
Наш день начинается с фразы «Доброе утро!». В течение дня мы общаемся с коллегами, родными, друзьями и даже с незнакомыми прохожими, которые спрашивают дорогу до ближайшего метро. Мы говорим даже тогда, когда вокруг нас никого нет, дабы лучше воспринять собственные рассуждения. Все это наша речь — дар, воистину несопоставимый с многими другими возможностями человеческого организма. Речь позволяет нам устанавливать социальные связи, выражать мысли и эмоции, самовыражаться, например, в песнях.
И вот в жизни людей появились умные машины. Человек, то ли от любопытства, то ли от жажды новых свершений, пытается научить машину говорить. Но для того, чтобы говорить, нужно слышать и слушать. В наше время сложно удивить программой(например Siri), способной распознать речь, чтобы найти на карте ресторан, позвонить маме, даже рассказать анекдот. Она понимает многое, не все, конечно, но многое. Но так было не всегда, естественно. Десятилетия назад было за счастье, когда машина могла понять хотя бы десяток слов.
Сегодня мы с вами окунемся в историю того, как человечество смогло заговорить с машиной, какие прорывы в течение веков в этой области послужили толчком развития технологии распознавания речи. Также рассмотрим как современные устройства воспринимают и обрабатывают наши голоса. Поехали.
Истоки распознавания речи
Что есть речь? Грубо говоря, это звук. А значит для того, чтобы распознать речь, нужно для начала распознать звук и записать его.
Сейчас у нас есть iPod, MP3-плееры, раньше были магнитофоны, еще раньше патефоны и граммофоны. Все это устройства для воспроизведения звуков. Но кто же был прародителем их всех?

Томас Эдисон со своим изобретением. 1878 год
Это был фонограф. 29 ноября 1877 года великий изобретатель Томас Эдисон продемонстрировал свое новое творение, способное записывать и воспроизводить звуки. Это был прорыв, вызвавший живейший интерес общества.
Принцип работы фонографа
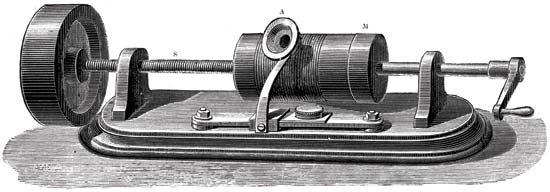
Основными деталями механизма для записи звука были цилиндр с покрытием из фольги и игла-резец. Игла перемещалась по цилиндру, который вращался. А механические колебания улавливались с помощью мембраны-микрофона. В результате чего игла оставляла отметки на фольге. В результате мы получали цилиндр с записью. Для ее воспроизведения изначально использовался тот же цилиндр, что и при записи. Но фольга была слишком хрупкая и быстро изнашивалась, потому записи были недолговечны. Далее начали применять воск, которым покрывали цилиндр. Для того, чтобы продлить существование записей, их начали копировать с использованием гальванопластики. За счет использования более твердых материалов копии служили гораздо дольше.
