Этот метод производит самые точные измерения, которые только можно представить, записывая изменения тока у различных участков ДНК.

Помните сцену из фильма «Матрица», в которой Нео раскрывает всю свою силу, после чего мир предстаёт перед ним в виде бегущих в разные стороны строк кода? Что если бы вы видели окружающий мир таким образом, так что сидящий рядом человек был бы подобен веб-странице, на которую можно щёлкнуть правой кнопкой мыши и изучить элемент и исходный код под ним?
Мы ещё не достигли такого уровня, но недавние достижения в нанопоровом секвенировании, обусловленные разработками программного обеспечения с открытым исходным кодом, позволили существенно сократить время декодирования генома с 15 дней до трёх или даже меньше. Не так давно расшифровка занимала годы! Чтобы понять принцип, лежащий в основе метода, названного UNCALLED [GitHub], мы связались с профессором Майклом Шатцем — обладателем звания BDPs (Почётный профессор Блумберг, Bloomberg Distinguished Professorships) и доцентом кафедры компьютерных наук и биологии в Университете Джона Хопкинса.
Начнём с нанопорового секвенатора. Как рассказал Шатц, «идея его создания возникла ещё около 30 лет назад, и легенда гласит, что первая диаграмма была нарисована на салфетке». В реальности черновик изначального концепта для нанопорового секвенатора был сформирован доктором Дэвидом Димером в блокноте стенографиста шариковой ручкой с красными чернилами!

Представьте себе отверстие настолько крошечное, что в него за раз может пройти только одна-единственная нить ДНК. Протолкните через эту пору ваш генетический материал, и вы получите последовательности А, G, C, T (нуклеотиды аденин, гуанин, цитозин и тимин соответственно), составляющие человеческий геном. Итак, как различать между собой эти четыре строительных блока ДНК?

Как объяснил Шатц, «этот процесс включает самые тонкие измерения, которые только можно представить — измерение разницы в токе между различными участками ДНК. Это происходит на уровне пикоампер (пА, 10−12 А), и мы можем получать такие показания в режиме реального времени». Ещё пять лет назад оборудование, необходимое для этой работы, было доступно только серьёзным исследовательским учреждениям. Сегодня примерно за тысячу долларов вы можете приобрести нанопоровый секвенатор в качестве периферийного устройства, подключающегося к любому компьютеру через USB.
В данных, получаемых в результате секвенирования, обычно присутствует много шума. Но Шатц и его команда, вдохновившись моделью Маркова, разработали нечёткую логику (fuzzy logic) для декодирования каждого белка практически в режиме реального времени. «Это же практически как в “Звёздном пути”, не правда ли? — Рассказал Шатц. — Нуклеотиды проходят через это крошечное отверстие, и мы измеряем ток четыре тысячи раз в секунду». Программное обеспечение декодирует последовательности в режиме реального времени, благодаря чему их можно соотнести с различными маркерами. Например, вы можете определить патогенную бактерию или ген, ассоциированный с раком. Что более важно — вы можете игнорировать ненужные на данный момент фрагменты ДНК.
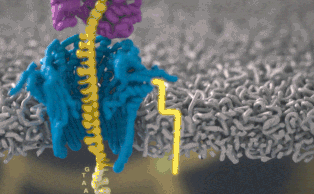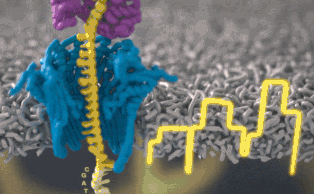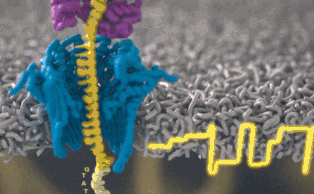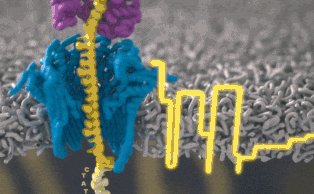
Каждый участок ДНК, проходящий через это крошечное отверстие, представляет собой заряженную молекулу. Софт позволяет пользователю обращать напряжение у каждой такой молекулы, что приводит к её выталкиванию из нанопоры. Именно возможность выборочно секвенировать только те участки, что имеют отношение к научной работе, позволяют добиться значительного повышения скорости секвенирования. Как говорит Шатц: «Существуют API call для выбора молекул, с которыми вы хотите работать. Поразительно, что это вообще возможно».
Обработка «языка жизни»
Каждый фрагмент ДНК возвращает показатели напряжения в зависимости от нуклеотидов. Итак, когда вы получаете напряжение, насколько сложен поисковой запрос? Это не простая таблица, а скорее некое очень нечёткое логическое соответствие. «В электрических данных, которые вам могут понадобиться, требуется, чтобы у нуклеотидов А были одни показатели тока, у С — другие, и так далее, — сказал Шатц. — Но у вас их вообще нет».На самом деле электрический ток связан с несколькими нуклеотидами подряд. Около шести ближайших к считыванию нуклеотидов — самые влиятельные. Прохождение цепочки ДНК через нанопору можно представить как протягивание цепи через трещёточный механизм, по звукам которого можно понять, что через него проходит. «Таким образом, вы на самом деле считываете один и тот же нуклеотид примерно шесть раз в различных контекстах в окружении шести других нуклеотидов». Показатели тока становятся очень шумными. Для каждого измерения тока могут быть сотни последовательностей нуклеотидов, которые он может представлять.
Представьте себе, что каждая комбинация этих шести нуклеотидов обладает смещением. На смещении один имеется сотня возможных последовательностей нуклеотидов, на смещении 2 — ещё одна сотня, на третьем и четвёртом также ещё по сотне последовательностей. «Но это та самая комбинация перекрывающихся последовательностей, в случае с которой вы можете надеяться на решение задачи с конкретными нуклеотидами — ведь вы знаете, что последовательности перекрываются». Например, GATTACA при смещении один может следовать за ATTACAT при смещении два, но не TTTACAT, AATACAT, или любая другая последовательность, начинающаяся не с ATTACA.
Система декодирования использует логику, похожую на обработку естественного языка, чтобы сопоставить шумный электрический сигнал с последовательностями нуклеотидов.
Как только вы получите последовательность нуклеотидов, вам нужно будет обработать текст, чтобы решить, из какой части генома происходит эта молекула. Как говорит Шатц, «основная часть этой технологии была изобретена для систем хранения баз данных ещё 30 лет назад. Существует действительно мощный алгоритм, называемый Преобразование Барроуза — Уилера, который и в наши дни занимает центральное место в геномике».
Нанопоровый секвенатор очень дешёв по сравнению с лабораторными инструментами, используемыми несколько лет назад. Но для секвенирования требуется одноразовый картридж — так называемая проточная ячейка, чья стоимость может увеличиваться при необходимости просмотреть более объёмные последовательности. «Программное обеспечение полезно тем, что вместо сканирования всего генома мы можем действительно точно знать, какую молекулу мы собираемся помещать в наше секвенирование, — сказал Шатц. — Мы можем вытаскивать и выбирать в режиме реального времени, какие молекулы будут полностью считываться, а какие — отбрасываться примерно через секунду секвенирования».

