
Всем привет, меня зовут Виктор Щепкин, я работаю Team Lead’ом в Allods Team, которая входит в состав MY.GAMES и уже насчитывает целых 14 студий. В этом тексте я расскажу про особенности работы с Unreal Engine, а также подробно опишу, какие решения и процессы мы используем при разработке проектов:
-
как мы используем Unreal Engine Modules и Plugins;
-
cross-sharing технических решений;
-
про стандартизацию и валидацию данных;
-
и многое другое.
Отдельно хочу отметить cross-sharing технических решений. Сейчас в Allods Team ведется активная разработка нескольких проектов на Unreal Engine, поэтому мы всегда заинтересованы в том, чтобы не только обмениваться опытом, но и делиться конкретными техническими решениями, которые появились в ходе работы над проектами. Это значительно упрощает процесс самой разработки и экономит ресурсы.
Все, что я расскажу ниже — это исключительно наш личный опыт, а когда речь идет о личном опыте, то всегда можно найти, что можно улучшить или с чем-то поспорить. Поэтому не стесняйтесь писать свои мысли и предложения в комментариях, я с радостью почитаю про вашу практику, а также отвечу на ваши вопросы.
Unreal Engine Modules и Plugins
Мы считаем, что при работе с Unreal Engine можно и нужно придерживаться модульности: вместо того, чтобы проект состоял только лишь из одного основного модуля, мы стремимся использовать множество независимых системных модулей — это позволяет формировать наши проекты по принципу конструктора, состоящего из системных модулей, что помогает нам легко переносить целые фичи из проекта в проект.
Чтобы достичь модульности, мы используем возможности, которые нам предоставляет Unreal Engine:
-
Unreal Engine Modules — коллекции классов, которые могут входить в состав как проекта, так и плагинов. При этом важно учитывать, что реализация Unreal Engine Module может быть только на C++, поэтому если мы хотим вынести какой-либо блюпринт как некую часть модуля, то для этого мы создаем отдельный плагин.

Unreal Engine Modules мы используем в случаях, когда вся логика может храниться в одном модуле. Например, наш Character Stats System Module представляет собой базовый набор атрибутов GAS’a, компонентов для работы с ними, а также набор вспомогательных функций, который мы используем при реализации базового представления персонажа, его характеристик и боевой системы.
