
Эта статья из серии постов на тему демистификации ИИ, в которых предпринимаются пытытки устранить двусмысленность жаргона и разоблачить мифы связанные с технологиями ИИ.
ChatGPT и другие большие языковые модели (LLM, в дальнейшем БЯМ, короче ЯМ — прим. переводчика) доказали свою полезность для задач отличных от генерации текста. Однако в некоторых областях их эффективность вызывает вопросы. Одной из таких областей является математика, где ЯМ иногда могут предоставить правильные решения для достаточно сложных задачах, в то же время потерпеть неудачу в тривиальных.
Существует немало исследований в которых изучаются возможности и ограничения ЯМ в математике. Недавняя работа проведенная исследователями из нескольких университетов показала, что возможности ChatGPT ниже уровня среднего аспирантов по математике. И отдельное исследование, проведенное профессором Нью-Йоркского университета Эрнестом Дэвисом показало, что ЯМ терпят неудачу при решении весьма простых математических задач заданных на естественном языке.
Эти исследования помогают лучше понять разрыв в решении проблем людьми и глубокими нейронными сетями. Люди и ЯМ могут достигать одного и того же результата в определенных математических задачах, но их методы различаются. И это может оказаться критичным, когда речь заходит о доверии к ЯМ (и другим моделям глубокого обучения) при решении задач требующих планирования и рассуждений.
ChatGPT на поле брани с продвинутой математикой
Математика используется во многих областях науки, включая инженерных и социальных. Специалисты не математики, работающие в этих областях, могут обратиться к ChatGPT, чтобы получить ответы на математические вопросы.
“Поскольку ChatGPT всегда формулирует свои ответы с высокой степенью уверенности, у этой группы людей могут возникнуть трудности с различением правильных ответов от неправильных математических рассуждений, что может привести к принятию неверных решений в дальнейшем”, — заявил в интервью TechTalks Саймон Фридер, исследователь машинного обучения из Оксфорда. “Поэтому важно информировать эти группы об ограничениях ChatGPT, чтобы не возникало чрезмерного доверия к результатам его использования”.
Фридер является соавтором свежей статьи в которой исследуется способность ChatGPT имитировать навыки необходимые для занятия профессиональной математикой. Авторы собрали выборку данных GHOSTS состоящей из задач из различных областей, включая ответы на вычислительные задания, завершения математических доказательств, решения задач математических олимпиад, и поиска в математической литературе.
Задачи были взяты из нескольких источников, включая учебники для выпускников, других математические выборок данных и корпусов знаний.
Их результаты показывают, что ChatGPT выполнил многие задания на проходной балл. Например, что касается вопросов для аспирантов, исследователи отметили, что чат “никогда не показывал не понимания вопроса” (хотя можно поспорить о применимости термина “понимание” к ЯМ), но выдавал ошибочные ответы. Фридер считает, что ChatGPT особенно заметно терпит неудачи в задачах, которые “требуют изобретательных доказательств”, таких как на олимпиадах.
Чат также продемонстрировал очень плохие вычислительные способности. “Даже вычисление простых интегралов (первообразных) может быть затруднено, поскольку ChatGPT часто правильно находя функцию для первообразной упускал константу интегрирования”, — сказал Фридер.
Одним из интересных выводов сделанных в статье является несоответствие между различными уровнями решения проблем. Например, в задачах с дырами в доказательствах (нашел статью на эту тему — прим. переводчика) исследователи обнаружили, что ChatGPT часто “с легкостью выполняет сложные символьные задач”», но во многих случаях не справляется с базовой арифметикой или перестановкой выражений.
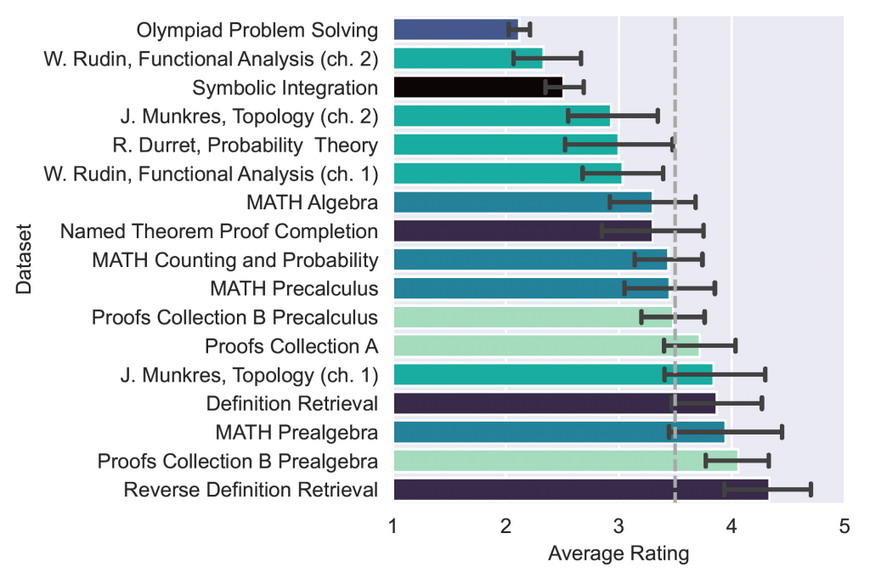
Средний рейтинг для каждого набора данных (одинаковые цвета указывают на то, что файлы взяты из одного и того же набора данных). Поскольку максимальный рейтинг равен 5, а минимальный при котором вопрос был хотя бы понят равен 2, проходной балл (50% баллов) будет равен 3,5, как указано пунктирной линией. Столбики ошибок представляют 95% доверительные интервалы. Источник — Figure 2.
