Прозвучала мысль, что мы кривые ламеры и не умеем всё правильно готовить. Альтернативой была гипотеза «все врут».
Прошло полгода. Мы научились всё это готовить, но заодно поняли, что гипотеза «все врут» куда более вероятная.

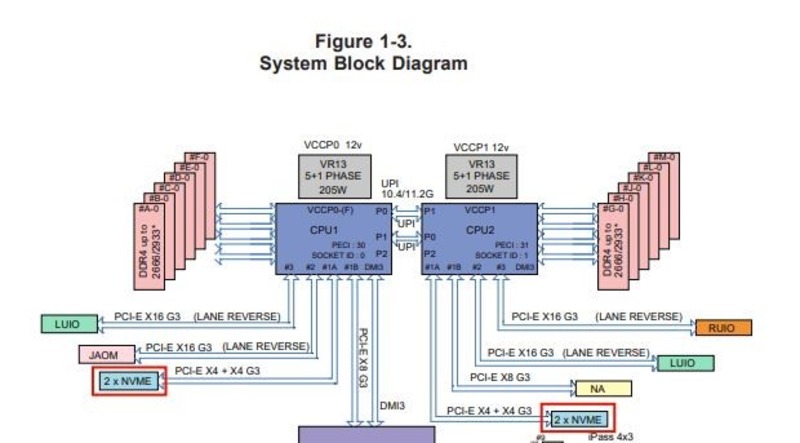
Тут видно, что RAM подключена к CPU1, а NVME-диски — к CPU2. Это будет критически важно дальше по сюжету.
В общем, сейчас расскажу, чего именно нам стоило ввести нормальные NVMe-тарифы и почему при всём этом очень важно разбираться в архитектуре сервера.
В чём была проблема
У нас не было NVMe-тарифа для наших клиентов VDS. Мы хотели сделать такой тариф, потому что рыночные запросы на это дело были. Чтобы сделать такой тариф, нужно выбрать конфигурацию сервера с NVMe-дисками внутри, протестировать её и внедрить по всем локациям. Мы используем только гомогенное корпоративное железо, то есть во всех наших ЦОДах по миру должны быть одни и те же конфигурации серверов. Так проще обслуживать, писать софт, обеспечивать единые цены и ремонтировать всё это. То есть введение нового сервера требует довольно больших тестов.
Мы купили несколько разных железок (самосбор, не корпоративных линеек, потому что корпоративные поставки сейчас очень долгие, чуть ли не с лагом в полгода в лучшем случае). И начали тестировать. История тестирования — в первом посте.
Краткие итоги:
— Сюрприз, но на NVMe нельзя собрать рейд. Точнее, можно, но он будет медленнее отдельных дисков, и никто так не делает. То есть смысла в рейде не то что нет, а он ещё и отрицательно сказывается на производительности. При этом все хостеры с NVMe пишут, что у них там рейды.
— Сюрприз, но NVMe-диски работают на считаные проценты лучше SSD-дисков. А мы ведь ждали совсем даже не этого.
Что было дальше
Первый сервер, до которого мы добрались в Москве летом, был Супермикро + набор дисков к нему. Тесты показали, что результаты не могут сравниться с тем, что вроде бы дают другие хостеры. То есть мы где-то что-то серьёзно недопонимали. Дальше я рассказал эту историю на Хабре, и Yoh, creker, vesper-bot, Savrik, trashwind, VanyaKokorev и borovinskiy высказали дельные мысли в комментариях. Спасибо, вы нам очень помогли в поисках дальше.
Поиски дальше заключались в том, что мы несколько месяцев искали узкое место.
Сначала пробовали разные варианты софтверного рейда включая VROC. Не помогло. Потом попробовали хардверный рейд. Как и ожидалось, ограничения шины всё равно не давали его использовать. Отвезли свой сервер в компанию, которая занимается нестандартной сборкой и делает очень кастомные решения. Они могут чуть ли не Делл из Супермикро собрать. В общем, у них лаборатория. Поставили разные софт-рейды и хард-рейды, стали менять кабели соединения, интерфейсы. Ничего особо не меняло ситуацию. Решили, что дело — в Hyper-V и его особенностях реализации, долго его ковыряли.
