Советы по отделению отвлекающих факторов от полезных сведений

Если вы пройдете вводный курс по статистике, вы поймете, что данные можно использовать для поиска вдохновения или проверки теории, но никогда и для того, и для другого. Почему так?
Люди слишком хороши в поиске закономерностей во всем. Вы сами определяете какие закономерности действительно существуют, а какие – выдуманы. Мы – существа, которые находят лицо Элвиса в картофельной чипсе. Если у вас есть соблазн приравнять закономерности к понятиям, помните, что есть три вида закономерностей:
- Паттерны, которые существуют и в вашем наборе данных, и за его пределами.
- Паттерны, которые существуют только в вашем наборе данных.
- Паттерны, которые существуют только в вашем воображении (апофении).
Закономерность данных может существовать (1) во всей совокупности, представляющей интерес, (2) только в выборке или (3) только в Вашей голове.
Какие закономерности и шаблоны данных могут быть полезны для Вас? Это зависит от ваших целей.
Вдохновение
Если вам нужно чистое вдохновение – данные могут быть сотворить чудо. Даже апофения (человеческая склонность ошибочно воспринимать связи и смысл между несвязанными вещами) — может заставить ваш креатив работать на полную катушку. Творчество не имеет правильных ответов, поэтому все, что вам нужно сделать, это взглянуть на свои данные и поиграть с ними. В качестве дополнительного бонуса постарайтесь не тратить слишком много времени (вашего или заинтересованных лиц) впустую.
Факты
Когда ваше правительство хочет собрать с вас налоги, оно не может не обращать внимания на значения, выходящие за рамки ваших финансовых данных за год. Налоговой службе необходимо принять основанное на фактах решение о том, сколько вы должны и основной способ принятия этого решения – анализ данных за прошлый год. Другими словами, посмотреть на данные и применять формулу. В данном случае речь идет о чисто описательной аналитике, привязанной к имеющимся данным. Любой из первых двух видов закономерностей хорошо подходит для этого.
Описательная аналитика, привязанная к имеющимся данным.
(Я никогда не скрывала свои финансовые отчеты, но я думаю, что правительство Соединенных Штатов не было бы в восторге, если бы для их подмены я использовала методы расчета данных, которым я научилась в аспирантуре, чтобы платить налоги статистически).
Решения в условиях неопределенности
Иногда имеющиеся факты не совпадают с желаемыми. Когда вы не обладаете всей информацией, необходимой для принятия того или иного решения, вы должны ориентироваться в неопределенности, пытаясь выбрать разумный курс действий.
Именно в этом заключается статистика — наука о том, как изменить свое мнение в условиях неопределенности. Игра состоит в том, чтобы прыгнуть в неизвестность подобно Икару… и при этом не разбиться вдребезги.
В этом и заключается главная задача data science: как не оказаться *неосведомленным* в результате изучения данных.
Перед тем, как прыгнуть с этой скалы, лучше надеяться, что закономерности, которые вы обнаружили в своем ограниченном представлении о реальности, на самом деле работают за пределами вашего представления. Другими словами, для того чтобы быть полезными для вас, шаблоны должны быть обобщены.

Из трех видов закономерностей, при принятии решений в условиях неопределенности, безопасен только первый (обобщаемый). К сожалению, вы найдете и другие типы закономерностей в ваших данных – это большая проблема, лежащая в основе data science: как не утратить собственную осведомленность в результате изучения данных.
Обобщение
Если вы считаете, что нахождение бесполезных шаблонов в данных — это чисто человеческая привилегия – подумайте еще! Если вы не будете осторожны, то машины могут сделать такую же глупость автоматически.
Весь смысл машинного обучения и ИИ в том, чтобы правильно обобщать новые ситуации.
Машинное обучение — это подход к принятию множества схожих решений, который предполагает алгоритмический поиск закономерностей в ваших данных и их использование для правильной реакции на совершенно новые данные. В жаргоне машинного обучения и ИИ под обобщением понимается способность вашей модели хорошо работать с данными, которые она еще не видела. Какой смысл в модели, основанной на шаблонах, успешно работающей только со старыми данными? Для этого можно просто использовать таблицу поиска. Весь смысл машинного обучения и ИИ заключается в том, чтобы правильно делать корректные обобщения в новых ситуациях.

Именно поэтому первый вид закономерностей в нашем списке – единственный, который хорошо подходит для машинного обучения. Данные этого вида – сигнал, все остальное – просто шум (факторы, которые существуют только в ваших старых данных и мешают при создании обобщаемой модели).
Сигнал: закономерности, которые существуют и в вашем наборе данных, и за его пределами.
Шум: закономерности, которые существуют только в вашем наборе данных.
По сути, получение решения, которое обрабатывает старые шумы, а не новые данные – это то, что называется оверфиттингом в машинном обучении (мы произносим этот термин в том же тоне, в котором вы произносите свое любимое ругательство). В машинном обучении обучении почти все делается для избежания оверфиттинга.
Итак, к какому виду относится *этот* образец?
Предположим, что закономерность, которую вы (или ваш компьютер) извлекли из ваших данных, существует вне вашего воображения – к какой категории она относится? Является ли она реальным феноменом, который существует в интересующей вас совокупности (сигнал) или это особенность вашего датасета (шум)? Как определить тип закономерности, обнаруженной при работе с данными?
Если Вы изучите все имеющиеся данные, то вам не удастся этого сделать. Вы попадете в тупик и не сможете сказать, существует ли ваш шаблон где-либо еще. Вся риторика о проверке статистических гипотез зависит от неожиданности, и делать вид, что уже известный паттерн вас удивляет — дурной вкус (по сути, это хакерство).

