![[Перевод] Объяснение Kafka на примерах из Factorio](https://habrastorage.org/webt/ty/nm/rs/tynmrseb11oobsle0_65pt9esjy.jpeg "[Перевод] Объяснение Kafka на примерах из Factorio")
Если у вас мало свободного времени, не скачивайте Factorio
Для тех, кто в последние годы путешествовал за пределами цивилизации, на всякий случай поясню: Factorio — это стратегия реального времени с открытым миром, где вы строите и оптимизируете цепочки поставок, чтобы запустить спутник и восстановить связь с родной планетой, а Kafka — это распределённая платформа потоковой передачи событий, которая обрабатывает асинхронные коммуникации надёжным способом.
Если человек вообще никогда не работал с потоковой платформой, то ему станет всё понятно на примерах из игры. Что ж, давайте начнём с нуля, изучим основные концепции Kafka — и немного повеселимся.
Зачем нужен асинхронный обмен сообщениями?
Допустим, у нас три микросервиса. Один для добычи железной руды, второй для переплавки руды в листовой металлопрокат, а третий — для производства шестерён из этого проката. Мы можем связать все сервисы в цепочку с помощью синхронных HTTP-вызовов. Как только бур добывает новую руду, он отправляет вызов POST на плавильную печь, которая, в свою очередь, отправляет POST на фабрику.

Слева направо: добыча, плавка и производство, которые тесно связаны друг с другом посредством синхронной связи
Всё было отлично, пока на фабрике не отключили электричество. Тогда HTTP-вызовы от печи не сработали, что в свою очередь привело к сбою вызовов от бура. Конечно, чтобы избежать каскадных сбоев и потери сообщений, можно реализовать прерыватели цепи (‘circuit breaker’ на рисунке) и повторные попытки…
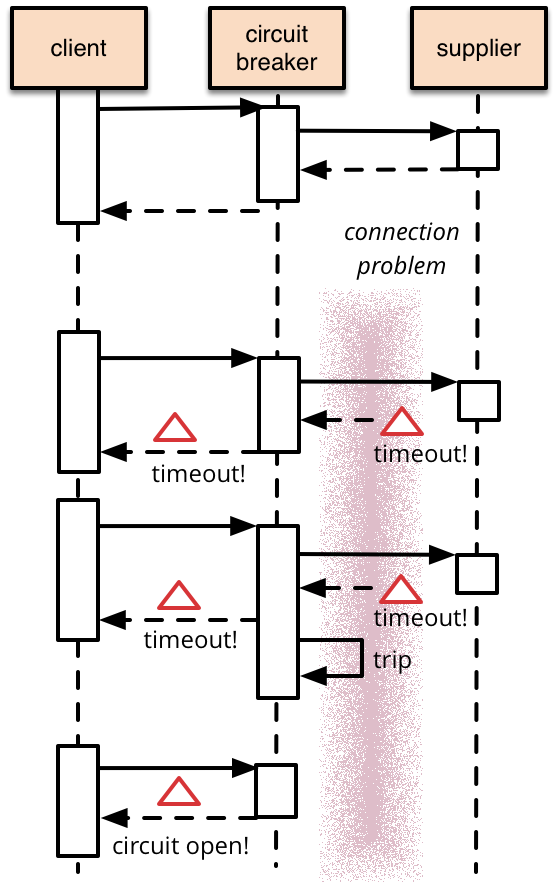
… но в какой-то момент придётся прекратить попытки, иначе у нас закончится память.

Отключение электроэнергии на заводе
Если бы только разделить эти микросервисы… И здесь на помощь приходит Kafka. С её помощью можно надёжно хранить потоки записей с гарантированной защитой от сбоев. В терминологии Kafka эти потоки называются «темы» (топики).

Разделение микросервисов с помощью асинхронной связи
При использовании асинхронных тем во время пиковых нагрузок и при перебоях все записи буферизируются. Очевидно, у буферов ограниченная ёмкость. Поэтому поговорим о масштабируемости.
Мы можем увеличить ёмкость хранилища и пропускную способность, добавив серверы в кластер. Другой способ — нарастить диски, CPU и ширину канала. Какой из этих вариантов даст наилучшее соотношение цены и качества — зависит от конкретного случая использования. Но увеличение размера серверов — в отличие от увеличения их количества — подчиняется закону убывающей отдачи. Пропускная способность Kafka линейно растёт с каждым добавленным узлом, так что обычно это оптимальный вариант.

