
Ричард Столлман и будущее инноваций в ПО
Давным-давно основным препятствием для инноваций в разработке ПО был доступ к компьютерам.
По мере того как вычисления становились более распространенными, а индустрия ПО стала важной составляющей экономики, препятствием для инноваций в разработке ПО стало не отсутствие доступа к вычислениям (поскольку компьютеры появились везде), а новое явление: в погоне за прибылью корпорации начали ограничивать открытый доступ к ПО.
Такие люди как Ричард Столлман начали с этим бороться.
Ричард Столлман возглавляет движение Free Software Movement, которое показывает, как разработчики проприетарного ПО ограничивают свободу пользователей, а также выявляет слежку и манипулирование в таком ПО и проводит кампании, призывающие заменить проприетарное ПО свободным.
В статье на тему «Почему ПО должно быть свободным» Ричард Столлман утверждает, что разработка ПО должна рассматриваться отдельно от распространения или модификации ПО. Он приводит несколько примеров того как препятствование распространению или модификации ПО наносит вред обществу: меньше людей могут его использовать, никто из пользователей не может его адаптировать или исправить, а другие разработчики не могут учиться на этом ПО или создавать новые проекты на его основе.
Ричард Столлман подчеркивает в своих работах, что переход ценности между потребителем и производителем должен распознаваться, оцениваться количественно и быть прозрачным, для того чтобы эффективно распределять ресурсы.
Ричард Столлман подчеркивает в своих работах, что переход ценности между потребителем и производителем должен распознаваться, оцениваться количественно и быть прозрачным, для того чтобы эффективно распределять ресурсы.
Идея хорошая, но реальность, к сожалению, оказалась не совсем такой, какой ее представлял Столлман.
Реальность: закрыт не только код, но и данные
К сожалению, движение за открытое ПО (пока) не победило. Даже несмотря на то, что open source, как индустрия сейчас больше, чем когда-либо, большая часть кода до сих пор закрыта из-за того, что создатель ПО может получить от экосистемы больший доход, запрещая свободное использование своего ПО.
К сожалению, движение за открытое ПО (пока) не победило. Даже несмотря на то, что open source, как индустрия сейчас больше, чем когда-либо, большая часть кода до сих пор закрыта из-за того, что создатель ПО может получить от экосистемы больший доход, запрещая свободное использование своего ПО.
Важно отметить, что по мере развития индустрии ПО более важным, чем само ПО, становятся данные системы. Данные — это информация о пользователях приложения и о самом веб-сервисе, которые постоянно обновляются в зависимости от того, как люди их используют.
Денис Назаров из Andreessen Horowitz в своей статье на тему «Что придет после open source?», отметил, что переход от персональных инструментов ПО, работающих офлайн (например, Excel, Photoshop), к веб-сервисам (например, Spotify, Netflix, Uber, Instagram) привел к одному ключевому различию: в первом случае пользователи сами хранят собственные данные, а во втором — веб-сервис хранит данные за пользователя. Это и привело к консолидации контроля в руках сервисов, которые аккумулировали данные их пользователей (например, базы данных, содержащие всю информацию о пользователях сервиса).
Со временем, данные этого сервиса становятся важнее чем сам код, на котором работает этот веб-сервис. По мере того, как пользователи создают все больше данных (к которым система в текущий момент имеет доступ), сервис становится более полезным и привлекательным для новых пользователей, тем самым, продолжая наращивать количество данных. Это образует замкнутый круг и сосредотачивает еще больше контроля в руках веб-сервисов.
Например, Spotify совершенствует музыкальные рекомендации при помощи алгоритма анализирующего данные о прослушиваниях, улучшая тем самым опыт пользователя. В результате больше пользователей присоединяются к Spotify, что, в свою очередь, генерирует еще больше данных для Spotify, а затем еще больше улучшает продукт и пользовательский опыт.
Это как маховик: чем больше данных у вас есть как у сервиса, тем ценнее вы в долгосрочной перспективе. Именно так Facebook-Amazon-Netflix-Google стали такими влиятельными компаниями.
2019: инновации мертвы?
Сегодня, потребительские веб-сервисы и облачные сервисы довольно близки к олигополиям. Это плохо для конечного потребителя и для инноваций на рынке в целом. Бен Томпсон в своей теории агрегации пишет, что «Интернет фундаментально изменил конкурентное пространство: распространители больше не соревнуются, основываясь на эксклюзивных отношениях с поставщиком, думая о потребителях/пользователях в последнюю очередь. Вместо этого поставщиков можно сделать товаром, делая потребителей/пользователей главным приоритетом. В более широком смысле это значит, что самый важный фактор, определяющий успех, — это опыт пользователя. Лучшие дистрибьюторы/агрегаторы/маркетмейкеры побеждают, предоставляя лучший опыт, что приносит им больше потребителей/пользователей, и привлекает больше поставщиков, улучшая при этом пользовательский опыт по благоприятному кругу».
