
Привет, меня зовут Антон Фурсов, и я занимаюсь автоматизацией тестирования в Pixonic. Сегодня поговорим про уже набившую уже всем оскомину автоматизацию тестирования. В последнее время стало модно внедрять ее везде и всюду, но в геймдеве она до сих пор встречается не так часто — из-за специфики самой сферы.
Для начала стоит кратко обозначить, о чем пойдет речь:
• Нужна ли проекту автоматизация тестирования в целом и готов ли он для этого;
• Сколько ресурсов это может стоить в перспективе и чем может аукнуться;
• Важные, казалось бы, «мелочи», которые многие часто упускают из виду, когда принимают решения;
• Как мы в Pixonic с этим живем уже пятый год и что делаем для развития и поддержки.
Начнем по порядку с тем попроще и плавно будем спускаться в «подвал» к нашим велосипедам.
War Robots — флагман Pixonic, которому уже без почти девять лет. А это значит, что в нем бездонная яма мета-механик (речь идет о различных механиках менеджмента роботов и их обвесах, разных социальных фичей вроде кланов и лиг и всего такого прочего) и интерфейсов. Плюс, все это полируется сверху весьма глубоким core-геймплеем (то есть всем, что происходит в бою: стрельба, передвижение, захваты маяков, уникальные способности роботов и прочее) с приличным количеством механик. И еще сверху разнообразный контент (роботы, пилоты, пушки, модули и много-много другого), который постоянно добавляется в игру. Все это генерирует очень много работы для QA отдела — лет на сто вперед. И глядя на это, можно придти к мысли, что автоматизация тестирования здесь не просто нужна, а необходима.
Так что же в такой ситуации становится решающим фактором? Давайте поговорим о вещах, которые справедливы для любой сферы разработки — не важно, геймдев это, веб-разработка или какое-либо другое ПО:
-
Первое и, наверное, самое важное — это деньги. То есть, насколько в конкретном проекте целесообразно внедрять автоматизацию. Особенно этот фактор актуален в случаях, если проект постоянно меняется, а для геймдева это — почти стандартная. У нас в любой могут прийти продюсеры и сказать: «Переделывайте вообще все, концепт — ерунда». Так что если ваш бюджет ограничен, а сама сфера рисковая, то я бы трижды задумался, стоит ли игра свеч, потому что автоматизация тестирования — удовольствие не из дешевых. Далее мы еще посмотрим, насколько именно.
-
Второе. Процессы тестирования и их состояние — очень важный фактор. Потому что если вы до сих пор клеите разработчикам стикеры с багами на монитор и передаете код проекта на флешке друг другу, то автоматизация тестирования — это не для вас, ведь она весьма требовательна к тестовому покрытию, которое у вас уже сделано. Другими словами, вы ее встраиваете не просто где-то рядом, а строите на том фундаменте, что у вас уже есть. Такая вот банальная банальность.
И еще немного о вещах, справедливых в большей степени только для геймдева:
-
Смерть в зародыше — бич игровых проектов. Количество прототипов, погибающих на ранних этапах разработки, очень велико. Большинство проектов не доживает даже до софт-лонча. Соответственно, вкладывать деньги в автоматизацию тестирования на проекте, который не факт, что выстрелит или хотя бы отобьется — сомнительное занятие.
-
«Культура» разработки накладывает свои ограничения, так как ниша очень конкурентная, и порой надо уметь быстро запрыгнуть на хайп-трейн. Выстрелил условный Apex Legends — все ломанулись делать батлрояли, и кто успел, того и тапки. Плюс, все всегда пытаются срезать косты. Поэтому в пайплайны игровой разработки очень тяжело встраиваются такие процессы, как автоматизация тестирования, которые требовательны к тому, чтобы все было сносно. Мы не будем говорить идеально. Сносно.
-
Скудность инструментария для автоматизации тестирования и необходимость городить свои «велосипеды». Это было справедливо до недавнего времени, сейчас индустрия бурно растет, ширится, вследствие чего появляются новые инструменты для решения задач по автоматизации. Тем не менее, если взять во внимание предыдущий пункт, даже существующие решения и инструменты весьма проблематично встроить в процессы игровой разработки.
-
Взаимодействие с пользователем на совершенно ином уровне. Иными словами, это более комплексный подход взаимодействия с потребителем, нежели в условном банковском приложении, где есть весьма четкие паттерны пользовательского взаимодействия. Все-таки игры больше про тактильность, когда игрок должен ощутить процесс, быть вовлеченным в него, получать от него удовольствие, как, например, тот же пресловутый импакт от стрельбы или, если вы играли в последнего «Человека-паука», — перемещение в пространстве на паутине. Такие вещи фактически невозможно автоматизировать, они про эмоции.
Если подвести промежуточный итог, то проект в модели GaaS (Game as a Service) — наш идеальный кандидат. Это означает, что проект будет поддерживать и развивать долгое время, и заводить в него автотесты — хорошая идея.
Итак, мы вывели тезис, что автоматизация тестирования как рабочий инструмент — удовольствие не из дешевых. Допустим, нас это не пугает и мы полны решительности внедрить ее. С какими еще проблемами можно столкнуться, что может пойти не так, в теории?