Это все равно, что увидеть облако в форме кролика, а затем проверять, все ли облака выглядят как кролики… глядя на одно и того же облако. Надеюсь, вы понимаете, что для проверки вашей теории вам понадобятся новые облака.
Любые данные, используемые для формирования теории или вопроса, не могут быть использованы для проверки той же самой теории.
Что бы вы делали, если бы знали, что у вас есть доступ только к одному облаку? Медитировали в кладовке, вот что. Задайте свой вопрос, прежде чем вы посмотрите на данные.
Математика никогда не противоречит здравому смыслу.
Здесь мы подходим к самому печальному выводу. Если вы используете свой набор данных в поисках вдохновения, то вы не сможете использовать его снова для тщательной проверки теории, которую он вдохновил (какие бы приемы математического джиу-джитсу вы не использовали – математика никогда не противоречит здравому смыслу).
Сложный выбор
Смысл в том, что вы должны сделать выбор! Если у вас только один набор данных, то вы вынуждены спрашивать себя: «Я медитирую в шкафу, формулируя свои гипотезы для статистического тестирования, а затем осторожно принимаю строгий подход – и все это чтобы я мог воспринимать себя всерьез? Или я просто собираю данные для вдохновения, и при этом я понимаю, что, возможно, обманываю себя и помню, что должен использовать такие фразы, как „я чувствую“ или „это вдохновляет“ или „я не уверен“?» Сложный выбор!
Или существует способ съесть один кусок торта дважды? Проблема в том, что у вас только один набор данных, А вам нужно больше, чем один набор данных. А если данных у вас достаточно, то у меня есть хитрость, которая. Взорвет. Ваш. Мозг.

Хитрый трюк
Чтобы добиться успеха в data science, просто превратите один набор данных в два (хотя бы), разделив ваши данные. Затем используйте один для вдохновения, а другой – для тщательного тестирования. Если закономерность, которая изначально вдохновила вас, существует и в данных, которые не могли повлиять на ваше мнение, то вполне вероятно, что эта закономерность – это общее правило, действующее в кошачьем лотке, из которого вы берете свои данные.
Если один и тот же феномен наблюдается в обоих наборах данных, возможно, это общее правило, проявляющееся во всех источниках этих данных.
РСЧД!
Так как жизнь без исследований – это и не жизнь вовсе, вот четыре слова, которыми стоит жить: разделяйте свои чертовы данные.
Мир был бы лучше, если бы все разделяли свои данные. У нас были бы лучшие ответы (благодаря статистике) и лучшие вопросы (благодаря аналитике). Единственная причина, по которой люди не рассматривают разделение данных как обязательную привычку, заключается в том, что в прошлом веке это была роскошь, которую очень немногие могли себе позволить. Наборы данных были настолько малы, что если бы вы попытались их разделить, то, возможно, от них ничего бы не осталось.
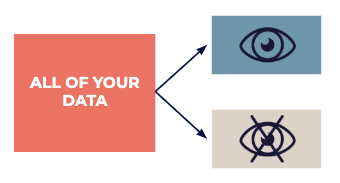
Разделяйте свои данные на доступный всем исследовательский набор данных, который может быть использован для вдохновения, и тестовый, который впоследствии будет использоваться экспертами для точного подтверждения любых «догадок», найденных на этапе исследования.
Некоторые проекты до сих пор сталкиваются с этой проблемой, особенно это касается медицинских исследований (раньше я занималась нейробиологией, поэтому я с большим уважением отношусь к сложности работы с небольшими наборами данных), но многие из вас имеют столько данных, что вам нужно нанимать инженеров, чтобы просто организовать их перемещение… какое у вас оправдание?! Не скупитесь, разделяйте ваши данные.
Если у вас нет привычки разделять данные – возможно вы застряли в XX-м веке.
Если у вас достаточно много данных, при этом их наборы не разделены, то вы существуете в устаревшей парадигме. Люди, существующие в этой парадигме, смирились с архаичным мышлением и отказались двигаться дальше во времени.
Машинное обучение — потомок разделения данных
В конце концов, идея проста. Используйте один набор данных для формирования теории, разберитесь в этих данных, а затем сотворите волшебство — докажите, истинность своих идей на совершенно новом наборе данных.
Разделение данных — самое простое быстрое решение для более здоровой культуры данных.
Таким образом вы сможете безопасно пользоваться статистически методами и застрахуетесь от оверфиттинга. Фактически, история машинного обучения — это история разделения данных.
Как пользоваться лучшей идеей в data science
Чтобы воспользоваться преимуществами лучшей идеи в data science, все, что вам нужно сделать – это убедиться, что вы храните тестовые данные в недоступном для посторонних глаз месте, а затем пусть ваши аналитики сходят с ума по всему остальному.
Чтобы добиться успеха в data science, просто превратите один набор данных в (по крайней мере) два, разделив ваши данные.
Когда вы решите, что они принесли вам полезную информацию, выходящую за рамки изученной ими, используйте ваш секретный тайник с тестовыми данными для проверки своих выводов.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Курс по Machine Learning (12 недель)
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс «Python для веб-разработки» (9 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- Шпаргалка по сортировке для Data Science
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence

