![[Перевод] NVIDIA. Раскрывая тайны архитектуры GPU Turing следующего поколения: удвоенный Ray Tracing, GDDR6 и многое другое](https://habrastorage.org/webt/7c/7l/qd/7c7lqd7hpvnms_v0fcexsts94-m.jpeg "[Перевод] NVIDIA. Раскрывая тайны архитектуры GPU Turing следующего поколения: удвоенный Ray Tracing, GDDR6 и многое другое")
Гибридный рендеринг и нейронные сети: RT & Tensor Cores
Так что же такого особенного и нового в архитектуре Тьюринг? Функция marquee, по крайней мере для комьюнити ProViz от NVIDIA, предназначена для гибридного рендеринга, который сочетает в себе трассировку лучей с традиционной растеризацией.

Главное изменение: NVIDIA включила в Turing еще больше оборудования для трассировки лучей, чтобы предложить наиболее быстрое хардварное ускорение трассировки лучей. Новым для архитектуры Тьюринга является специализированный вычислительный блок RT Core, как его называет NVIDIA, в настоящее время о нем недостаточно много информации, известно лишь что его функция — поддержка трассировки лучей. Эти процессорные блоки ускоряют как проверку пересечения лучей и треугольников, так и манипуляции с BVH (иерархии ограничивающих объемов).
NVIDIA заявляет, что самые быстрые компоненты Тьюринг могут обсчитывать 10 миллиардов (Гига) лучей в секунду, что по сравнению с неускоренным Pascal является 25-кратным улучшением характеристик трассировки лучей.
Архитектура Тьюринг включает тензорные ядра Volta, которые были усилены. Тензорные ядра являются важным аспектом нескольких инициатив NVIDIA. Наряду с ускорением трассировки лучей, важным инструментом в «магической сумке с фокусами» NVIDIA является уменьшение количества лучей, требуемых в сцене с помощью шумоподавления AI, чтобы очистить изображение, здесь тензорные ядра справляются лучше всех. Конечно, это не единственная область, где они хороши – все нейронные сети и AI империи NVIDIA построены на них.
Turing характерна поддержка более широкого диапазона точности, а значит, возможность значительного ускорения в рабочих нагрузках, которые не имеют высоких требований к точности. Помимо precision mode Volta FP16, тензорные ядра Turing поддерживают INT8 и даже INT4. Это в 2 и 4 раза быстрее, чем FP16, соответственно. Хотя на презентации NVIDIA не пожелала углубляться в детали, я бы предположил, что они реализовали что-то похожее на упаковку данных, которую используют для низкоточных операций на ядрах CUDA. Несмотря на сниженную точность нейронной сети (уменьшена отдача — по INT4 мы получаем всего 16 (!) значений) — есть определенные модели, которым действительно достаточен этот низкий уровень точности. Как результат, режимы сниженной точности покажут хорошую пропускную способность, особенно в задачах вывода, что несомненно порадует некоторых пользователей.
Возвращаясь к гибридному рендерингу в целом, интересно, что несмотря на эти большие индивидуальные ускорения, общие обещания NVIDIA по приросту производительности выглядят несколько скромнее. Хотя компания и обещает повысить производительность в 6 раз по сравнению с Pascal, не пора ли поинтересоваться, какие именно части ускорены, и в сравнении с какими. Время покажет.
Между тем, чтобы лучше использовать тензорные ядра вне задач трассировки лучей и узконаправленных задач глубокого обучения, NVIDIA будет развертывать SDK, NVIDIA NGX, что позволит интегрировать нейронные сети в обработку изображений. NVIDIA предполагает использование нейронных сетей и тензорных ядер для дополнительной обработки изображений и видео, включая такие методы, как предстоящее Deep-Anti-Aliasing (DLAA).
Turing SM: выделенные ядра INT, единый кэш, Variable Rate Shading
Наряду с RT и тензорными ядрами, архитектура Turing Streaming Multiprocessor (SM) и сама преподносит новые трюки. В частности, унаследовано одно из последних изменений Volta, в результате которого ядра Integer выделяются в свои собственные блоки, а не являются частью ядер CUDA с плавающей точкой. Преимущество — ускоренная генерация адресов и производительность Fused Multiply Add (FMA).