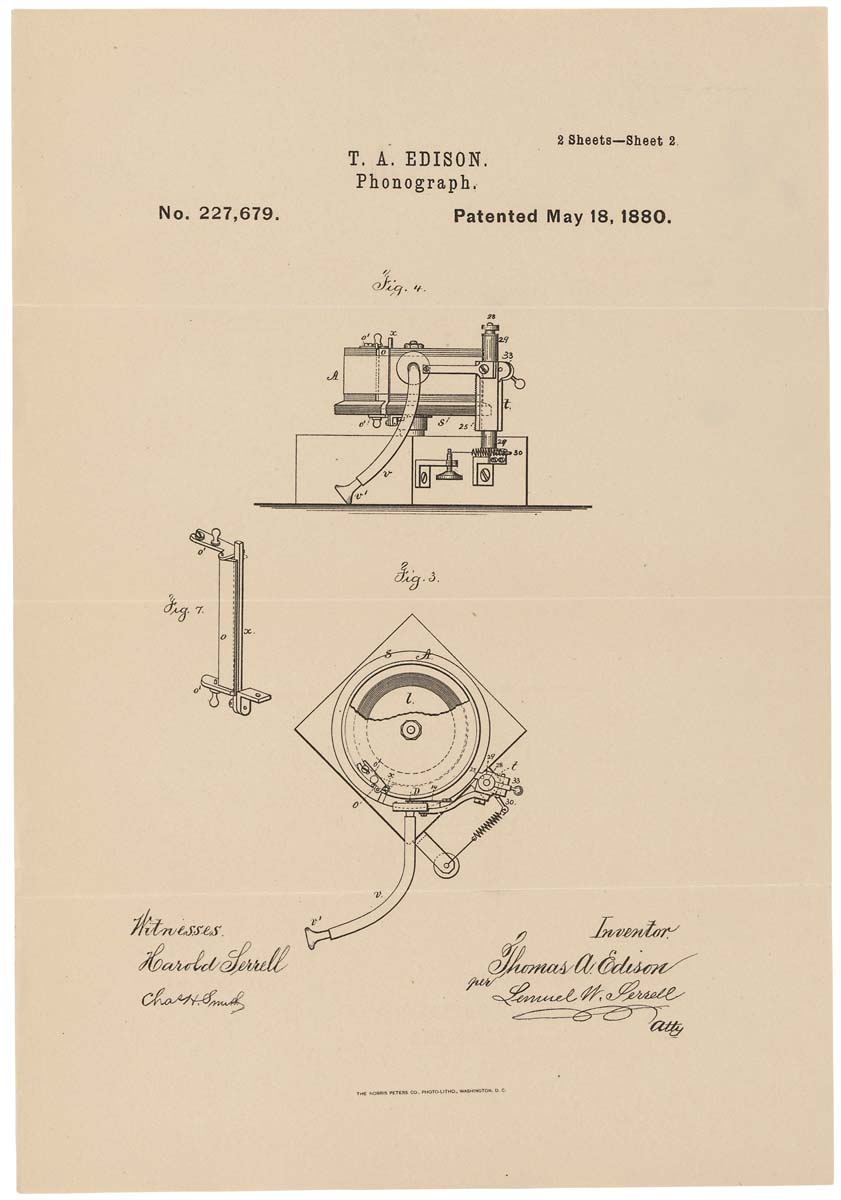
Схематическое изображение фонографа на патенте. 1880 год, 18 мая
Учитывая вышеуказанные недостатки, фонограф хоть и был интересной машиной, но его не сметали с прилавков. Только при появлении дискового фонографа — более известного под названием граммофон — пришло общественное признание. Новинка позволяла делать более продолжительные записи (первый фонограф мог записать всего пару минут), которые служили долго. А сам граммофон был оснащен рупором, который увеличивал громкость воспроизведения.
Томас Эдисон изначально задумывал фонограф как устройство для записи телефонных разговоров, вроде современных диктофонов. Однако его творение приобрело большую популярность в воспроизведении музыкальных произведений. Послужив началом для становления звукозаписывающей индустрии.
Речевой «орган»
Bell Labs знаменита своими изобретениями в области телекоммуникаций. Одним из таких изобретений был водер (Voder).
Еще в 1928 году Гомер Дадли (Homer Dudley) начал работу над вокодером — устройством, способным синтезировать речь. О нем мы поговорим позднее. Сейчас же рассмотрим его часть — водер.

Схематическое изображение водера
Основным принципом работы водера была разбивка человеческой речи на акустические компоненты. Машина была крайне сложной, и управлять ею мог только обученный оператор.
Водер имитировал эффекты голосового тракта человека. Было 2 основных звука, которые мог выбрать оператор своим запястьем. Ножные педали использовались для контроля генератора разрывных колебаний (гудящий звук), создававшего озвученные гласные и носовые звуки. Газоразрядная трубка (шипение) создавала сибилянтов (фрикативных согласных). Все эти звуки проходили через один из 10 фильтров, который выбирался клавишами. Также были специальные клавиши для таких звуков как «p» или «d», и для аффрикатов «j» в слове «jaw» и «ch» в слове «cheese».