Что больше всего удивляло, мы общались и с поддержкой других хостингов, и с поставщиками железа, и с лабораториями, и никто не мог нормально объяснить, что происходит и почему NVMe такие медленные и тупые.
И тут внезапно прозвучала мысль про UPI-линии. И мы решили попробовать делить виртуальные машины по NUMA-нодам (нума-нода — это связка процессора, оперативки и диска в рамках одного сервера).
И тут у меня есть что вам показать!
Тесты
Тестировали платформу Supermicro X11DDW-NT:
|
CPU
|
Intel Xeon Gold 6250
|
|
RAM
|
DDR4-2933 32GB
|
|
SSD
|
Intel P4610 1.6TB NVMe
|
Разводка линий данной платформы. Видно, что каждый CPU обслуживает по два NVMe-диска. Каждый из дисков подключён с помощью PCI-E X4. CPU соединены между собой двумя UPI-линиями.
Теоретическая скорость линий:
- четыре линии PCI-E x4 — 16000 MB/s;
- две линии UPI — 20.8 GT/s.
Видно, что суммарная пропускная способность PCI-E-линий для четырёх дисков сравнима по величине с пропускной способностью двух линий UPI. Более того, транзакции UPI-линий используются для доступа к RAM и синхронизации работы CPU. Поэтому транзакций, которые используются непосредственно для передачи данных, остаётся меньше.
Чтобы полностью исключить шину UPI из обработки и передачи данных, мы поступим самым простым и надёжным способом: отключим CPU2, а также все модули RAM и диски NVME, к нему относящиеся:

На фотографии видно, что слоты CPU2 и относящихся к нему RAM- и NVME-дисков не заняты. Дальше для тестирования используем diskspd. Тесты проводим под Windows Server 2016 и Windows Server 2019.
Тест чтения: DiskSpd64.exe -b4K -t32 -o32 -w0 -d10 -r -S -c100G F:/testfile.dat G:/testfile.dat
Тест записи: DiskSpd64.exe -b4K -t32 -o32 -w100 -d10 -r -S -c100G F:/testfile.dat G:/testfile.dat
Результаты:
|
Write (percent)
|
Win2016 — IOPS
|
Win2019 — IOPS
|
|
0 (read)
|
1132231.01
|
1026432.57 (- 9 %)
|
|
100 (write)
|
863745.10
|
953902.69 (+ 10 %)
|
Под Win2019 чтение медленнее на 9 %, но зато на 10 % быстрее запись, чем под Win2016.
Во всех тестах нагрузка CPU была 95–98 %. Отсюда возникает вопрос, как изменится скорость, если поставить второй CPU. Поставим второй CPU и проведём соответствующий тест.
Windows Server 2016:
|
Write (percent)
|
один CPU — IOPS
|
два CPU — IOPS
|
|
0 (read)
|
1132231.01
|
590263.08 ( — 48 %)
|
|
100 (write)
|
863745.10
|
594401.43 ( — 32 %)
|
Windows Server 2019:
|
Write (percent)
|
один CPU — IOPS
|
два CPU — IOPS
|
|
0 (read)
|
1026432.57
|
818586.28 ( — 21%)
|
|
100 (write)
|
953902.69
|
842953.92 ( — 12 %)
|
Видно, что синхронизация работы CPU через UPI-линию существенно снизила результаты. Падение производительности с двумя CPU под Win2019 существенно меньше, чем под Win2016.
▍ Вторая часть марлезонского балета:
А теперь установим оба CPU. Но вся RAM будет на CPU1, а NVME — на CPU2.
RAM подключена к CPU1, а NVME-диски — к CPU2.
Тесты на количество IOPS такие же, как в предыдущем разделе.
