![[Перевод] Легендарный Intel Core i7-2600K: тестирование Sandy Bridge в 2019 году (часть 1)](https://habrastorage.org/webt/en/sm/au/ensmaubp6bpmweoot2x1pamo4f0.png "[Перевод] Легендарный Intel Core i7-2600K: тестирование Sandy Bridge в 2019 году (часть 1)")
Одним из самых популярных процессоров уходящего десятилетия стал Intel Core i7-2600K. Дизайн был революционным, так как он предлагал значительный скачок в производительности и эффективности одноядерного процессора, а сам процессор еще и хорошо поддавался разгону. Следующие несколько поколений процессоров Intel выглядели уже не такими интересными, и часто не давали пользователям повода для апгрейда, поэтому фраза «Я останусь с моим 2600К» стала повсеместной на форумах и звучит даже сегодня. В этом обзоре мы стряхнули пыль с коробки со старыми процессорами и прогнали ветерана через набор бенчмарков 2019 года, как на заводских параметрах, так и в разгоне, чтобы убедиться, что он по-прежнему является чемпионом.
«Семейное фото» Core i7
Почему 2600K стал определяющим для поколения
Сядьте в кресло, откиньтесь на спинку кресла и представьте себя в 2010 году. Это был год, когда вы посмотрели на свою устаревшую систему Core 2 Duo или Athlon II, и поняли, что пришло время для апгрейда. Вы уже знакомы с архитектурой Nehalem, и знаете, что Core i7-920 неплохо разгоняется и уделывает конкурентов. Это было хорошее время, но внезапно Intel изменила равновесие в отрасли, и создала по-настоящему революционный продукт. Отзвуки ностальгии по которому слышны до сих пор.

Core i7-2600K: самый быстрый Sandy Bridge (до 2700K)
Этим новым продуктом был Sandy Bridge. AnandTech выпустил эксклюзивный обзор, и в результаты было почти невозможно поверить, по многим причинам. Согласно нашим тестам того времени, процессор был просто несравнимо выше всего, что мы видели раньше, особенно учитывая тепловые монстры Pentium 4, вышедшие за несколько лет до этого. Модернизация ядра, основанная на 32-нм технологическом процессе Intel, стала самым масштабным поворотным моментом в производительности x86, и с тех пор мы не наблюдали подобных прорывов. AMD понадобиться еще 8 лет на то, чтобы получить свой момент славы с серией Ryzen. Intel же удалось воспользоваться успехом своего лучшего продукта, и получить место чемпиона.
В этом базовом дизайне Intel не скупилась на инновации. Одним из ключевых элементов был кэш микроопераций. Это означало, что недавно декодированные инструкции, которые потребовались снова, берутся уже декодированными, вместо того, чтобы тратить энергию на повторное декодирование. У Intel с Sandy Bridge, и намного позже у AMD с Ryzen включение микрооперационного кеша стало чудом для однопоточной производительности. Корпорация Intel также начала улучшать одновременную многопоточность (которая в течение нескольких поколений назвалась HyperThreading), постепенно работая над динамическим распределением вычислительных потоков.
Четырехъядерный дизайн самого лучшего процессора на момент запуска, Core i7-2600K, стал основой продуктов в следующих пяти поколениях архитектуры Intel, включая Ivy Bridge, Haswell, Broadwell, Skylake и Kaby Lake. Со времен Sandy Bridge, хотя Intel и перешла на меньший технологический процесс, и воспользовалась преимуществами более низкого энергопотребления, корпорация не смогла воссоздать этот исключительный скачок в чистой пропускной способности команд. Позднее прирост за год составлял 1-7%, в основном за счет увеличения операционных буферов, портов выполнения и поддержки команд.
Поскольку Intel не смогла повторить прорыв Sandy Bridge, а микроархитектура ядер была ключевым моментом производительности x86, пользователи, которые приобрели Core i7-2600K (я купил два), оставались на нем долгое время. Во многом по причине ожидания еще одного большого скачка производительности. И с годами их разочарование нарастает: зачем инвестировать в четырехъядерный Kaby Lake Core i7-7700K с тактовой частотой 4,7 ГГц, когда твой четырехъядерный Sandy Bridge Core i7-2600K все еще разогнан до 5,0 ГГц?
(Ответы Intel обычно касаются энергопотребления и новых функций, таких как работа GPU и накопителей через PCIe 3.0. Но некоторых пользователей эти объяснения не удовлетворили.)
Вот почему Core i7-2600K определил поколение. Он оставался в силе, вначале к радости Intel, а затем к разочарованию, когда пользователи не желали обновляться. Сейчас, в 2019 году, мы понимаем, что Intel уже вышла за пределы четырех ядер в своих основных процессорах, и, если пользователю по зубам стоимость DDR4, он может либо перейти на новую систему Intel, либо выбрать путь AMD. Но вот вопрос, как Core i7-2600K справляется с рабочими нагрузками и играми 2019 года; или, точнее, как справляется разогнанный Core i7-2600K?