“Нет области математики, в которой вы могли бы полностью доверять выводам ChatGPT (это справедливо и за пределами математики, из-за стохастической природы языковых моделей)”, — сказал Фридер. “Это общее ограничение языковых моделей заключающееся в том, что не существует строгих подходов гарантирующих корректность вывода, от чего также страдает ChatGPT”.
Одной из проблем этого чата является его уверенность в ответах, даже когда он терпит неудачу и использует ошибочную логику. Это очень затрудняет его использование в качестве надежного источника математических знаний.
“Кажется справедливым сказать, что ChatGPT непоследовательно плох в продвинутой математике: в то время как его рейтинги падают с математической сложностью вопроса, в нескольких случаях он действительно дает проницательные доказательства”, — пишут исследователи.
А как он справляется с элементарной математикой?
В другой недавней статье Эрнест Дэвис исследует возможности и ограничения ЯМ в решении таких задач, как эта: “У Джорджа есть семь пенни, десятицентовик и три четвертака. У Харриет есть четыре пенни и четыре четвертака. Сначала Джордж дает Гарриет тридцать один цент мелочью; затем Гарриет возвращает ему ровно половину своих пенни. Сколько денег сейчас у Джорджа?”
Это простые задачи с тремя свойствами: они требуют элементарных математических навыков, сформулированы на естественном языке и предполагают понимание здравого смысла.
Дэвис тестировал три различных подхода. В первом ЯМ просили напрямую выдать ответ. Второй подход заключался в том, чтобы модель генерировала программу, которая решает задачу. И третий — выводила формализованное представление, которое можно было ввести в систему автоматической проверки теорем. ЯМ плохо работали во всех трех подходах, хотя результаты были несколько лучше, когда их просили сгенерировать программу, которая может решить задачу.
Итак, если ЯМ не могут выполнять задания из элементарной математики, почему они демонстрируют замечательные результаты в тестах, разработанных для оценки математических навыков ИИ?
ЯМ добились заметного прогресса в лингвистике, в меньшей степени в здравом смысле и математике. Но, как указывает Дэвис в своей статье, ЯМ плохо умеют сочетать несколько навыков. Например, они в целом “гораздо хуже справляются с задачами, включающими две арифметические операции, чем с теми, которые требуют одной, как в задачах со словами, так и в чисто числовых”.
Одно из важных замечаний Дэвиса заключается в том, что математические критерии разработанные для оценки систем ИИ взяты из тестов созданных для людей. Это может приводить к вводящим в заблуждение выводам. У людей базовые навыки становятся фундаментом на котором мы развиваем более продвинутые. Так, например, если человек может решать дифференциальные уравнения можно ожидать, что он будет не плохо ориентироваться в линейной алгебре.
Но модели машинного обучения, такие как ЯМ, иногда могут находить ответы на сложные проблемы не приобретая тех же навыков, что и люди. Это может быть связано с тем, что ответы находятся непосредственно в обучающих данных (особенно когда модель обучается на очень большом корпусе данных). Или, что модели обнаруживают закономерности, которые могут приводить к правильным ответам во многих случаях, но не всегда.
“[ЯМ] не могут надежно охватить ни одну область математики или какой-либо ее продвинутый раздел”, — сказал Дэвис TechTalks. В то же время “Вероятно, нет такой области математики, в которой вы никогда не получите правильного ответа, потому что иногда они могут выдать ответы, которые были в обучающей выборке”.
Интересно, что Дэвис находит некоторые из тех же видов несоответствий, которые были отмечены и в предыдущей работе. Например, в то время как ChatGPT часто решает базовые и промежуточные математические задачи, иногда он терпит неудачу в очень простых задачах, таких как простой подсчет (возможно это связано с вероятностным выбором механизма сэмплирования модели, см. объяснение в этом переводе с примерами кода; поэтому при повторном запуске задачи в новой сессии возможно получение правильного ответа — прим. переводчика).
