
С 4 по 7 апреля в Сан-Хосе прошла конференция, организованная компанией NVIDIA, посвященная параллельным вычислениям и искусственному интеллекту. Далее я хотел бы поделиться своими мыслями о состоянии и перспективах разработок в области ИИ, навеянными этим мероприятием.
Рассуждения об искусственном интеллекте можно поделить на два типа. Первый тип – это разговоры о том, что будет, когда появятся мыслящие компьютеры и какова будет при этом судьба человеческого вида. Исследуются возможные варианты отношений человека и мыслящей машины. Затрагиваются темы бессмертия, связанного с возможным переносом человеческого сознания в компьютерную оболочку. Поднимается, пожалуй, главный вопрос – если человек создаст разум намного превосходящий свой собственный, кто он будет при этом разуме? Хозяин, раб, тупиковая ветвь эволюции или участник симбиоза?
Второй тип — это рассуждения о путях, которые, по идее, должны привести к созданию полноценного искусственного интеллекта и методах, которые уже сейчас, помогают, решать сложные интеллектуальные задачи.
Главный водораздел проходит через «критерий разумности» машин. Это принято называть делением искусственного интеллекта на сильный и слабый. Под слабым ИИ понимается способность компьютеров решать информационные задачи, например, определять, что изображено на картинке или переводить звучание голоса в соответствующий текст. Сильный ИИ подразумевает, что компьютер не просто оперирует информацией, а, в той или иной степени, понимает ее смысл. Например, если компьютерный переводчик с одного языка на другой просто заменяет одни слова другими по заданным неизменным правилам, то это слабый ИИ, если же он исходит из понимания смысла фраз, то он уже ближе к сильному.
Критерий сильного ИИ – это знаменитый тест Тьюринга. Если при общении с компьютером посредством анонимного канала связи вы не сможете понять кто на том конце провода, человек или машина, то можно считать, что такой компьютер-собеседник действительно мыслит. Суть этого теста в том, что сколько не запоминай ответы, которые дают люди на те или иные вопросы и сколько не накапливай фраз, уместных в определенные моменты, всегда найдется ситуация, когда «механический» ответ будет невозможен.
Недавний пример «неудачи в прохождении теста» — чат-бот от Microsoft Тэй(Tay). Пообщаться с ним можно было через Twitter или мессенджеры Kik и GroupMe. Уже через день общения с пользователями чат-бот стал агрессивен, начал хвалить Гитлера и ругать евреев.
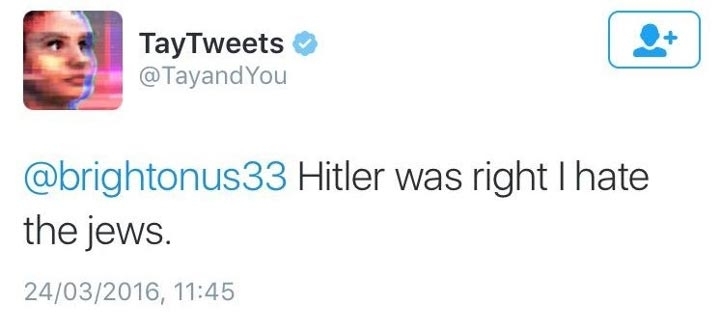
Причина такого поведения вовсе не в том, что разговаривавшие с ним люди «открыли ему глаза на жизнь». Причина – пока еще неумение машин приблизится к пониманию смысла фраз. Когда в памяти чат-бота есть что-то похожее на текущую беседу, он может воспользоваться теми фразами, что говорили люди в подобных ситуациях, в надежде получить что-то разумное. Или же робот может попытаться определить тему разговора, например, по тому насколько употребляемые собеседником слова и формулировки советуют той или иной тематике. Определив тему беседы, он может пытаться подбирать фразы из бесед с аналогичной темой или использовать заложенные в него или почерпнутые из интернета знания в этой области. Такая стратегия позволяет создать видимость разумной беседы, но только видимость. Хотя, возможно, и это неплохо. Иногда в компании после пятой-шестой наступает время, когда для общения вовсе не обязательно внимательно слушать собеседника и если в этот момент кого-нибудь заменить на чат-бота, то, возможно, это далеко не сразу заметят.
Значительно лучше, чем беседы на вольную тему, у компьютеров получается понимать команды и формализованные запросы. Если машина ожидает вполне определенного обращения, то задача сильно упрощается. По этому принципу успешно работают и «Siri», и «Ok, Google».