Важно учитывать, что Unreal Engine Modules, которые мы разрабатываем и которые находятся в проекте, могут зависеть только от движка и от плагинов, но ни в коем случае не друг от друга! Такие зависимые вещи должны находиться в Unreal Engine Module самого проекта.
-
Plugins — коллекции кода (в виде Unreal Engine Modules или Blueprints) и/или данных (ассетов).
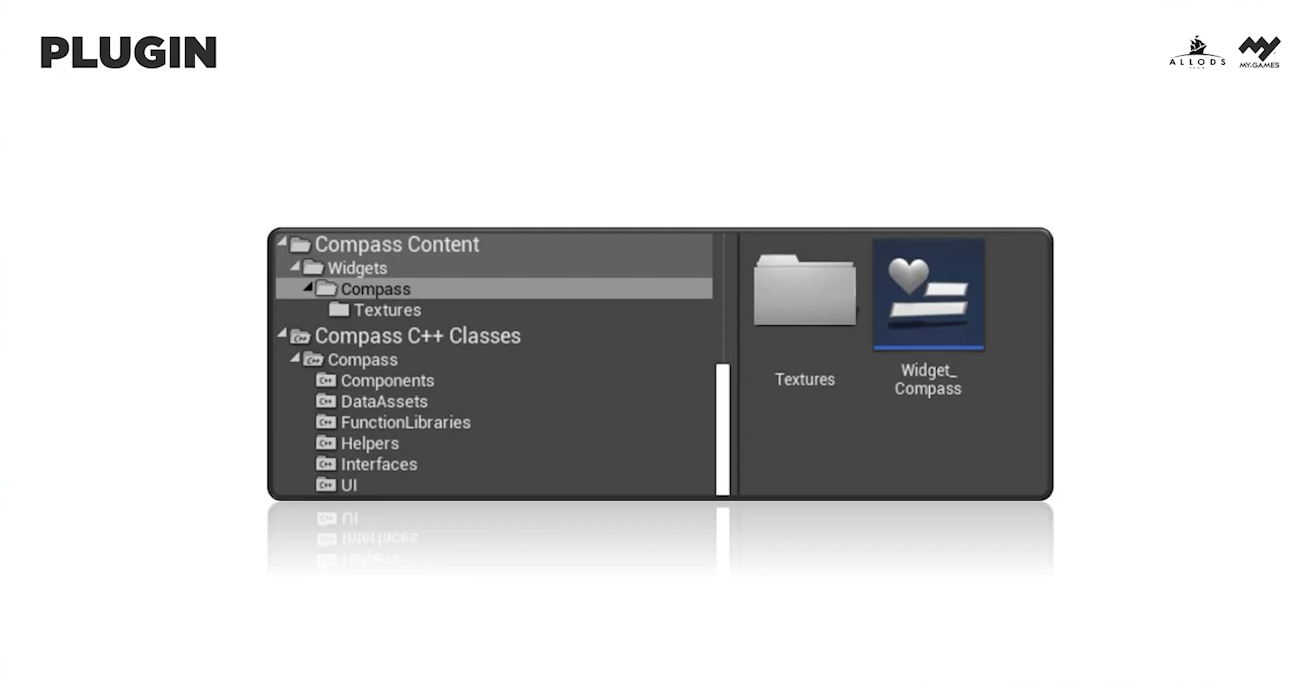
А вот плагины мы используем в случаях, когда речь идет о разработке более комплексных фичей, которые сложно уместить в один Unreal Engine Module. Или же когда фича, помимо самого Unreal Engine Module, содержит в себе какой-либо контент. Например, наш Compass Plugin — это плагин, состоящий из Compass Module, в котором находится реализация поведения игрового компаса, а также из Widget, который является базовым UI-представлением компаса. Этот Widget можно использовать на этапе прототипирования как готовое решение из коробки, а в последующем как шаблон для реализации своего уникального UI-представления.
Модульный подход лежит в корне cross-sharing’a технических решений между проектами, поскольку мы можем использовать готовую фичу на другом проекте. И при необходимости мы улучшаем и расширяем наши наработки. Таким образом, мы существенно экономим время и ресурсы при разработке и прототипировании проектов.
Coding Standard
Прежде чем говорить о стандартизации кода, следует подчеркнуть, что у нас внутри работают независимые друг от друга команды, у каждой из которых есть своя история, свой опыт и набитые шишки, а соответственно, и свои стандарты. Но в основе этих подходов лежит общая стандартизация кода от Epic Games.
Выбор основного стандарта кода от Epic Games обусловлен тем, что мы не стали изобретать велосипед, а применили существующий стандарт, с которым каждый день встречаются разработчики на Unreal Engine. За счет этого при найме новых сотрудников у нас нет необходимости переучивать их на наш уникальный стандарт. Но если кто-то не знает стандартизации кода от Epic Games, то он быстро этому обучится, потому что будет встречать его 90% времени (стоит учитывать, что Epic Games в исходниках движка не везде соблюдает свои же стандарты — все же они такие же разработчики, как и мы с вами, и им тоже не всегда хватает времени на вычитку).
Кроме того, если вы пишете собственный стандарт кода, то, скорее всего, его будет сложно использовать, потому что он далеко не всегда будет устраивать всех разработчиков в разных командах. Лучше брать что-то более обобщенное, что уже было придумано до вас.
