
Сегодня граф – один из самых приемлемых способов описать модели, созданные в системе машинного обучения. Эти вычислительные графики составлены из вершин-нейронов, соединенных ребрами-синапсами, которые описывают связи между вершинами.
В отличие скалярного центрального или векторного графического процессора, IPU – новый тип процессоров, спроектированный для машинного обучения, позволяет строить такие графы. Компьютер, который предназначен для управления графами – идеальная машина для вычислительных моделей графов, созданных в рамках машинного обучения.
Один из самых простых способов, чтобы описать процесс работы машинного интеллекта – это визуализировать его. Команда разработчиков компании Graphcore создала коллекцию таких изображений, отображаемых на IPU. В основу легло программное обеспечение Poplar, которое визуализирует работу искусственного интеллекта. Исследователи из этой компании также выяснили, почему глубокие сети требуют так много памяти, и какие пути решения проблемы существуют.
Poplar включает в себя графический компилятор, который был создан с нуля для перевода стандартных операций, используемых в рамках машинного обучения в высокооптимизированный код приложений для IPU. Он позволяет собрать эти графы воедино по тому же принципу, как собираются POPNN. Библиотека содержит набор различных типов вершин для обобщенных примитивов.
Графы – это парадигма, на которой основывается все программное обеспечение. В Poplar графы позволяют определить процесс вычисления, где вершины выполняют операции, а ребра описывают связь между ними. Например, если вы хотите сложить вместе два числа, вы можете определить вершину с двумя входами (числа, которые вы хотели бы сложить), некоторые вычисления (функция сложения двух чисел) и выход (результат).
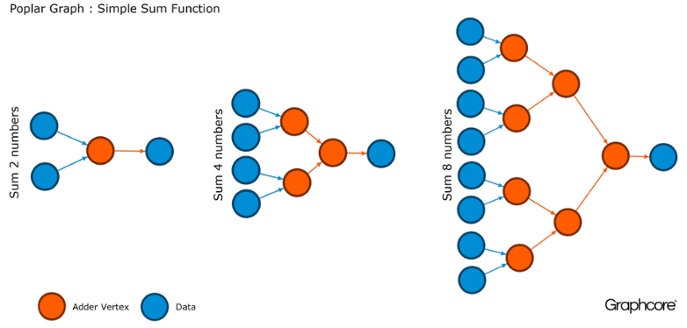
Обычно операции с вершинами гораздо сложнее, чем в описанном выше примере. Зачастую они определяются небольшими программами, называемыми коделетами (кодовыми именами). Графическая абстракция привлекательна, поскольку не делает предположений о структуре вычислений и разбивает вычисления на компоненты, которые процессор IPU может использовать для работы.
Poplar применяет эту простую абстракцию для построения очень больших графов, которые представлены в виде изображения. Программная генерация графика означает, что мы можем адаптировать его к конкретным вычислениям, необходимым для обеспечения наиболее эффективного использования ресурсов IPU.
Компилятор переводит стандартные операции, используемые в машинных системах обучения, в высокооптимизированный код приложения для IPU. Компилятор графов создает промежуточное изображение вычислительного графа, которое разворачивается на одном или нескольких устройствах IPU. Компилятор может отображать этот вычислительный граф, поэтому приложение, написанное на уровне структуры нейронной сети, отображает изображение вычислительного графа, который выполняется на IPU.

Граф полного цикла обучения AlexNet в прямом и обратном направлении
Графический компилятор Poplar превратил описание AlexNet в вычислительный граф из 18,7 миллиона вершин и 115,8 миллиона ребер. Четко видимая кластеризация – результат прочной связи между процессами в каждом слое сети с более легкой связью между уровнями.
Другой пример – простая сеть с полной связью, прошедшая обучение на MNIST – простом наборе данных для компьютерного зрения, своего рода «Hello, world» в машинном обучении. Простая сеть для изучения этого набора данных помогает понять графы, которыми управляют приложения Poplar. Интегрируя библиотеки графов с такими средами, как TensorFlow, компания представляет один из простых путей для использования IPU в приложениях машинного обучения.