Что касается ALU (я все еще жду подтверждения для Turing) — поддержка более быстрых операций с низкой точностью (например, быстрый FP16). В Volta это реализовано как операции FP16 на удвоенной частоте относительно FP32, и INT8 операции на скорости 4x. Тензорные ядра уже поддерживают эту концепцию, поэтому было бы логично перенести ее на ядра CUDA.
Быстрая FP16, технология Rapid Packed Math и другие способы упаковки нескольких небольших операций в одну крупную операцию — все это ключевые компоненты улучшения производительности графического процессора в то время, когда закон Мура замедляется.
Используя большие (точные) типы данных только по мере необходимости, их можно упаковать вместе, чтобы выполнить больше работы за тот же период времени. Это, в первую очередь, важно для вывода нейронных сетей, а также для разработки игр. Дело в том, что не все шейдерные программы нуждаются в точности FP32, а сокращение точности может повысить производительность и сократить полезную пропускную способность памяти и использование файла реестра.
Turing SM включает в себя нечто, что NVIDIA называет «unified cache architecture». Поскольку я все еще ожидаю официальных SM-диаграмм от NVIDIA, неясно, является ли это той же унификацией, которую мы видели у Volta — где кеш L1 был объединен с общей памятью — или NVIDIA сделала еще один шаг вперед. Во всяком случае, NVIDIA заявляет, что теперь предложена вдвое большая пропускная способность относительно «предыдущего поколения», но при этом неясно, имеется ввиду «Паскаль» или «Вольта» (последнее более вероятно).
Наконец, глубоко спрятанное в пресс-релизе Turing, обнаружено упоминание поддержки variable rate shading. Это относительно молодая и развивающаяся технология графического рендеринга, о которой мало информации (особенно о том, как именно она реализована у NVIDIA). Но на очень высоком уровне абстракции это звучит как «технология нового поколения NVIDIA, позволяющая применять затенение с различным разрешением, что дает возможность разработчикам отображать различные области экрана при различных эффективных разрешениях для концентрации качества (и времени рендеринга) в областях, где это наиболее необходимо».
«Накормить зверя»: поддержка GDDR6
Поскольку память, используемая графическими процессорами, разрабатывается сторонними компаниями, здесь нет секретов. JEDEC и его крупные 3 участника Samsung, SK Hynix и Micron развивают память GDDR6 в качестве преемника GDDR5 и GDDR5X. NVIDIA подтвердила тот факт, что Turing будет ее поддерживать. В зависимости от производителя, GDDR6 первого поколения рекламируется как обладатель пропускной способности памяти до 16 Гбит/с на шину, что вдвое больше, чем у карт последнего поколения NVIDIA GDDR5, и на 40% быстрее, чем у последних карт GDDR5X от NVIDIA.
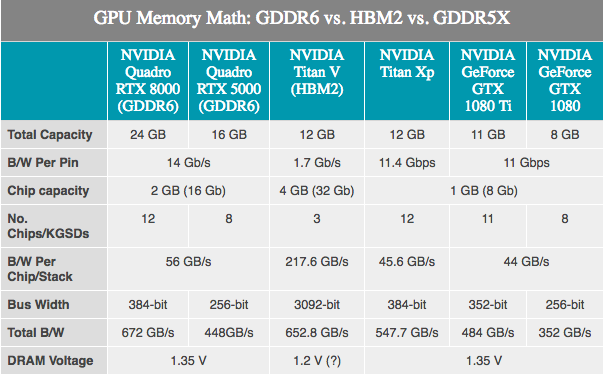
По сравнению с GDDR5X, GDDR6 не выглядит каким-то крупным прорывом, так как многие нововведения GDDR6 уже были применены в GDDR5X. Принципиальные изменения здесь включают более низкие рабочие напряжения (1.35v), а внутренне память теперь разделена: два канала памяти на микросхему. Для стандартного 32-битного чипа — два 16-битных канала памяти, в общей сложности имеем 16 таких каналов на 256-битной карте. Хотя это, в свою очередь, говорит, что существует очень большое количество каналов, графические процессоры получат от нововведения максимальную выгоду, ведь исторически они являются максимально «параллельными» устройствами.

NVIDIA со своей стороны подтвердила, что первые карты Turing Quadro будут использовать GDDR6 со скоростью 14 Гбит/с. При этом NVIDIA также подтвердила использование памяти Samsung, особенно для своих передовых 16-гигабайтных устройств. Это важно, так как означает, что типичный 256-битный графический процессор NVIDIA может быть оснащен 8 стандартными модулями и получить 16 ГБ общей емкости памяти, или даже 32 ГБ, если они используют clamshell mode (позволяет адресовать 32 Гбайт памяти на стандартной 256-битной шине).