Найдите отличия: Sandy Bridge, Kaby Lake, Coffee Lake
По правде говоря, Core i7-2600K не был самым быстрым мейнстрим процессором Sandy Bridge. Спустя несколько месяцев Intel вывела на рынок немного более «высокочастотный» 2700K. Он работал почти так же, и разгонялся аналогично 2600K, но стоил немного дороже. К этому времени пользователи, которые увидели скачок производительности и сделали апгрейд, были уже на 2600K, и остались с ним.
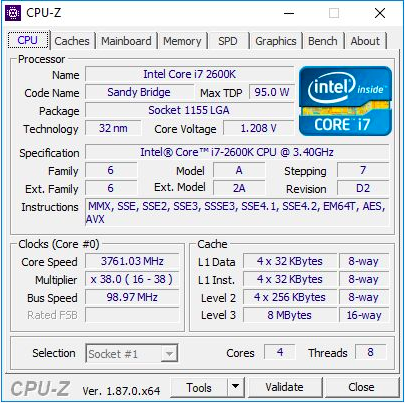
Core i7-2600K представлял собой 32-нм четырехъядерный процессор с технологией HyperThreading, с базовой частотой 3,4 ГГц, частотой турбо 3,8 ГГц, и с номинальным TDP 95 Вт. Тогда TDP от Intel еще не был оторван от реальности: в нашем тестировании для этой статьи мы увидели пиковое энергопотребление 88 Вт на не разогнанном CPU. Процессор поставлялся с интегрированной графикой Intel HD 3000 и поддерживал память DDR3-1333 по умолчанию. Intel установила цену 317 долларов при запуске чипа.
Для этой статьи я использовал второй i7-2600K, который я купил, когда они только появились. Он был протестирован как на штатной частоте, так и разогнанным до 4,7 ГГц на всех ядрах. Это средний разгон – лучшие из этих чипов работают на частоте 5,0 ГГц — 5,1 ГГц в повседневном режиме. На самом деле, я хорошо помню, как мой первый Core i7-2600K работал на 5,1 ГГц на всех ядрах, и даже 5,3 ГГц (также на всех ядрах), когда во время соревнований по оверклокингу в середине зимы, при комнатной температуре около 2C, я использовал мощный жидкостный кулер и радиаторы 720мм. К сожалению, со временем я повредил этот чип, и теперь он не загружается даже при штатной частоте и напряжении. Таким образом, мы должны использовать мой второй чип, который был не так хорош, но все же способен дать представление о работе разогнанного процессора. При оверклокинге мы также использовали разогнанную память, DDR3-2400 C11.
Стоит отметить, что со времен запуска Core i7-2600K мы перешли с Windows 7 на Windows 10. Core i7-2600K не поддерживает инструкции AVX2, и не был создан для Windows 10, поэтому будет особенно интересно посмотреть, как это отобразится на результатах.


Core i7-7700K: последний четырехъядерный процессор Intel Core i7 с технологией HyperThreading
Самым быстрым и новым (и последним?) четырехъядерным процессором с HyperThreading, выпущенным Intel, был Core i7-7700K, представитель семейства Kaby Lake. Этот процессор построен на улучшенном 14-нм техпроцессе Intel, работает на базовой частоте 4,2 ГГц и турбо частоте 4,5 ГГц. Его TDP с номинальной мощностью 91 Вт в нашем тестировании показал энергопотребление 95 Вт. Он поставляется с графикой Intel Gen9 HD 630 и поддерживает стандартную память DDR4-2400. Intel выпустила чип с заявленной ценой 339 долларов.
Одновременно с 7700K, Intel также выпустила свой первый разгоняемый двухъядерный процессор с гипертредингом — Core i3-7350K. В ходе этого обзора мы разогнали такой Core i3 и сравнили его с Core i7-2600K на заводских параметрах, пытаясь ответить на вопрос, удалось ли Intel добиться производительности двухъядерного процессора, подобной их старому четырехядерному флагману. В итоге, то время как i3 одержал верх в однопоточной производительности и работе с памятью, нехватка пары ядер счете сделала большинство задач слишком тяжелой работой для Core i3.