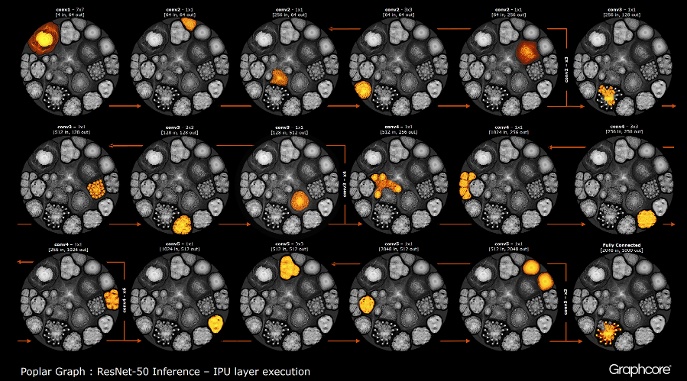
После того, как с помощью компилятора построился граф, его нужно выполнить. Это возможно с помощью движка Graph Engine. На примере ResNet-50 демонстрируется его работа.
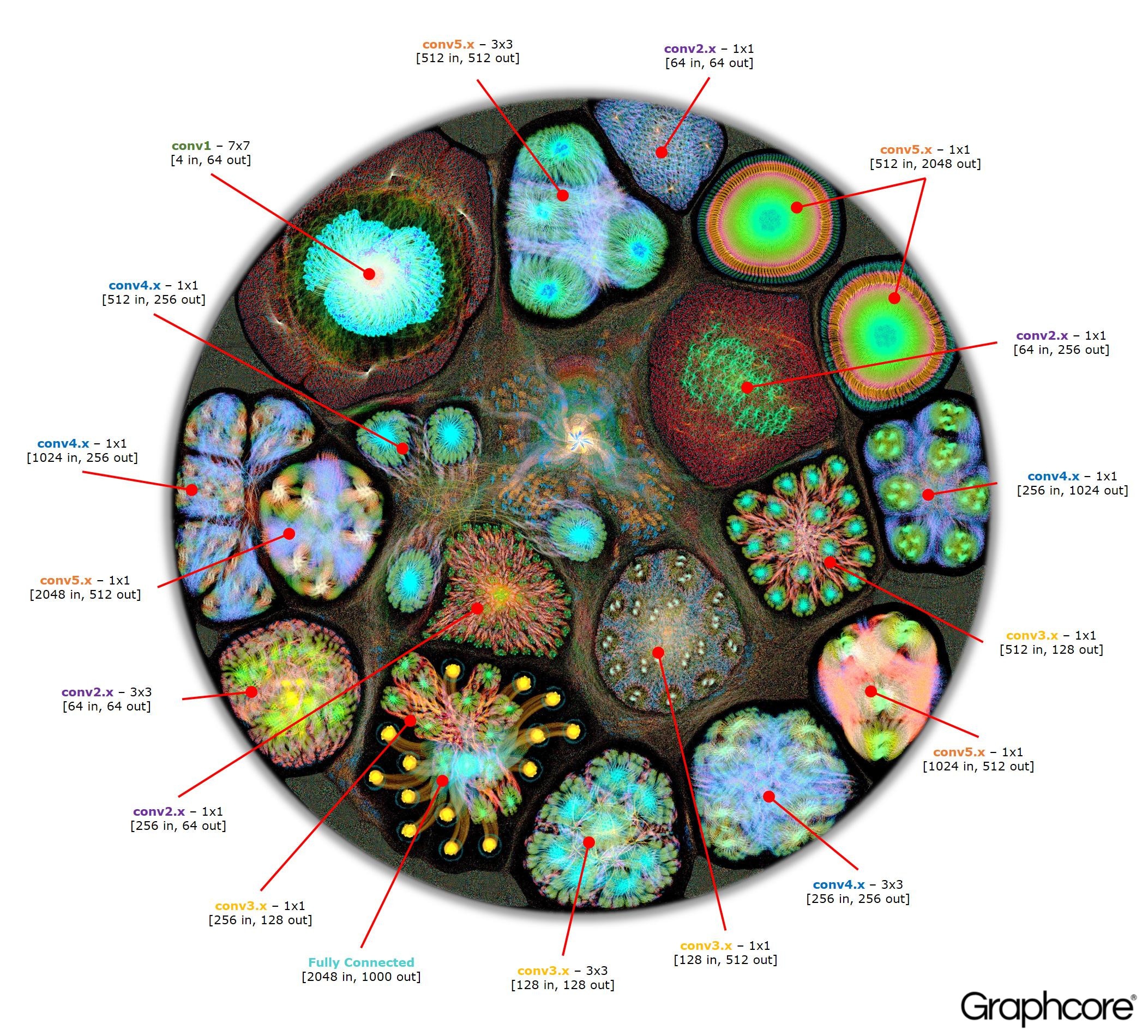
Граф ResNet-50
Архитектура ResNet-50 позволяет создавать глубокие сети из повторяющихся разделов. Процессору остается только единожды определить эти разделы и повторно вызывать их. Например, кластер уровня conv4 выполняется шесть раз, но только один раз наносится на граф. Изображение также демонстрирует разнообразие форм сверточных слоев, поскольку каждый из них имеет граф, построенный в соответствии с естественной формой вычисления.