Что касается документации самого стандарта, то в качестве основы мы используем документацию от Epic Games, но в разных командах есть незначительные отличия в виде расширений или улучшений. Я крайне не советую все это переносить в свою документацию по следующим причинам:
-
документация быстро разрастается, из-за чего сложно найти нужную часть;
-
так как прогресс не стоит на месте, документация быстро становится out-of-date;
-
подобного типа документы обычно хранятся в отдельном месте (например, в Confluence), а не рядом с кодом, с которым работает разработчик;
-
ну и давайте будем честны — мало кто читает документацию, потому что на это зачастую не хватает времени.
Вместо этого в качестве документации мы используем код, хранящийся в отдельном плагине, который содержит в себе Unreal Engine Module и ассеты. Ассеты содержатся в виде блюпринтов, в которых также находится описание стандартизации кода — это важно, потому что стандартизация кода блюпринтов никак не должна отличаться от обычных стандартов, которые используются при разработке на C++ в Unreal Engine.
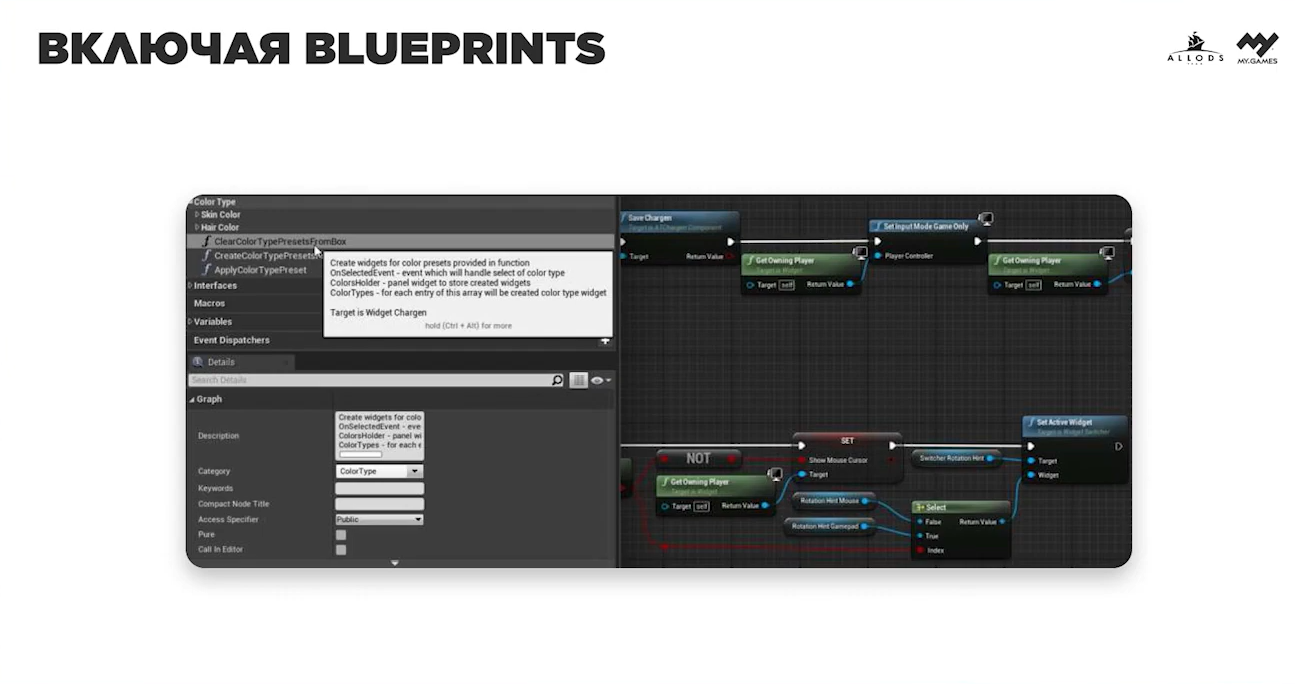
Такой подход лучше всего проявил себя при код-ревью, потому что у нас больше нет необходимости кидать ссылку на документацию и заставлять сотрудника что-то там искать — нам достаточно указать на строчку кода в CodingStandard.h или CodingStandard.cpp.