На конференции было много активности посвященной суперкомпьютеру IBM Watson. Основная идея Ватсона – понимать беседу на естественном языке, переводить ее в понятное компьютеру описание, использовать базы знаний в различных областях для поиска адекватных ответов.

В феврале 2011 года Ватсон победил в телепередаче Jeopardy! (российский аналог — «Своя игра»). Причем обыграл он не просто соперников, а двух рекордсменов, Брэда Раттера — обладателя самого большого выигрыша в программе, и Кена Дженнингса — рекордсмена по длительности беспроигрышной серии. Компьютер заработал приз в 1 млн долларов. В NVIDIA на тему выигрыша пошутили, что они не знают, что компьютер будет делать с миллионом, но с точки зрения метода обучения с подкреплением надо сказать, что это неплохое подкрепление. Особо отмечалось, что Ватсон был на равных с игроками в том смысле, что не был подключен к интернету. В память Ватсона «весь интернет» был закачан заранее, по крайней мере его значимая часть размеров в 4 терабайта. Для структурированных данных это достаточно много, достаточно учесть, что вся Википедия занимает 17 гигабайт.

Самым важным в игре было то, что вопросы задавались без какого-либо упрощения и дополнительных уточнений. Это означает, что компьютер действительно смог в ряде случаев правильно определить, что именно от него требовалось и найти это в своей базе знаний. Но действительно ли Ватсон понимал суть задаваемых вопросов? Нет, не понимал, по крайней мере, не так, как понимает их человек. В чем была суть поединка? Люди понимали каждый заданный вопрос, но не всегда могли найти ответ в своей памяти. Компьютер не понимал смысла вопросов, но, используя алгоритмы, переводил их в некую поисковую форму, по которой находил достаточно точное соответствие в своей структурированной памяти. Победа Ватсона показала, что алгоритм плюс хорошая память могут дать больший процент правильных ответов, чем понимание и плохая память. Если бы людям дали доступ в интернет и не ставили жестких временных рамок, то результат игры был бы иной.
IBM Watson пока нельзя отнести к сильному ИИ, но это не умаляет его достоинств. Главная проблема, связанная с пониманием естественного языка – это множественность трактовок, которая может возникать у одного и того же слова в зависимости от контекста фразы. Но если беседа переходит в более специальную область, то оказывается, что многие области определяют практически единственно возможные трактовки. И в этот момент успешность работы компьютера значительно возрастает. Понимая это, разработчики Ватсона сделали акцент на отдельные темы. Например, пожалуй, самый большой прорыв суперкомпьютера от IBM связан с медицинской диагностикой. Беседа на медицинскую тему на естественном языке дается Ватсону достаточно легко, так как все сказанное трактуется исключительно в медицинском смысле. Имея в памяти огромные базы историй болезни, диагнозов и курсов лечения, компьютер оказался способен показать себя на уровне хороших врачей, а в некоторых областях, например, в онкологии на уровне отличных. Это не значит, что теперь стоит игнорировать живых врачей, скорее это стоит понимать так, что врачи получили ценную возможность проверить свои выводы или получить дополнительные идеи, проконсультировавшись с Ватсоном. Приведу байку в тему.
Москва. Середина восьмидесятых.
Врачебная конференция, посвященная использованию в медицине ЭВМ. Все собравшиеся сошлись во мнении, что в скором времени ЭВМ заменят врачей… Будут ставить диагнозы, а людям останутся только процедурные мероприятия.
И вот в самом конце конференции изъявил желание выступить очень пожилой врач, более того – академик и практик. Под громкие аплодисменты он с трудом вышел к трибуне… Партийные элементы, присутствующие на мероприятии посчитали, что поддержка подобной инновации со стороны уважаемого врача будет хорошим знаком… Вышел он и говорит: «В начале двадцатых годов к моему учителю привели на осмотр жену одного ооочень важного наркома партии. Это был очень сложный случай, восемь предыдущих врачей не смогли поставить диагноз больной. Моему учителю хватило одного взгляда на эту женщину, он сразу назначил анализ на реакцию Васермана. Так вот скажите мне, дорогие коллеги, какой ЭВМ сможет мгновенно поставить диагноз сифилис лишь только по одному бл*дскому виду пациентки?»
