В блоке из предыдущих трёх статей мы построили ПЛИС систему на базе LiteX, рабочие блоки для которой могут быть написаны не на странном языке, базирующимся на Питоне, а на чистом Верилоге. А благодаря LiteX, база для системы была создана для нас автоматически. Такой подход позволяет резко упростить и ускорить процесс разработки систем.

Пока что наши собственные модули были подключены к системе через регистры команд и состояний (CSR). Часто этого более, чем достаточно, но иногда всё-таки разрабатываемые блоки должны содержать в себе сложные наборы регистров, а может даже и память. И без прямого подключения к системной шине не обойтись.
Сегодня мы подключим пару собственных Slave-устройств к системной шине Wishbone, которая будет создана средой LiteX. Устройства, разумеется, будут описаны на Верилоге. Приступаем!
Предыдущие статьи цикла.
Что такое Wishbone
Wishbone – это шина, которая очень популярна у разработчиков с сайта OpenCores.org. То есть существует масса устройств, которые подключаются именно к ней. Поэтому одной из шин, которые могут лежать в основа LiteX-системы, является именно Wishbone. Я написал много статей, где рассказывал о деталях пусть другой, но идеологически сходной шины — AVALON_MM (например, Разработка собственного ядра для встраивания в процессорную систему на базе ПЛИС), поэтому подробно останавливаться на сути работы шин не буду. Но стоит отметить, что Wishbone имеет несколько отличий от классических шин.
Спецификация Wishbone лежит тут: Wishbone B4 (opencores.org)
Из неё видно, что шина является асинхронной. В ней имеется не только строб (STB), но и подтверждение (ACK). Когда мне доводилось исследовать одну хитрую систему на базе RISC-V, этот факт очень помогал. Я запрашивал дамп участка памяти, находясь в BIOS. Если он отображался моментально, значит, этот участок был «живым», пусть из него читались и все FF-ы. Если же выводился с существенной задумчивостью, значит, там нет никаких Slave-устройств, они не присылают ACKов, а мастер просто отваливается после долгого таймаута на чтении каждого из байтов. Благодаря этому свойству я научился сопоставлять исходные коды на Верилоге (они впоследствии оказались сгенерёнными LiteXом) с реальной обстановкой, не написав ни строчки своего тестового кода. А в автоматически сгенерённом коде всё сделано хитро, чего стоят хотя бы десятичные константы разной разрядности, сдвинутые влево на разное число разрядов. Читать его – ужас. Так что задержки доступа при отсутствии ACK мне здорово помогли. Сама система физически при этом находилась в Лондоне, я просто подключался к ней по SSH. В общем, асинхронность всё усложняет, но и польза от неё тоже имеется. Итак, диаграммы, поясняющие суть асинхронного доступа:


Плюс на этой шине есть сигнал CYC, охватывающий весь цикл… В общем, все детали в спецификации. Дело в том, что сегодня мы не будем проектировать собственных устройств. Мы просто возьмём готовые решения из сети, реализованные на Верилоге, и внедрим их в свою систему. Представим себе, что мы нашли полезные модули и хотим их внедрить к себе. Даже при таком подходе, нам будет чем заняться. Так что пока, в пределах статьи, в недра шины не погружаемся. Нам будет достаточно знать перечень необходимых сигналов, ведь именно они будут пробрасываться из LiteX-части в Верилоговскую. Все эти сигналы перечислены в спецификации шины.