Core i7-9700K: новейшая вершина Intel Core i7 (теперь с 8 ядрами)
Наш последний процессор для тестирования — Core i7-9700K. В нынешнем поколении это уже не флагман Coffee Lake (теперь это i9-9900K), но имеет восемь ядер без гипертрединга. Сравнение с 9900K, имеющим вдвое больше ядер и потоков, выглядит бессмысленным, тем более когда цена i9 составляет 488 долларов. В отличие от этого, Core i7-9700K продается оптом «всего лишь» по $ 374, с базовой частотой 3,6 ГГц и турбо-частотой 4,9 ГГц. Его TDP определено Intel в 95 Вт, но на потребительской материнской плате чип потребляет ~ 125 Вт при полной нагрузке. Память DDR4-2666 поддерживается в качестве стандарта.
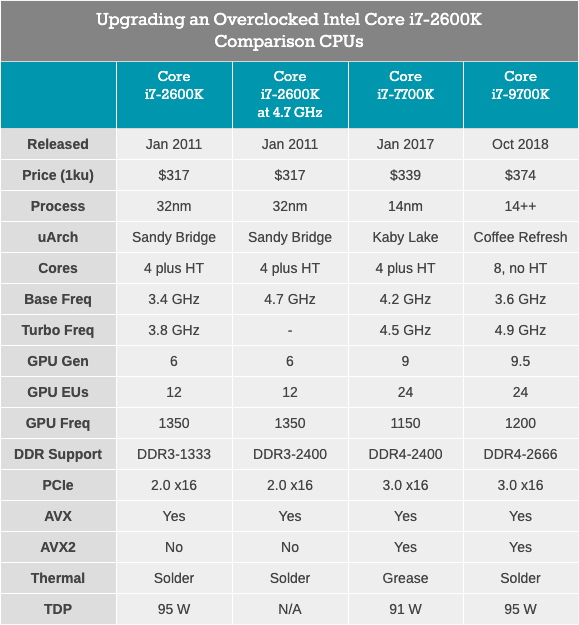
Core i7-2600K вынужден работать с DDR3, поддерживает PCIe 2.0, а не PCIe 3.0, и, не предназначен для работы с NVMe накопителями (которые не участвуют в этом тестировании). Будет интересно посмотреть, насколько близок разогнанный ветеран к Core i7-7700K, и какой прирост мы увидим при переходе к чему-то вроде Core i7-9700K.
Sandy Bridge: Архитектура ядра
В 2019 году мы говорим о микросхемах размером 100-200 мм2, имеющих до восьми высокопроизводительных ядер, и созданных на последних вариантах техпроцесса Intel или AMD GlobalFoundries/TSMC. Но 32нм Sandy Bridge был совсем другим зверем. Производственный процесс был всё ещё «плоским», без транзисторов FinFET. В новом CPU было реализовано второе поколение High-K, и было достигнуто масштабирование 0,7x по сравнению с предыдущим, более крупным 45-нм техпроцессом. Core i7-2600K был самым большим четырехъядерным чипом, и вмещал 1,16 млрд. Транзисторов на 216 мм2. Для сравнения, новейший процессор Coffee Lake на 14 нм вместил восемь ядер и более 2 млрд. Транзисторов на площади с ~ 170 мм2.
Секрет огромного скачка производительности кроется в микроархитектуре процессора. Sandy Bridge обещал (и обеспечил) значительный производительности при равной тактовой частоте, по сравнению с процессорами Westmere предыдущего поколения, а также сформировал базовую схему для чипов Intel на следующее десятилетие. Множество ключевых нововведений впервые оказались в розничной продаже с появлением Sandy Bridge, а затем повторялись и улучшались множество итераций, постепенно достигнув той высокой производительности, которой мы пользуемся сегодня.
В текущем обзоре я во многом опирался на первоначальный отчет Anandtech об микроархитектуре 2600K, вышедший в 2010 году. Конечно, с некоторыми дополнениями, основанными на современном взгляде на этот процессор.
Краткий обзор: ядро CPU с внеочередным исполнением инструкций
Для новичков в разработке процессоров, вот краткий обзор того, как работает процессор с внеочередным исполнением. Коротко говоря, ядро делится на внешний и внутренний интерфейсы (front end и back end), и данные сначала поступают во внешний интерфейс.
