Два новых расширения RISC-V ISA позволяют процессору Snitch работать до 6,45 раз быстрее и эффективнее, чем сопоставимые процессоры.
Команда ученых из ETH Zurich представила новую версию процессора RISC-V. Она получила название Snitch. По словам разработчиков, новый ЦПУ обладает впечатляющими показателями скорости и способен обеспечить 6-кратный выигрыш в производительности и почти 4-кратный — в энергоэффективности для многоядерных рабочих нагрузок. Но не спешите с выводами: все не так однозначно, как кажется на первый взгляд. Под катом — разбор основных особенностей нового процессора, реальные «цифры» его производительности и информация о разработчиках.
![[Перевод] Процессор Snitch на базе RISC-V может похвастаться шестикратным приростом производительности](https://habrastorage.org/getpro/habr/upload_files/160/8a1/3b2/1608a13b294a4143849e685ea73f6580.jpg "[Перевод] Процессор Snitch на базе RISC-V может похвастаться шестикратным приростом производительности")
Пополнение рядов RISC-V
Кратко о RISC-V: под этим названием «скрываются» свободные система команд и процессорная архитектура на основе концепции RISC.
Несколько интересных фактов:
-
В описании RISC-V содержится порядка 50 стандартных инструкций (за счет расширений доступны еще 53 инструкции, а форматом C определены 34 дополнительные команды).
-
Первые микроконтроллеры и процессоры на базе RISC-V начали выпускаться в 2017 году.
-
Штаб-квартира RISC-V находится в Цюрихе (основана в 2015 году), а с 2018-го RISC-V Foundation активно сотрудничает с The Linux Foundation.
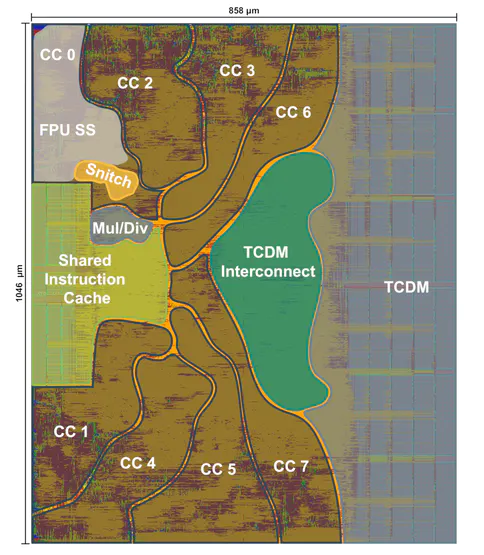
Snitch также построен на RISC-V, в которую добавлено (цитируем разработчиков) «2 крошечных и совсем не навязчивых расширения». К ним относятся компактное управляющее ядро и FPU двойной точности. Первое расширение избавляет процессор от некоторых явных инструкций работы с памятью. Второе позволяет не загружать управляющее ядро при производстве вычислений с плавающей запятой, а поручить ему выполнение ряда других задач.
«Приложения с параллельными вычислениями, к которым, в частности, относятся средства аналитики данных, ПО для машинного обучения и научных вычислений, предъявляют все более высокие требования к количеству операций с плавающей запятой в секунду», — поясняет команда. «А с повышением степени интеграции энергоэффективность становится одной из наиболее приоритетных задач при проектировании процессоров. Хотя специализированные ускорители уже достаточно эффективны, область их применения до сих пор остается слишком узкой. Их банально тяжело адаптировать, если вдруг понадобится изменить оригинальный алгоритм, под который они заточены. Мы, в свою очередь, предлагаем рынку новую архитектурную концепцию, которая одновременно решит проблему достижения чрезвычайной энергоэффективности и при этом сохранит гибкость, не меньшую, чем у прочих вычислительных устройств общего назначения».