К шине могут быть подключены Master и Slave-устройства. По-русски часто их называют ведущими и ведомыми. В далёкие восьмидесятые на шине МПИ их называли активными и пассивными (даже были сигналы СИА и СИП – Синхронизация Активного и Синхронизация Пассивного). Вот скучный пример подключения таких устройств из спецификации шины:
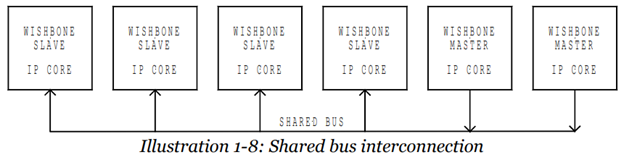
А вот – более живой рисунок, найденный на просторах Интернета. На нём шина Wishbone отмечена длинным изогнутым штрихпунктиром слева:
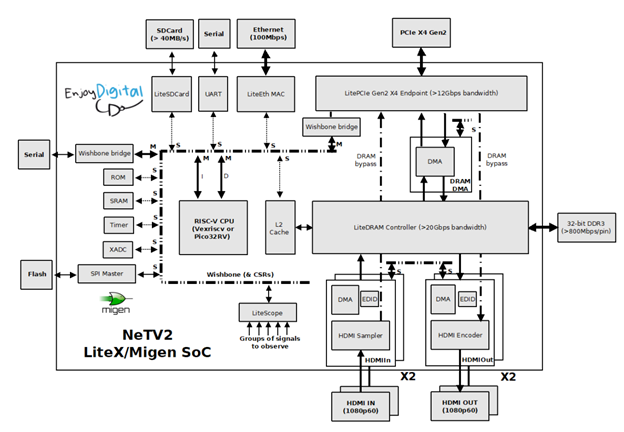
Некоторые подключения к шине отмечены, как M, некоторые – как S. Это активные и пассивные устройства соответственно. Активные могут посылать запросы, а пассивные должны их принимать.
Сегодня мы будем добавлять пассивные (Slave) устройства на шину, а в качестве активного, как и в прошлые разы, будем использовать входящий в состав библиотек LiteX модуль EtherBone, позволяющий слать запросы к шине Wishbone по сети Ethernet.
Регионы шины
Как мы знаем, устройства на шине имеют диапазоны адресов. В идеологии LiteX добавляется очень похожее, но не обязательно совпадающее понятие региона. Регион – это участок адресного пространства, к которому может быть подключено устройство. В чём разница? Ну, если подходить к вопросу совсем формально, то регион в адресном пространстве может иметь больший размер, чем диапазон адресов, требуемый для устройства. Но мы сегодня не научную лекцию читаем, мы сегодня практикуемся. Поэтому сейчас мы будем запрашивать регионы только требуемого размера. Но давайте я покажу суть вышесказанного на рисунке.
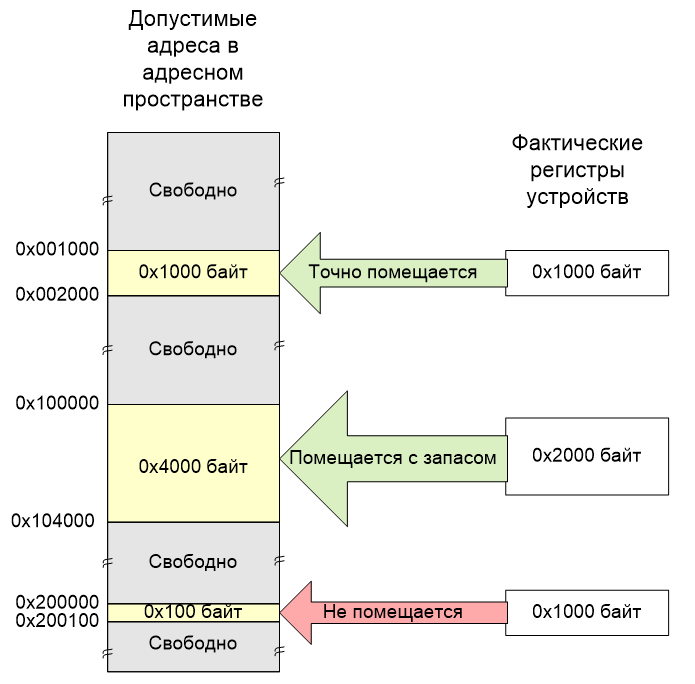
Жёлтым я показал как раз регионы, выделенные в адресном пространстве для тех или иных нужд. Как видим, главное – чтобы блок регистров (ну, или память) устройства по размеру был не больше, чем тот регион, в который его пытаются вставить. При этом с нашими ПЛИС вряд ли мы сможем сделать устройств больше, чем влезет в адресное пространство шины. Так что, если мы ничего не напутаем, всё точно будет хорошо. Главное – не напутать! Но как этого добиться?
Давайте попробуем посмотреть, как регионы адресного пространства распределены в той реальной LiteX-системе, которую мы проектируем на протяжении всего блока статей. Как часто (но не всегда) бывает, мне не удалось найти хорошего описания этого дела, с точки зрения Питоновского кода, но Visual Studio помогла мне проиллюстрировать суть. Ставим точку останова и осматриваем актуальное значение переменных объекта soc.