Так, например, если бы вы планировали определить, является ли индивид носителем гена, известного своей связью с раком (например, BRCA1, ассоциированный с раком груди), вы бы взяли образец. Если бы вы хотели обработать весь материал методом нанопорового секвенирования, это был бы очень медленный и дорогостоящий процесс. Все молекулы смешиваются в пробирке, и вы упорядочиваете их по одной за раз, когда они в случайном порядке извлекаются из этой пробирки. Однако новое программное обеспечение из лаборатории Шатца, названное UNCALLED, может практически в реальном времени оценить, стоит изучать последовательность или нет.
Фактически, во время обычного секвенирования, вы захотите секвенировать геном более одного раза, поскольку любой взятый вами образец содержит случайный набор молекул ДНК и может не содержать тех частей, которые вас больше всего интересуют. Имея возможность выбирать, вы можете быстрее отделить то, что вы ищете, и избежать многократного повторения секвенирования в других областях.
Или, например, возьмём пример с инфекционным заболеванием, которое в наши дни у всех на уме. Из-за необходимости в проведении тестирования лаборатории по всему миру сталкиваются с огромными рабочими нагрузками. «В этом смысле человеческий геном невероятно скучный. Это не то, что вы в действительности ищете», — сказал Шатц. С UNCALLED нанопоры будут отсеивать весь явно человеческий материал. «Всё, что не совпадает с человеческим геномом, мы вернём и попробуем сохранить, чтобы провести анализ в режиме реального времени и определить, что это такое».
Открытый доступ к нашему исходному коду
Когда Шатц впервые попал в мир геномики, эта сфера имела крайне плохую репутацию из-за закрытости и проприетарности. «В самом начале было много попыток запатентовать гены. Например, было несколько громких случаев, касающихся генов, ассоциированных с раком груди. Предпринимались попытки запатентовать эти последовательности и получать очень большие деньги с того, что сейчас доступно в ходе обычного анализа».
Как говорит Шатц, к счастью, за последние годы эта тенденция изменилась в лучшую сторону. «За последние 20 лет произошло несколько скачков в развитии технологий, поэтому есть ощущение крайней необходимости. Несмотря на то, что все эти секвенаторы просто записывают нуклеотидные последовательности, каждая платформа обладает различными свойствами и характеристиками, а также ошибками, связанными с ней. Поэтому существует реальная потребность в разработке программного обеспечения, которое может преодолеть эти различия и наилучшим образом использовать данные с разных платформ».
Почему бы не сделать программное обеспечение проприетарным продуктом? Что ж, скорость здесь играет ключевое значение. «Если вы попробуете коммерциализировать это, то для создания компании потребуется некоторое время, настолько много, что к тому моменту, как вы перейдете к работе над продуктом, уже появится следующий. В этой сфере такая гонка, что в долгосрочной перспективе коммерциализировать программное обеспечение очень сложно, указал Шатц. — Кроме того, наша работа в основном финансируется за счёт государственных грантов, поэтому это [бесплатное распространение софта] — один из наших способов вернуть долг обществу».
Текущий климат намного здоровее и доброжелательнее для таких учёных, как Шатц, планирующих продолжать распространять в открытом доступе созданное в его лаборатории программное обеспечение. «Мы получаем так много пользы от возможности делиться кодом и работать сообща. Практически во всех случаях реальные плюсы перевешивают потенциальные минусы».