У разных команд есть отличия в стандартах, но они не слишком сильные:
-
порядок и стиль написания #include;
-
правила комментирования функций и переменных;
-
порядок и использование Metadata Specifiers.
Data Standard
Мы считаем, что если есть стандартизация кода, то должна быть и стандартизация данных (ассетов). Но речь идет не о блюпринтах — для них у нас есть Coding Standard. В стандартизацию данных входят следующие вещи:
-
стандартизация наименования контента (Naming Conventions);
-
стандартизация структуры папок проекта;
-
стандартизация мешей;
-
стандартизация текстур;
-
стандартизация уровней.
В случае со стандартизацией данных у Epic Games нет конкретного стандарта, а есть лишь набор рекомендаций, да и те разбросы по множеству статей в документации. И здесь на помощь приходит комьюнити, которое по большей части решило проблему.
Но вот в отличие от Coding Standard, Data Standard у нас задокументирован в Сonfluence — по этой причине Data Standard сильно зависит от проекта и может меняться под него. Да, есть некоторые общие вещи, которые всегда будут похожи у разных проектов, но все-таки большая часть стандартов всегда будет отличаться. Вот некоторые примеры:
-
стандартизация наименования контента — быстро разрастается под проект, особенно если разработка ведется в парадигме Data Driven Gameplay. Это происходит из-за того, что при использовании только префиксов DA_/DT_ для именования ассетов с данными, появляются проблемы с их поиском и фильтрацией;
-
стандартизация мешей — основные правила, что описаны в Style Guide, сильно дополнены, например, правилами именования сокетов;
-
стандартизация текстур — максимальное разрешение текстуры сильно зависит от платформ, для которых разрабатывается проект.
Data Validation
Поскольку у нас есть стандартизация данных, то должна быть и их валидация. Валидация данных — это инструмент, который позволяет следить за тем, чтобы в проектном репозитории всегда хранились только валидные и правильно оформленные данные. В первую очередь при валидации данных мы смотрим на следующие вещи.
1) Соответствие данных актуальным стандартам:
-
в реальности разработчик не может все держать в голове или постоянно смотреть в документацию;
-
не забываем про проблемы документации стандартов, которая часто и быстро меняется вместе с проектом. Также помним, что документацию далеко не все читают.
2) Данные, хранящиеся в репозитории, должны быть валидными — то есть не содержать ошибок или предупреждений.
3) «Эффект бабочки» — это явление, при котором мельчайшие изменения в одном файле могут повлечь проблемы в других связанных файлах.
Для валидации данных у Epic Games уже есть готовое решение (даже несколько) в виде Data Validation Plugin. Подробнее об этом и о том, что мы валидируем, вы сможете прочитать в нашей следующей статье, которая выйдет в ближайшее время, а пока пройдемся только по ключевым местам.