Вот так выглядят регионы у той системы, которую мы уже успели разработать… Если у нас нет процессорного ядра (а именно такую систему я маниакально делал), список регионов выглядит так:
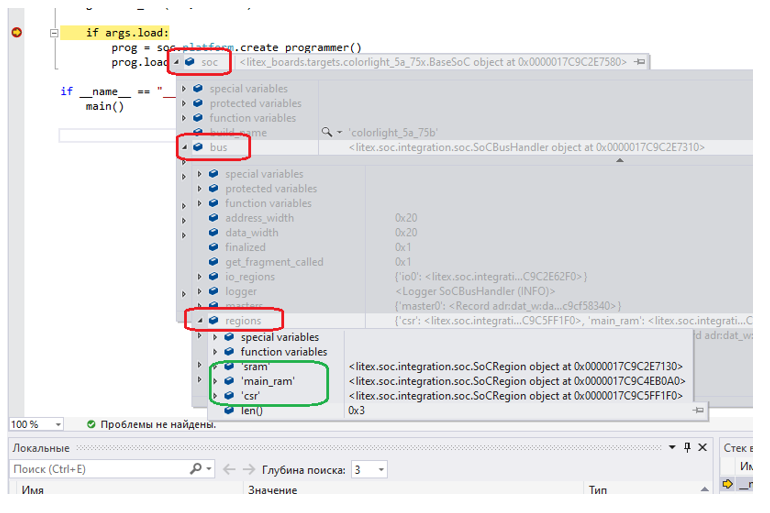
Посмотрим, скажем, регион csr:
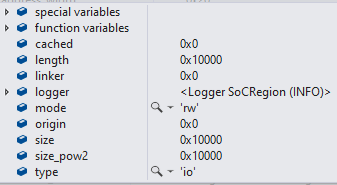
Обратите внимание, что у него тип – io. Это значит, что он не кэшируемый. Ещё давайте обратим внимание, что базовый адрес (origin) у него равен нулю. Этот ноль ещё попьёт нам кровушки, но чуть ниже.
Для сравнения, осмотрим регион sram.

У него базовый адрес 0x1000000 и тип «кэшируемый».
Когда нужен и когда не нужен кэш? У меня была большая отдельная статья – Методы оптимизации кода для Redd. Часть 1: влияние кэша. Там было показано, что когда речь идёт о памяти, без него никуда. Мы уже видели выше, что если шина Wishbone используется в синхронном режиме (а без него упадёт FMax), то любой цикл занимает не менее двух тактов (промотайте назад и рассмотрите времянки, которые я скопировал из документации). То есть при прямых одиночных обращениях к памяти через эту шину, просадок быстродействия не избежать. А кэширование спасёт ситуацию.
Но если мы делаем регистры ввода-вывода, то любое обращение к ним должно проходить от активного устройства к пассивному. И такой регион не должен кэшироваться. Пусть он работает медленно, зато все обращения дойдут до целевого устройства.
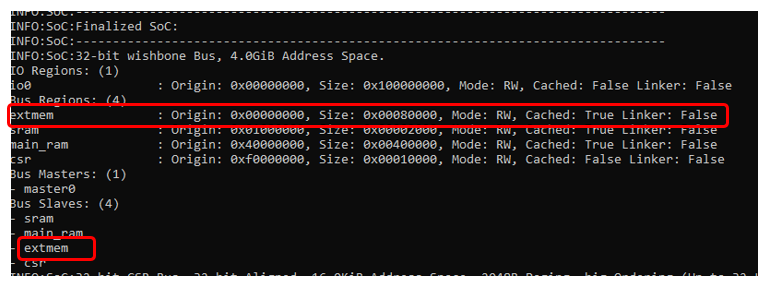
В целом, полную информацию о распределении регионов можно увидеть не только в отладчике, но и в консоли во время работы скрипта:

Все регионы должны быть размещены в адресном пространстве так, чтобы они не пересекались друг с другом. При пересечении будет выдана ошибка. Положение региона определяется базовым адресом и размером. Сейчас по умолчанию у нас имеется регион, обслуживающий уже хорошо знакомые нам регистры CSR, регион sram (статическая память) и регион sdram (динамическая память). Ни один из этих регионов мы не заказывали, но нам его создала автоматика на основе базового класса SoC.