-
Первое: автоматизацию тестирования тяжело продавать менеджменту, потому что он не видит прямой связи между качеством и прибылью. Ты никогда не продашь менеджеру мысль «автотесты — это прибыльно». Он тебе скажет: «Ты что, поехавший? Вот новая пушка за десять баксов — это прибыльно. А вот эти автотесты — давай как-нибудь потом».
-
Автоматизация — это лишь дополнительный слой качества. Никогда не стоит ее воспринимать как ультимативное решение, заменяющее «ручников». В принципе, для геймдева очевидно, что автоматизация никогда не заменит ручное тестирование, потому что игру надо не только технически проверить. Надо выяснить, работают ли фичи в принципе как игровые элементы, интересны ли они, будет ли пользователь в это играть, будет ли ему нравиться. Поэтому автотесты могут спасти от рутины, но не заменят людей.
-
Ну и автоматизация — это не только про код тестов, как может показаться. Это куча обвязок вокруг, это системы отчетности, свое тестовое окружение, настроенное конкретно под нужды автотестов. У нас это, например, Device Manager, который отвечает за распределение тестов по девайсам, чтобы они друг с другом взаимодействовали, воевали и так далее. Бонусом, это разные вспомогательные библиотеки, куча всяких хелперов по работе с движком, которые вытаскивают информацию из движка. В общем, много всего разнообразного и не менее важного.
Теперь к сухим цифрам по стоимости: в нашем случае это было четыре года активной разработки, три человека (два полноценных разработчика и один QA Automation), умножаем все на средний оклад этих трех человек. Плюс, цена на инструменты (ПО, тестовая ферма), но я бы сказал, что это уже погрешность на фоне предыдущих затрат. Соответственно, вот с такими цифрами и стоит приходить к менеджеру. Во всяком случае, эти цифры справедливы на этапе разработки, на поддержке разработчики могут отвалится, но это уже у кого как.
Цена автоматизации = 4 года активной разработки × 3 человека × средний оклад + инструменты
И еще немного мыслей и советов, набитых на личном опыте:
-
Экономия времени QA-отдела и повышение качества — весомый аргумент. Когда мы пытались протолкнуть идею автоматизации тестирования, менеджмент первым делом спросил, где на это взять деньги. Мы сказали: «Вот у нас есть комплект регрессионных тестов. Он, условно, занимает 200 человеко-часов каждый релиз. Всё это можно списать на автотесты, получится высвободить эти самые 200 часов с каждого релиза. А уже высвобожденные ресурсы ребята из QA могут, например, потратить на приемочное тестирование или тестовую документацию». А менеджмент в ответ: «Так и быть. Вам на зарплаты хватит».
-
Хорошая отчетность лучше плохой, а плохая — лучше никакой. Всегда нужно четко понимать, что вы хотите проверить своими тестами и что хотите увидеть в итоге. И крайне желательно прикрутить хоть какую-нибудь мало-мальски репрезентативную отчетность, так как именно артефакты являются ключевым фактором в разборах упавших тестов. Списка тестов, где часть тестов зеленая, а часть — красная, будет недостаточно. Важно ведь понимать, по какой причине упал тот или иной тест. И чем больше отчетности — тем лучше. Но к этому мы еще вернемся.
-
Начинай с малого. Стартовать всегда лучше с небольшого пула тестов. Берете, например, какой-нибудь набор Build Verification тестов или небольшой комплект тестов (штук 20 максимум), в которых вы уверены на 100%: знаете, что функционал, который они покрывают — стабильный, его не планируется менять в обозримом будущем, и спокойно обкатываете на этом весь процесс. То есть, вы покрыли автотестами этот небольшой пул и начинаете их эксплуатировать на постоянной основе. Дело в том, что даже с таким небольшим пулом тестов с началом эксплуатации всплывет куча нюансов: начиная от самого окружения, как оно настроено, ведет себя и чего еще нужно донастроить, и заканчивая тем, что еще вам нужно допилить на стороне клиента, какие еще эндпоинты из него прокинуть в фреймворк автотестов.
-
Кидаться в автоматизацию без опыта, в одиночку и в свободное время — сомнительное занятие. Уверяю вас, бизнесу пользы от таких потуг не будет — просто потому, что у вас нет опыта. Никто это не одобрит. К тому же, есть большой риск научиться плохому, потому что, когда ты варишься в этом процессе один, без четкого понимаю, что и как нужно делать, можно наворотить много всякого неприятного. Лучше потратьте это время на себя, на самообучение и подтягивание квалификации.
Сейчас у нас порядка 2000 тестов разной направленности, если совсем точно — 1884. Покрытие периодически наращивается, ведь мы не стоим на месте. Соответственно, есть тесты метагейма — все наши UI, магазины, ангар, кланы, лиги, то есть все, что не касается непосредственно core-механик. Есть тесты core-механик, то есть непосредственно боев, где роботы сражаются, стреляют, передвигаются, захватывают маяки. И еще дополнительные вспомогательные тесты — бенчмарки, тесты локализации, тесты утечек памяти. Помимо этого у нас есть еще немного юнит-тестов на сам фреймворк автотестов, чтобы проверять автотесты, когда ты пишешь автотесты. Они проверяют базовые вещи — вроде того, что хэндлеры присылают нам правильные вещи из клиента.




