
Разработка логического анализатора на базе Redd – проверяем его работу на практике
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd, и отладка на примере теста памяти.
- Разработка простейшей «прошивки» для ПЛИС, установленной в Redd. Часть 2. Программный код.
- Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС.
- Разработка программ для центрального процессора Redd на примере доступа к ПЛИС.
- Первые опыты использования потокового протокола на примере связи ЦП и процессора в ПЛИС комплекса Redd.
- Веселая Квартусель, или как процессор докатился до такой жизни.
- Методы оптимизации кода для Redd. Часть 1: влияние кэша.
- Методы оптимизации кода для Redd. Часть 2: некэшируемая память и параллельная работа шин.
- Экстенсивная оптимизация кода: замена генератора тактовой частоты для повышения быстродействия системы.
- Доступ к шинам комплекса Redd, реализованным на контроллерах FTDI
- Работа с нестандартными шинами комплекса Redd
- Практика в работе с нестандартными шинами комплекса Redd
- Проброс USB-портов из Windows 10 для удалённой работы
- Использование процессорной системы Nios II без процессорного ядра Nios II
- Практическая работа с ПЛИС в комплекте Redd. Осваиваем DMA для шины Avalon-ST и коммутацию между шинами Avalon-MM
- Разработка простейшего логического анализатора на базе комплекса Redd
Сегодня нам очень понадобится опыт, который мы получили в в одной из недавних статей. Там я говорил, что в идеале было бы полезно выучить язык Tcl, но в целом, можно программировать на дикой смеси высокоуровневой логики, описанной на C++ и низкоуровневых запросах на Tcl. Если бы я вёл разработку для себя, то так бы и сделал. Но когда пишешь статью, приходится стараться умять всё в как можно меньшее количество файлов. Одна из задуманных статей так никогда и не была написана именно по этой причине. Мы договорились с коллегой, что он сделает код в рамках проекта, а я потом опишу его. Но он построил код так, как это принято в жизни – раскидал его по огромному количеству файлов. Потом код оброс бешеным количеством технологических проверок, которые нужны в жизни, но за которыми не видно сути. И как мне было описывать всё это? Посмотрите налево, посмотрите направо… Здесь играй, здесь не играй, а здесь коллега рыбу заворачивал? В итоге, полезный материал не пошёл в публикацию (правда, статьи по той тематике всё равно не набирали рейтинга, так что полезный-то он полезный, но мало кому интересный).
Вывод из всего этого прост. Чтобы в статье не бегать от модуля к модулю, пришлось разобраться, как сделать на чистом Tcl. И знаете, не такой это оказался страшный язык. Вообще, всегда можно перейти в каталог C:intelFPGA_lite и задать поиск интересующих слов по файлам *.tcl. Решения почти всегда найдутся. Так что он мне нравится всё больше и больше. Ещё и ещё раз советую приглядеться к этому языку.
Я уже говорил, что при запуске Квартусового Tcl скрипта под Windows и под Linux, тексты должны немного различаться в районе инициализации. Запуск под Linux непосредственно на центральном процессоре Redd’а должен давать большее быстродействие. Но зато запуск под Windows во время опытов более удобен для меня, так как я могу редактировать файлы в удобной для себя среде. Поэтому все дальнейшие файлы я писал под запуск из System Console в Windows. Как их переделать в Линуксовый вариант, мы разбирались в той самой статье по ссылке выше.
Обычно я даю фрагменты кода с пояснениями, а затем уже справочно полный код. Но это хорошо, когда во фрагментах каждый видит что-то знакомое. Так как для многих, кто читает эти строки, язык Tcl считается экзотикой, сначала я приведу для справки полный текст своего первого пробного скрипта.