Этот небольшой отрывок из презентации водера наглядно демонстрирует принцип его работы и действий оператора
Выдать допустимо распознаваемую речь оператор мог только после нескольких месяцев усердной практики и тренировок.
Впервые водер был продемонстрирован на выставке в Нью Йорке в 1939 году.
Экономия через синтез речи
А теперь рассмотрим вокодер, частью которого был вышеупомянутый водер.

Одна из моделей вокодера: HY-2 (1961 год)
Вокодер изначально предназначался для экономии частотных ресурсов радиолиний при передаче голосовых сообщений. Вместо самого голоса передавались значения его определенных параметров, которые на выходе обрабатывались синтезатором речи.
Базисом вокодера было три основных свойства:
- генератор шума (согласные звуки);
- генератор тонального сигнала (гласные звуки);
- формальные фильтры (воссоздание индивидуальных особенностей говорящего).
Несмотря на свое серьезное назначение, вокодер привлек внимание электронных музыкантов. Преобразование сигнала источника и его воспроизведение на другом устройстве позволяло достигать разнообразных эффектов, как например эффект поющего «человеческим голосом» музыкального инструмента.
Считалочка для машины
В далеком 1952 году технологии были не столь развиты, как сейчас. Но это не мешало ученым-энтузиастам ставить перед собой невыполнимые, по мнению многих, задачи. Так и господа Стивен Балашек (S. Balashek), Ралон Биддалф (R. Biddulph) и К.Х. Девис (K. H. Davis) решили научить машину понимать их речь. На свет вслед за идеей появилась машина Одри (Audrey). Ее возможности были весьма ограничены — она могла распознать только цифры от 0 до 9. Но и этого уже было достаточно, чтобы смело заявить о прорыве в компьютерных технологиях.

Одри с одним из своих создателей (если верить Интернету, поправьте меня, если это не так)
Несмотря на свои небольшие возможности, такими же габаритами Одри похвастаться не могла. Она была довольно крупной «девочкой» — шкаф реле был почти 2 метра в высоту, а все элементы занимали небольшую комнату. Что не удивительно для ЭВМ того времени.
Процедура взаимодействия оператора и Одри также обладала некоторыми условиями. Оператор произносил слова (цифры, в данном случае) в трубку обычного телефона, обязательно выдерживая паузу в 350 миллисекунд между каждым словом. Одри принимала информацию, переводила ее в электронный формат и включала определенную лампочку, соответствующую той или иной цифре. Не говоря уже о том, что не каждый оператор мог получить точный ответ. Для достижения точности 97% оператором должен был быть человек, который долгое время практиковался в «болтовне» с Одри. Другими словами, понимала Одри только своих создателей.
Даже учитывая все недостатки Одри, которые связаны не с ошибками проектирования, а с ограничениями технологий тех времен, она стала первой звездой на небосклоне машин, понимающих человеческий голос.
Будущее в обувной коробке
В 1961 году в лаборатория развития передовых систем IBM было разработано новое чудо-устройство — Shoebox, способное распознавать 16 слов (на английском исключительно) и цифры от 0 до 9. Автором сего компьютера был Вильям Дерч (William C. Dersch).

Shoebox от IBM
Необычное название соответствовало внешнему облику машины, она была размером и формой как коробка для обуви. Единственное, что бросалось в глаза, это микрофон, который присоединялся к трем аудио-фильтрам, необходимым для распознания высоких, средних и низких звуков. Фильтры были соединены с логическим декодером (диодно-транзисторная логическая схема) и механизмом включения лампочек.
Оператор подносил микрофон ко рту и произносил слово (например, цифру 7). Машина преобразовывала акустические данные в электронные сигналы. Результатом понимания было включение лампочки с подписью «7». Помимо понимания отдельных слов, Shoebox могла понимать простые арифметические задачки (как 5+6 или 7-3) и выдавать верный ответ.
Shoebox был представлен своим же творцом в 1962 году на всемирной выставке в Сиэтле.