Кстати, а зачем нам этот регион sram? У нас ведь нет процессорного ядра. Немного порыскав по исходникам, я выяснил, что его размер определяется аргументом –integrated-sram-size. Добавляем к свойствам отладки ключ:

Стало лучше: мы убрали расход неиспользуемых ресурсов ПЛИС. Регион sram больше не фигурирует в списке:

Распределяем регионы
Предсказуемо, я не нашёл хорошего руководства по методике распределения регионов, поэтому мне пришлось много тыкаться, чтобы накопить практический опыт. Выяснилось, что есть несколько способов выделения регионов, каждый из которых имеет свои достоинства. Сегодня я покажу только тот, который мне показался самым лаконичным, но отмечу, если кто-то решит полазить по исходным кодам библиотеки вокруг тех функций, которые мы сейчас рассмотрим, он найдёт много интересного на тему альтернативных решений.
Итак. Рассмотрим несколько примеров из штатной поставки LiteX:
self.bus.add_slave(“serwb”, serwb_master_core.bus, SoCRegion(origin=0x30000000, size=8192))

Тут один из аргументов – функция SoCRerion. Она как раз регион и создаёт.
Вот ещё пример:

Здесь создание региона авторы вынесли в отдельную строку. Сути это не меняет. Правда, код разрастается.
И ещё один пример, чтобы накопить вариантов и сделать вывод:

Что мы видим во всех этих строках? Адрес региона назначается вручную. Нет, замечательно, конечно! Но если количество устройств достигнет десятка-другого, может начаться путаница. А когда модули начнут кочевать из проекта в проект – настанет полная анархия. Я ещё помню времена, когда базовые адреса устройств для PC, подключаемых к шине ISA, настраивались перемычками. Ох и бардак же творился! Настроить конфигурацию – это было отдельное искусство. Постоянно что-то хотело с чем-то начать конфликтовать. Когда вышла спецификация PnP… А если точнее, то, когда устройства, удовлетворяющие ей, перестали глючить, в мире наступила гармония! И будет очень неприятно вернуться в те «догармонические» времена! Неужели нельзя поручить такой умной библиотеке, как LiteX, назначать адреса регионов автоматически?
Можно! Но помните я говорил, что нулевой адрес блока csr попьёт нашей кровушки? Пришло время рассказать, как это будет выглядеть, и что мы сможем противопоставить этому.
Никто не запрещает нам запрашивать регионы вот так:
self.bus.add_slave("psram", self.spram.bus, SoCRegion(size=128*kB))Вот ещё вариант:
soc.bus.add_slave(name="extmem",
slave=extmem_bus,region=SoCRegion(size=extmem.size,cached=True))Как видим, мы вполне можем не заполнять поле Origin. Тогда адреса будут назначаться автоматически, но начинаться они будут с нуля. А на этом адресе у нас уже имеется блок CSR. Возникнет конфликт адресов, и нам будет выдано сообщение об ошибке.
Что делать? Двигать блок csr, благо для этого надо вставить всего одну строку. Например:
soc.mem_map["csr"] = 0xf0000000;Кто-то скажет, что я добавляю костыли. Вовсе нет! Это нам повезло, что у платформы colorlight_5a_75x не возникло никаких конфликтов. Когда я попытался собрать пример для другой платы на такой же ПЛИС и взял за основу платформу colorlight_i5, у меня возник тот же самый конфликт пересекающихся регионов! На адрес 0 запрыгнул регион spi_flash, потому что он пользуется похожим же механизмом назначения адресов.
Вы спросите, почему не сбоит у других разработчиков? А вот тут и кроется разгадка того костыля, который вовсе не костыль. Все тестируют систему, в которой имеется ядро vexriscv. Никто не проверял платформу colorlight_i5 без процессора. Это я отключаю его, так как мне он сейчас без надобности, я хочу управлять шиной только через Ethernet. А когда процессор включён, блок CSR автоматически прыгает как раз туда, куда я его загнал костылями. Вот фрагмент файла \litex\soc\cores\cpu\vexriscv\core.py:

Так что никакой это не костыль, а самое настоящее повторение штатных механизмов.
Итак. Сегодня мы будем загонять блок csr наверх, в зону 0xf0000000, а потом назначать регионы, не указывая их базовых адресов, только требуемый размер. Тогда система будет распределять их автоматически! Этот метод самый простой и точно работает. А что будет потом – мы будем решать проблемы по мере их поступления, опираясь на немногочисленные примеры. Да и как назначать конкретные адреса регионам, мы уже знаем, но также знаем и то, что этот механизм несёт в себе источник путаницы. Если что – просто будем назначать не автоматически, а вручную… Но пока можно автоматически, почему бы не поручить всё автоматике?