“Мое собственное ощущение таково, что если ЯМ не может решать простые арифметические задачи, то на самом деле нет особого смысла спрашивать насколько хорошо она справляется с задачами по теории мер, топологии или абстрактной линейной алгебре”, — сказал Дэвис.
В поиске математических знаний
В тестах, которые провели Фридер и его коллеги, в которых ChatGPT показал особенно хорошие результаты были поиск текста по определению и обратный поиск определений по тексту запроса. По сути, он может служить очень хорошей поисковой системой для получения математических знаний, предоставляя описание тем и сопоставляя описание с основной концепцией.
“[ChatGPT] особенно хорошо работает в качестве математической базы знаний: его можно использовать для эмуляции математической поисковой системы и для получения различных фактов о более сложных объектах”, — сказал Фридер. “Например, я сам узнал о представлении, которое называется ‘расплывчатой топологией’, входящем в более общее представление о слабой топологии. Сначала выбор слова показался странным, и я подумал, что это галлюцинация чата, пока не поискал в Интернете и не узнал из Википедии, что ”расплывчатая топология» — правильное название для конкретного математического объекта.»
Дэвис соглашается с тем, что ChatGPT и другие ЯМ могут быть хороши в подборе текста, что также наблюдается в других областях, таких как стандартизированные научные тесты. Но он также отметил, что еще предстоит выяснить насколько они сравнимы на практике с подобными возможностями Wikipedia и Mathworld, особенно поиске определений и обратном поиске определений.
Для обратного поиска определений необходимо проверить насколько устойчива их система к переформулировкам определений из стандартного учебника, как сохраняющим смысл, где они должны быть успешными, так и изменяющим смысл, где они, предположительно, не должна быть успешными, и в идеале должны выдавать какое-то предупреждение”, — сказал Дэвис.
Точно настроенные ЯМ
В своей статье Фридер и его коллеги обнаружили, что модели глубокого обучения, разработанные для решения математических задач или ЯМ настроенные на больших математических выборках данных, гораздо более точны, чем ChatGPT.
Одна из выдающихся работ — это модель глубокого обучения, разработанная исследователями ИИ Facebook Гийомом Ламплом и Франсуа Шартоном в 2019 году. Они создали систему для генерации обучающих наборов данных для контролируемого обучения интегрированию и дифференциальным уравнениям первого и второго порядка. Затем они обучили трансформаторную модель на этой выборке данных. Результаты их тестирования показали, что эта модель работает лучше, чем программы алгебры на основе правил, такие как MATLAB и Mathematica.
Вторая модель — Minerva, большая языковая модель от Google, предварительно обученная на общих данных естественного языка и доработанная на данных устных математических задач, конкурсных математических заданиях, а также задачах из разных областей науки и техники. Как и ожидалось обе модели превзошли ChatGPT в решении математических задач.
«Тонкая настройка на большем математическом наборе данных, вероятно, увеличила производительность», — сказал Фридер.
Дэвис также согласился с тем, что точно настроенные трансформаторы, подобные разработанному Лэмплом и Чартоном, могут “иногда находить решения проблем, которые отсутствуют в стандартных системах, таких как Mathematica”. Но он отметил, что “те проблемы, которые смогли решить эти системы, почти никогда не представляли действительного математического интереса”. “Это может измениться”, — добавил он.
Дэвис также отметил, что было несколько реальных случаев, когда системы ИИ были полезны математикам, включая систему глубокого обучения, которая обнаружила быстрые алгоритмы умножения матриц, и несколько систем, которые смогли помочь в теории графов. “Но такого рода помощь в значительной степени случайна”, — добавил он.
В перспективе предстоит еще много работы
В этой области еще много возможностей для открытий. При более точной настройке эти системы однажды могут стать надежными помощниками для людей не имеющих высшего образования в области математики. Но пока стоимость оценки результативности математических выводов ЯМ непомерно высока.
Фридер и его коллеги открыли исходный код своего набора данных и фреймворка, который включает подробную систему оценки выходных данных модели и достоверности, коды ошибок и предупреждений, а также комментарии рецензентов. Процесс сбора и анализа данных потребовал ручной работы экспертов и не мог быть передан на аутсорсинг через такие платформы, как Amazon Mechanical Turk. Сделав его общедоступным они хотят “побудить сообщество вносить свой вклад и расширять эти наборы данных, чтобы их можно было использовать в качестве полезного ориентира для других ЯМ”, как пишут сами исследователи.
Фридер и его соавторы также работают над новой статьей, в которой будут представлены результаты исследования возможности автоматического выполнения математики исключительно с помощью ЯМ. “Это даст эмпирический ответ на старый вопрос о том, нужно ли формализовать математику или нет, чтобы выполнять автоматические доказательства теорем”, — сказал он.