Бенчмарки и утечки памяти
Бенчмарки — это, пожалуй, самый популярный вид автоматизации игровых проектов, потому что он беспроигрышный: померять производительность — это всегда здорово и полезно. В нашем случае у нас есть сценарий, зашитый в клиент. Например, пустой скайбокс, на фоне которого спавнятся десять пушек. Далее беспрерывно стреляем из них одновременно — соответственно, проигрываются соответствующие анимации с эффектами и частицами, вокруг всего этого крутится камера, а длится весь процесс, например, 30 секунд. Все эти 30 секунд мы записываем, сколько кадров игра успела отрисовать.

Потом мы строим графики из получившихся цифр с отрисованными кадрами и смотрим, что, где и как: есть ли деградация по сравнению с предыдущим запуском или все стало лучше. На графике кадры — по оси Y, дата запуска — по оси Х, цветные линии — это девайсы, на которых мы запускаем.

Таким образом, бенчмарки у нас изолированы. То есть мы можем проверять контент изолированно друг от друга, но у нас есть еще и общий бенчмарк. Полезно, красиво, наглядно.
Что касается утечек памяти, то там сценарий достаточно простой. Запускаем игровую сцену — например, ангар. Из этого ангара переходим в бой — это уже другая сцена. Проверяем, остались ли у нас какие-то атласы, материалы или еще что-то, не уничтоженное после этого перехода. Остались? Значит, мы течем по памяти. Берем список того, что не уничтожается, идем в клиент, говорим «А-та-та».
Далее — трекинг времени загрузок и переходов между экранами. В любом тесте, который выполняется в рамках прогонов регресса, мы трекаем время от холодного запуска до попадания в ангар. Соответственно, строим графики: Y — время загрузки, X — когда тест был прогнан, цветные линии — девайсы, на которых все это гонялось.

