
В Instagram развернута одна из крупнейших в мире БД Apache Cassandra. Проект начал использовать Cassandra в 2012 году с целью замены Redis и поддержки внедрения таких функций приложения как система распознания мошенничества, Лента и Директ. Сначала кластеры Cassandra работали в среде AWS, но позже инженеры мигрировали их в инфраструктуру Facebook вместе со всеми остальными системами Instagram. Cassandra показала себя очень хорошо с точки зрения надежности и отказоустойчивости. В то же время метрики задержки при чтении данных явно можно было улучшить.
В прошлом году команда поддержки Cassandra в Instagram начала работать над проектом, направленным на существенное снижение задержки чтения данных в Cassandra, который инженеры назвали Rocksandra. В этом материале автор рассказывает, что сподвигло команду на реализацию этого проекта, сложности, которые пришлось преодолеть, и метрики производительности, которыми инженеры пользуются как во внутренней, так и во внешней облачных средах.
Основания для перехода
Instagram активно и широко использует Apache Cassandra в качестве сервиса хранения типа «ключ-значение». Большинство запросов Instagram происходят онлайн, поэтому для предоставления надежного и приятного пользовательского опыта для сотен миллионов пользователей Instagram, SLA очень требовательны к показателям работы системы.
Instagram придерживается показателя надежности «пять девяток». Это означает, что количество отказов в любой момент времени не может превышать 0.001%. В целях улучшения производительности инженеры активно наблюдают за пропускной способностью и задержками различных кластеров Cassandra, и следят за тем, чтобы 99% всех запросов укладывались в определенный показатель (задержка P99).
Ниже приведен график, демонстрирующий задержку на стороне клиентов одного для одного из боевых кластеров Cassandra. Голубым цветом обозначена средняя скорость чтения (5 мс), а оранжевым — скорость чтения для 99%, варьирующаяся в пределах 25-60 мс. Ее изменения сильно зависят от клиентского трафика.
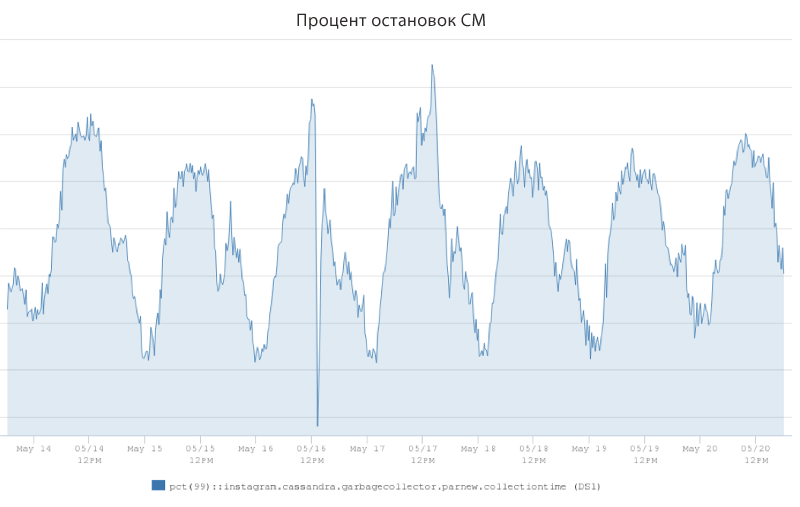