Телефонный разговор с машиной
В 1971 году компания IBM, известная своей любовью к новаторским изобретениям и технологиям, решила применить распознавание речи на практике. Automatic Call Identification system (Автоматическая система идентификации звонков) позволяла инженеру, находившемуся где угодно в США, позвонить компьютеру в Роли (Северная Каролина). Звонящий мог задать вопрос и получить на него голосовой ответ. Уникальность данной системы заключалась в понимании множества голосов, учитывая их тональность, акцент, громкость речи и т.д.
Высоко взлетевшая Гарпия
Управление перспективных исследовательских проектов Министерства обороны США (сокращенно DARPA) в 1971 году объявили о начале программы по разработке и исследованиям в области распознавания речи, целью которой является создание машины, способной распознать 1000 слов. Смелый проект, учитывая успехи предшественником, исчисляемые десятками слов. Но нет предела человеческой находчивости. И вот в 1976 году университет Карнеги-Меллон демонстрирует Harpy, способную распознать 1011 слов.
Видео-демонстрация принципа работы Harpy
Университет уже разрабатывал системы распознавания речи — Hearsay-1 и Dragon. Они использовались как основы для реализации Harpy.
В Hearsay-1 знания (т.е. словарь машины) представлен в виде процедур, а в Dragon — в виде Марковской сети с априорным вероятностным переходом. В Harpy было решено использовать последую модель, но без данного перехода.
Проще говоря можно изобразить сеть — последовательность слов и их сочетаний, а также звуков с отдельном слове, для понимания машиной различного произношения одного и того же слова.
Harpy понимала 5 операторов, из них трое мужчин и две женщины. Что говорило о большей вычислительной возможности данной машины. Точность распознавания речи составляла примерно 95%.
Tangora от IBM
В начале 1980-ых компания IBM решила разработать к середине десятилетия систему, способную распознавать более 20 000 слов. Так родилась Tangora, в работе которой использовались скрытые марковские модели. Несмотря на довольно внушительный словарик, системе требовалось не более 20 минут совместной работы с новым оператором (говорящем человеком), чтобы обучиться распознаванию его речи.
Ожившая кукла
В 1987 году компания по производству игрушек Worlds of Wonder выпустила революционную новинку — говорящую куклу по имени Julie. Самой впечатляющей особенностью датской игрушки была возможность обучить ее распознавать речь владельца. Julie могла вполне сносно общаться. Помимо этого, кукла была оснащена множеством датчиков, благодаря которым она реагировала, когда ее поднимали, щекотали или переносили из темного в светлое помещение.
Рекламный ролик Julie от Worlds of Wonder с демонстрацией ее возможностей
Ее глаза и губы были подвижны, что создавало еще более живой образ. В дополнение к самой кукле можно было приобрести книгу, в которой картинки и слова были выполнены виде специальных наклеек. Если провести пальчиками куклы по ним, то она будет озвучивать то, что «чувствует» на ощупь. Кукла Julie стала первым устройством с функцией распознавания речи, который был доступен любому желающему.
Первый софт для диктовки

В 1990 году компания Dragon Systems выпустила первое программное обеспечение для персональных компьютеров, основой которого было распознавание речи — DragonDictate. Работала программа исключительно на Windows. Пользователю приходилось делать небольшие паузы между каждым словом, чтобы программа могла их разобрать. В дальнейшем появилась более совершенная версия, позволяющая говорить непрерывно — Dragon NaturallySpeaking (именно она и доступна сейчас, в то время как оригинальная DragonDictate перестала обновляйся еще со времен Windows 98). Несмотря на свою «медлительность», программа DragonDictate приобрела большую популярность среди пользователей ПК, особенно среди людей с ограниченными возможностями.
Не египетский Сфинкс
Университет Карнеги-Меллон, который уже «засветился» ранее, стал местом рождения еще одной исторически важной системы распознавания речи — Sphinx 2.

Создатель Sphinx Ксаедонг Ханг (Xuedong Huang)
Непосредственным автором системы стал Ксаедонг Ханг (Xuedong Huang). От своей предшественницы Sphinx 2 отличало ее быстродействие. Система была ориентирована на распознавание речи в реальном времени для программ, где используется разговорный (бытовой) язык. Среди особенностей Sphinx 2 были: формирование гипотез, динамическое переключение между языковыми моделями, обнаружение эквивалентов и т.д.