Возможно, кто-то из специалистов по LiteX в комментариях раскроет тайны более удобной работы с регионами. Потому что наверняка есть какие-то секреты… Может быть, они даже где-то документированы. Но я честно искал и не нашёл. Поэтому выстрадал то, что описал выше.
Уффф. Минимально необходимую теорию я рассказал. Мы знаем, где посмотреть описание шины и знаем, что важная вещь при работе LiteX с шиной – это регион. И мы уже знаем пару способов добавлять регионы в систему. Но, прежде чем переходить к практике, давайте разберёмся, какие устройства мы будем добавлять в систему на этот раз. В прошлых статьях мы нашли в сети пример видеоадаптера с VGA-выходом и практиковались на нём. Над чем будем издеваться в этот раз?
Какие устройства будем добавлять
Первое устройство – внешняя микросхема SRAM
Первое устройство, которое мы будем добавлять, я нашёл тут cores/a2p: An experimental small core based on VexRiscv, written in Scala – a2p – OpenPOWER Foundation Git System
Честно говоря, я понятия не имею, что это за проект. Что там было у Ильфа и Петрова? «Я доволен спектаклем, — сказал Остап, — стулья в целости». Вот и в этом проекте главное – есть пример, как внедрять собственный Verilog-модуль, содержащий пассивное устройство для шины Wishbone.
Здесь авторы, ни много ни мало, делают модуль, стыкующий внешнюю восьмибитную микросхему статической памяти с системной шиной. Нужный нам модуль лежит в файле \a2p\build\openroad\litex\modules\issiram.v
Микросхема статической памяти имеет собственную шину. Отличия той шины состоят в том, что линии данных там двунаправленные, и их всего восемь. У системной Wishbone линий данных по 32 штуки на вход и на выход. Ну, и управляющие линии на микросхеме памяти чуть отличаются от Wishbone. Вот рисунок из документа на эту микросхему, поясняющий суть её шины, я нашёл его в сети:
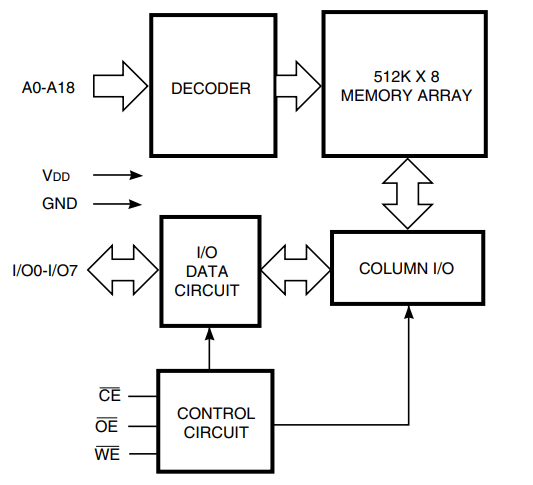
Более глубоко, как именно работает шина SRAM, да и сам Верилоговский модуль, мы разбираться не будем. Нам главное, что в интерфейсной части этого модуля есть как линии шины Wishbone, так и линии, уходящие на ножки ПЛИС, так как они должны подключаться к микросхеме SRAM. Мы на нём натренируемся, а потом будем применять полученный опыт для своих модулей, которые будем разрабатывать сами. Ну, или находить в сети и детально разбираться, как они устроены.
А для этого модуля у нас всё равно нет соответствующей микросхемы. Да и напомню, у выбранной для опытов платы Colorlight 5A-75B все линии ПЛИС вообще-то идут через шинные формирователи на выход. Мы не можем сделать ни входных линий, ни тем более, двунаправленных. Поэтому даже если бы микросхема в наличии и была, всё равно мы бы её к своей макетке не смогли подключить. Но зато какой вкусный интерфейс у Верилоговского модуля из проекта A2P! Самое то, чтобы тренироваться!
module issiram #(
parameter WB_BITWIDTH = 32,
parameter RAM_BITWIDTH = 8
)(
input clk,
input rst,
input wbs_stb_i,
input wbs_cyc_i,
input [29:0] wbs_adr_i,
input wbs_we_i,
input [3:0] wbs_sel_i,
input [31:0] wbs_dat_i,
output wbs_ack_o,
output [31:0] wbs_dat_o,
output mem_ce_n,
output mem_oe_n,
output mem_we_n,
output [18:0] mem_adr,
inout [7:0] mem_dat
);Что с префиксом wbs – это линии шины Wishbone, что с префиксом mem – внешние линии, которые надо подключить к микросхеме памяти. Шина адреса у внешней памяти – девятнадцатиразрядная.