Всякие подробности: NVLink, VirtualLink и 8K HEVC
Уже заканчивая обзор архитектуры Turing, NVIDIA мимоходом подтвердила поддержку некоторых новых функций внешнего ввода-вывода. Поддержка NVLink будет присутствовать, как минимум, в нескольких продуктах Turing. Напомним, что NVIDIA использует ее во всех трех новых картах Quadro. NVIDIA предлагает двухстороннюю конфигурацию графического процессора.
Важный момент (прежде чем часть нашей аудитории, ориентированной на игры, углубится в чтение): наличие NVLink в оборудовании Turing еще не означает, что оно будет использоваться в потребительских видеокартах. Возможно все ограничится только картами Quadro и Tesla.
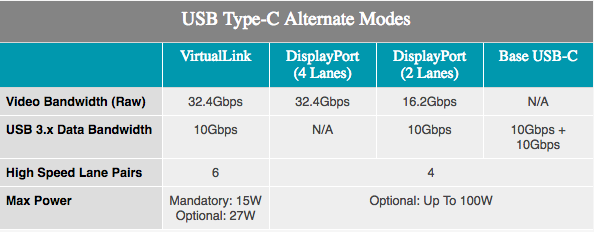
С добавлением поддержки VirtualLink у игроков и пользователей ProViz будет что ожидать от VR. Альтернативный режим USB Type-C был анонсирован в прошлом месяце и поддерживает 15 Вт + мощности, передачу 10 Гбит/с данных благодаря USB 3.1 Gen 2, 4 полосы DisplayPort HBR3 на одном кабеле. Другими словами, это соединение DisplayPort 1.4 с дополнительными данными и мощностью. Это позволяет видеокарте напрямую управлять головной гарнитурой VR. Стандарт поддерживается NVIDIA, AMD, Oculus, Valve и Microsoft, поэтому продукты Turing станут первыми из ряда продуктов, которые будут поддерживать новый стандарт.
Хотя NVIDIA только едва коснулась темы, мы знаем, что блок видеокодера NVENC был обновлен в Turing. Последняя итерация NVENC добавляет специальную поддержку кодирования HEKC 8K. Тем временем NVIDIA смогла улучшить качество своего кодировщика, позволяя достичь такого же качества, как и раньше, с меньшим на 25% битрейтом видео.
Показатели производительности
Наряду с объявленными спецификациями оборудования, NVIDIA показывает несколько цифр производительности оборудования Turing. Следует отметить, что здесь мы знаем очень и очень мало. Компоненты, по-видимому, основаны на полностью и частично включенных Turing SKU с 4608 ядрами CUDA и 576 тензорными ядрами. Частоты не раскрываются, однако, поскольку эти цифры профилированы для аппаратного обеспечения Quadro, мы, вероятно, увидим более низкие тактовые частоты, чем на любом потребительском оборудовании.

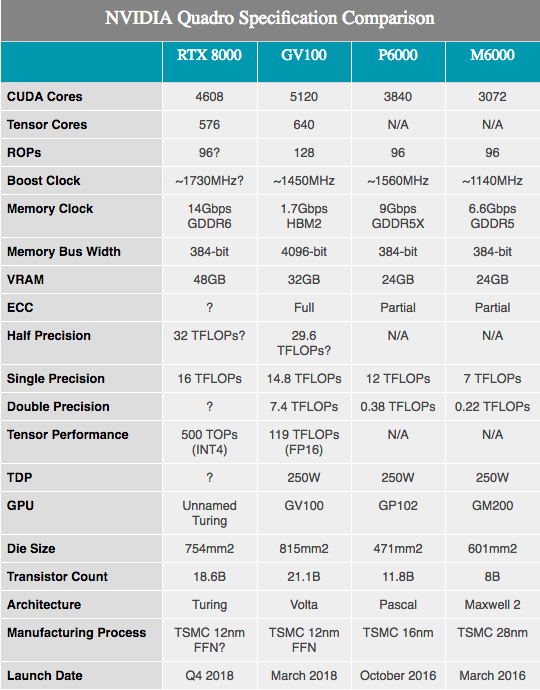
Наряду с вышеупомянутым показателем 10GigaRays/sec для ядер RT, производительность тензорных ядер NVIDIA составляет 500 триллионов тензорных операций в секунду (500T TOPs). Для справки, NVIDIA часто упоминает GPU GV100 как способную выдать максимум 120T TOP, но это не одно и то же. В частности, в то время как GV100 упоминается при обработке операций FP16, производительность Turing цитируется с чрезвычайно низкой точностью INT4, которая как раз составляет четверть размера FP16 и, следовательно, увеличивает пропускную способность в четыре раза. Если мы будем нормализовать точность, то тензорные ядра Тьюринга, по-видимому, не имеют лучшей пропускной способности на ядро, а скорее предлагают больше вариантов точности, чем Volta. Во всяком случае, 576 тензорных ядер в этом чипе ставят его почти вровень с GV100, который имеет 640 таких ядер.