Код Sphinx 2 был использован во множестве коммерческих продуктах. А в 2000 году на сайте SourceForge Кевин Лензо выложил исходный код системы для всеобщего ознакомления. Желающие изучить исходный код Sphinx 2 и других его вариаций могут перейти по ссылке.
Медицинский диктант
В 1996 году IBM запустили MedSpeak, ставший первым коммерческим продуктом с функцией распознавания речи. Предполагалось использование данной программы в медики для формирования записей врачей. К примеру, рентгенолог, осматривая снимки пациента, озвучила свои комментарии, которые система MedSpeak переводила в текст.
Прежде чем перейти к самым знаменитым представителям программ с функцией распознавания речи, давайте быстренько, вкратце, рассмотрим еще несколько исторических событий связанных с данной технологией.
Исторический блиц
- 2002 год — Microsoft интегрирует распознавание речи во все свои продукты серии Office;
- 2006 год — Агентство национальной безопасности США начинает использование программ распознавания речи для определения в записях разговоров предельных ключевых слов;
- 2007 год (30 января) — Microsoft выпускает Windows Vista — первую ОС с распознаванием речи;
- 2007 год — Google представляет GOOG-411 — система телефонной переадресации (человек звонит на номер, говорит какая организация или человек ему нужен и система их соединяет). Работала система в пределах США и Канады;
- 2008 год (14 ноября) — Google запускает голосовой поиск на мобильных устройствах iPhone. Это стало первым использованием технологии распознавания речи в мобильных телефонах;
И вот мы подошли к временному периоду, когда с технологией распознавания речи столкнулось множество людей.
Дамы, не ссорьтесь
4 октября 2011 года компания Apple анонсировала Siri, расшифровка названия которой говорит само за себя — Speech Interpretation and Recognition Interface (т.е. Интерфейс интерпретации и распознавания речи).

История разработки Siri очень долгая (по факту насчитывает 40 лет труда) и интересная. Сам факт ее существования и обширного функционала это совместная работа множества компаний и университетов. Однако мы не будем заострять свое внимание на данном продукте, ибо статья не о Siri, а о распознавании речи в целом.
Microsoft не хотели пасти задних, потому уже в 2014 году (2 апреля) анонсировали свой виртуальный цифровой помощник Cortana.

Функционал Cortana схож с ее конкуренткой Siri, за исключением более гибкой системы настроек доступа к информации.
Дебаты на тему «Cortana или Siri. Кто лучше?» ведутся со времен их появления на рынке. Как, в целом, и борьба между пользователями iOS и Android. Но это хорошо. Конкурирующие продукты, в попытке казаться лучше соперника будут предоставлять все новые и новые возможности, развивать и использовать более совершенные технологии и техники в той же сфере распознавания речи. Имея лишь одного представителя в какой-либо сфере потребительских технологий, говорить о быстром развитии оной не приходиться.
Небольшое забавное видео беседы Siri и Cortana (явно построенное, но от то не менее забавное). Внимание!: в данном видео присутствует ненормативная лексика.
Разговор с машинами. Как они нас понимают?
Как я уже упоминал ранее, грубо говоря, речь это звук. А что есть звук для машины? Это изменения (колебания) давления воздуха, т.е. звуковые волны. Для того чтобы машины (компьютер или телефон) смог распознать речь необходимо сначала считать эти колебания. Частота измерений должна быть как минимум 8000 раз в секунду (еще лучше — 44 100 раз в секунду). Если измерения будут проводится с большими временными прерываниями, то мы получим неточный звук, а значит неразборчивую речь. Вышеописанный процесс именуется оцифровкой в 8kHz или 44.1kHz.
Когда данные по колебаниям звуковых волн собраны, их нужно отсортировать. Так как в общей куче мы имеет и речь, и побочные звуки (шум машин, шелест бумаги, звук работающего компьютера и т.д.). Проведение математических операций позволяет отсеять именно нашу речь, которая и нуждается распознавании.