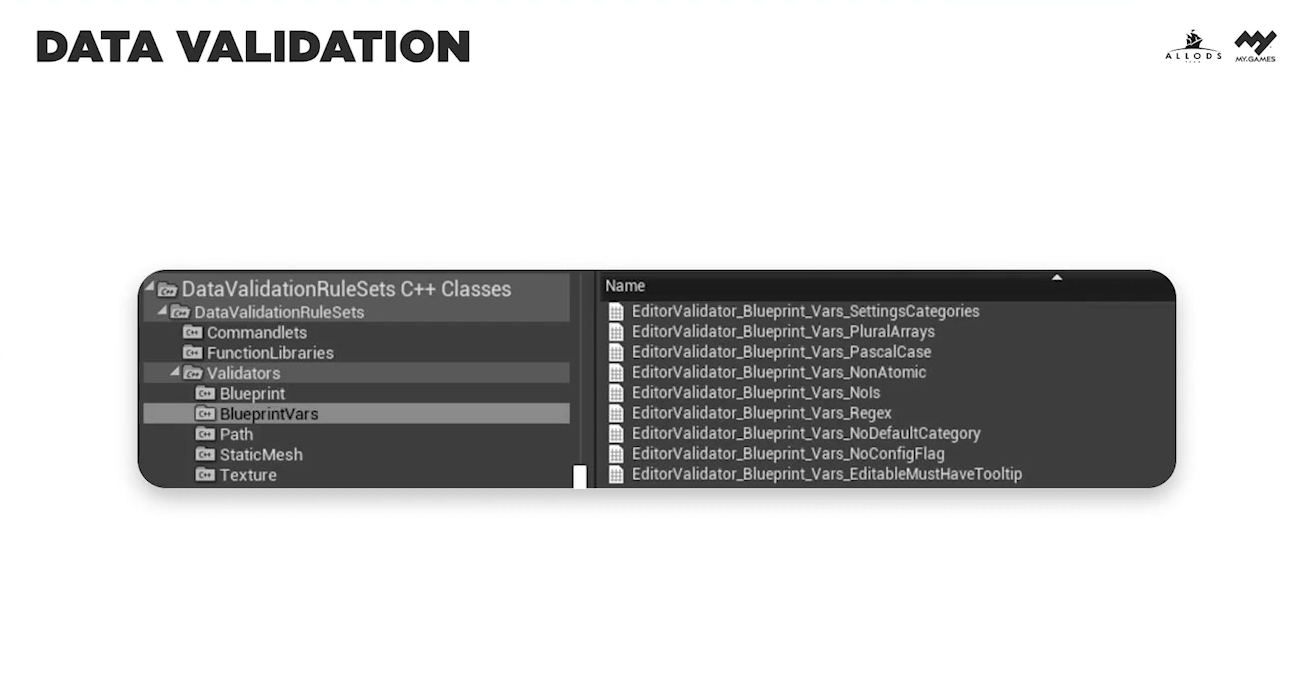
Прежде всего мы валидируем:
-
Любые данные — Naming Convention. Хороший нейминг помогает разработчикам легче ориентироваться в проекте. Если каждый начинает использовать свой собственный нейминг, то это превращается в очень сложную задачу и, как правило, заканчивается дублированием данных.
-
Любые импортируемые данные. Все исходные данные, которые импортируются в проект, должны быть размещены на специальном виртуальном диске, который является представлением контентного репозитория. Мы не допускаем пути импорта с рабочего стола!
-
Блюпринты. Больше всего внимания мы уделяем ошибкам и предупреждениям. Если с первыми все понятно, то вот по поводу вторых стоит уточнить. Может показаться, что предупреждения, которые выдает движок — это не так уж страшно. Но на самом деле это не так — если вы игнорируете предупреждения, то готовьтесь к тому, что когда-то, и скорее всего, в самое неподходящее время, такое предупреждение превратится в ошибку. И поскольку с момента, когда появилось предупреждение, до его трансформации в ошибку, могло пройти много времени, цена поиска проблемы и ее устранения может быть слишком высока.
-
Variables (в блюпринтах). Часть нашей стандартизации кода, все системные переменные, нужно помещать в отдельную категорию и сопровождать их комментариями. Это необходимо для того, чтобы контент-мейкеры понимали, какие данные изменять можно, а какие являются системными и лучше их не трогать.
-
Textures. В работе с ними важно следить за тем, чтобы разрешение сторон текстуры всегда было кратным степени двойки. Также важно, чтобы размер текстуры не превышал пороговое значение, заданное под проект. Например, если мы делаем проект для мобильной платформы и загружаем туда текстуру разрешением 8К, то это приведет к большим проблемам с текстурной памятью, а такое встречается очень часто.