В общем, на этом модуле мы не сможем проверить работоспособность на практике, но зато прекрасно потренируемся пробрасывать линии разных видов, чтобы получить опыт проброса.
Второе устройство – статическая память самой ПЛИС
Однако, как минимум, нам надо проверить, всё ли работает. Для этой цели я нашёл другое устройство. У него есть только шина Wishbone, поэтому оно не так интересно с точки зрения подключения. Но зато в эту шину мы сможем сначала записать данные, а потом – посчитывать их назад, чтобы убедиться в том, что всё работает.
И вообще. Кто же добавляет в систему только одно устройство? Понятно, что устройств должно быть несколько! Так что всё равно полезно будет добавить сразу два устройства, чтобы убедиться, что всё пройдёт гладко!
Итак, вторым подопытным кроликом будет память ПЛИС, доступная через шину Wishbone. Проект, из которого черпаем вдохновение, живёт тут https://github.com/alexforencich/verilog-wishbone
В нём нас интересует файл \rtl\wb_ram.v, но я его немного доработал. Без доработки даже Квартус не понимал, что там используется ОЗУ ПЛИС, чего уж говорить про Yosys. Как именно доработал – не входит в тему статьи, поэтому просто скажу, что можно взять за основу и оригинальный файл, но в примерах к статье, лежит уже доработанный вариант.
Интерфейсная часть данного модуля попроще, чем у предыдущего, тут есть только шина Wishbone:
module wb_ram #
(
parameter DATA_WIDTH = 32, // width of data bus in bits (8, 16, 32, or 64)
parameter ADDR_WIDTH = 9, // width of address bus in bits
parameter SELECT_WIDTH = (DATA_WIDTH/8) // width of word select bus)
(
input wire clk,
input wire [ADDR_WIDTH-1:0] adr_i, // ADR_I() address
input wire [DATA_WIDTH-1:0] dat_i, // DAT_I() data in
output wire [DATA_WIDTH-1:0] dat_o, // DAT_O() data out
input wire we_i, // WE_I write enable input
input wire [SELECT_WIDTH-1:0] sel_i, // SEL_I() select input
input wire stb_i, // STB_I strobe input
output wire ack_o, // ACK_O acknowledge output
input wire cyc_i // CYC_I cycle input
);Тело модифицированного модуля, опять же, выходит за рамки темы статьи, но все желающие могут посмотреть его в примерах, ссылка на которые будет в конце.
Добавляем первое устройство
Описываем ножки микросхемы
Мы уже тренировались объявлять ножки микросхемы ПЛИС, через которые будем подключаться к периферийным устройствам. Ещё раз обращаю ваше внимание, что в Лайтексе при этом можно указывать как физические контакты ПЛИС, так и контакты разъёмов платы. Разъёмы сами по себе ближе схемотехникам. Их проще искать на схемах. Но кроме чисто эстетических удобств, это решает также серьёзную проблему. Какая бы ни была версия платы, нас это совершенно не заботит. А нашу плату можно купить трёх версий, причём один и тот же продавец при заказе одной и той же позиции в разных посылках прислал платы разных версий, а там разводка совершенно разная. Но при описании контактов на уровне разъёмов, мы просто запускаем скрипт, передавая ему ключи, указывающие версию! Остальное – проблемы среды разработки. Она сама сопоставит контакты разъёма с контактами ПЛИС. Мечта! И она сбылась! Только за это я уже люблю LiteX!