Далее идет анализ выделенной звуковой волны — речи. Поскольку она состоит из множества отдельных составляющих, формирующих те или иные звуки (например, «ah» или «ee»). Выделение этих особенностей и преобразование их в числовые эквиваленты позволяет определить конкретные слова.
Английский язык, к примеру, состоит из более 40 фонем (44, если быть точным, а по некоторым теориям их более 100), т.е. речевых звуков. Машина определяет их все, поскольку в процессе ее разработки были проведены тренировочные тесты, в течение которых разные люди произносили одни и те же слова и фразы. Так машина могла определить сходства и отличия и сформировать алгоритм определения звуков. Стоит учитывать и тот факт, что на то, как «выглядит» звук, влияет не только человек (а точнее, его произношение, акцент, тембр голоса и т.д.), но и сочетание разных фонем в одном слове. К примеру, «t» в «sTar» и «t» в «ciTy» для машины выглядят совершенно по-разному.
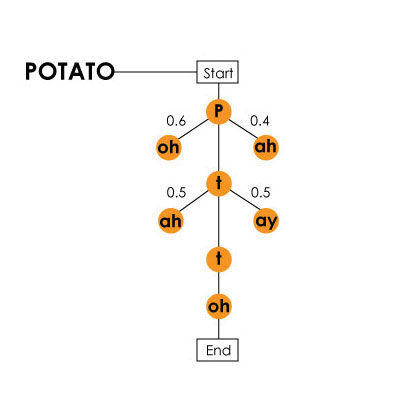
Модель Маркова на примере слова «potato» (картфель) / присутствует в видео о системе Harpy
Далее компьютеру необходимо, следуя моделям формирования словесных последовательностей, определить где именно стоит разделить слова. Например, есть фраза «hang ten», которую компьютер не сможет разделить вот так — «hey, ngten», поскольку не найдет в своей базе совпадений с «ngten».
Для того, чтобы компьютер не выдавал тарабарщину вместо сказанной фразы, ему необходимо понимать какие слова идут за какими. Для этого используется не только база знаний, позволяющая определить составляющие фразы (слова), но и алгоритм частичной гипотезы, с помощью которого машина определяет уместно ли слово№2 в связке со словом№1. Фразу «What do cats like for breakfast?» можно услышать как «water gaslight four brick vast?». Брэд, не так ли. Именно для недопущения подобных оплошностей и нужен вышеописанный алгоритм. В нем также может учитываться и возможность сочетания слов, которые, по логике машины, не должны сочетаться. Но данное усовершенствование модели алгоритма гипотез требует гораздо большей мощности.
После завершения всех этих сложных математических, статистических и измерительных процедур компьютер выдает пользователю результат. Вся красота данной технологии, а точнее данной технологии на данном этапе ее развития, заключается в невероятном быстродействии системы.
Эпилог
Как мы видим, столь современная и удивительная технология начала свой путь довольно давно. Еще в позапрошлом веке. Если в те времена кто-то сказал бы, что в будущем можно будет побеседовать с телефоном (не говоря уже о том, что он беспроводной), никто бы не поверил. А автора таких высказываний возможно принудительно лечили бы в соответствующей больнице. Но сейчас данная технология стала столь же обыденной, как смартфоны, ноутбуки, Интернет и многое другое. Будущие поколения вообще могут и не вспомнить, что когда-то, давным давно, машины не могли говорить с человеком.
На правах рекламы. Успейте воспользоваться в новом году интересным предложением и получить скидку в размере 25% на первый платеж при заказе на 3 или 6 месяцев!
Это не просто виртуальные серверы! Это VPS (KVM) с выделенными накопителями, которые могут быть не хуже выделенных серверов, а в большинстве случаев — лучше! Мы сделали VPS (KVM) c выделенными накопителями в Нидерландах и США (конфигурации от VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD или 4TB HDD / 1Gbps 10TB доступными по уникально низкой цене — от $29 / месяц, доступны варианты с RAID1 и RAID10), не упустите шанс оформить заказ на новый тип виртуального сервера, где все ресурсы принадлежат Вам, как на выделенном, а цена значительно ниже, при гораздо более производительном «железе»!
Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки? Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США!
Источник