Движок создает и управляет исполнением модели машинного обучения, используя граф, созданный компилятором. После развертывания Graph Engine контролирует и реагирует на IPU или устройства, используемые приложениями.
Изображение ResNet-50 демонстрирует всю модель. На этом уровне сложно выделить связи между отдельными вершинами, поэтому стоит посмотреть на увеличенные изображения. Ниже приведены несколько примеров секций внутри слоев нейросети.


Почему глубоким сетям нужно так много памяти?
Большие объемы занимаемой памяти – одна из самых больших проблем глубинных нейронных сетей. Исследователи пытаются бороться с ограниченной пропускной способностью DRAM-устройств, которые должны быть использованы современными системами для хранения огромного количества весов и активаций в глубинной нейронной сети.
Архитектуры были разработаны с использованием процессорных микросхем, предназначенных для последовательной обработки и оптимизации DRAM для высокоплотной памяти. Интерфейс между двумя этими устройствами является узким местом, которое вводит ограничения пропускной способности и добавляет значительные накладные расходы в потреблении энергии.
Хотя мы еще не имеем полного представления о человеческом мозге и о том, как он работает, в целом понятно, что нет большого отдельного хранилища памяти. Считается, что функция долговременной и кратковременной памяти в человеческом мозге встроена в структуру нейронов+синапсов. Даже простые организмы вроде червей с нейронной структурой мозга, состоящей из чуть более 300 нейронов, обладают в какой-то степени функцией памяти.
Построение памяти в обычных процессорах – это один из способов обойти проблему узких мест памяти, открыв огромную пропускную способность при гораздо меньшем энергопотреблении. Тем не менее, память на кристалле – дорогая штука, которая не рассчитана на действительно большие объемы памяти, которые подключены к центральным и графическим процессорам, в настоящее время используемым для подготовки и развертывания глубинных нейронных сетей.
Поэтому полезно посмотреть на то, как память сегодня используется в центральных процессорах и системах глубокого обучения на графических ускорителях, и спросить себя: почему для них необходимы такие большие устройства хранения памяти, когда головной мозг человека отлично работает без них?
Нейронным сетям нужна память для того, чтобы хранить входные данные, весовые параметры и функции активации, как вход распространяется через сеть. В обучении активация на входе должна сохраняться до тех пор, пока ее нельзя будет использовать, чтобы вычислить погрешности градиентов на выходе.
Например, 50-слойная сеть ResNet имеет около 26 миллионов весовых параметров и вычисляет 16 миллионов активаций в прямом направлении. Если вы используете 32-битное число с плавающей запятой для хранения каждого веса и активации, то для этого потребуется около 168Мб пространства. Используя более низкое значение точности для хранения этих весов и активаций, мы могли бы вдвое или даже вчетверо снизить это требование для хранения.
Серьезная проблема с памятью возникает из-за того, что графические процессоры полагаются на данные, представляемые в виде плотных векторов. Поэтому они могут использовать одиночный поток команд (SIMD) для достижения высокой плотности вычислений. Центральный процессор использует аналогичные векторные блоки для высокопроизводительных вычислений.