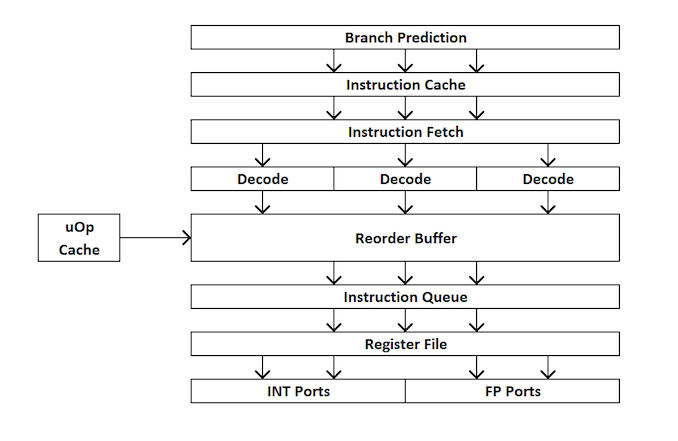
Во внешнем интерфейсе у нас есть средства предварительной выборки и предсказатели ветвлений, которые будут предсказывать и извлекать инструкции из основной памяти. Идея заключается в том, что если вы можете предсказать, какие данные и инструкции понадобятся в ближайшее время (до того, как они будут востребованы), то сможете сэкономить время, разместив эти данные близко к ядру. Затем инструкции помещаются в декодер, который преобразует инструкцию байт-кода в ряд «микроопераций», которые ядро затем может обрабатывать.
Существуют различные типы декодеров для простых и сложных инструкций — простые инструкции x86 легко отображаются на одну микрооперацию, тогда как более сложные инструкции могут декодироваться на большее количество операций. Идеальная ситуация — это максимально низкий коэффициент декодирования, хотя иногда инструкции могут быть разделены на большее количество микроопераций, если эти операции могут выполняться параллельно (параллелизм на уровне команд или ILP).
Если ядро имеет кэш микроопераций, он же кэш uOp, то результаты каждой декодированной инструкции сохраняются в нём. До того, как инструкция будет декодирована, ядро проверяет, была ли эта конкретная команда декодирована недавно, и в случае успеха использует результат из кеша вместо повторного декодирования, которое расходует энергию.
Сейчас микрооперации ставятся «очереди на размещение» — allocation queue. Современное ядро может определить, являются ли инструкции частью простого цикла, или же uOps (микрооперации) можно объединить для ускорения всего процесса. Затем uOps подаются в re-order буфер, который образует «back end» ядра.
В бэкэнде, начиная с re-order буфера, uOps можно переставлять в зависимости от того, где находятся данные, необходимые каждой микрооперации. Этот буфер может переименовывать и распределять микрооперации в зависимости от того, куда они должны идти (целочисленные операции или FP), и, в зависимости от ядра, он также может выступать в качестве механизма удаления завершенных инструкций. После re-order буфера uOps подаются в планировщик в нужном порядке, чтобы убедится в готовности данных, и максимизировать пропускную способность uOp.
Планировщик передает uOps в порты выполнения (для выполнения вычислений) по мере необходимости. Некоторые ядра имеют единый планировщик для всех портов, однако в некоторых случаях он разделен на планировщик для целочисленных операций / операций с векторами. Большинство ядер с внеочередным исполнением имеет от 4 до 10 портов (некоторые больше), и эти порты выполняют необходимые вычисления, что бы инструкция «прошла» через ядро. Порты выполнения могут принимать вид модуля загрузки (загрузка из кэша), модуля хранения (сохранение в кеше), модуля целочисленных математических операций, модуля математических операций с плавающей запятой, а так же векторных математических операций, специальных модулей деления, и некоторых других для специальных операций. После того, как порт выполнения отработал, данные могут быть сохранены в кеш для повторного использования, помещены в основную память; в это время инструкция отправляется в очередь удаления, и, наконец, удаляется.
Этот краткий обзор не затрагивает некоторые механизмы, которые современные ядра используют для облегчения кэширования и поиска данных, такие как буферы транзакций, потоковые буферы, тегирование и т. д. Некоторые механизмы итеративно улучшаются при каждом поколении, но обычно, когда мы говорим о «инструкциях за такт» в качестве показателя производительности, мы стремимся «пропустить» как можно больше инструкций через ядро (через фронтэнд и бэкэнд). Этот показатель зависит от скорости декодирования на фронтэнде процессора, предварительной выборки команд, re-order буфера, и максимльного использования портов исполнения наряду с удалением максимального числа выполненных команд за каждый тактовый цикл.
С учетом вышесказанного, мы надеемся, что читатель сможет глубже понять результаты тестирования Anandtech, полученные во времена запуска Sandy Bridge.
Sandy Bridge: фронтэнд
Архитектура CPU Sandy Bridge выглядит эволюционной при беглом обзоре, но она революционна с точки зрения количества транзисторов, которые изменились со времен Nehalem / Westmere. Самым важным изменением для Sandy Bridge (и всех микроархитектур после него) является микрооперационный кеш (uOp cache).

В Sandy Bridge появился микрооперационный кеш, который кэширует инструкции после их декодирования. Здесь нет сложного алгоритма, декодированные инструкции просто сохраняются. Когда префетчер Sandy Bridge получает новую инструкцию, сначала происходит поиск инструкции в кеше микроопераций, и если она найдена, то оставшаяся часть конвейера работает с кешем, а фронтэнд отключается. Аппаратное обеспечение декодирования является очень сложной частью конвейера x86, и его отключение экономит значительное количество энергии.