Да, были такие проблемы, что проседало время загрузки, мы начали это трекать и смотреть. На графике — сумасшедшие времена, потому что девайсы попроще, и мы в какой-то момент прикрутили delivery-систему (закачка бандлов на старте), которая растянула время холодной загрузки на время скачивания бандлов с ресурсами.
Также мы трекаем время переходов между экранами. В чем суть? Например, в рамках приложения, когда ты переходишь, условно говоря, из экрана, в котором ты создаешь клан, в экран Лиг, происходит загрузка. И иногда эти загрузки могут «подтекать», так что мы решили все эти вещи замерять.
В рамках этих проверок есть общий сценарий, который ходит по всем основным экранам игры и замеряет время загрузки между ними. На основе полученных данных строится график, идентичный графику с временем холодно старта — только там, конечно, не секунды, а миллисекунды. В принципе, это тоже полезно: видим, где и на каких девайсах у нас есть проблемы по переходам, потому что старые девайсы тоже надо поддерживать, там тоже есть игроки.
Контент и локализация
Далее — контент и локализация. Я их называю полуавтоматическими проверками, потому что в любом случае результат этих проверок должен прийти и посмотреть живой QA-специалист.
В чем суть? Пишем видео, где воспроизводим какой-то эффект. Качеством этого видео мы можем управлять: можно записать максимально возможное доступное качество, либо супершакальное — что захочется. Список контента прогоняем, а на выходе получаем пачку роликов. QA-специалист пришел, отсмотрел, завел баги — разработчик починил, билд пересобрал. Цикл повторился, если есть на то необходимость.