Это также означает, что данные, хранящиеся в системах с закрытым состоянием, улучшают пользовательский опыт, помогая доминирующему сервису еще больше наращивать базу данных пользователей. На момент написания этого материала у меня на телефоне было установлено 11 приложений Google, 7 приложений Amazon и 4 приложения Facebook.
В потребительской сети как и в пространстве корпоративного ПО происходит очевидная централизация власти.
Бен Томпсон недавно указывал, что AWS, Azure и другие сервисы облачной инфраструктуры съедят open source компании живьем. Один из примеров — MongoDB, но очевидно, что в будущем жертв будет гораздо больше. AWS и Azure съедят рынок инфраструктуры, а Salesforce, Workday и ServiceNow — рынок приложений для бизнеса.
Здесь важна дистрибьюция: пока эти продавцы каждый день извлекают выгоду из использования открытого ПО, они консолидируют власть благодаря преобладающей дистрибьюции. Они выигрывают, используя ту же формулу, что и их собратья-олигополисты из потребительской сети: чем больше у них будет клиентских данных, тем больше продуктов и услуг они могут продать с помощью апселлинига и перекрестных продаж в будущем.
Итак, что мы имеем?
У нас есть потребительская сеть, находящаяся под контролем компаний, которые можно пересчитать по пальцам одной руки и у нас есть инфраструктурное облако, все больше контролируемое примерно таким же количеством вендоров.
С такой консолидацией, инновациям очень тяжело появиться вне этих компаний.
Если вы начинающий предприниматель в сферах потребительской сети или в корпоративного ПО, то вам будет очень сложно найти пользователей.
Выход
Появилась новая технология, которая расширит возможности для инноваций в ПО.
Что если мы возьмем идеи Ричарда Столлмана об открытом доступе к ПО и реализуем их? И пойдем еще дальше: что если мы также сделаем данные состояния открытыми и доступными для каждого веб-сервиса?
Существует сочетание стимулов и технологий, которое может создать такой мир.
Представьте новый вид вычислений.
По определению Виталика Бутерина, этот вид вычислений децентрализован по архитектуре и политике, но централизован логически.
Он децентрализован по архитектуре, потому что он создан из многих компьютеров, которые общаются между собой. Он децентрализован по политике, потому что огромное количество людей или организаций контролируют компьютеры, из которых состоит эта система. Он централизован логически, потому что существует только одно согласованное всеми состояние и система ведет себя, как один компьютер.
В чем заключаются преимущества такого децентрализованного компьютера?
- Пользователи могут видеть исходный код, который выполняется на бэкенде;
- Все публичные данные находятся в открытом доступе для всех;
- Все публичные данные находятся в открытом доступе для всех;
Назовем это последнее свойство «компaнуемостью сервисов».
Компaнуемость?
Если мы возьмем подход Ричарда Столлмана к открытому ПО и применим его к открытым сервисам, мир изменится до неузнаваемости.
Если мы возьмем подход Ричарда Столлмана к открытому ПО и применим его к открытым сервисам, мир изменится до неузнаваемости.
Если мы перенесем эту же идею на веб-сервисы, это позволит разным сервисам использовать состояния друг друга, в свою очередь позволяя разработчикам повторно использовать веб-сервисы, говорить друг с другом и совершенствовать работу друга друга.
Давайте посмотрим, как это может работать.
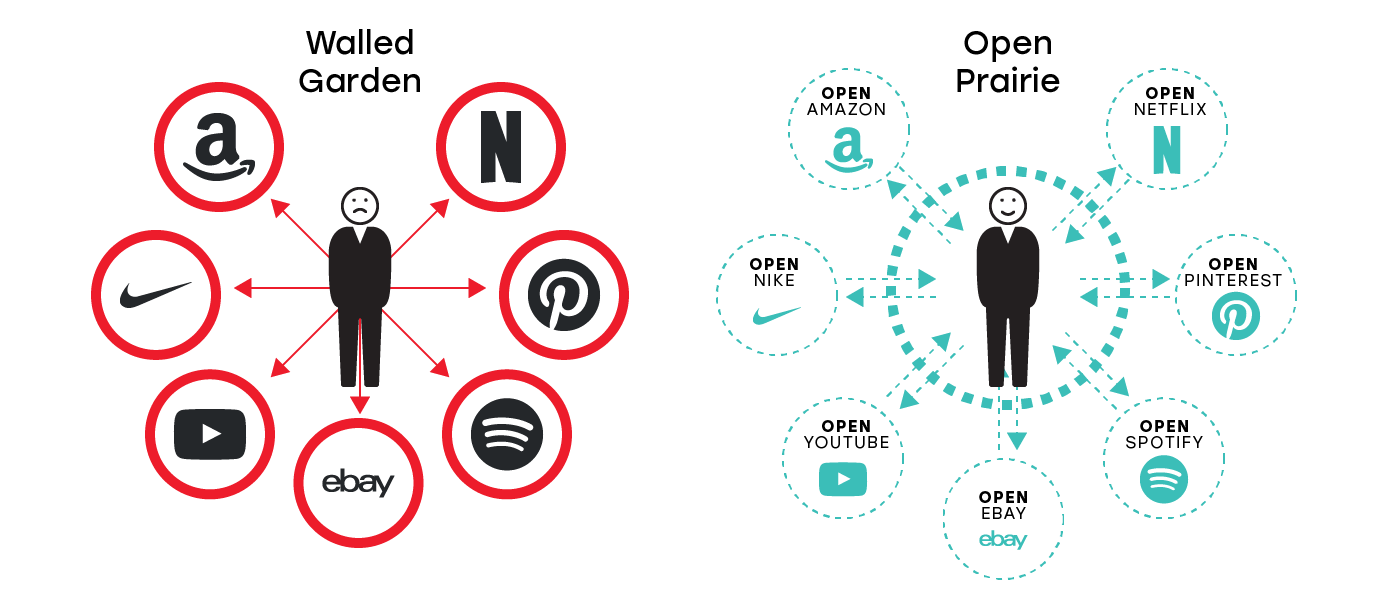
Пример 1: открытые сервисы в борьбе с цензурой
