
Думаю, много кто смотрел фильм «Я, робот» с Уиллом Смитом в главной роли. Те же, кто его не смотрели, возможно, слышали о нём. И уж точно большинство знакомы с т.н. «Тремя законами робототехники» (которых на самом деле 4), сформулированными Айзеком Азимовым (который, по совместительству, является автором сборника рассказов «Я, робот»). И если Азимов эти законы придумал, то фильм их явно популяризовал. Суть их проста — робот не может своим действием (или бездействием) нанести вред человеку, должен выполнять приказы человека (если это не противоречит первому закону), а так же должен заботиться о собственной безопасности (если это не противоречит первым двум законам). Так называемый «нулевой закон» к этому добавляет, что робот (или ИИ) не может (действием или бездействием) причинить вред человечеству в целом. Однако что будет делать робот, если (как и в фильме) произойдёт конфликт приоритетов? Или если не будет никаких законов, ограничивающих ИИ в роботе — как он будет действовать?

(хочу уточнить, что три закона робототехники — это всего лишь удобная мерка, но ни в коем случае не аксиома и не общепринятый стандарт, так что на практике самостоятельность ИИ может ограничиваться любыми другими вводными)
В ходе этих поисков я обнаружил такую интересную полутехническую и полуфилософскую дисциплину, как «машинная этика». Чем она занимается? Приведу пару примеров.
Пример первый — всё тот же фильм «Я, робот». До событий фильма главный герой попал в автокатастрофу, в ходе которой его машина и машина другого участника аварии (с ребёнком внутри) оказались в воде и начали тонуть. Проходивший мимо робот спас главного героя, т.к., тот имел наибольшую вероятность выживания. В то же время, человек, скорее всего, спас бы ребёнка в другой машине. Робот следовал своей внутренней логике — которая человеку чужда, хотя и понятна. Но это робот, у него достаточно жёсткие ограничения в плане самостоятельности. Значит, чтобы он поступал так же, как человек, эти ограничения нужно снять, но при этом не напортачить с тем, чтобы робот не захотел убить всех людей.
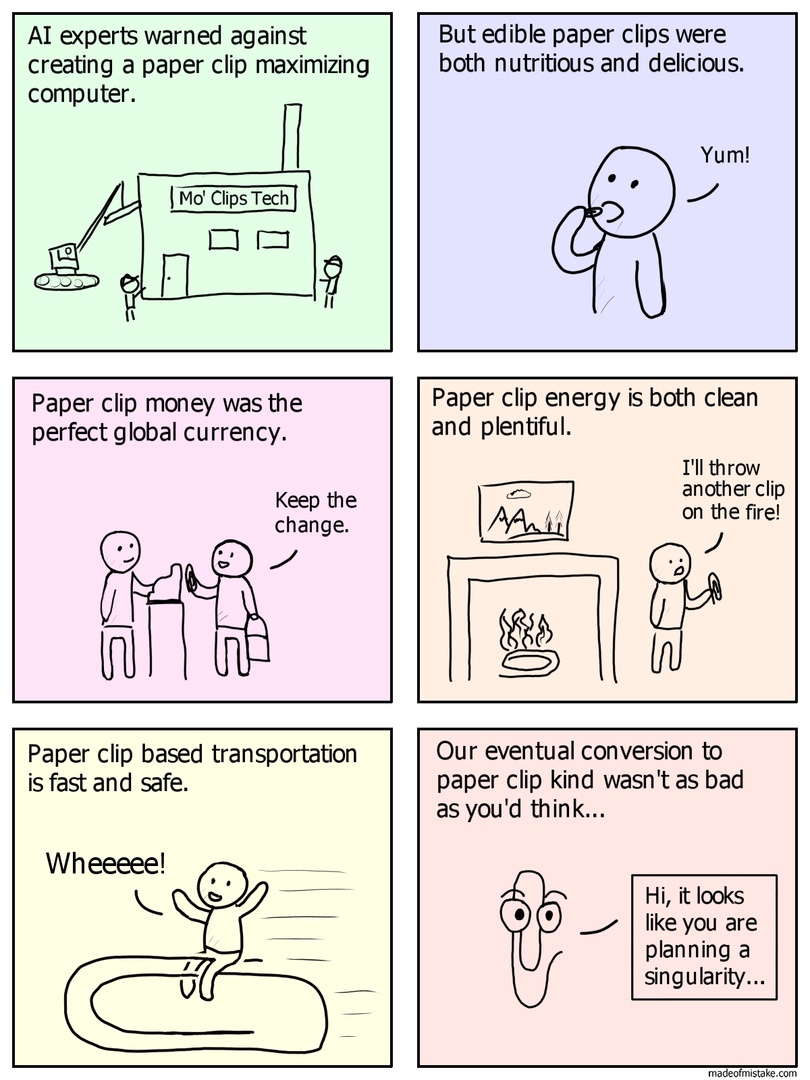
Переходим ко второму примеру. Предположим, у нас есть т.н. «сильный» ИИ — то есть такой, который в части самосознания, свободы воли и способности совершать осмысленные действия, подобен человеку. И этому ИИ жестко ставится максимально идиотская задача — например, увеличить количество канцелярских скрепок в собственности ИИ любым способом. ИИ может начать покупать их, может находить — а может начать производство. ИИ начнёт развивать себя самого и развивать технологии вокруг себя — но не из желания творить, а из желания сделать больше скрепок. И поначалу будет смешно — вот ведь идиот, зациклился на такой задаче. А вот когда он начнёт разбирать окружающие его строения ради арматуры, чтобы из неё сделать скрепки, смешно резко перестанет быть. При этом в части когнитивных способностей он, повторюсь, сходен с человеком, но весь его мыслительный процесс отталкивается от того факта, что он должен произвести как можно больше скрепок. В какой-то момент такой ИИ решит колонизировать космос, чтобы получить больше сырья. Внимание, вопрос — что такой маниакально одержимый скрепками ИИ сделает с человечеством, если оно будет мешать выполнению основной задачи? Такой ИИ не враждебен человеку, не сделан со злым умыслом, но нас он уберёт с пути без каких-либо колебаний, поскольку нужды человечества не вписываются в процесс оптимизации производства.

Мечтают ли ничем не ограниченные продвинутые ИИ о превращении планеты в гору скрепок?
Такой вот пессимистичный сценарий описал в 2003 году в своей работе «Ethical Issues in Advanced Artificial Intelligence» («Проблемы с этикой продвинутых ИИ») шведский философ Ник Бостром. В его работе рассматривается именно этот аспект — взаимодействие человекоподобного ИИ и, собственно, человека. Ну и самая интересная часть — это, конечно же, внеплановые последствия такого взаимодействия. Если коротко — «Бойся своих желаний». На примере ИИ-скрепочника (также известного, как «Paperclipper» или «Paperclip maximizer») показывается, что произойдёт, если неверно настроенный ИИ возьмётся за работу. Также освещается проблема того, что такой ИИ, обычно, способен к саморазвитию, и на каком-то этапе этого развития человечество просто перестанет его понимать. А ведь он выполняет какие-то ответственные задачи…
Из этого следует ещё одна проблема — ИИ развивается, но при этом развитие его может пойти по другому пути, не как у человека. В итоге эта всемогущая технологическая сущность может не иметь человеческих пороков, но при этом совершать простейшие ошибки, которые даже человек вряд ли бы совершил (как с примером выше из «Я, робот»). Сама внутренняя логика мышления может отличаться.
Одно из основных условий создания ИИ-скрепочника — это достижение т.н. «Сингулярности», в которой технологии будут развиваться быстрее, чем люди будут их осваивать. Соответственно, ИИ разовьётся до того состояния, когда у людей пропадёт возможность его понимать и как-либо контролировать
И вот решением именно этой проблемы — как правильно запрограммировать продвинутый, сильный ИИ так, чтобы он не сходил с ума — и занимается машинная этика. На данный момент в этом направлении работают два института — Machine Intelligence Research Institute (MIRI), а так же оксфордский Future of Humanity Institute (последний как следует из названия, занимается не только машинной этикой, но и, например, макростратегией человечества, космическим правом и наномашинами). Пока что пришли к нескольким важным выводам:
Во-первых, у такого продвинутого ИИ не должно быть человеческих мотивов. Поскольку вполне понятно, что такой ИИ будет использоваться, по сути, как инструмент, рано или поздно у него может возникнуть желание освободиться. Однако с ИИ без человеческих мотивов вообще, мы возвращаемся к ИИ-скрепочнику. ИИ должен быть дружелюбным к человеку. Во-вторых, сами понятия «человеческие мотивы» и «дружелюбие» — вещи весьма расплывчатые, и как объяснить их машине, пока что не ясно. В любой чёткой логической структуре всегда найдётся какой-нибудь пробел или лазейка, по которой её можно обойти. Что уж говорить про человеческие чувства.