variable DMA_BASE 0x2000000
variable DMA_DESCR_BASE 0x2000020
# Чтение регистра блока DMA.
#
proc dma_reg_read { address } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
return [master_read_32 $m_path $address 1]
}
# Запись регистра блока DMA
proc dma_reg_write { address data } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
master_write_32 $m_path $address $data
}
# Запись регистра дескрипторов блока DMA
proc dma_descr_reg_write { address data } {
variable DMA_DESCR_BASE
variable m_path
set address [expr {$address * 4 + $DMA_DESCR_BASE}]
master_write_32 $m_path $address $data
}
proc prepare_dma {sdram_addr sdram_size} {
# Остановили процесс, чтобы всё понастраивать
# Да, мне лень описывать все константы,
# я делаю всё на скорую руку
dma_reg_write 1 0x20
# На самом деле, тут должно быть ожидание фактической остановки,
# но в рамках теста, оно не нужно. Точно остановимся.
# Добавляем дескриптор в FIFO
# Адрес источника (вообще, это AVALON_ST, но я всё
# с примеров списывал, а там он зануляется)
dma_descr_reg_write 0 0
# Адрес приёмника.
dma_descr_reg_write 1 $sdram_addr
# Длина
dma_descr_reg_write 2 $sdram_size
# Управляющий регистр (взводим бит GO)
dma_descr_reg_write 3 0x80000000
# Запустили процесс, не забыв отключить прерывания
dma_reg_write 1 4
}
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
puts [master_read_32 $m_path 0 16]
Разбираем фрагменты скрипта
При работе со скриптом нам надо знать базовые адреса блоков. Обычно я их беру из заголовочных файлов, сделанных для BSP, но сегодня мы не создали никаких проектов. Однако адреса всегда можно посмотреть в Platform Designer хоть на привычной нам структурной схеме (я покажу только пример одного адреса):

Хоть там же на специальной вкладке, где всё собрано в виде таблиц:
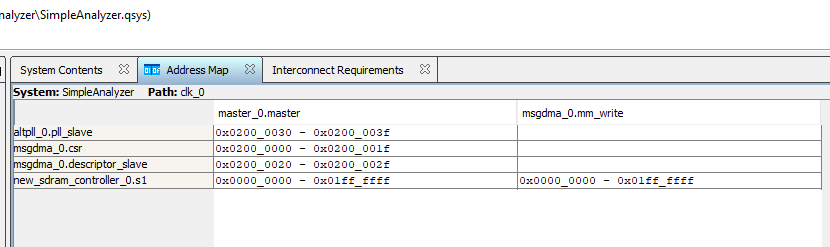
Нужные мне адреса я вписал в начало скрипта (а нулевой начальный адрес буферного ОЗУ я буду подразумевать всегда, чтобы облегчить код):
variable DMA_BASE 0x2000000
variable DMA_DESCR_BASE 0x2000020
Функции доступа к DMA в позапрошлой статье я специально написал в простейшем виде. Сегодня же я просто взял и аккуратно перенёс этот код из C++ в Tcl. Эти функции требуют доступа к аппаратуре, а именно чтения и записи порта самого блока DMA и функция записи порта блока дескрипторов DMA. Читать дескрипторы пока не нужно. Но понадобится – допишем по аналогии. Мы уже тренировались работать с аппаратурой здесь, поэтому делаем такие функции:
# Чтение регистра блока DMA.
#
proc dma_reg_read { address } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
return [master_read_32 $m_path $address 1]
}
# Запись регистра блока DMA
proc dma_reg_write { address data } {
variable DMA_BASE
variable m_path
set address [expr {$address * 4 + $DMA_BASE}]
master_write_32 $m_path $address $data
}
# Запись регистра дескрипторов блока DMA
proc dma_descr_reg_write { address data } {
variable DMA_DESCR_BASE
variable m_path
set address [expr {$address * 4 + $DMA_DESCR_BASE}]
master_write_32 $m_path $address $data
}
Теперь уже можно реализовывать логику работы с DMA. Ещё и ещё раз говорю, что я специально в позапрошлой статье не обращался к готовому API, а сделал как можно более простые собственные функции. Я знал, что мне придётся эти функции портировать. И вот так я портировал инициализацию DMA (аргументы – начальный адрес и длина в байтах для буфера, в который будет идти приём):
