Чем больше ядер, тем больше проблема распределения памяти между всеми ядрами при одновременной совместной работе. С увеличением числа ядер всё больше выгодно минимизировать потери времени на управлении ядрами при обработке данных — ибо скорость обмена данными отстает от скорости работы процессора и обработки данных в памяти. Можно физически обратиться к чужому быстрому кэшу, а можно к своему медленному, но сэкономить на времени передаче данных. Задача усложняется тем, что запрашиваемые программами объемы памяти не четко соответствуют объемам кэш-памяти каждого типа.
Физически разместить максимально близко к процессору можно только очень ограниченный объем памяти — кэш процесcора уровня L1, объем которого крайне незначителен. Даниэль Санчес (Daniel Sanchez), По-Ан Цай (Po-An Tsai) и Натан Бэкмен (Nathan Beckmann) — исследователи из лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института — научили компьютер конфигурировать разные виды своей памяти под гибко формируемую иерархию программ в реальном режиме времени. Новая система, названная Jenga, анализирует объемные потребности и частоту обращения программ к памяти и перераспределяет мощности каждого из 3 видов процессорного кэша в комбинациях обеспечивающих рост эффективности и экономии энергии.

Для начала исследователи протестировали рост производительности при комбинации статичной и динамической памяти в работе над программами для одноядерного процессора и получили первичную иерархию — когда какую комбинацию лучше применять. Из 2 видов памяти или из одного. Оценивались два параметра -задержка сигнала (латентность) и потребляемая энергия при работе каждой из программ. Примерно 40% программ стали работать хуже при комбинации видов памяти, остальные — лучше. Зафиксировав какие программы «любят» смешанное быстродействие, а какие — размер памяти, исследователи построили свою систему Jenga.
Они виртуально протестировали 4 виды программ на виртуальном компьютере с 36 ядрами. Тестировали программы:
- omnet — Objective Modular Network Testbed, библиотека моделирования C и платформа сетевых средств моделирования (синий цвет на рисунке)
- mcf — Meta Content Framework (красный цвет)
- astar — ПО для отображения виртуальной реальности (красный цвет)
- bzip2 — архиватор (фиолетовый цвет)
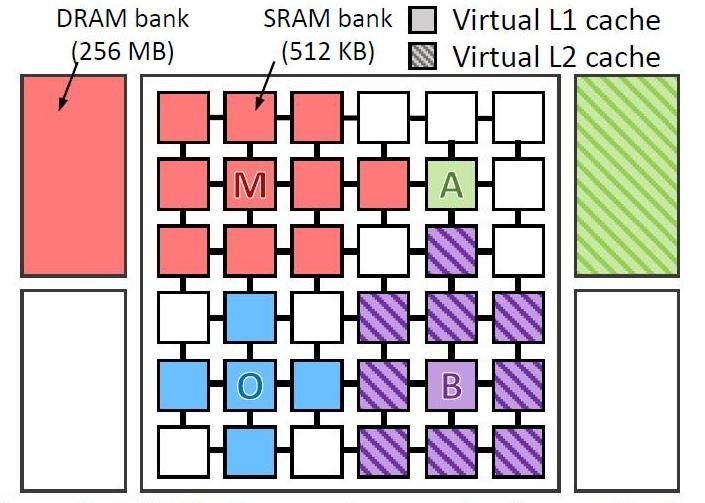
На картинке показано где и как обрабатывали данные каждой из программ. Буквы показывают, где выполняется каждое приложение (по одному на квадрант), цвета показывают, где находятся его данные, а штриховка указывает на второй уровень виртуальной иерархии, когда он присутствует.
С кэшем L1 взаимодействует кэш второго уровня — L2. Он является вторым по быстродействию. Обычно он расположен либо на кристалле, как и L1, либо в непосредственной близости от ядра, например, в процессорном картридже. В старых процессорах — набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования — при общем объёме кэша в 8 Мбайт на каждое ядро приходится по 2 Мбайта. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра. В задачах, связанных с многочисленными обращениями к ограниченной области памяти, например, СУБД, его полноценное использование дает рост производительность в десятки раз.
Кэш L3 обычно еще больше по размеру, хотя и несколько медленнее, чем L2 (за счет того, что шина между L2 и L3 более узкая, чем шина между L1 и L2). L3 обычно расположен отдельно от ядра ЦП, но может быть большим — более 32 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании. Применение кэша третьего уровня оправдано в очень узком круге задач и может не только не дать увеличения производительности, но наоборот и привести к общему снижению производительности системы.
Отключение кэша второго и третьего уровней наиболее полезно в математических задачах, когда объём данных меньше размера кэша. В этом случае, можно загрузить все данные сразу в кэш L1, а затем производить их обработку.
