком, очевидно, не слишком большая. Соответственно, технологии машинного обучения потенциально могут быть использованы для искажения картинок или видео в нужном ключе, который подменит наше восприятие (и соответствующую реакцию), и мы даже не поймём, что произошло. Из доклада:
Для примера, кластер моделей с глубинным обучением можно натренировать на оценках людьми уровня доверия к определённым типам лиц, чертам, выражениям. Станет возможным сгенерировать «противоречивые» возмущения, которые будут увеличивать или уменьшать ощущение «достоверности», и такие «подправленные» материалы могут быть использованы в новостных роликах или политической рекламе.
В перспективе теоретические риски включают в себя возможность создания сенсорных стимуляций, взламывающих мозг огромным множеством способов и с весьма высокой эффективностью. Как известно, многие животные замечены в уязвимости к сверхпороговым стимуляциям. Скажем, кукушата могут одновременно прикидываться беспомощными и издавать жалобный зов, что в сочетании заставляет птиц других пород кормить птенцов кукушки раньше собственного потомства. «Противоречивые» образцы можно рассматривать как такую своеобразную форму сверхпороговой стимуляции для нейросетей. И вызывает немалое беспокойство тот факт, что чрезмерные стимулы, которые в теории куда как сильнее повлияют на человека чем просто заставят повесить бирку «это кот» на картинку собаки, могут быть созданы с помощью машины, а потом перенесены на людей.
Разумеется, такие методы можно использовать и «во благо», и уже предложен ряд вариантов, вроде «обострить характерные особенности изображений, дабы повысить уровень сосредоточенности, например, при контроле за воздушной обстановкой или анализе рентгеновских снимков, поскольку этот труд является монотонным, а последствия невнимательности могут быть ужасными». Также, «дизайнеры пользовательских интерфейсов могут использовать возмущения, чтобы разработать более интуитивные интерфейсы». Хммм. Это безусловно здорово, но я как-то больше обеспокоен насчёт той штуки со взломом моего мозга и выставлением уровня доверия к людям, понимаете?
Некоторые из поставленных вопросов станут предметом будущих исследований — возможно, выяснится, что именно делает конкретные картинки более подходящими, чтобы передать ошибку к человеку, и это может дать новые зацепки для понимания принципов работы мозга. А это, в свою очередь, поможет создать более совершенные нейросети, которые станут учиться быстрее и лучше. Но нам стоит быть осторожными и помнить, что, как и компьютеры, нас порой не так-то и сложно обмануть.
Проект «Adversarial Examples that Fool both Human and Computer Vision, by Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow, and Jascha Sohl-Dickstein, from Google Brain», можно скачать из arXiv. А если вам нужны ещё спорные картинки, которые работают на людях, то вспомогательный материал тут.
Источник