Это кэш прямого отображения, и может хранить приблизительно 1,5 КБ микроопераций, что фактически эквивалентно 6 КБ кэшу инструкций. Кэш микроопераций включен в кэш инструкций L1, и его Hit Rate для большинства приложений достигает 80%. Кэш микроопераций имеет чуть более высокую и стабильную пропускную способность по сравнению с кэшем инструкций. Фактические L1 кэши команд и данных не изменились, они по-прежнему составляют 32 КБ каждый (всего 64 КБ L1).
Все инструкции, поступающие из декодера, могут кэшироваться этим механизмом, и, как я уже говорил, в нем каких-то особых алгоритмов – попросту, все инструкции кэшируются. Давно не использованные данные удаляются, когда заканчивается место. Микрооперационный кеш может показаться похожим на кэш трассировки в Pentium 4, но с одним существенным отличием: он не кэширует трассировки. Это попросту кэш инструкций, в котором хранятся микрооперации вместо макроопераций (инструкции x86).
Наряду с новым микрооперационным кешем Intel также представила полностью переработанный модуль прогнозирования ветвлений. Новый BPU примерно такой же, как и его предшественник, но гораздо точнее. Увеличение точности является результатом трех основных инноваций.
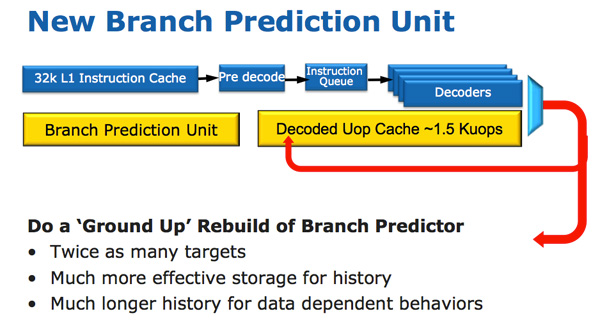
Стандартный предсказатель ветвления является 2-битным предсказателем. Каждая ветвь отмечается в таблице как принятая / не принятая с соответствующей достоверностью (сильная / слабая). Intel обнаружила, что почти все ветви, предсказанные этим бимодальным предиктором, имеют «высокую» достоверность. Поэтому в Sandy Bridge бимодальный предсказатель ветвлений использует один бит достоверности для нескольких ветвей, а не один бит достоверности для каждой ветви. В результате у вас в таблице истории ветвей будет такое же, как и раньше, количество битов, представляющих гораздо больше ветвей, что приводит к более точным прогнозам в будущем.
Sandy Bridge: около ядра
С ростом многоядерных процессоров управление потоком данных между ядрами и памятью стало важной темой. Мы видели множество различных способов перемещения данных вокруг ЦП, таких как топологии crossbar (перекрестная), ring (кольцевая), mesh (сеточная) и, позднее, полностью отдельные микросхемы ввода-вывода. Битва следующего десятилетия (2020+), как упоминалось ранее AnandTech, будет битвой межядерных соединений, и сейчас она уже начинается.
Особенность Sandy Bridge как раз заключается в том, что это был первый потребительский ЦП от Intel, который использовал кольцевую шину, соединяющую все ядра, память, кэш последнего уровня и интегрированную графику. Это все еще тот же дизайн, что мы наблюдаем в современных процессорах Coffee Lake.
Кольцевая шина
В Nehalem/Westmery Bridge добавляет на чип графический процессор и движок транскодирования видео, которые совместно используют кэш-память L3. И вместо того, чтобы прокладывать больше проводов к L3, Intel представила кольцевую шину.
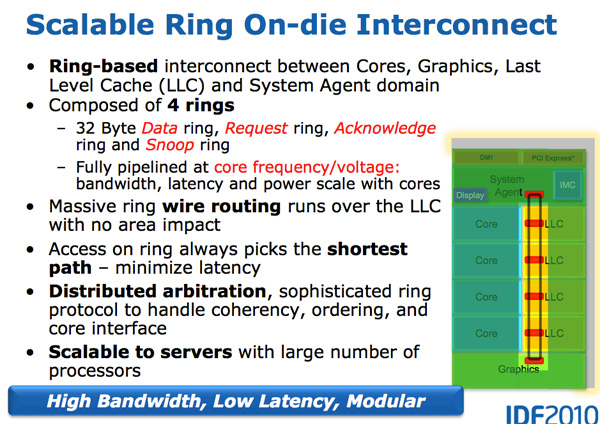
Архитектурно, это та же кольцевая шина, которая используется в Nehalem EX и Westmere EX. Каждое ядро, каждый фрагмент кэша L3 (LLC), встроенный графический процессор, медиа-движок и системный агент (забавное название для северного моста) присоединены к кольцевой шине. Шина состоит из четырех независимых колец: шины данных, запросов, подтверждений и шины мониторинга состояний. Каждая обращение к любому из колец может передавать 32 байта данных за такт. По мере увеличения количества ядер и размера кэша пропускная способность вашего кэша соответственно увеличивается.