Итак, в предыдущих статьях у нас было объявлено что-то такое:
_gpios = [
# Attn. Jx/pin descriptions are 1-based, but zero based defs. used!
# J1
("gpio", 0, Pins("j1:0"), IOStandard("LVCMOS33")), # Input now
("gpio", 1, Pins("j1:1"), IOStandard("LVCMOS33")), # Input now
("gpio", 2, Pins("j1:2"), IOStandard("LVCMOS33")), # Input now
# GND
("gpio", 3, Pins("j1:4"), IOStandard("LVCMOS33")), # Input now
("gpio", 4, Pins("j1:5"), IOStandard("LVCMOS33")), # Input now
…Никто не мешает нам подключить микросхему SRAM к ножкам, объявленным в этом массиве. Но проект A2P, из которого мы черпаем вдохновение, описывает ножки не в виде одноранговых контактов, а в виде шинно-организованных групп. Почему бы нам не потренироваться работать с этим механизмом? Статьи же как раз и нужны, чтобы пробовать разные методы, а уже в бою выбирать самый удобный для себя! В общем, концовка этого списка теперь выглядит так:
("sram_pins",0,
Subsignal ("cen", Pins("j8:14")),
Subsignal ("wen", Pins("j8:13")),
Subsignal ("oen", Pins("j8:12")),
Subsignal ("addr", Pins("j8:11 j8:10 j8:9 j8:8 j8:7 j8:6",
"j8:5 j8:4 j8:2 j8:1 j8:0 j7:6 j5:0",
"j7:4 j7:2 j7:1 j7:0 j6:6 j4:6")),
Subsignal ("data", Pins("j6:4 j6:2 j6:1 j6:0 j5:6 j5:4",
"j5:2 j5:1"))
)
]Там некоторые ножки идут невпопад, но нам же не подключать всё к реальной системе. Просто на ряд разъёмов макетки выведены одни и те же сигналы. Я упустил дублирование некоторых из них, вот потом и устранял. Давайте считать, что так развели нам плату с микросхемой ОЗУ схемотехники.
Добавляем класс
Мы уже умеем добавлять класс, содержащий обычные линии. Класс для шины Wishbone ничуть не сложнее. Я даже не знаю, как прокомментировать его. Всё уже сказано в предыдущих статьях. Вот он:
class ISSIRam(Module):
def __init__(self, clk, rst, wishbone, pins):
self.bus = wishbone
self.data_width = 32
self.size = 524288
self.specials += Instance("issiram",
i_clk = clk,
i_rst = rst,
i_wbs_stb_i = wishbone.stb,
i_wbs_cyc_i = wishbone.cyc,
i_wbs_adr_i = wishbone.adr,
i_wbs_we_i = wishbone.we,
i_wbs_sel_i = wishbone.sel,
i_wbs_dat_i = wishbone.dat_w,
o_wbs_ack_o = wishbone.ack,
o_wbs_dat_o = wishbone.dat_r,
o_mem_ce_n = pins['ce'],
o_mem_oe_n = pins['oe'],
o_mem_we_n = pins['we'],
o_mem_adr = pins['adr'],
io_mem_dat = pins['dat']
)Вносим правки в основной скрипт
Импортируем классы для работы с шиной Wishbone и регионами:
from litex.soc.interconnect import wishbone
from litex.soc.integration.soc import SoCRegionТеперь добавляем код в функцию main. Перво-наперво, не забываем перекинуть регион CSR наверх в адресном пространстве
soc.mem_map["csr"] = 0xf0000000;Мы тактировали блок gpu от входного сигнала 25 МГц. Поэтому здесь заведём тактовый сигнал с системной частотой, снятой с блока PLL. Ну, и сигнал Reset должен на шину уходить:
clk_ram = soc.crg.cd_sys.clk
rst = ResetSignal()Создаём словарь (почему словарь – мы разбирались в предыдущей статье) с контактами для подключения ОЗУ к ПЛИС:
issiram = soc.platform.request('sram_pins')
pins = {
'ce': issiram.cen,
'oe': issiram.oen,
'we': issiram.wen,
'adr': issiram.addr,
'dat': issiram.data
}Создаём экземпляр шины Wishbone:
extmem_bus = wishbone.Interface()Теперь у нас есть всё, чтобы создавать экземпляр класса контроллера внешней статической памяти. У нас есть ножки Reset и Clock, у нас есть ножки ПЛИС для внешнего подключения, у нас есть линии шины Wishbone. А больше для объекта класса «Контроллер SRAM» ничего и не нужно. Создаём его!