Поддержание максимальной утилизации вычислительных ресурсов и увеличение энергоэффективности
Проблема поддержания высокого уровня использования мощностей компьютера и FPU в частности и ранее была предметом множества архитектурных исследований. Наиболее известные и/или широко используемые примеры — суперскалярные архитектуры, векторные архитектуры (например, Cray) и так называемые универсальные вычисления с использованием графических процессоров. Но несмотря на впечатляющие результаты в части достижения высокой производительности, энергоэффективность отнюдь не является основной целью их создателей.
Специалисты из ETH Zurich приняли решение распараллелить ядра, чтобы равномерно распределить работу каждому из них. Синхронизация между ядрами достигается с помощью атомарного расширения RISC-V и поддержки атомарного режима на TCDM и AXI с использованием атомарного расширения AXI5 и атомарного адаптера.
В зависимости от бенчмарка, распараллеливание обеспечивает увеличение производительности от 3 до 6 раз. Измерения проводились на специальном восьмиядерном кластере, полученные результаты сравнивались с одноядерной версией. Наибольшая скорость компьютера на базе многоядерного процессора может быть достигнута для таких задач как умножение матриц, двумерная свертка, kNN и вычисления по методам Монте-Карло.

Snitch и встроенный FPU способны выполнять фактически двойную работу при минимальных «накладных» затратах в 3,2%. При этом он существенно гибче, чем прочие представители современных линеек векторных процессоров, и вдвое более энергоэффективен. Чтобы получить представление об абсолютной энергоэффективности, разработчики оценили достижимую пиковую энергоэффективность на 22-нм техпроцессе. По результатам теста Snitch достигает 79% от теоретической пиковой эффективности.
Итоговое полевое тестирование, для которого был построен ранее упомянутый специальный восьмиядерный кластер Snitch на 22-нм техпроцессе, показало чрезвычайно впечатляющие цифры: процессор оказался в 6,45 раз быстрее и в 3,5 раза эффективнее одноядерного «конкурента».
Разработчики нового процессора и их планы на будущее
В заключение статьи мы хотели бы сказать пару слов о каждом из участников команды разработки проекта Snitch.

Флориан Заруба получил степень бакалавра, а затем магистра в Швейцарском федеральном технологическом институте в 2017 году. В настоящее время он получает степень доктора наук в Лаборатории интегрированных систем. Его исследовательские интересы сосредоточены преимущественно в сфере проектирования высокопроизводительных компьютерных архитектур.

Фабиан Шуйки получил степень бакалавра наук в области электротехники и магистерскую степень в 2014 и 2016 годах соответственно. В настоящее время он продолжает работу над написание докторской диссертации по цифровым схемам и системам под руководством Луки Бенини, который также является соавтором Snitch. Среди его научных интересов — изучение компьютерных архитектур, высокоточные вычисления, а также вопросы обработки данных в памяти.

Торстен Хёфлер, профессор компьютерных наук в ETH Zürich, Швейцария. Также является одним из ключевых членов Форума Message Passing Interface (MPI), где возглавляет направление «Коллективные операции и топологии». Его исследовательские интересы сосредоточены преимущественно вокруг одной центральной темы, проектирования систем, ориентированных на производительность, и включают в себя вопросы, касающиеся масштабируемых сетей, методов параллельного программирования и моделирования производительности. Торстен был удостоен премий за лучшую опубликованную работу на конференциях ACM/IEEE Supercomputing SC10, SC13, SC14, EuroMPI’13, HPDC’15, HPDC’16, IPDPS’15 и прочих подобных мероприятиях. Также Хёфлер подготовил множество активно рецензируемых научных публикаций для ряда крупных отраслевых конференций и журналов.

Лука Бенини возглавляет кафедру цифровых схем и систем в ETH Zürich, по совместительству является профессором Университета Болоньи. Исследования Бенини преимущественно касаются сферы проектирования энергоэффективных вычислительных систем. Перу автора принадлежат более 1000 рецензируемых статей и пять полноформатных книг. Бенини является членом ACM и Academia Europaea, а также лауреат Премии IEEE CAS Mac Van Valkenburg 2016 года.
Что касается планов на будущее — Флориан Заруба в интервью и пресс-релизах говорит преимущественно о том, что разработка ПО для нового процессора будет чуть сложнее, однако программисты непременно оценят универсальность, скорость и эффективность нового CPU. В специальном интервью для IEEE он также обмолвился, что проекты на Snitch можно будет масштабировать до тысяч ядер с распределением задач по нескольким чиплетам.
Исходный код проекта был опубликован в репозитории PULP Platform на GitHub и доступен всем желающим под лицензией Apache 2.0.