С локализацией примерно то же самое. Запускаются тестовые сценарии, которые ходят по нужным нам окнам, переключают при этом языки и делают скриншоты этих окон. Таким образом, получается пачка скриншотов интерфейсов на разных языках, которые потом, по аналогии с роликами из тестов эффектов, проверяет живой QA-специалист.
В чем польза? Вы проверяете не только текст, но еще и верстку и, возможно, битые шрифты, потому что всякие корейско-китайские шрифты любят ломаться. И все то же самое, что с визуальными эффектами: баг завели, баг поправили, цикл повторился. Основной профит в том, что человек не тратит время на то, чтобы засетапить себе все это и кликать самому.
А теперь наконец-то давайте посмотрим код.
Тесты — тоже код
На скриншоте ниже, правда, плохой код, так писать не надо. Так что избавляемся от лишнего.
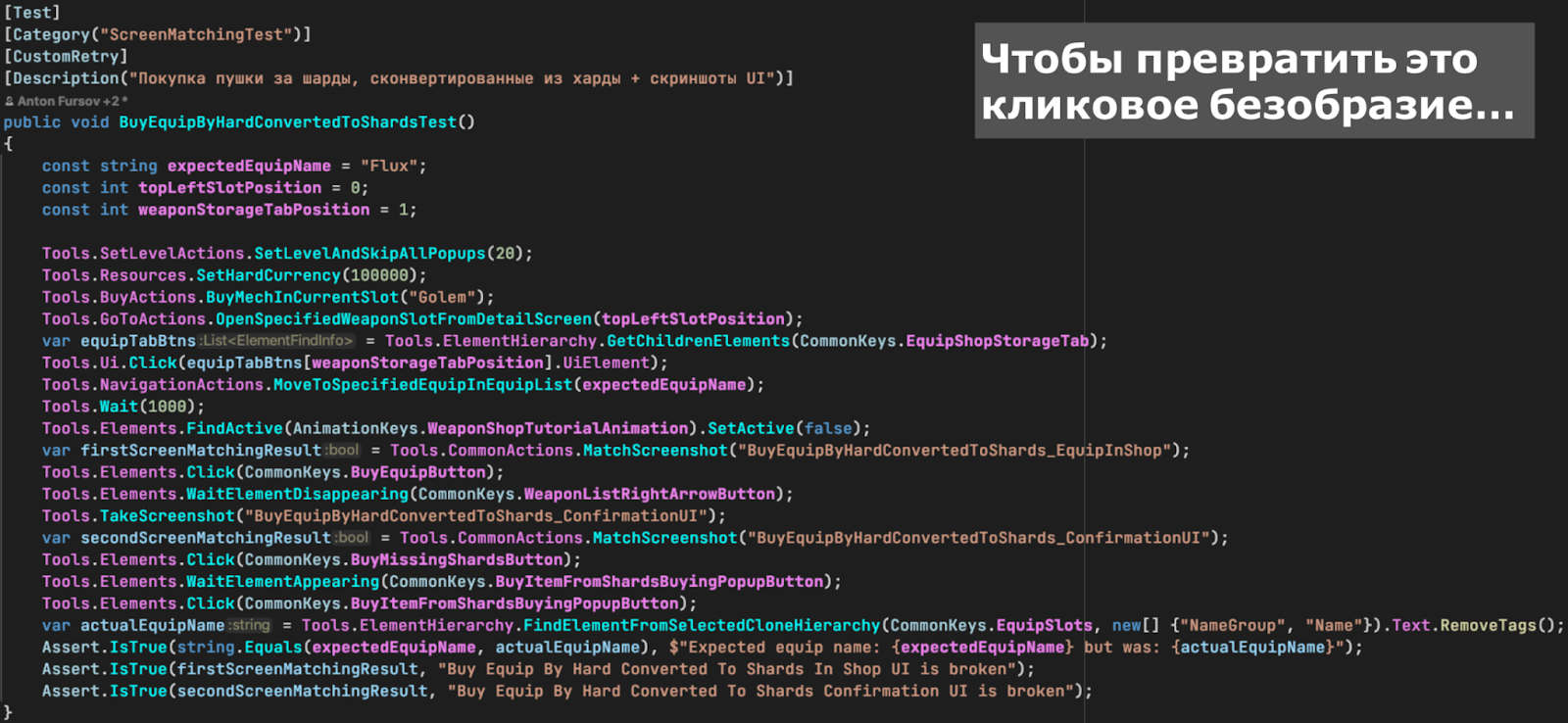
Нам нужно, чтобы все выглядело читабельно и было похоже на сценарий: ты зашел, просто «прочитал», что делает тест, понял, что он в конце проверяет. Такое легко править, легко поддерживать, людей легко на это подсаживать.

Что мы делаем, чтобы так было? Пару простых банальностей. Для людей, которые читали чистый код — это прописные истины.
-
Нейминг. Даже чиселки надо называть соответствующими именами. Вот у вас есть какой-то Waiter, он ждет 2000 миллисекунд. Вы написали Wait(2000) и ушли, тест работает. Два года спустя возвращаетесь: а что я тут ждал? Непонятно. Пока ты сценарий не запустишь — не поймешь, зачем ты ждешь эти две секунды. А назвал правильно — и тогда не надо лишний раз ничего запускать, достаточно просто посмотреть на код.
-
Переиспользование кода. Все, что часто повторяется, мы оборачиваем в методы, структуры и переиспользуем от теста к тесту.
-
Периодически старые тесты нужно вентилировать. Код устаревает, тесты сами по себе устаревают и теряют актуальность. Вы даже можете не подозревать, что у вас тест работает вхолостую. Он зелененький, но уже ничего вообще не проверяет, потому что кто-то когда-то решил экран, на который он был написан, переделать.

Еще у нас есть так называемые хелперы — это методы на основе часто повторяющихся действий в игре. В рамках игры экран тяжело выделить как сущность (как тот же PageObject), а вот действие выделить сильно проще. Во всяком случае, в нашей игре. Вступи в клан, купи робота, уничтожь робота, захвати маяк — из таких вот хелперов, как из кирпичиков, потом собираются тесты.
Суть хелпера ниже — уничтожение одного робота другим. Интересность его в том, что он раскидан на два девайса. То есть, он используется в тесте, который выполняется параллельно на двух устройствах, где один робот сражается с другим. Все по-честному, почти как черный ящик.