Что касается ядер CUDA, NVIDIA заявляет, что графический процессор Turing может предложить 16 TFLOPS производительности. Это немного опережает 15 TFLOPS производительности с единой точностью Tesla V100, или еще больше опережает 13,8 TFLOPS от Titan V. Если вы ищете более понятную потребителю информацию, это примерно на 32% больше чем у Titan Xp. Набросав несколько приблизительных расчетов на бумаге, можно предположить тактовую частоту GPU примерно в 1730 МГц, с учетом, что на уровне SM не было никаких дополнительных изменений, которые бы поменять традиционные формулы производительности ALU.
Между тем NVIDIA заявила, что карты Quadro будут поставляться с памятью GDDR6, работающей со скоростью 14 Гбит / с. И глядя на две лучших Quadro SKU, предлагающие 48 ГБ и 24 ГБ GDDR6 соответственно, мы почти видим 384-битную шину памяти у этого графического процессора Turing. Переходя к цифрам, это составляет до 672 ГБ/с пропускной способности памяти для двух топовых карт Quadro.
В противном случае, с изменением архитектуры сложно сделать много полезных сравнений производительности, особенно сравнивая с Pascal. Из того, что мы видели у Volta, общая эффективность NVIDIA повысилась, особенно в хорошо продуманных вычислительных нагрузках. Таким образом, примерно 33% улучшение производительности на бумаге, в сравнении с Quadro P6000, вполне может оказаться чем-то намного большим.
Я упомяну размер кристалла нового графического процессора. Расположившись на 754 мм2, он не просто большой, он огромный. По сравнению с другими графическими процессорами уступает по величине только NVIDIA GV100, который в настоящее время остается флагманом NVIDIA. Но учитывая 18,6 млрд транзисторов, легко понять, почему результирующий чип должен быть таким большим. Видимо у NVIDIA есть большие планы на этот GPU, что в итоге сможет оправдать наличие двух огромных графических процессоров в своем стеке продуктов.
NVIDIA, со своей стороны, не указала конкретный номер модели этого GPU – является ли он традиционным графическим процессор класса 102 или даже 100-го класса. Интересно, увидим ли мы модификацию этого типа GPU для потребительского продукта в той или иной форме; он настолько велик, что NVIDIA может пожелать сохранить его для своих более прибыльных графических процессоров Quadro и Tesla.
Выйдет в четвертом квартале 2018 года, если не раньше
Напоследок скажу, что наряду с анонсом архитектуры Turing, NVIDIA объявила, что первые 4 карты Quadro на базе графических процессоров Turing — Quadro RTX 8000, RTX 6000 и RTX 5000 начнут поставляться в четвертом квартале этого года. Поскольку сама природа этого анонса несколько инвертирована — обычно NVIDIA сначала объявляет потребительские компоненты — я бы не стал применять ту же временную шкалу к потребительским картам, которые не имеют столь жестких требований к валидации. Мы увидим оборудование Turing в четвертом квартале этого года, если не раньше. Желающие купить Quadro могут начинать экономить деньги уже сейчас: лучшая из новых карт Quadro RTX 8000 обойдется вам примерно в 10 000 долларов.
Наконец, что касается потребителей с Tesla от NVIDIA, запуск Turing оставляет Volta в подвешенном состоянии. NVIDIA не рассказала нам, будет ли Turing в конечном итоге расширяться в high-end пространство Tesla — заменив GV100 — или их лучший процессор Volta останется хозяином своего домена на века. Однако, поскольку другие карты Tesla были до сих пор основаны на Pascal, они первые кандидаты на вытеснение Тьюрингом в 2019 году.
Спасибо, что остаетесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до декабря бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Источник