Периодически Jenga на уровне ОС реконфигурирует виртуальные иерархии для минимизации объемов обмена данных, учитывая ограниченность ресурсов и поведение приложений. Каждая реконфигурация состоит из четырех шагов.
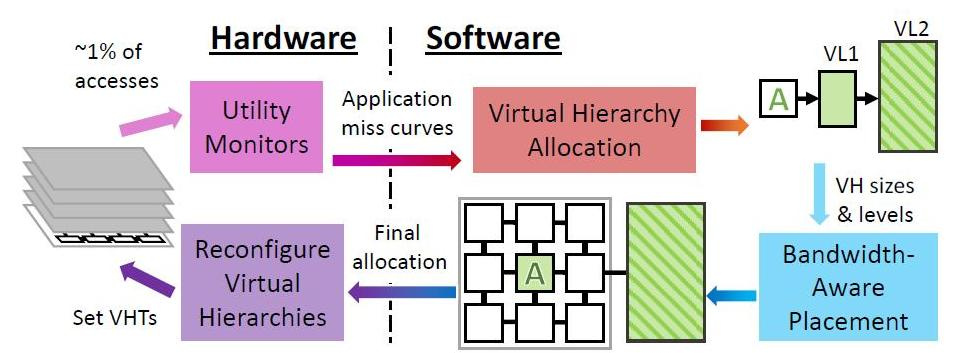
Jenga отправляет данные не только в зависимости от того, какие программы — любящие большую односкоростную память или любящие быстродействие смешанных кэшей, но и в зависимости от физической близости ячеек памяти к обрабатываемым данным. Независимо от того — какой вид кэша требует программа по умолчанию или по иерархии. Главное чтобы соблюсти минимизировать задержку сигнала и энергозатраты. В зависимости от того, сколько видов памяти «любит» программа, Jenga моделирует латентность каждой виртуальной иерархии с одним или двумя уровнями. Двухуровневые иерархии образуют поверхность, одноуровневую иерархию — кривую. Затем Jenga проектирует минимальную задержку в размерах VL1, что дает две кривые. Наконец, Jenga использует эти кривые для выбора лучшей иерархии (то есть размера VL1).
Применение Jenga дало ощутимый эффект. Виртуальный 36-ядерный чип стал работать на 30 процентов быстрее и использовал на 85 процентов меньше энергии. Конечно, пока Jenga — просто симуляция работающего компьютера и пройдет некоторое время, прежде чем вы увидите реальные примеры этого кеша и еще до того, как производители микросхем примут его, если понравится технология.
Конфигурация условной 36 ядерной машины
- Процессоры. 36 ядер, x86-64 ISA, 2.4 GHz, Silvermont-like OOO: 8B-wide
ifetch; 2-level bpred with 512×10-bit BHSRs + 1024×2-bit PHT, 2-way decode/issue/rename/commit, 32-entry IQ and ROB, 10-entry LQ, 16-entry SQ; 371 pJ/instruction, 163 mW/core static power - Кэши уровня L1. 32 KB, 8-way set-associative, split data and instruction caches,
3-cycle latency; 15/33 pJ per hit/miss - Служба предварительной выборки Prefetchers (Fig. 23 only). 16-entry stream prefetchers modeled after and validated against
Nehalem - Кэши уровня L2. 128 KB private per-core, 8-way set-associative, inclusive, 6-cycle latency; 46/93 pJ per hit/miss
- Когерентный режим (Coherence). 16-way, 6-cycle latency directory banks for Jenga; in-cache L3 directories for others
- Global NoC. 6×6 mesh, 128-bit flits and links, X-Y routing, 2-cycle pipelined routers, 1-cycle links; 63/71 pJ per router/link flit traversal, 12/4mW router/link static power
- Блоки статической памяти SRAM. 18 MB, one 512 KB bank per tile, 4-way 52-candidate zcache, 9-cycle bank latency, Vantage partitioning; 240/500 pJ per hit/miss, 28 mW/bank static power
- Многослойная динамическая память Stacked DRAM. 1152MB, one 128MB vault per 4 tiles, Alloy with MAP-I DDR3-3200 (1600MHz), 128-bit bus, 16 ranks, 8 banks/rank, 2 KB row buffer; 4.4/6.2 nJ per hit/miss, 88 mW/vault static power
- Основная память. 4 DDR3-1600 channels, 64-bit bus, 2 ranks/channel, 8 banks/rank, 8 KB row buffer; 20 nJ/access, 4W static power
- DRAM timings. tCAS=8, tRCD=8, tRTP=4, tRAS=24, tRP=8, tRRD=4, tWTR=4, tWR=8, tFAW=18 (все тайминги в tCK; stacked DRAM has half the tCK as main memory)
Источник

_large_large.jpg "Telegram в России работает со сбоями уже третью неделю подряд")