На каждое ядро в итоге приходится тот же объем пропускной способности кэша L3, что и в высокопроизводительных процессорах Westmere — 96 ГБ/с. Совокупная пропускная способность Sandy Bridge в 4 раза выше, чем в четырехъядерном Westmere, поскольку она просто умножается на количество ядер, и составляет 384 ГБ/с.
Это означает, что задержка L3 значительно уменьшена с примерно 36 тактов в Westmere до 26 — 31 такта в Sandy Bridge (с некоторой переменной задержкой кэша, которая зависит от того, какое ядро обращается к какому фрагменту кэша). Кроме того, в отличие от Westmere, кэш-память L3 теперь работает на тактовой частоте ядра — концепция un-Core все еще существует, но Intel называет внеядерную часть «системным агентом», и больше не включает в неё кэш-память L3. (Термин «un-Core» все еще используется сегодня для описания межсоединений.)
Благодаря кэш-памяти L3, работающей на частоте ядра, вы получаете преимущества гораздо более быстрого кеша. Недостатком является то, что L3 разгоняется вместе с ядрами процессора, когда включаются режимы турбо или простоя. Если графическому процессору нужен L3, когда частота ядер понижена, кэш L3 не будет работать так же быстро, как если бы он был независимым. Или системе придется разгонять ядро и потреблять дополнительную мощность.
Кэш L3 разделен на фрагменты, каждый из которых ассоциируется с отдельным ядром. Поскольку Sandy Bridge имеет полностью доступный кэш L3, каждое ядро может адресовать весь кэш. Каждый фрагмент собственный контроллер доступа к шине, и полноценный конвейер кэша. В Westmere был один конвейер кэша и очередь, в которую все ядра отправляли запросы, но в Sandy Bridge они распределяются по сегментам кэша. Использование кольцевой шины означает, добавление новых точек доступа в шину перестало критически влиять на размер матрицы. Несмотря на то, что каждый из пользователей кольца получает собственный контроллер, данные всегда идут по кратчайшему пути. Управление шиной распределено по всему кольцу, и в результате каждый модуль «знает», был ли свободный слот на шине один такт назад.
Системный агент
По какой-то причине Intel перестала использовать термин un-core в SB, и в Sandy Bridge назвала эту часть «системным агентом». (Опять-таки, в настоящее время un-core снова в моде для межсоединений, ввода-вывода и контроллеров памяти). Системный агент представляет собой традиционный Северный мост. Вам доступно 16 линий PCIe 2.0, которые можно разделить на два канала x8. Имеется переработанный двухканальный контроллер памяти DDR3, который, наконец, обеспечивает задержку памяти примерно на уровне Lynnfield (Clarkdale переместил контроллер памяти с ЦП на графический процессор).
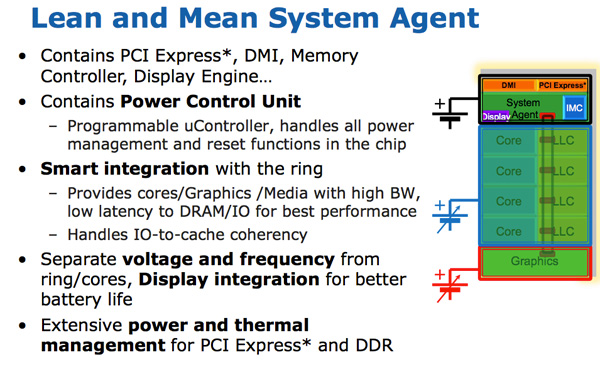
Системный агент также имеет интерфейс DMI, блок видеовыхода и PCU (блок управления питанием). Тактовая частота SA ниже, чем у остальной части ядра, и имеет отдельную схему питания.
Графика Sandy Bridge
Еще одно значительное улучшение производительности Sandy Bridge в сравнении с Westmere касается обработки графики. В то время как процессорные ядра показывают улучшение производительности на 10-30%, графическая производительность Sandy Bridge попросту вдвое выше, чем у продуктов Intel до Westmere (Clarkdale / Arrandale). Несмотря на скачок с 45 нм до 32 нм, скорость обработки графики улучшается благодаря значительному увеличению IPC.