-
Static Meshes. Проверяем UV, избегаем overlapping, ну и посматриваем на валидность LOD’ов.
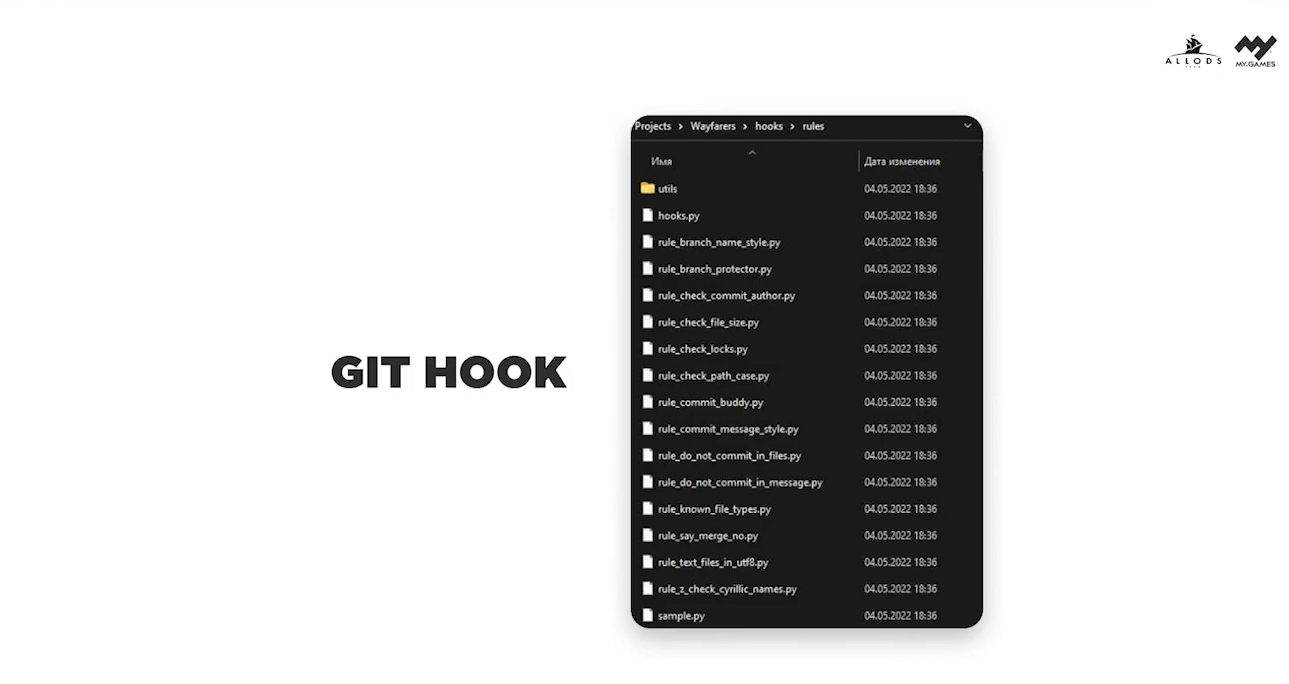
Сам процесс валидации данных запускается при помощи клиентского Git Hook — он запускает сommandlet, который проверяет каждый файл, указанный в коммите.
Source Code/Data Management
Все проектные данные хранятся в двух различных репозиториях:
-
проектный репозиторий — тут мы используем Git, естественно, поверх которого стоит Git LFS;
-
артовый репозиторий с исходниками (речь идет о любых исходниках, в том числе и о гигантских PSD), для которого мы используем SVN.
Почему мы в Allods Team используем Git, а не Perforce? К сожалению, у меня нет конкретного ответа — так исторически сложилось что ли. Но я успел поработать с Perforce в рамках разработки проекта на Unreal Engine и вот мое личное мнение: что Git не очень справляется со всеми возложенными на него задачами (речь идет именно о работе в связке с Unreal Engine), что Perforce не огонек. К сожалению, серебряную пулю никто так и не сделал (ну или я не в курсе), везде есть свои плюсы и минусы. Единственное, чем Perforce подкупает — это готовые технические решения от Epic Games. Но даже сейчас все это легко перекрывается отличными Open Source решениями.