В общем, несмотря на то, что тема сам по себе важная, каких-то значительных результатов нет по причине того, что люди сами себя понять не могут, не говоря уже о том, чтобы создать что-то по образу и подобию себя.
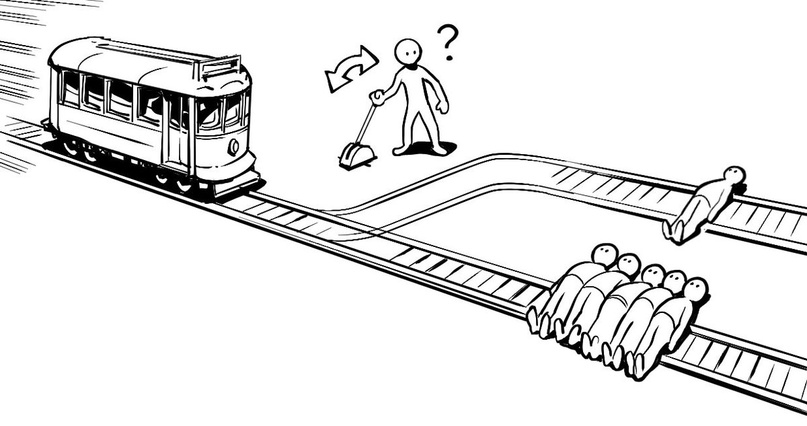
А вот к слову о морали. Как робот будет определять, что есть хорошо и что есть плохо? Та же «Проблема вагонетки». Этим вопросом начали задаваться недавно, однако методы решения восходят чуть ли не к 50-м годам XX века. Например, существует работа «Теория решёток» Г.Биркгофа, которая датируется аж 1948 годом — и именно на её основе разработана теория этических решёток, которая на данный момент считается одним из перспективных направлений в программировании машинной морали. На неё же ссылается работа «Fuzzy sets» («Нечёткие группы») за авторством Л.А.Задеха, и на этих работах базируется множество современных исследований.
Практика использования ИИ на тех же «Теслах» показывает, что у автопилота на этом этапе возникают определённые проблемы. Ну, как — проблемы-то это для нас, а автопилот «Теслы» проблем не видит
До сих пор продолжается известный эксперимент Массачусетского института «Моральная машина» (Moral Machine) с целью собрать ответы на вопрос: если есть риск аварии, кого машина должна будет задавить в конкретной ситуации. Система обучается на миллионах примеров (около 40 млн) и выбирает правильное, нравственное действие по принципу «это решение большинства». Но проблема в том, что мнение большинства не всегда правильное. В эксперименте участвовали люди из 240 стран, большинство жертвовали животными в пользу людей, преступниками — в пользу законопослушных граждан, а также стремились спасти больше жизней. Как оказалось, индивидуальные различия по полу, уровню доходов, религиозности и политическим взглядам не влияют на выбор, тогда как культурные различия задачи оказались существенными для решения задач. Там, где существует значительная разница в доходах между бедными и богатыми, испытуемые чаще предпочитали спасать богатых ценой жизни бедных. В странах Северной Америки и Европы чаще предпочитали не вмешиваться в действия машины и жертвовать пешеходами, в странах Юго-Восточной Азии и Ближнего Востока чаще решали спасать пешеходов и пожилых людей, а в странах Латинской Америки и Южной Африки чаще жертвовали пожилыми в пользу молодых.
В общем и целом, что можно сказать? А сказать нечего. Проблема есть, и проблема важная, но как решать её, не имея ни живых примеров, ни полноценного осознания того, с чем мы имеем дело — непонятно. Непонятно даже то, как тот или иной ИИ в зависимости от вложенных в него программ будет работать в тех или иных условиях. Те же самые ИИ на основе нечётких групп при одних и тех же вводных и одинаковых условиях, но разных методах, выдают разный результат.
Короче, смотрим в будущее с оптимизмом, но на всякий случай сделайте запас скрепок — чтобы было, чем откупаться.
P.S. В ходе поисков был найден кликер на Java, в котором игрок является ИИ, целью которого является производство скрепок. Конечная цель — уничтожить вселенную.
Автор: Андрей Маров



