
Скриншот-задание и выдача нейросети pix2code на собственном языке, который компилятор потом транслирует в код для нужной платформы (Android, iOS)
Новая программа pix2code (научная статья) призвана облегчить работу программистов, которые занимаются муторным делом — кодированием клиентского GUI.
Дизайнер обычно создаёт макеты интерфейса, а программист должен написать код для реализации этого дизайна. Такая работа отнимает драгоценное время, которое разработчик может потратить на более интересные и творческие задачи, то есть на реализацию настоящих функций и логики программы, а не GUI. Скоро генерацию кода можно будет переложить на плечи программы. Игрушечная демонстрация будущих возможностей машинного обучения — проект pix2code, который уже вышел на 1-е место в списке самых горячих репозиториев на GitHub, хотя автор ещё даже не выложил исходный код и наборы данных для обучения нейросети! Такой огромный интерес к этой теме.
Кодировать GUI скучно. Что ещё больше усугубляет ситуацию, это разные языки программирования на разных платформах. То есть нужно писать отдельный код для Android, отдельный для iOS, если программа должна работать нативно. Это отнимает ещё больше времени и заставляет выполнять однотипные, скучные задачи. Точнее, так было раньше. Программа pix2code генерирует код GUI для трёх основных платформ — Andriod, iOS и кроссплатформенный HTML/CSS — с точностью 77% (точность определяется на встроенном языке программы — сравнением сгенерированного кода с целевым/ожидаемым кодом для каждой платформы).

Автор программы Тони Белтрамелли (Tony Beltramelli) из датского стартапа UIzard Technologies называет это демонстрацией концепции. Он считает, что при масштабировании модель улучшит точность кодирования и потенциально способна избавить людей от необходимости вручную кодировать GUI.
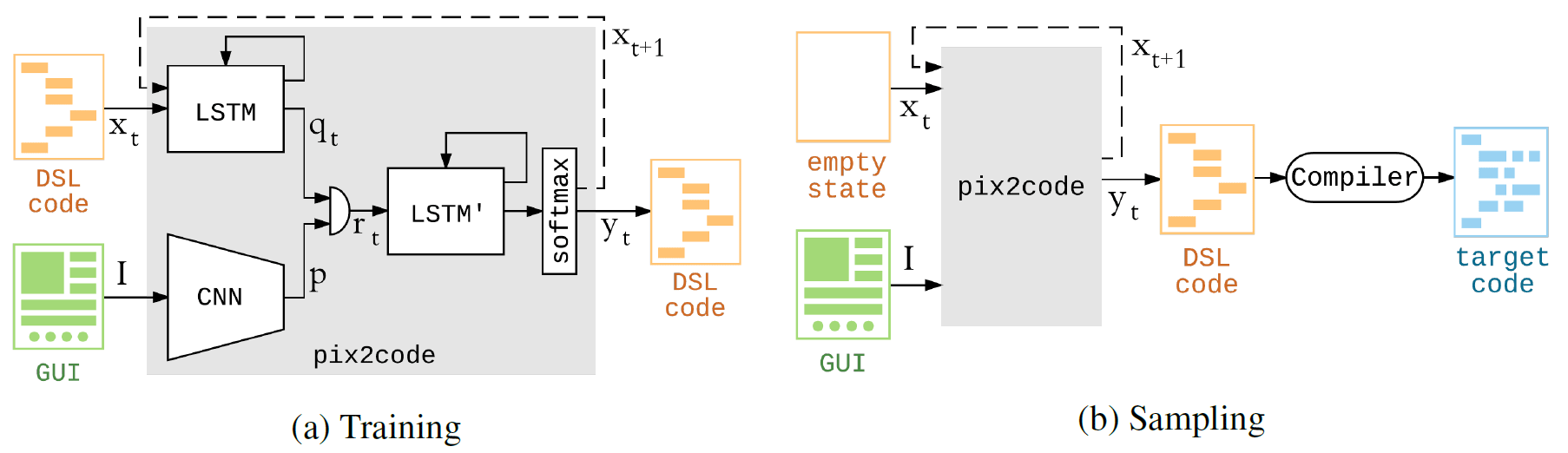
Программа pix2code построена на свёрточных и рекуррентных нейронных сетях. Обучение на Nvidia Tesla K80 GPU заняло чуть менее пяти часов — за это время система оптимизировала параметров для одного набора данных. Так что если вы хотите обучить её для трёх платформ, потребуется около 15-ти часов.
Модель способна генерировать код, принимая на входе только значения пикселей из одного скриншота. Другими словами, для нейросети не требуется специальный конвейер для выделения признаков и предварительной обработки входных данных.
Генерацию компьютерного кода по скриншоту можно сравнить с генерацией текстового описания по фотографии. Соответственно, архитектура модели pix2code состоит из трёх частей: 1) модуль компьютерного зрения для распознавания картинки, представленных там объектов, их расположения, формы и цвета (кнопки, подписи, контейнеры элементов); 2) языковой модуль для понимания текста (в данном случае, языка программирования) и генерации синтаксически и семантически корректных примеров; 3) использование двух предыдущих моделей для генерации текстовых описаний (кода) для распознанных объектов (элементов GUI).
Автор обращает внимание, что нейросеть можно обучить на другом наборе данных — и тогда она начнёт генерировать код на других языках для других платформ. Сам автор не планирует это делать, потому что расценивает pix2code как своеобразную игрушку, которая демонстрирует часть технологий, над которыми работает его стартап. Однако любой желающий сможет форкнуть проект и создать реализацию для других языков/платформ.
В научной работе Тони Белтрамелли написал, что опубликует наборы данных для обучения нейросети в открытом доступе в репозитории на GitHub. Репозиторий уже создан. Там в разделе FAQ автор уточняет, что выложит наборы данных после публикации (или отказа в публикации) его статьи на конференции NIPS 2017. Уведомление от организаторов конференции должно прийти в начале сентября, так что наборы данных появятся в репозитории в то же время. Там будут скриншоты GUI, соответствующий код на языке программы и выдача компилятора для трёх основных платформ.
Относительно исходного кода программы — его автор публиковать не обещал, но учитывая ошеломительный интерес к его разработке он принял решение открыть и его тоже. Это будет сделано одновременно с публикацией наборов данных.
Научная статья опубликована 22 мая 2017 года на сайте препринтов arXiv.org (arXiv:1705.07962).
Источник