Исследование выявило, что резкие всплески задержки во многом обусловлены работой сборщика мусора JVM. Инженеры ввели метрику под названием «процент остановок СМ» для измерения процентного количества времени, которое уходило на «остановку мира» сервером Cassandra, и сопровождалось отказом в обслуживании запросов клиентов. Здесь же выше приведен график, показывающий количество времени (в процентах), которое уходило на остановки СМ на примере одного из боевых серверов Cassandra. Показатель варьировался в диапазоне от 1.25% в моменты самого малого трафика до 2.5% в моменты пиковой нагрузки.
График показывает, что этот инстанс сервера Cassandra мог тратить 2.5% рабочего времени на сбор мусора вместо обслуживания запросов клиентов. Профилактические операции сборщика, очевидно, оказывали значительное влияние на задержку P99, и потому стало ясно, что если нам удастся снизить показатель остановок CM, то инженеры смогли бы существенно снизить и показатель задержки P99.
Решение
Apache Cassandra — это написанная на Java распределенная база данных, с собственным движком хранения данных на основе LSM-деревьев. Инженеры обнаружили, что такие компоненты движка как таблица памяти, инструмент сжатия, пути чтения/записи, и некоторые другие создавали много объектов в динамической памяти Java, что приводило к тому, что JVM приходилось выполнять множество дополнительных служебных операций. Для снижения влияния механизмов хранения на работу сборщика мусора, команда поддержки рассмотрела различные подходы и в конечном счете решила разработать движок на C++, и заменить им существующий аналог.
Делать все с нуля инженеры не хотели, и поэтому решили взять за основу RocksDB.
RocksDB — это высокопроизводительная встраиваемая БД с открытым исходным кодом для хранения типа «ключ-значение». Она написана на C++, а в ее API есть официальные языковые привязки для C++, C, и Java. RocksDB оптимизирована для получения высокой производительности, особенно на быстрых накопителях, таких, как SSD. Она широко используется в отрасли в качестве движка хранения для MySQL, mongoDB, и других популярных БД.
Трудности
В процессе реализации нового движка хранения на RocksDB инженеры столкнулись с тремя сложными задачами и решили их.
Первая сложность заключалась в том, что в Cassandra все еще отсутствует архитектура, позволяющая подключить сторонние обработчики данных. Это значит, что работа существующего движка довольно тесно взаимосвязана с другими компонентами БД. Чтобы найти баланс между масштабным рефакторингом и быстрыми итерациями инженеры определили API нового движка, включая самые распространенные интерфейсы чтения, записи и потоков. Таким образом команда поддержки смогла реализовать новые механизмы обработки данных за API и вставить их в соответствующие пути выполнения кода внутри Cassandra.
Вторая сложность была в том, что Cassandra поддерживает структурированные типы данных и схемы таблиц, в то время как RocksDB предоставляет только интерфейсы типа ключ-значение. Инженеры тщательно определили алгоритмы кодирования и декодирования для поддержки модели данных Cassandra в рамках структур данных RocksDB и обеспечили преемственность семантики аналогичных запросов между двумя БД.
Третья сложность была связана с таким важным для любой распределенной БД компонентом, как работа с потоками данных. Всякий раз, при добавлении или удалении узла из кластера Cassandra, ей необходимо правильно распределять данные между различными узлами для балансировки нагрузки внутри кластера. Существующие реализации этих механизмов основывались на получении подробных данных от существующего движка БД. Поэтому инженерам пришлось отделить их друг от друга, создать слой абстракции и реализовать новый вариант обработки потоков с помощью API RocksDB. Для получения высокой пропускной способности потоков, команда поддержки теперь сначала распределяет данные по временным sst-файлам, а после использует специальный API RocksDB для «заглатывания» файлов, позволяющий производить их массовую одновременную загрузку в инстанс RocksDB.
Показатели производительности
Спустя почти год разработки и тестирования, инженеры завершили первую версию реализации и успешно «раскатали» ее на нескольких боевых Cassandra-кластерах Instagram. На одном из боевых кластеров, задержка P99 упала с 60 мс до 20 мс. Наблюдения также показали, что остановки СМ в этом кластере упали с 2.5% до 0.3%, то есть почти в 10 раз!
Инженеры также хотели проверить, сможет ли Rocksandra показать хорошие результаты в общедоступной облачной среде. Команда поддержки настроила кластер Cassandra в среде AWS с использованием трех i3.8 xlarge EC2 инстансов, каждый с 32-ядерным процессором, 244 Гбайт оперативной памяти, и нулевым рейдом из четырех NVMe флеш-накопителей.
Для сравнительных тестов воспользовались NDBench, и дефолтной для фреймворка схемой таблицы.
TABLE emp ( emp_uname text PRIMARY KEY, emp_dept text, emp_first text, emp_last text )Инженеры выполнили предварительную загрузку 250 млн 6 строк размером 6 Кбайт каждая (на каждом сервере хранится около 500 Гбайт данных). Далее настроили 128 читателей и писателей в NDBench.
Команда поддержки протестировала различные нагрузки и измерила средние/P99/P999 задержки на чтение и запись. На приведенных ниже графиках видно, что Rocksandra показала существенно более низкие и более стабильные показатели задержки на чтение и запись.


Инженеры также проверили нагрузку в режиме чтения без записи и обнаружили, что при одинаковой задержке P99 на чтение (2 мс), Rocksandra способна обеспечить более чем 10-кратное увеличение скорости чтения информации (300 К/c у Rocksandra против 30 К/с у C* 3.0).


Планы на будущее
Команда поддержки Instagram открыла код Rocksandra и фреймворка для оценки производительности. Вы можете скачать их с Github и попробовать в собственной среде. Обязательно расскажите, что из этого вышло!
В качестве следующего шага команда активно работает над добавлением более широкой поддержки функциональности C*, такой как вторичные индексы, починка и другое. А кроме того инженеры разрабатывают архитектуру подключаемого движка БД на C*, чтобы в дальнейшем передать эти наработки сообществу Apache Cassandra.

Источник