proc prepare_dma {sdram_addr sdram_size} {
# Остановили процесс, чтобы всё понастраивать
# Да, мне лень описывать все константы,
# я делаю всё на скорую руку
dma_reg_write 1 0x20
# На самом деле, тут должно быть ожидание фактической остановки,
# но в рамках теста, оно не нужно. Точно остановимся.
# Добавляем дескриптор в FIFO
# Адрес источника (вообще, это AVALON_ST, но я всё
# с примеров списывал, а там он зануляется)
dma_descr_reg_write 0 0
# Адрес приёмника.
dma_descr_reg_write 1 $sdram_addr
# Длина
dma_descr_reg_write 2 $sdram_size
# Управляющий регистр (взводим бит GO)
dma_descr_reg_write 3 0x80000000
# Запустили процесс, не забыв отключить прерывания
dma_reg_write 1 4
}
Ну, собственно, всё. Дальше идёт основное тело скрипта. Какое я там сделал допущение? Я не жду окончания работы DMA. Я же знаю, что таймер тикает весьма быстро. Поэтому запрошенные мною 0x100 байт заполнятся весьма шустро. И все мы знаем, что JTAG работает очень неспешно. В реальной жизни, разумеется, надо будет добавить ожидание готовности. А может и отображение текущего адреса. И ещё чего-нибудь… И тогда код станет точно непригодным для статьи, из-за того, что все эти мелочи станут закрывать суть. А пока простейший код выглядит так:
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
puts [master_read_32 $m_path 0 16]
То есть, настроились на работу с аппаратурой, приняли 0x100 байт в буфер с адресом 0, отобразили первые 16 байт.
Заливаем прошивку, запускаем System Console, исполняем скрипт, наблюдаем такую красоту:

Таймер 0, счётчик 0. Таймер 0x18, счётчик 1. Таймер 0x5EB, счётчик 2. Ну, и так далее. В целом, мы видим то, что хотели. На этом можно было бы и закончить, но текстовое отображение не всегда удобно. Поэтому продолжаем.
Как отобразить результаты в графическом виде
То, что мы получили – это вполне себе замечательно, но временные диаграммы обычного логического анализатора часто удобнее смотреть в графическом виде! Надо бы написать программу, чтобы можно было это делать… Вообще, написать свою программу – всегда полезно, но время – ресурс ограниченный. А в рамках работы с комплексом Redd, мы придерживаемся подхода, что все эти работы – вспомогательные. Мы должны тратить время на основной проект, а на вспомогательный нам никто его не выделит. Можно этим заняться в свободное от работы время, но лично мне это не даёт делать балалайка. Она тоже много времени отнимает. Так что свободное время лично у меня тоже занято. К счастью, уже существуют решения, которые могут облегчить нам жизнь. Я узнал о нём, когда читал статьи про Icarus Verilog. Там строят графическую визуализацию времянок через некие файлы VCD. Что это такое?
В стандарте Verilog (я нашёл его здесь ) смотрим там раздел 18. Value change dump (VCD) files. Вот так! Оказывается, можно заставить тестовую систему на языке Verilog генерировать подобные файлы. И они будут стандартизированы, то есть, едины, независимо от среды, в которой производится моделирование. А где стандарт, там и единство логики систем отображения. А что, если мы тоже будем формировать такой же файл на основании того, что пришло из анализатора? Причём заставим Tcl скрипт делать это… Осталась самая малость: выяснить, что в файл следует записать, а также – как это сделать.
Радостный, я попросил Гугля показать мне пример vcd-файла. Вот, что он мне дал. Я выделил всё, что там было в таблице и сохранил в файл tryme.vcd. Если к моменту чтения статьи страничка перестанет существовать, вот содержимое этого файла – ниже.
$comment
File created using the following command:
vcd files output.vcd
$date
Fri Jan 12 09:07:17 2000
$end
$version
ModelSim EE/PLUS 5.4
$end
$timescale
1ns
$end
$scope module shifter_mod $end
$var wire 1 ! clk $end
$var wire 1 " reset $end
$var wire 1 # data_in $end
$var wire 1 $ q [8] $end
$var wire 1 % q [7] $end
$var wire 1 & q [6] $end
$var wire 1 ' q [5] $end
$var wire 1 ( q [4] $end
$var wire 1 ) q [3] $end
$var wire 1 * q [2] $end
$var wire 1 + q [1] $end
$var wire 1 , q [0] $end
$upscope $end
$enddefinitions $end
#0
$dumpvars
0!