Графический процессор Sandy Bridge построен на тех же 32-нм транзисторах, что и ядра процессора. Графический процессор находится в своем собственном мирке в смысле питания и частоты. GPU может быть выключен или включен независимо от процессора. Графическое турбо доступно как для десктоп, так мобильных процессоров.
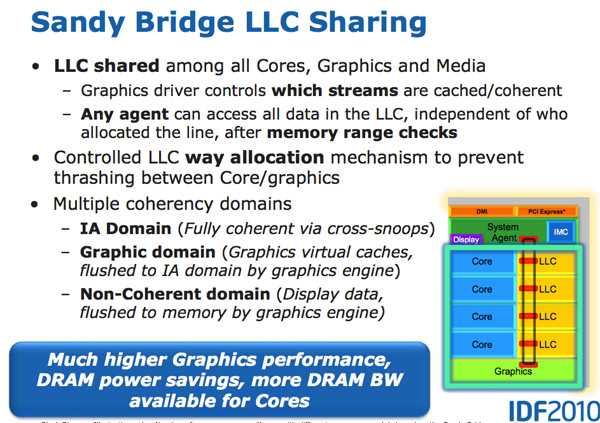
GPU рассматривается как равноправный гражданин в мире Sandy Bridge, и получает полный доступ к кэш-памяти L3. Графический драйвер контролирует, что именно попадает в кэш L3, и вы даже можете ограничить объем кеша, который доступен графическому процессору. Хранение графических данных в кеше особенно важно, поскольку оно уменьшает обращения в основную память, которые являются дорогостоящими как с точки зрения производительности, так и с точки зрения энергопотребления. Но перестройка графического процессора для использования кэша не является простой задачей.
Графика SNB (внутреннее название Gen 6) широко использует аппаратное обеспечение с фиксированными функциями. Идея такая: всё, что можно описать с помощью фиксированной функции, которая должно быть реализовано хардварной фиксированной функцией. Преимущество – производительность, мощность и уменьшенный размер матрицы, хотя и за счет потери гибкости.
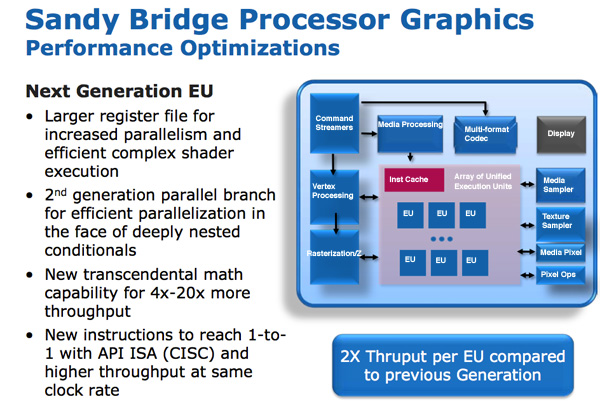
Программируемое аппаратное обеспечение шейдеров состоит из шейдеров / ядер / исполнительных блоков (execution units), которые Intel называет EU. Каждый EU может принимать инструкции из нескольких потоков. Внутренний ISA сопоставлен один-к-одному с большинством инструкций API DirectX 10, что щзначает CISC-подобную архитектуру. Переход от взаимно-однозначного API к отображению инструкций увеличивает IPC за счет эффективного увеличения ширины EU.
В EU есть и другие улучшения. Трансцендентная математика обрабатывается аппаратными средствами в EU, и ее производительность значительно возросла. Intel тогда сообщила, что операции синуса и косинуса теперь на несколько порядков быстрее, чем в графике до Westmere.
В предыдущих графических архитектурах Intel регистровый перераспределялся «на лету». Если потоку требуется меньше регистров, остальные регистры могут быть выделены другому потоку. Несмотря на то, что это был отличный подход для экономии площади матрицы, он оказался ограничителем производительности. Часто потоки не могли быть обработаны, поскольку не было доступных регистров для использования. Intel увеличила число регистров на поток сначала с 64 до 80, и, затем, до 120 для Sandy Bridge. Сценарии простоев из-за недостатка регистров значительно сократились.

В сумме, все эти усовершенствования привели к удвоению пропускной способности инструкций в EU.
При запуске было две версии GPU Sandy Bridge: одна с 6 EU и одна с 12 EU. Все мобильные процессоры (при запуске) используют 12 EU, в то время как в настольных SKU может использоваться 6 или 12 в зависимости от модели. Sandy Bridge был шагом в нужном направлении для Intel, так как интегрированная графика начала становиться обязательной для потребительских продуктов, и Intel постепенно начала увеличивать процент площади чипа, выделенный для GPU. Современные (2019 г.) настольные процессоры аналогичного уровня имеют 24 EU (Gen 9.5), в то время как будущие 10-нм процессоры будут иметь ~ 64 EU (Gen11).