Это же касается и движка, в нашем случае — Unity. Мы в него всё равно стучимся, да и в клиент тоже стучимся — соответственно, такие вещи тоже прописываем. Конкретно в данном случае это хелпер, который может пройтись по иерархии отрисованных на сцене объектов и вытащить нужный нам объект по имени, спрятанный в иерархии, для взаимодействия с ним. А мы потом вольны с ним сделать все, что угодно: кликнуть по нему, вытащить из него текст, посмотреть заполнение, если это слайдер, к примеру.

Тестовые данные. Их тоже надо держать в тонусе и, желательно, где-нибудь в одном месте. Начиная с простых констант и заканчивая различными конструкциями, которые наполняются прочитанным балансом. Например, чтобы перейти в лигу, вам нужно начислить игроку в профиль 583 победы — и эта цифра у вас размазана по коду всех тестов, связанных с этой лигой. Не круто. Лучше все это собрать где-то в одном месте, назвать и использовать централизованно, чтобы потом не было вопросов.
А если, например, в какой-то момент изменится баланс — тогда можно будет все оперативно поменять в одном месте и не лазить по всем тестам с правками. Другой пример — сущности, которые оборачиваются в объекты, вроде тех же роботов, обладающие своими характеристикам. Их мы, читая баланс, можем наполнять данными и потом использовать в коде тестов для проверок. Такой подход позволяет контролировать и масштабировать данные без ущерба коду тестов.


Далее — кастомные ассерты. В какой-то момент у нас появилась потребность в ассертах, которые делают чуть больше, чем может стандартная библиотека ассертов NUnit’а. Например, на листинге ниже — ассерт, сравнивающий скриншоты. В нем спрятана логика, текст ошибки и все, что связано с этим действием.

Или, например, ассерт, проверяющий, сработал ли резист к урону на роботе. Точно так же, как и с примером со сравнением скриншотов, мы спрятали дополнительную логику расчета внутри ассерта. Такой ассерт весьма информативен, при этом исключает ненужное дублирование кода.

А теперь поговорим про эффективность тестов и то, как мы выжимаем из них максимум.
Повышаем эффективность тестов
Первый инструмент, который мы прикрутили для этого дела, — это так называемые списки блокирующих объектов. Это коллекция из объектов сцены, которую мы передаем в клиент при каждой команде, с которой мы обращаемся в рамках теста к клиенту. Например, всякие экраны переходов, при которых надо немного подождать. И в рамках теста, при появлении такого объекта на сцене, срабатывает следующая логика: «Ага, здесь появился вот этот fade-in экран с загрузкой, мне надо пару секунд подождать». Или это какие-то кликабельные вещи вроде поп-апов.
Например, в тесте разблокируется новый уровень — у вас появился поп-ап новой фичи. Для сценария теста он не нужен, его надо бы убрать, он мешает, блокирует экран. И вы просто не паритесь — тест кликнет по нему без необходимости указывать это в сценарии.

Либо это совсем фатальные вещи, когда, например, интернет отвалился или произошло еще что-то неприятное. Тогда мы просто сразу роняем тесты с результатом вида: «Ну сорян, появился один из фатальных объектов на сцене, тест упал».