Вертикальное масштабирование — серверы большего размера с экспоненциальным ростом стоимости

Горизонтальное масштабирование — распределение нагрузки на большее количество серверов
Чтобы разделить тему на несколько серверов, нужно разбить её на более мелкие подпотоки. Эти подпотоки в Kafka называются разделами. Когда служба производит новую запись, она выбирает раздел, куда её поместить.
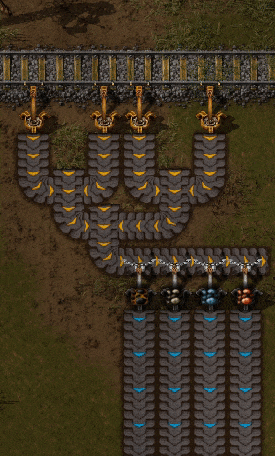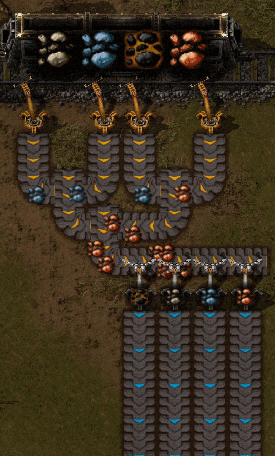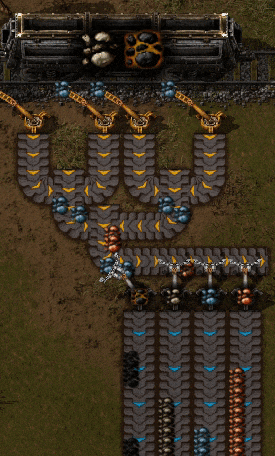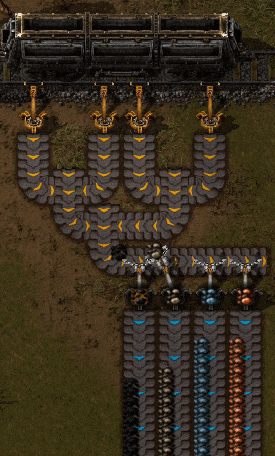
Вагон производит записи. Разделитель (partitioner) переносит сообщения в нужный раздел. И тема с четырьмя разделами
Дефолтный разделитель хэширует ключ сообщения и модулирует его на количество разделов:
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;Так сообщения с одинаковым ключом всегда оказываются в одном разделе.
Обратите внимание, что сообщения гарантированно упорядочены только в контексте производителя и раздела. Записи от нескольких производителей или от одного производителя в нескольких разделах могут чередоваться.
Теперь, когда мы знаем, как сообщения помещаются в темы, давайте посмотрим, как они потребляются. Когда вы начинаете прослушивать тему, по умолчанию вам направляются записи со всех разделов. Однако часто бывает так, что несколько инстансов микросервиса работают одновременно для достижения более высокой пропускной способности или доступности. Если все они начнут прослушивать тему, то каждая запись будет обрабатываться каждым инстансом, а это обычно не оптимальный вариант.

Все инстансы микросервиса потребляют все сообщения
Равномерно разделить разделы между несколькими потребителями помогают группы потребителей. Когда инстанс микросервиса присоединяется к группе потребителей, Kafka переназначает ему часть разделов. Аналогично, когда инстанс выходит из строя или по какой-то другой причине покидает группу, его разделы назначаются другим инстансам. Kafka следит, чтобы разделы всегда равномерно распределялись между потребителями в каждой группе.

Одна группа потребителей с тремя членами
Если в разделах разное количество записей, могут возникнуть проблемы. Один инстанс может не успевать, потому что ему назначен раздел с большим количеством записей, в то время как другие инстансы простаивают. Следует убедиться, что во всех разделах примерно одинаково записей.

В слишком загруженном разделе накапливается очередь сообщений
Каждый потребитель отслеживает, какие записи он обработал. Поскольку записи обрабатываются по порядку, достаточно простого смещения (offset). Время от времени (по умолчанию каждые 5 секунд) потребитель фиксирует своё смещение в Kafka (коммит).
Когда потребитель покидает свою группу, его разделы передаются другим потребителям. Они начнут запрашивать записи с того смещения, на котором остановился предыдущий потребитель.
Возможно, запись была обработана, но ещё не зафиксирована. В таком случае придётся либо начать с зафиксированного смещения, либо начать обработку новых сообщений и пропустить всё, что ещё не обработано. Вот почему Kafka может гарантировать доставку сообщений только минимум один раз или максимум один раз, но не ровно один раз.
Аналогия перестаёт работать при дублировании данных. В Kafka мы можем обработать одну запись несколько раз. Несколько групп потребителей могут потреблять одни и те же записи. Для надёжности темы можно хранить с коэффициентом репликации три. У тем может быть период хранения, по истечении которого записи удаляются. Всё это возможно, потому что записи легко дублировать, в отличие от физических объектов в Factorio.
На этом можно закончить. Благодаря любимой игре мы рассмотрели практически все основные концепции Kafka и получили общее представление, как она работает. Подведём краткий итог.
Что мы узнали
Kafka — это распределённая платформа потоковой передачи событий, которая хранит записи долговременным образом путём репликации на нескольких серверах. Темы состоят из разделов, которые хранят записи по порядку. Разделители решают, какие записи относятся к каким разделам. Группы потребителей необязательны и помогают распределить разделы между потребителями для масштабируемости. Смещения фиксируются как контрольные точки на случай сбоя потребителей.
Вот вкратце и всё, как работает Kafka.