extmem = ISSIRam(clk_ram, rst, extmem_bus, pins)Из предыдущих статей мы уже знаем, что объект надо включить в систему:
soc.submodules.extmem = extmemа вот то, чего мы пока никогда не делали – это подключение линий новой шины Wishbone к системной шине. Они же до сих пор висят в воздухе! Подключаем их, попутно создав кэшируемый регион, мы же работаем не с портами, а с памятью, так что кэш нам полезен:
soc.bus.add_slave(name="extmem", slave=extmem_bus,region=SoCRegion(size=extmem.size,cached=True))Ну, и Верилоговский модуль не забудем включить в проект, как мы уже делали раньше:
soc.platform.add_source("issiram.v")Итого, всё вместе выглядит так:
# Это добавляем как можно раньше, после создания SoC
soc.mem_map["csr"] = 0xf0000000;
…
# Это – где угодно
clk_ram = soc.crg.cd_sys.clk
rst = ResetSignal()
issiram = soc.platform.request('sram_pins')
pins = {
'ce': issiram.cen,
'oe': issiram.oen,
'we': issiram.wen,
'adr': issiram.addr,
'dat': issiram.data
}
extmem_bus = wishbone.Interface()
extmem = ISSIRam(clk_ram, rst, extmem_bus, pins)
soc.submodules.extmem = extmem
soc.bus.add_slave(name="extmem", slave=extmem_bus,region=SoCRegion(size=extmem.size,cached=True))
soc.platform.add_source("issiram.v")прогоняем скрипт, видим в терминале:

…
Страшно? Да нисколечко! Прекрасно! Раз всё так просто, приступаем к внедрению второго блока!
Внедряем второй блок
Для второго блока я не буду пояснять каждый шаг. Я просто покажу добавленный класс и добавленный код для скрипта. Итак. Класс:
class WBRam(Module):
def __init__(self, clk, rst, wishbone):
self.bus = wishbone
self.data_width = 32
self.size = 512*4
self.specials += Instance("wb_ram",
i_clk = clk,
i_rst = rst,
i_stb_i = wishbone.stb,
i_cyc_i = wishbone.cyc,
i_adr_i = wishbone.adr,
i_we_i = wishbone.we,
i_sel_i = wishbone.sel,
i_dat_i = wishbone.dat_w,
o_ack_o = wishbone.ack,
o_dat_o = wishbone.dat_r
)Да мы теперь сможем такие классы пачками генерить! Код ничуть не сложнее:
wbram_bus = wishbone.Interface()
wbram = WBRam(clk_ram, rst, wbram_bus)
soc.submodules.wbram = wbram
soc.bus.add_slave(name="wbram", slave=wbram_bus,region=SoCRegion(size=wbram.size,cached=True))
soc.platform.add_source("wb_ram.v")Поздравляю! Мы умеем подключать пассивные устройства к шине Wishbone! Статья, как обычно, затянулась, но давайте всё-таки быстренько всё проверим.
Проверка работоспособности системы
Ох, и посидел я с тестовым скриптом! В этой системе особо не разгуляешься, тут нет аналога Квартусовского логического анализатора Signal Tap, чтобы быстренько подключиться к точкам в системе. Пришлось проверять всё методом проб и ошибок. Оказывается, при чтении памяти через блок EtherBone, надо умножать адрес на 4. Не спрашивайте, зачем. Наверняка какая-то задумка для совместимости восьми и тридцатидвухбитных версий шины Wishbone. Но сначала я пришёл к этому аналитически, потом – нашёл в примерах. Надо и всё тут! Поэтому тестовый скрипт в итоге выглядит так:
#!/usr/bin/env python3
from litex import RemoteClient
wb = RemoteClient()
wb.open()
# # #
# Fill Memory
for i in range(512):
wb.write (wb.mems.wbram.base+i*4,i)
# Check Memory Content
for i in range(512):
if (wb.read (wb.mems.wbram.base+i*4) != i):
print ("Errror at ",i);
print ("Test Finished");
wb.close()Как его запускать – я описывал в позапрошлой статье Первые эксперименты со смешанным Litex+Verilog проектом для ПЛИС. Он проходит! Ну и замечательно! Чтобы убедиться, что это не кэш нам даёт такой замечательный результат, я попробовал собрать систему, в которой соответствующий регион не кэшируется. Скрипт также не выдаёт ошибок.
Заключение
Мы научились добавлять в систему, построенную на базе библиотеки LiteX собственные пассивные устройства, подключаемые через шину Wishbone.
Код, получившийся при разработке статьи, можно найти тут.
Как всегда, если тема до сих пор вызывает интерес, можно перевести дух и рассмотреть, как подключать к шине свои активные устройства.