В итоге списки блокирующих объектов позволяют реагировать на объекты, появляющиеся на сцене во время выполнения тестового сценария, но при этом не относящиеся к нему напрямую:
-
дождаться исчезновения объекта;
-
кликнуть на блокирующий объект;
-
выдать ошибку в случае критичного блокирующего элемента.
Следующий инструмент — кастомные перезапуски тестов.
В чем суть: это небольшая надстройка над стандартным атрибутом [Retry()] из NUnit’а. В нашем случае она позволяет в рамках идущего прогона тестов перезапустить конкретный падающий тест столько раз, сколько мы указали в настройках, либо пока он не пройдет.
Зачем это было сделано? Всякое случается: на девайсе или в офисе может подвести сеть, лагающий игровой сервер, да и сам девайс может тупить. Устройства перегреваются, начинают тротлить, не успевать в тайминги тестов. Ну и просто всякие софт-локи, которые тоже случаются — например, в рамках какой-нибудь механики, в основе которой заложен рандом: нужно выбить конкретную награду, которые выдаются случайно из указанного в балансе пула, и крутить такие вещи можно очень долго. Вместо этого лучше уронить тест после определенного количества попыток и попробовать снова. Но тут есть нюансы, и покрывать тестами рандомные механики — не очень правильное дело, лучше подготавливать их на уровне баланса.
Резюмируя, CustomRetry помогает нам в следующем :
● Позволяет перезапускать упавший тест n раз, пока он не пройдет или же признать его упавшим по истечении n попыток.
● Инструмент позволяет бороться с такими факторами, как:
○ проблемы окружения (например, нестабильная сеть);
○ проблемы с девайсами;
○ ожидаемые ситуации, приводящие к ожидаемой блокированию игры.
Что мы еще делаем?
В какой-то момент пришло понимание, что у нас скопилось очень много повторяющейся из теста в тест рутины, съедающей время. Тогда мы решили чуть-чуть забэкдорить и стучаться по API на игровой сервер напрямую, в обход клиента. Это позволило нам очень быстро собирать необходимое окружение в игре для проверки чего-то более конкретного.
Например, в бою вам нужно собрать робота с указанными пушками, с указанным пилотом указанного уровня. Если вы будете все это делать по-честному через интерфейс игры, то это займет прилично времени: пройтись по магазину роботов, по магазинам пушек, по магазину пилота, улучшить пилота. И это не говоря уже о том, что на пути к этому есть тысяча мест, где в этом сценарии можно споткнуться и уронить тест.
Как мы можем все это упростить? А можно просто прокинуть себе хэндлеры из клиента в фреймворк, которые отвечают например за покупку робота и делают это в обход клиента. Но в тоже время это честная покупка, которая требует соблюдения поставленных игрой предусловий, — нужный уровень игрока, нужное количество ресурсов — иначе сервер не позволит нам ее совершить. Другими словами, мы просто выкидываем рутину по перемещению в интерфейсе из процесса покупки.
А теперь наглядно: есть тест, проверяющий специальное умение робота, находящегося в самом конце списка роботов в магазине (а у нас их, на минуточку, больше 60). Если запустить этот сценарий с полноценной покупкой через интерфейс магазина, то на это уйдет примерно 5 минут 21 секунда; он просто идет в магазин и покупает робота в конце списка, при этом листая до него. А если же покупка робота будет совершена через API, то экономия по времени будет почти двукратная: 2 минуты 52 секунды
Время выполнения теста с покупкой робота через UI «по-честному»:

Время выполнения теста с покупкой робота через непосредственный запрос:

Таким образом, обращение из тестов по API к игровому серверу позволяет «мгновенно» выполнять ряд типовых предусловий и настраивать игровую среду для тестов:
-
покупка робота/обвесов/модулей;
-
покупка/назначение/прокачка пилотов;
-
получение указанного контента (в том числе указанного уровня).
Далее — сравнение скриншотов. Тема очень благодатная, для нас в свое время это стало самым полезным введением, так как визуальные баги стали вылавливаться просто на раз-два. Сравниваем мы то, что лежит в эталоне в файловом хранилище, с тем, что мы снимаем с экрана телефона в момент прохождения сценария — и получаем результат.
Все сделано максимально просто: мы сравниваем bitmap, а точнее — массив пикселей всего скриншота, снятого в момент прохождения с теста, с таким же массивом пикселей, взятых из эталона, и смотрим дельту по расхождению цвета каждого пикселя. Если дельта по цветам конкретного пикселя различается на пороговое значение, то подсвечиваем этот пиксель красным, тем самым показывая, что в этой области несоответствие.
Какие параметры мы можем крутить, чтобы сделать сравнение более комфортным? Как раз тот самый параметр по дельте цвета, иначе, если сделать его равным нулю, то будет несоответствие даже там, где человек глазом не увидит, что что-то поменялось, потому что там речь уже об оттенке оттенка, неразличимом на глаз.