Тесты на пропускную способность:
Чтение: DiskSpd64.exe -b128K -t32 -o32 -w0 -d10 -si -S -c100G F:/testfile.dat G:/testfile.dat
Запись: DiskSpd64.exe -b128K -t32 -o32 -w100 -d10 -si -S -c100G F:/testfile.dat G:/testfile.dat
Количество IOPS:
|
Write (Percent)
|
Win2016 — IOPS — 4K
|
Win2019 — IOPS — 4K block
|
|
0 (read)
|
530662.74
|
599021.15 (+ 13 %)
|
|
100 (write)
|
597662.21
|
783532.95 (+ 30 %)
|
Пропускная способность MiB/s:
|
Write (Percent)
|
Win2016 — MiB/s — 128K block
|
Win2019 — MiB/s — 128K block
|
|
0 (read)
|
5688.68
|
5035.62 ( — 11 %)
|
|
100 (write)
|
3843.31
|
3615.85 ( — 6 %)
|
Видно, что под Win2019 — несколько большее количество IOPS, но меньшая пропускная способность.
▍ Итоги:
Сравним количество IOPS при обмене без UPI и через UPI.
Windows Server 2016:
|
Write (Percent)
|
Без UPI — IOPS
|
Через UPI — IOPS
|
|
0 (read)
|
1132231.01
|
530662.74 ( — 53 %)
|
|
100 (write)
|
863745.10
|
597662.21 ( — 31 %)
|
Windows Server 2019:
|
Write (Percent)
|
Без UPI — IOPS
|
Через UPI — IOPS
|
|
0 (read)
|
1026432.57
|
599021.15 ( — 41 %)
|
|
100 (write)
|
953902.69
|
783532.95 ( — 18 %)
|
Та-дам! Результаты наглядно демонстрируют, что пропускная способность UPI-линий может стать узким местом при использовании NVME.
Что всё это значит?
Что все врут.
Как только мы начали распределять виртуалки по NUMA-нодам, внезапно всё заработало с нужной скоростью. Причём, кстати, под 2016-й винсервер иногда лучше, чем под 2019-й, так что если вы сейчас решаете, жить на уходящей с поддержки версии или сразу мигрировать на модное и современное, то это ещё один довод в обсуждение. Скорее всего, дело просто в том, что MS сдвинули баланс r/w где-то на уровне драйверов или рядом.
Так вот, по умолчанию виртуалки распределяются по NUMA-нодам в хаотичном порядке. Это значит, что UPI-линии используются для связи железа между нодами, в частности, с теми самыми NVMe-дисками. И могут стать узким местом.
Те хостеры, которые используют NVMe и не дописали свой софт так, чтобы создавать виртуалки в рамках одной NUMA-ноды, а не вперехлёст по железу, скорее всего, остановились на однопроцессорных серверах. На них всё «из коробки» будет работать с прогнозируемой скоростью. Там нет UPI вообще.
Относительно RAID-массивов — решения всё ещё нет. Удивительно, но рабочего рейда пока найти не удалось, хотя NVMe — всё же не вчерашняя технология. Те, кто пишет про RAID, либо банально врут, либо замедляют скорость чуть ли не ниже SSD, что исключает полезность NVMe-дисков. Мы решили делать полный технический бекап диска раз в сутки, и если что — автоматически восстанавливать из него при вылете NVMe-диска. Увы, но автоматических ребилдов, как на SSD, когда пользователь VDS этого даже не замечает, пока не будет (и в ближайшем будущем — тоже). Нам добавится работы при восстановлении при аварии. Точнее, нашим скриптам.
С новым распределением по NUMA-нодам результаты производительности NVMe у нас полностью в рынке. Тарифы — на бою, цены — хорошие. Посмотреть можно тут. Мы очень постарались, чтобы вы платили за реальную производительность, а не наклейку «NVMe» на тарифе.
Корпоративное железо приехало и выглядит вот так:



В этих серверах Lenovo SR650 V2 не две, а три UPI-линии. Возможно, наши танцы с бубном будут не нужны, так как мы надеемся, что дополнительная UPI-линия может убрать необходимость разделять виртуалки по NUMA-нодам.
Итого: если вы можете настраивать использование NUMA-нод в сервере с NVMe — лучше настроить. Если бы мы использовали KVM, то это всё завелось бы куда легче, дело отчасти — в реализации виртуализации (распределении ресурсов машин). Hyper-V изначально не имел возможности распределения виртуальных машин по NUMA-нодам, но в конечном счёте они выпустили специальную утилиту CpuGroups.exe. При её использовании можно получить измеримый эффект ускорения при использовании NVME-дисков.