Представьте водителя, который совершил 100 поездок на Uber и получил блестящую репутацию. Представьте сценарий, в котором Uber цензурирует водителя из-за ложной жалобы, в процессе полностью удаляя данные о их репутации.
Если бы существовал OpenUber, который бы был построен на открытых данных, так чтобы сервис мог общаться с другими аналогичными сервисами, этот водитель мог бы перенести свою репутацию в OpenLyft, OpenInstacart, OpenDoorDash и другие веб-сервисы, доступные без дополнительной регистрации, KYC или, что более важно, — без какого-либо риска потери репутации. Это позволяет всем сервисам быть интероперабельными и использоваться повторно для других интерфейсов и бизнесов, делая репутацию пользователей тоже портативной. Это также защищает пользователей от субъективного цензурирования.

Пример 2: Открытые данные для улучшения опыта пользователя
Представьте мир, в котором пользователь хранит свои данные. Пользователь может предоставлять доступ к своим данным в обмен на кастомизированный опыт, таким образом создавая взаимовыгодные отношения.
Например, я предоставляю данные о своих покупках на OpenAmazon сервису OpenNike.com и таким образом позволяю OpenNike.com кастомизировать мой опыт покупки обуви, основываясь на истории прошлых покупок обуви, которая доступна на OpenAmazon.
В таком мире данными владею я, а не корпорация, с которой я работаю. Я предоставляю доступ к данным в обмен на дифференцированный пользовательский опыт. Это мое решение, а не корпорации.
Заключение
Звучит как будущее, частью которого я бы очень хотел стать.
Для этого, мы должны создать новую вычислительную парадигму, которая бы позволяла делать масштабируемые, децентрализованные и открытые сервисы за минуты с помощью интуитивного разработческого опыта.
Этот новый вид вычислений, может создать такое будущее, расширив при этом ограниченные сегодня возможности для инноваций в разработке ПО.
Есть несколько проектов, которые работают над созданием будущего, описанного в этой статье. Solid под руководством Тима Бернерса Ли из MIT строит много фундаментальных вещей. Другой пример — NEAR, который создает инфраструктуру для приложений с открытым состоянием и позволяет сделать такие приложения простыми в разработке, использовании и чтобы при этом у них были рабочие бизнес-модели.
Мы надеемся, что эта статья приведет к появлению большего числа проектов в этой сфере.
Если у вас есть идеи сервисов, управляемых сообществом, и вы хотите над ними работать, приходите в нашу программу поддержки предпринимателей Open Web Collective.
Присоединяйтесь к экосистеме NEAR и будем строить открытый интернет вместе!
Похожие статьи
 Эксклюзивное интервью Хабра с Ником Бостромом
Эксклюзивное интервью Хабра с Ником Бостромом Три секретами европейских валют
Три секретами европейских валют Видеосвязь больше не гарантия: как дипфейки подрывают доверие в бизнесе
Видеосвязь больше не гарантия: как дипфейки подрывают доверие в бизнесе Как мыслит языковая модель
Как мыслит языковая модель Обычные телескопы способны обнаружить межзвездные лазерные маяки внеземных цивилизаций
Обычные телескопы способны обнаружить межзвездные лазерные маяки внеземных цивилизаций Здравый смысл против релятивизма
Здравый смысл против релятивизма Анатомия кожи: как работает ее естественная защита?
Анатомия кожи: как работает ее естественная защита? Глобальная Управляющая Система: интерпретация высшего разума через призму ТАУ и кибернетики
Глобальная Управляющая Система: интерпретация высшего разума через призму ТАУ и кибернетики