1"
0#
0$
0%
0&
0'
0(
0)
0*
0+
0,
$end
#100
1!
#150
0!
#200
1!
$dumpoff
x!
x"
x#
x$
x%
x&
x'
x(
x)
x*
x+
x,
$end
#300
$dumpon
1!
0"
1#
0$
0%
0&
0'
0(
0)
0*
0+
1,
$end
#350
0!
#400
1!
1+
#450
0!
#500
1!
1*
#550
0!
#600
1!
1)
#650
0!
#700
1!
1(
#750
0!
#800
1!
1'
#850
0!
#900
1!
1&
#950
0!
#1000
1!
1%
#1050
0!
#1100
1!
1$
#1150
0!
1"
0$
0%
0&
0'
0(
0)
0*
0+
0,
#1200
1!
$dumpall
1!
1"
1#
0$
0%
0&
0'
0(
0)
0*
0+
0,
$end
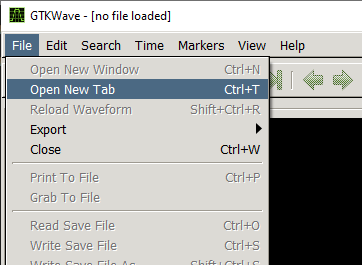
Какое-то «Юстас Алексу». Можно, конечно, разобраться, глядя в стандарт, но больно там много всего. Попробуем всё сделать на практике, загрузив файл в какую-нибудь среду, визуализирующую его содержимое, и сопоставив текст с полученной картинкой. Несмотря на то, что заголовок web-страницы гласит, что всё это – пример от среды ModelSim, мне не удалось открыть данный файл в этой среде. Возможно, в комментариях кто-то подскажет, как это сделать. Однако не МоделСимом единым жив человек. Существует такая кроссплатформенная система с открытым исходным кодом — GtkWave. Сборку под Windows я взял тут . Запускаем её, выбираем в меню File->Open New Tab:
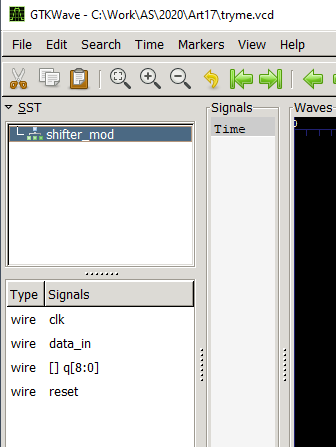
Указываем наш файл и получаем такую картинку:
Выделяем все сигналы и через меню правой кнопки «Мыши» выбираем Recurse Import->Append:
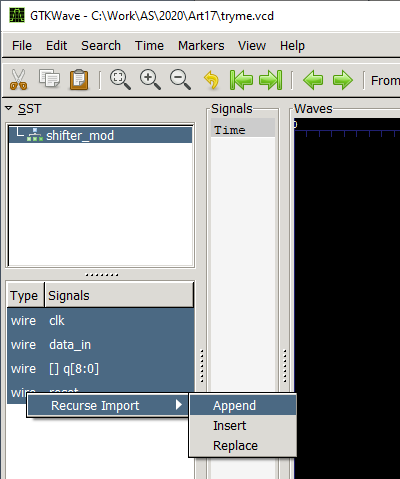
И вот результат:
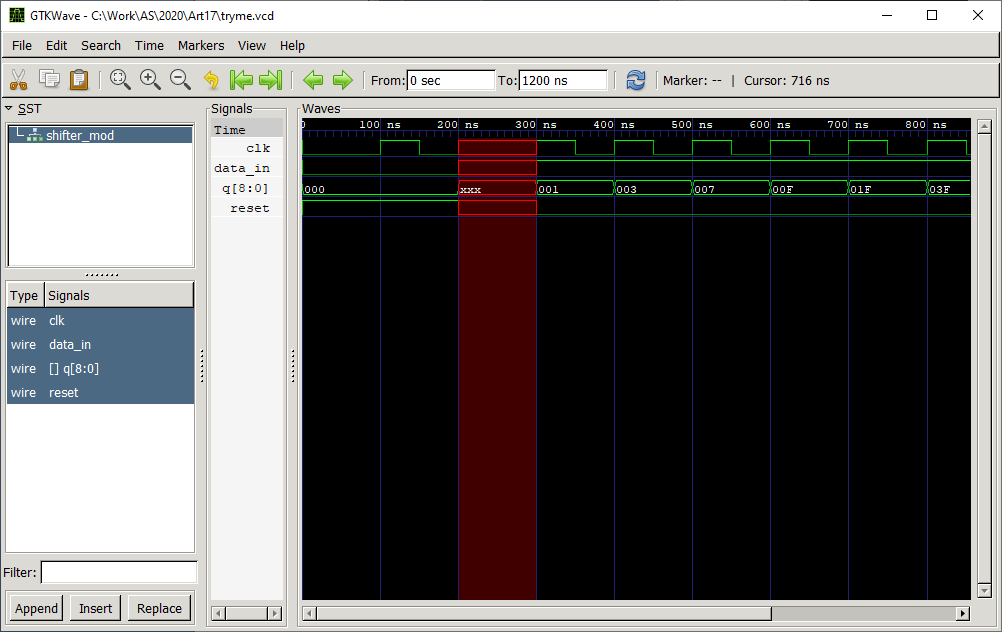
Видя такое дело, вполне можно разобраться, что в файле зачем добавлено.
$timescale
1ns
$end
Ну, тут всё понятно. Это в каких единицах время будет задаваться.
$scope module shifter_mod $end
$var wire 1 ! clk $end
$var wire 1 " reset $end
$var wire 1 # data_in $end
$var wire 1 $ q [8] $end
$var wire 1 % q [7] $end
$var wire 1 & q [6] $end
Это объявляются переменные с весьма экзотическими именами «Восклицательный знак», «Кавычки», «решётка» и т.п. Шина в найденном примере объявляется побитово. Идём дальше:
#0
$dumpvars
0!
1"
0#
…
0+
0,
$end
Время равно нулю. Дальше – значения переменных. Зачем ключевое слово $dumpvars? Придётся заглянуть в стандарт. Как я и думал, какое-то непонятное занудство. Но создаётся впечатление, что нам сообщают, что эти данные получены при помощи директивы языка $dumpvars. Давайте попробуем убрать это слово и соответствующую ему строку $end. Загружаем обновлённый файл и видим результат:
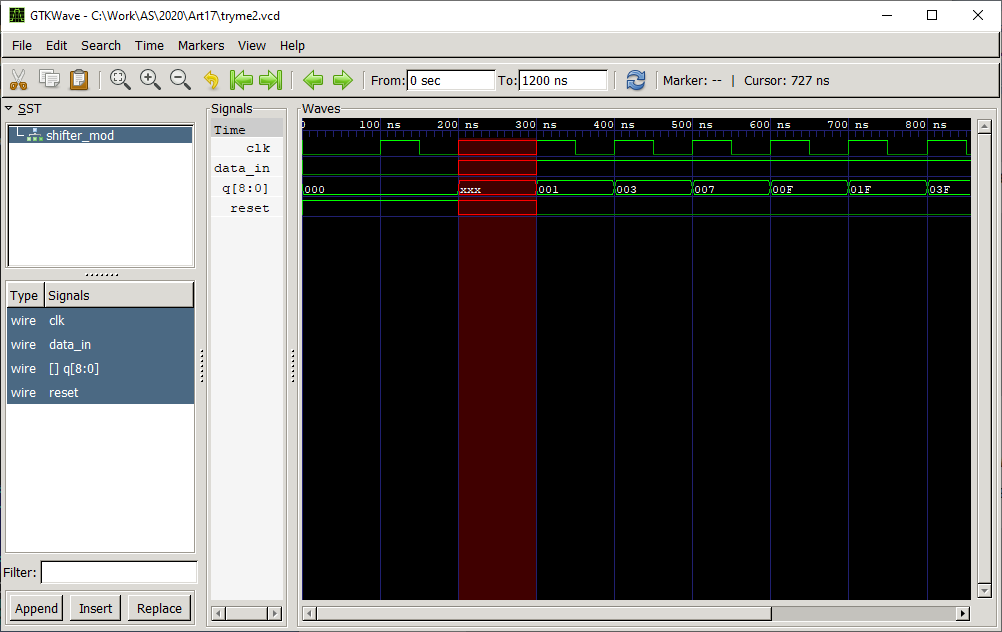
Как говорится, найдите десять отличий… Никакой разницы. Значит, нам это добавлять на выход не нужно. Идём дальше.