Интересное наблюдение: все чаще и чаще слышу о том, что часть разработчиков перебирается на Plastic SCM. Я с ним не работал, поэтому если у вас есть опыт взаимодействия, делитесь им в комментариях, очень интересно почитать.
Теперь про SVN — художникам с ним проще работать (да и большинство художников только с ним и работали). Но на этот счет у нас в команде есть правило: любой художник, работающий над проектом, должен знать хотя бы основы Git — pull/push/branch и кого звать, когда происходит конфликт.
Зачем художникам все это? Художники (тут речь больше о 3D Artist’ах, художниках по текстурам, иногда о UI Artist’ах и так далее) отвечают за свой контент от самого начала разработки до полной интеграции контента в проект, поэтому им нужно знать Git. Конечно, у нас есть технический художник, который занимается интеграцией и автоматизацией этих процессов, но дело не в этом — художникам нужно понимать и видеть, как их работа выглядит в самом проекте после того, как применяются постпроцессы и шейдинг. Поэтому достаточно важно, чтобы художники самостоятельно умели интегрировать в проект свои наработки, в том числе и заливать их (порой даже в свои экспериментальные ветки).
Ну и вторым плюсом является более простой sparse checkout: когда нужна конкретная папка, можно достать только ее (ну и контент в ней), а не выкачивать весь репозиторий разом. У нас даже есть пример того, когда это может пригодиться. Допустим, у кого-то из Allods Team появилась задача посмотреть старые артовые наработки Skyforge, а все они весят 4 Тб. Если бы они были в Git, то пришлось бы качать все 4 Тб, что заняло бы примерно неделю. Откуда я знаю, сколько времени на это уйдет? Как-то раз пришлось скачивать полностью все исходники.
По этой причине арт у нас в SVN, а проект — в Git.
Git
Как я ранее уже написал, мы используем Git Hook’и, и помимо клиентского хука для валидации данных, у нас множество различных серверных хуков. Вот описание некоторых из них:
-
Commit Message может быть только на английском языке;
-
Commit Message должен содержать номер задачи;
-
имя файлов не должно содержать кириллицу;
-
все большие файлы должны быть только в Git LFS.
Конечно же, в работе с Git мы активно используем ветки — любой разработчик может при необходимости создавать отдельные ветки и работать в них. Это особенно важно, когда речь идет о больших фичах, реализация которых изначально делается только в отдельных ветках — в них же периодически подмердживается основная ветка. А ветка под фичу попадает в основную только после проверки отделом QA.
Но есть еще один нюанс при работе команды над одним проектом в Unreal Engine: все файлы, которые мы видим в Content Browser (они являются частью проекта) — это, как правило, бинарные файлы. Что это значит для нас: если два разработчика будут одновременно работать над одним файлом, то у того, кто будет заливать свои изменения последним, обязательно произойдет конфликт. А поскольку файлы бинарные, то ему придется переделывать свою работу.
Ранее, года три-четыре назад, при работе с Git нам приходилось писать в специальный чатик, что ты забрал такой-то файл в работу и его лучше не трогать. И это было не очень удобно. Но прогресс не стоит на месте. Поскольку поверх Git у нас стоит Git LFS — мы активно используем систему локов (да-да-да, в Git LFS есть система локов файлов, которая очень похожа на таковую в Perforce.
Как это устроено. Если разработчик хочет работать с тем или иным файлом, то он должен сначала его залокать. Эта процедура зарезервирует файл только под конкретного разработчика, и никто больше не сможет залить его, пока не будет снят лок.