В графических процессорах ширина синапса составляет 1024 бит, так что они используют 32-битные данные с плавающей запятой, поэтому часто разбивают их на параллельно работающие mini-batch из 32 образцов для создания векторов данных по 1024 бит. Этот подход к организации векторного параллелизма увеличивает число активаций в 32 раза и потребность в локальном хранилище емкостью более 2 ГБ.
Графические процессоры и другие машины, предназначенные для матричной алгебры, также подвержены нагрузке на память со стороны весов или активаций нейронной сети. Графические процессоры не могут эффективно выполнять небольшие свертки, используемые в глубоких нейронных сетях. Поэтому преобразование, называемое «понижением», используется для преобразования этих сверток в матрично-матричные умножения (GEMM), с которыми графические ускорители могут эффективно справляться.
Дополнительная память также требуется для хранения входных данных, временных значений и инструкций программы. Измерение использования памяти при обучении ResNet-50 на высокопроизводительном графическом процессоре показало, что ей требуется более 7,5 ГБ локальной DRAM.
Возможно, кто-то решит, что более низкая точность вычислений может сократить необходимый объем памяти, но это не так. При переключении значений данных до половинной точности для весов и активаций вы заполните только половину векторной ширины SIMD, потратив половину имеющихся вычислительных ресурсов. Чтобы компенсировать это, когда вы переключаетесь с полной точности до половины точности на графическом процессоре, тогда придется удвоить размер mini-batch, чтобы вызвать достаточный параллелизм данных для использования всех доступных вычислений. Таким образом, переход на более низкую точность весов и активаций на графическом процессоре все еще требует более 7,5ГБ динамической памяти со свободным доступом.
С таким большим количеством данных, которые нужно хранить, уместить все это в графическом процессоре просто невозможно. На каждом слое сверточной нейронной сети необходимо сохранить состояние внешней DRAM, загрузить следующий слой сети и затем загрузить данные в систему. В результате, уже ограниченный пропускной способностью задержкой памяти интерфейс внешней памяти страдает от дополнительного бремени постоянной перезагрузки весов, а также сохранения и извлечения функций активации. Это значительно замедляет время обучения и значительно увеличивает потребление энергии.
Существует несколько путей решения этой проблемы. Во-первых, такие операции, как функции активации, могут выполняться “на местах”, позволяя перезаписывать входные данные непосредственно на выходе. Таким образом, существующую память можно будет использовать повторно. Во-вторых, возможность для повторного использования памяти можно получить, проанализировав зависимость данных между операциями в сети и распределением той же памяти для операций, которые не используют ее в этот момент.
Второй подход особенно эффективен, когда вся нейронная сеть может быть проанализированна на этапе компиляции, чтобы создать фиксированную выделенную память, так как издержки на управление памятью сокращаются почти до нуля. Выяснилось, что комбинация этих методов позволяет сократить использование памяти нейронной сетью в два-три раза.
Третий значительный подход был недавно обнаружен командой Baidu Deep Speech. Они применили различные методы экономии памяти, чтобы получить 16-кратное сокращение потребления памяти функциями активации, что позволило им обучать сети со 100 слоями. Ранее при том же объеме памяти они могли обучать сети с девятью слоями.
Объединение ресурсов памяти и обработки в одном устройстве обладает значительным потенциалом для повышения производительности и эффективности сверточных нейронных сетей, а также других форм машинного обучения. Можно сделать компромисс между памятью и вычислительными ресурсами, чтобы добиться баланса возможностей и производительности в системе.
Нейронные сети и модели знаний в других методах машинного обучения можно рассматривать как математические графы. В этих графах сосредоточено огромное количество параллелизма. Параллельный процессор, предназначенный для использования параллелизма в графах, не полагается на mini-batch и может значительно уменьшить объем требуемого локального хранилища.
Современные результаты исследований показали, что все эти методы могут значительно улучшить производительность нейронных сетей. Современные графические и центральные процессоры имеют очень ограниченную встроенную память, всего несколько мегабайт в совокупности. Новые архитектуры процессоров, специально разработанные для машинного обучения, обеспечивают баланс между памятью и вычислениями на чипе, обеспечивая существенное повышение производительности и эффективности по сравнению с современными центральными процессорами и графическими ускорителями.
Источник