#100
1!
#150
0!
Мы видим, что в моменты 100 и 150 нс тактовый сигнал переключился, а остальные – нет. Поэтому мы можем добавлять только изменившиеся значения сигналов. Идём дальше.
#200
1!
$dumpoff
x!
x"
…
x,
$end
#300
$dumpon
1!
0"
Теперь мы умеем задавать состояние «X». Проверяем, нужны ли ключевые слова $dumpoff и $dumpon, выкинув их из файла (не забываем про парные им $end)…
Добавлять ещё один рисунок, полностью идентичный предыдущим, я не буду. Но можете проверить это же у себя.
Итак, мы уже получили всю информацию для формирования файла, только меня очень интересует один вопрос. Можно ли задавать многобитные сигналы не в виде одиночных битов, а оптом? Смотрим, что нам про это говорит стандарт:

vcd_declaration_vars ::=
$var var_type size identifier_code reference $end
var_type ::=
event | integer | parameter | real | realtime | reg | supply0 | supply1 | time
| tri | triand | trior | trireg | tri0 | tri1 | wand | wire | wor
size ::=
decimal_number
reference ::=
identifier
| identifier [ bit_select_index ]
| identifier [ msb_index : lsb_index ]
index ::=
decimal_number
Прекрасно! Мы можем задавать и вектора! Пробуем добавить одну переменную, дав ей имя «звёздная собака», так как односимвольные варианты уже израсходованы авторами оригинального примера:
$var reg 32 *@ test [31:0] $end
И добавим ей таких присвоений… Обратите внимание на пробелы перед именем переменной! Без них не работает, но и стандарт требует их наличия в отличие от однобитных вариантов:
#0
…
b00000001001000110100010101100111 *@
#100
…
b00000001XXXX0011010001010110zzzz *@
Смотрим результат (я в нём ради интереса раскрыл вектор)

Ну и замечательно. У нас есть вся теория, чтобы подготовить файл для просмотра в GtkWave. Наверняка, можно будет его посмотреть и в ModelSim, просто я пока не понял, как это сделать. Давайте займёмся формированием данного файла для нашего супер-мега-анализатора, который фиксирует одно единственное число.
Делаем Tcl-скрипт, создающий файл VCD
Если весь предыдущий опыт я брал из файлов *.tcl, идущих в комплекте с Квартусом, то здесь всё плохо. Слово file есть в любом из них. Пришлось спросить у Гугля. Он выдал ссылку на замечательный справочник.
Функции не трогаем, а основное тело скрипта переписываем так.
puts "running"
set m_path [lindex [get_service_paths master] 0]
open_service master $m_path
prepare_dma 0 0x100
set fileid [open "ShowMe.vcd" w]
puts $fileid "$timescale"
puts $fileid " 1ns"
puts $fileid "$end"
puts $fileid "$scope module megaAnalyzer $end"
puts $fileid "$var reg 32 ! data [31:0] $end"
puts $fileid "$upscope $end"
puts $fileid "$enddefinitions $end"
# А зачем рисовать где-то справа?
# Будем рисовать от первой точки
# Для этого запомним базу
set startTime [lindex [master_read_32 $m_path 0 1] 0]
for { set i 0} {$i < 20} {incr i} {
set cnt [lindex [master_read_32 $m_path [expr {$i * 8}] 1] 0]
set data [lindex [master_read_32 $m_path [expr {$i * 8 + 4}] 1] 0]
# Таймер тикает с частотой 100 МГц
# Один тик таймера - это 10 нс
# поэтому на 10 и умножаем
puts $fileid "#[expr {($cnt - $startTime)* 10}]"
puts $fileid "b[format %b $data] !"