При этом сама процедура лока и его снятия может быть выполнена через Git Bash или любой Git Client, поддерживающий эту функцию, а также через сам Unreal Engine при помощи Source Control Plugin. Если хотите попробовать, то вот достаточно хорошее решение для работы в движке. Самое главное в этом процессе — научить людей снимать локи, когда они заканчивают работу. Чтобы справиться с этим, мы применили автоматизацию: после коммита происходит автоматическое снятие лока. Тут не будет каких-то открытий или ноу-хау, просто раз уж я говорю обо всем по чуть-чуть, то надо и по CI/CD немного пройтись. На самом деле я сконцентрируюсь преимущественно на CI. Для начала давайте освежим, что такое CI. Continuous Integration подразумевает частые автоматизированные сборки проекта с целью быстрого выявления интеграционных проблем. У вас всегда будет актуальная и готовая к тестам версия продукта. Для всего этого мы используем Jenkins. Сам процесс настройки Jenkins описывать не буду, но вот несколько вещей, которые советуем сделать первым делом. 1) Система нотификаций. Не важно, каким мессенджером вы пользуетесь, нотификации сильно облегчат вам жизнь! Сборка не собралась? Надо чинить. И чем быстрее мы это сделаем, тем лучше. Post Commit Build. После каждого коммита мы запускаем сборку (без деплоя артефактов), она помогает обнаруживать ошибки компиляции и сборки проекта на самых ранних этапах разработки. Nightly Stable Build. В конце каждого дня мы снимаем текущий срез с основной рабочей ветки, собираем Debug Build, который каждое утро попадает в руки к нашим QA для Smoke-тестирования. 3) Использование Сommandlets как Build Step. Это набор дополнительных шагов-инструкций для сборок. Например: запекание света, расчет навигационного меша для AI. Зачем нам нужны Сommandlets, если все это можно сделать в редакторе? Во-первых, не у всех есть мощное железо, чтобы посчитать что-то быстро. Во-вторых, ошибки иногда все же случаются, например, кто-то может забыть сохранить карту вместе с рассчитанным Nav Mesh. Это самая грустная часть моего текста, потому что автотесты у нас есть, но далеко не на все. Основная трудность в том, что при разработке фичи, написание качественного автотеста с хорошим покрытием всех сценариев занимает 60-70% времени от создания самой фичи. И как правило, автотесты пишут сами программисты, потому что QA, знающие Gauntlet или просто Unreal Engine в контексте разработки автотестов, очень редки. А бизнес суров, порой сложно объяснить ценность автотестов в сравнении с какой-нибудь новой игровой механикой. Но у каждого проекта есть две части, которые обязательно нужно покрыть автотестированием — это backend и все, что связано с экономикой (в том числе и монетизация)! Без автотестов backend’a и экономики вы сильно рискуете в один прекрасный день увидеть свой сервис на сервере просто мертвым и с испорченными данными. Это в лучшем случае, а в худшем — понесете финансовые потери. Поэтому собирайте отдельную команду из QA, которая будет писать автотесты для backend’a, потому что там слишком много кейсов, которые обычным ручным тестированием покрыть невозможно! Как и говорилось ранее, прогресс не стоит на месте, а вместе с ним и мы! Мы продолжаем дальше набираться опыта и совершенствоваться, в наших планах разработка и интеграция следующих интересных вещей, о которых я расскажу в будущем: Clang-Tidy для Unreal Engine; Linter для Unreal Engine; интеграция системы багтрекинга в Unreal Engine. И это лишь малая часть того, что мы разрабатываем для работы с проектами. Еще осталось много того, о чем хотелось бы рассказать, но что не уместилось в рамках этой статьи. Вот некоторые из тем: Derived Data Cache; PSO Caching; Multi-User Editing; BuildGraph. Если что-то из этого вам интересно, то пишите в комментариях — наиболее востребованная тема отправится в печать первой. Ну а в остальном, спасибо всем за внимание, до новых встреч!
CI/CD
Автотесты