Sandy Bridge Media Engine
Рядом с GPU Sandy Bridge находится медиа-процессор. Обработка мультимедиа в SNB состоит из двух основных компонентов: декодирование видео и кодирование видео.
Механизм декодирования с аппаратным ускорением был улучшен по сравнению с текущим поколением: теперь весь видео конвейер декодировался с помощью модулей с фиксированными функциями. Это контрастирует с дизайном Intel до SNB, в котором для некоторых этапов декодирования видео используется массив EU. В результате Intel утверждает, что потребляемая мощность процессора SNB снижается вдвое при воспроизведении HD-видео.
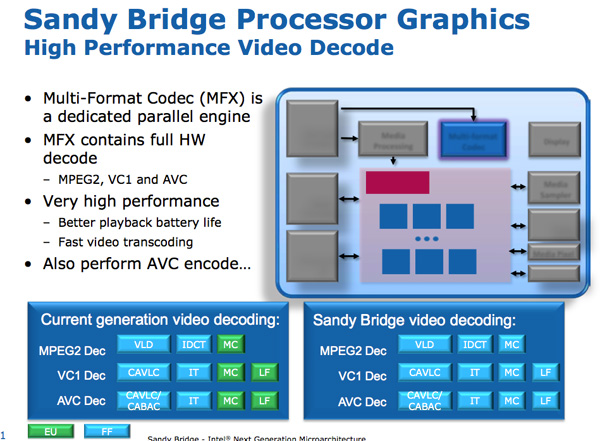
Механизм кодирования видео был совершенно новым дополнением к Sandy Bridge. Intel взяла ~ 3-минутное исходное видео 1080p 30 Мбит/с и перекодировала его в видеоформат iPhone 640 x 360. Весь процесс занял 14 секунд и завершился со скоростью примерно 400 кадров в секунду.
Принцип кодирования / декодирования фиксированной функцией теперь распространен в любом графическом оборудовании для настольных компьютеров и даже смартфонов. В те времена Sandy Bridge использовал матрицы размером 3 мм2 для этой базовой структуры кодирования / декодирования.
Новый, Агрессивный Турбо
Lynnfield был первым процессором Intel, который активно продвигал идею динамического увеличения тактовой частоты активных ядер процессоров при отключении неработающих ядер. Идея состоит в том, что если у вас есть TDP 95 Вт для четырехъядерного процессора, но три из этих четырех ядер простаивают, то вы можете увеличивать тактовую частоту одного активного ядра, пока не достигнете турбо-предела.
Во всех процессорах текущего поколения предполагается, что процессор достигает предела турбо-мощности сразу после включения турбо. В действительности, однако, процессор не нагревается мгновенно — есть период времени, когда процессор не рассеивает свою полную потребляемую мощность и набирает температуру.
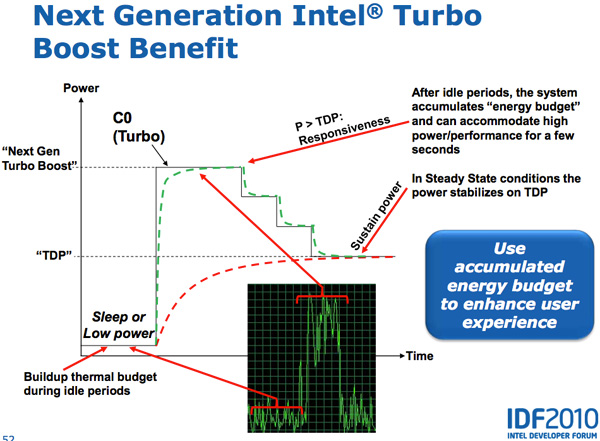
Sandy Bridge использует эту возможность, позволяя PCU разгонять активные ядра выше TDP на короткие промежутки времени (до 25 секунд). PCU отслеживает доступный тепловой бюджет во время простоя и тратит его, когда увеличивается нагрузка на процессор. Чем дольше процессор остается бездействующим, тем больше запас, на который можно превысить TDP. В итоге, при появлении рабочей нагрузки, центральный процессор включает турбо с превышением TDP, и понижает частоту снова, когда процессор нагревается, в конечном итоге останавливаясь на своем TDP. Хотя SNB может выходить за пределы своего TDP, PCU не позволит чипу превысить пределы надежности.

И CPU, и GPU Turbo могут работать в тандеме. Рабочие нагрузки, которые в большей степени связаны с GPU, работающими на SNB, могут привести снижению частоты ядер CPU, и повышению частоты GPU. Так же задачи, связанные с CPU, могут снизить частоту GPU и увеличить частоту CPU. Sandy Bridge в целом оказался намного более гибким механизмом, чем все, что было создано до него.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Источник