}
close $fileid
Здесь я не стал учитывать перескоки счётчика через ноль. Перед нами – простейший демонстрационный скрипт, так что не будем его перегружать. Запускаем… Дааааа. Это – именно то, о чём я предупреждал. Оно работает весьма и весьма долго. Сколько оно будет работать в случае заполненных мегабайтных буферов – страшно даже предположить. Но зато мы не потратили много времени на разработку! Опять же, кто работал с анализатором BusDoctor, тот не даст соврать: этот фирменный анализатор отдаёт данные больших объёмов тоже очень и очень неспешно.
$timescale
1ns
$end
$scope module megaAnalyzer $end
$var reg 32 ! data [31:0] $end
$upscope $end
$enddefinitions $end
#0
b0 !
#240
b1 !
#15150
b10 !
#25170
b11 !
#26510
b100 !
#26690
b101 !
#31180
b110 !
#31830
b111 !
#35540
b1000 !
#35630
b1001 !
#36940
b1010 !
#39890
b1011 !
#46130
b1100 !
#55540
b1101 !
#60820
b1110 !
#71270
b1111 !
#71480
b10000 !
#76270
b10001 !
#77990
b10010 !
#91000
b10011 !
Случайные промежутки – есть. Нарастающее двоичное число – есть. Правда, с отброшенными незначащими нулями. Визуализируем:

Счётчик щёлкает! В случайные моменты времени. Что хотели, то и получили
Заключение
Мы сделали простейший логический анализатор, потренировались принимать данные с него и производить их визуализацию. Чтобы довести этот простейший пример до совершенства, разумеется, придётся ещё потрудиться. Но путь, по которому идти, – понятен. Мы получили опыт изготовления реальных измерительных устройств на базе ПЛИС, установленной в комплексе Redd. Теперь каждый сможет доработать эту основу так, как сочтёт нужным (и как ему позволит время), а в следующей серии статей я начну рассказ о том, как заменить этому анализатору голову, чтобы сделать шинный анализатор для USB 2.0.
Те, у кого нет настоящего Redd, смогут воспользоваться вот такой свободно доставаемой платой, которая имеется у массы продавцов на Ali Express.

Искать следует по запросу WaveShare ULPI. Подробнее о ней – на странице производителя.
Похожие статьи
 Xiaomi повысила цены на смартфоны в Китае: подорожали флагманы и модели Redmi
Xiaomi повысила цены на смартфоны в Китае: подорожали флагманы и модели Redmi Массовые увольнения в IT: за 2026 год мировые компании сократили более 124 тысяч сотрудников из-за ИИ
Массовые увольнения в IT: за 2026 год мировые компании сократили более 124 тысяч сотрудников из-за ИИ Статистика Steam зафиксировала исторический перелом: 16-гигабайтные видеокарты и 8-ядерные процессоры впервые стали популярнее аналогов с 8 и 6 ядрами
Статистика Steam зафиксировала исторический перелом: 16-гигабайтные видеокарты и 8-ядерные процессоры впервые стали популярнее аналогов с 8 и 6 ядрами Реальная скорость Redmi K100 Pro Max с экраном 185 Гц, батареей 9070 мАч и звуком Bose разочаровала тестами
Реальная скорость Redmi K100 Pro Max с экраном 185 Гц, батареей 9070 мАч и звуком Bose разочаровала тестами Анонсирован мини-ПК Asus VM31 с интегрированной памятью
Анонсирован мини-ПК Asus VM31 с интегрированной памятью Секрет идеального снимка Млечного Пути с МКС: как астронавт NASA сделал невозможное фото без смазанных звезд
Секрет идеального снимка Млечного Пути с МКС: как астронавт NASA сделал невозможное фото без смазанных звезд Продажи Huawei Mate 80 превысили 8,1 миллиона штук — это рекорд для бренда
Продажи Huawei Mate 80 превысили 8,1 миллиона штук — это рекорд для бренда Oppo A7 Pro Max получит 7-летнюю батарею на 10 000 мАч, камеры по 50 Мп и станет лучшим в серии A
Oppo A7 Pro Max получит 7-летнюю батарею на 10 000 мАч, камеры по 50 Мп и станет лучшим в серии A