Еще крутим параметр по количеству отличающихся пикселей. Иногда бывают моменты, когда мы точно знаем, что на экране в любом случае поменяется какой-то кусочек — например, никнейм у игрока, который генерируется каждый раз заново, когда мы перезапускаем игру с нуля. Там же не будет постоянно одно и то же имя, у нас сервер не разрешит так сделать, — поэтому можно задать, что такой-то процент пикселей от всего массива может отличаться, а все, что больше — уже ошибка. Также мы можем задать регион в рамках экрана по контуру нужного нам объекта. Это актуально для экранов, на которых вокруг много анимации и эффектов, а нам нужно сравнить конкретное окошечко или иконку.
Еще мы делаем видеозаписи с экранов девайсов во время прохождения тестового сценария. При этом в артефакты сохраняются только записи проваленных сценариев (если в настройках не указано иное, потому как при желании можно сохранять вообще все записи). Это позволяет оперативно открыть артефакты упавшего теста и посмотреть, что произошло на девайсе, почему сценарий упал, в какой момент и что отвалилось.
Помимо этого, такая фича позволяет отлаживаться на удаленных устройствах, подключенных к ферме. Иногда возникает потребность запустить тест на конкретном девайсе с фермы или взять, например, три девайса для отладки теста механики, рассчитанной на трех игроков. В некоторых ситуациях это позволяет проверять какие-то визуальные эффекты, как это было описано ранее.
Результаты очень важны
Результаты — это, наверное, самая важная вещь в принципе для тестирования, а для автоматизации — тем более. Дело в том, что автотесты без внятных результатов практически бесполезны. В чем смысл автоматизации, если для установления причины падения теста и получения нужных результатов, тест все равно нужно запускать руками? Вот что мы делаем в этом плане.
Собираем во время прохождения сценария вообще все, что можем себе позволить:
-
вообще все логи, до которых можем дотянуться (логи девайса, логи Unity, лог выполнения сценария);
-
дамп иерархии объектов сцены в момент падения теста;
-
дамп активных приложений на девайсе;
-
дамп с пингами;
-
скриншоты;
-
видеозаписи с экранов.
Все это собранное добро мы формируем в приятный и информативный Allure-отчет, уже ставший классическим решением для отчетности автотестов. Получаются следующие преимущества:
-
такой отчет удобно просматривать любому участнику процесса разработки;
-
легко определить, по какой причине упал тест;
-
все нужные (и не очень) артефакты собраны в одном месте и имеют строгую ассоциацию с тестами.

Такой отчет можно смело отдать даже тем участникам процесса разработки, которые не сильно знакомым с автотестами. Все, что нужно для определения причины и заведения бага, в отчете уже есть. Это помогает, например, разработчикам самостоятельно прогонять приемки своих веток и ознакамливаться с результатами этих прогонов.
В качестве заключения
Если подытожить все вышесказанное, то можно сделать вывод, что автоматизация тестирования — процесс непростой и требующий определенной подготовки. Подходит она далеко не всем, и это нормально. В конце концов, разработка ПО — это бизнес, а он про деньги и верные решения.
Если говорить про геймдев, то в этом разрезе все становится еще комплекснее: игровые механики достаточно сложно покрывать автотестами в силу специфики их природы, так как у некоторых механик попросту нет четких стейтов, по которым можно получить конкретный сравнимый результат, они больше про ощущения. На все это накладывается сумбурная разработка и рисковое прототипирование, на этапе которого вообще нет смысла внедрять автотесты.
Ну а если говорить про наш опыт, то все достаточно прозрачно и просто: проект созрел, он дорос до той точки, когда поддержка стала очень значимым процессом, в том числе и со стороны тестирования. При этом в процессе создания нашего фреймворка и написания тестов мы набили кучу самых разных шишек, реализовали множество любопытных решений, которыми я с радостью поделился с вами в рамках этой статьи.


