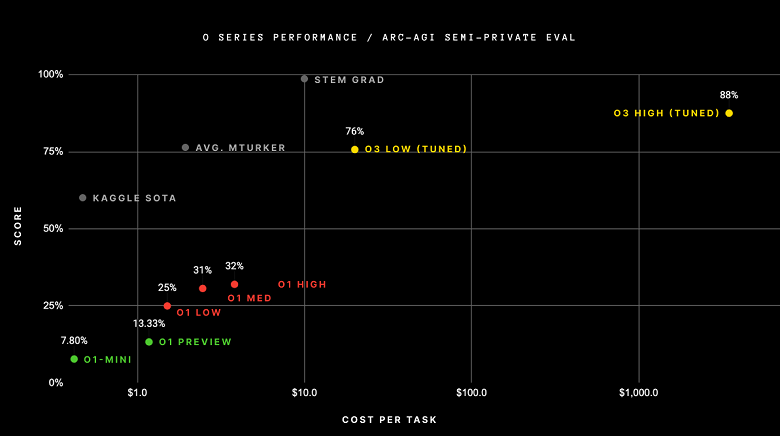
Новейшая разработка OpenAI, модель o3, добилась значительного успеха, показав результат в 75,7% в сложных испытаниях ARC-AGI в условиях стандартных вычислений и 87,5% в высокопроизводительном режиме. Этот результат стал неожиданностью для сообщества исследователей искусственного интеллекта, так как тест ARC-AGI основан на корпусе Abstract Reasoning Corpus, который оценивает способность ИИ решать новые задачи и демонстрировать «гибкость интеллекта». Тест ARC представляет собой набор визуальных загадок, требующих понимания основных концепций, таких как объекты, границы и пространственные отношения. Хотя люди способны легко справляться с этими задачами, современным системам ИИ это даётся с трудом. ARC уже долгое время считается одним из самых сложных испытаний для оценки ИИ.
Тест ARC-AGI содержит как публичные тренировочные и оценочные наборы данных, так и приватные и частично открытые тестовые наборы, доступ к которым ограничен. Это позволяет избежать воздействия на системы ИИ путём обучения на множестве примеров для охвата всех возможных комбинаций загадок. Кроме того, соревнование ограничивает объём вычислений, доступный участникам, чтобы исключить применение метода «грубой силы» для решений.

Ранее модели o1-preview и o1 достигали 32% в тесте ARC-AGI. Другой подход, который разработал исследователь Джереми Берман, включал использование гибридной методики, объединяющей Claude 3.5 Sonnet с генетическими алгоритмами и интерпретатором кода, что привело к результату в 53%, который был наивысшим до появления o3.
Франсуа Шолле, создатель ARC, охарактеризовал достижения модели o3 как «поразительный и значимый прорыв в области ИИ, демонстрирующий способность к освоению новых вызовов, не наблюдавшуюся ранее в моделях семейства GPT». Он также подчеркнул, что увеличение вычислительных мощностей на предыдущих поколениях моделей не давало аналогичных достижений.
Тем не менее, успех o3 в тесте ARC-AGI достигается значительными затратами. В конфигурации с невысокой производительностью модель расходует от $17 до $20 и 33 миллиона токенов на каждую задачу, в то время как в высокопроизводительном варианте количество вычислительных ресурсов увеличивается в 172 раза, а количество токенов доходит до миллиардов на каждую загадку.
Шолле и другие учёные считают, что ключом к решению новых задач является «синтез программ». По их мнению, «мыслящая» система должна быть способна разрабатывать модули для решения узких проблем и последовательно объединять их для решения более сложных задач. Традиционные языковые модели усвоили множество знаний, хранят обширные внутренние программы, однако у них отсутствует способность к креативному сочетанию этих составляющих, что ограничивает их в решении задач, выходящих за рамки тренировочного набора.

Однако информации о деталях работы o3 имеется немного, и на этот счёт мнения учёных расходятся. Шолле предполагает, что o3 использует тип программного синтеза, который применяет механизмы рассуждения с последовательным процессом (CoT) и поисковую механику в паре с моделью вознаграждения, оценивающей и совершенствующей решения по мере генерации токенов. Этот подход похож на исследования открытых моделей рассуждений, проводившиеся в последние месяцы.
С другой стороны, некоторые исследователи, такие как Натан Ламберт из Института искусственного интеллекта Аллена, полагают, что «o1 и o3 могут представлять собой лишь прямое использование одной языковой модели». В день объявления о о3 Нат МакАлис из OpenAI заявил в X, что o1 был «просто LLM, обученной с усилением через обучение RL. o3 раздвигает границы RL, превышая возможности o1».
Тогда же Денни Чжоу из команды по решению проблем Google DeepMind заявил, что комбинация поисковых и современных подходов к RL «зашла в тупик». «Уникальность в рассуждениях LLM заключается в том, что их процесс мышления генерируется авторегрессивно, а не за счёт поиска (например, mcts) в пространстве генерации, даже если применяется тщательно разработанная подсказка или оптимизированная модель», — написал он в X.
Подробности о функционировании o3 могут казаться второстепенными на фоне прорыва в ARC-AGI, однако они серьёзно повлияют на дальнейшее развитие методик обучения моделей LLM. Обсуждается возможность, что законы масштабирования LLM, завязанные на обучение данным и вычислениям, достигли своего предела. Вопрос о том, основывается ли тестовое масштабирование на продвинутых тренировочных данных или на иных архитектурах вывода, способен определять следующий этап в их эволюции.
Название ARC-AGI может ввести в заблуждение, некоторые считают его эквивалентом решения AGI. Однако Шолле подчёркивает, что «ARC-AGI — это не критерий для AGI. Пройти ARC-AGI вовсе не означает достижения AGI, и я полагаю, что o3 ещё не является AGI. o3 сталкивается с трудностями при решении элементарных задач, что указывает на принципиальные отличия от человеческого интеллекта».
К тому же он указывает, что o3 не может самостоятельно изучать некоторые навыки и нуждается в участии внешних специалистов во время этапов вывода и обучения.
Другие исследователи подчёркивают недостатки достигнутых результатов. Например, модель была специально обучена на тренировочном наборе ARC для достижения высоких показателей. «Моделям не требуется обширная настройка, ни в самом домене, ни для решения конкретных задач», — отмечает учёный Мелани Митчелл.
Для проверки наличия у моделей способностей к той степени абстракции и анализа, для которых предназначен тест ARC, Митчелл предлагает «проверить, могут ли эти системы адаптироваться к различным версиям конкретных задач или задачам анализа, использующим те же концепции, но осуществляемым в других сферах, кроме ARC».
Шолле и его команда работают над разработкой нового тестирования, которое станет вызовом для o3, возможно, снижая её оценки до менее 30%, даже при больших вычислительных ресурсах. Люди, по предположению, смогут решить до 95% головоломок без всякого обучения.
Источник: iXBT