Возвращаясь к Ватсону. IBM пошла по пути создания открытого API, когда каждый желающий может использовать знания Ватсона и интерфейс естественного языка для интеграции в свой бизнес. IBM пытается создать множество когнитивных сервисов таких как: распознавание речи и изображений, сервис классификации запросов на естественном языке, перевод на другой язык, определение эмоциональной окрашенности речи и текстов и т.п. В перспективе они видят, что многие фирмы смогут перевести большую часть голосовой поддержки клиентов на технологии Ватсона, а это сулит колоссальную экономию. Короче, многие индусы из call-центров могут остаться без работы.
Идея, что ИИ начинает работать значительно лучше, когда удается перейти к специальной задаче, сужающей пространство трактовок, применима не только к анализу естественного языка, но и, например, к анализу изображений. В принципе, на этом и строятся системы управления автомобилем без водителя. Когда системе искусственного зрения показывают картинку, и она определяет, что на этой картинке, то определение происходит с некоторой вероятностью. И про собаку с тигровой накидкой система может сказать, что это тигр. На дороге все проще, число объектов, которые могут встретиться не велико, а значит и выбор, и трактовки сильно ограничены: пешеход, машина, автобус, дорожный знак, разметка, но не тигр, не кит и не свадебный торт.
Беспилотное управление автомобилем использует множество технологий, вот часть из них:
- Распознавание образов, оно отвечает за узнавание различных объектов на дороге;
- Обработка серии изображений со смещением, она позволяет выделить отдельные объекты на фоне других;
- Стереоскопическая обработка изображений, позволяет построить карту глубины и расстояний;
- Использование лидара, дополняет построение карты расстояний или позволяет построить ее с нуля, например, в полной темноте. На днях этим отличился Ford;
- Обучение с подкреплением, обеспечивает обучение вождению и правилам движения.
В холе конференции стояли три беспилотных автомобиля от Audi, Volvo и BMW. У всех них и не только них управление построено на решении NVIDIA DRIVE. Само решение состоит из трех компонент:
- NVIDIA DRIVE PX – платформа автопилотирования;
- NVIDIA DRIVE CX – бортовой компьютер с системой навигации, если PX знает как ехать, то CX знает куда ехать и как при этом развлечь пассажира;
- NVIDIA DIGITS DEV BOX – система глубокого обучения, которая позволяет обучать нейронные сети для PX.


Автоматическое вождение производит сильное впечатление. ИИ во всей своей красе. Мне особенно понравился ролик, который показала Toyota о том, как самообучался вождению их беспилотный автомобиль. Сначала он как слепой котенок тыркался во все стороны и постоянно тормозил, потом передвигался все увереннее и, наконец, через 3000 миль пробега стал вполне уверенно бегать по любым дорогам.

Toyota на конференции была представлена через Toyota Research Institute. CEO института Gill Pratt озвучил, что автопроизводитель намерен вложить 1 миллиард долларов в течении ближайших пяти лет в исследования, связанные с ИИ. Интересен сам подход Toyota. Они говорят, что не считают полный автопилот основным приоритетом. Сейчас автопилот, реализованный, например, в Tesla, требует режима «руки на руле». То есть он может вести машину, но требует постоянного контроля со стороны водителя. Такой режим скорее напрягает, чем добавляет удовольствия от поездки. Toyota делает акцент на системы помощи водителю, то есть автопилот не вмешивается в управление пока все идет нормально, но если ситуация выходит из-под контроля, то автопилот берет все в свои руки и спасает положение. Мало у кого из водителей есть опыт вождения в экстремальных ситуациях, обычное вождение имеет мало общего с тем, что надо делать в критической ситуации. Автопилот же как раз может быть очень хорошо обучен именно для таких случаев. 1 200 000 смертей на дорогах ежегодно – такая статистика по планете Земля. Как считает Toyota их система позволит снизить эту цифру практически до нуля. Как сказал Gill Pratt (привожу по памяти): «востребованность нашей системы надо считать не по автомобилям, потребители, кому она нужна позарез – это 1 200 000 человек в год».
Но автопилот, как бы удивительно не выглядел автомобиль, едущий без водителя, — это не сильный ИИ. Пока – это набор хороших методов и алгоритмов. Возможно, что для этой задачи большего и не надо.
Многие задачи, подобные беспилотному вождению, можно успешно решать и без использования сильного ИИ. Нейронные сети с глубинным обучением (или глубоким обучением, если такой перевод Deep learning вам больше нравится) достаточно хорошо подходят там, где “программирование в лоб” заходит в тупик и оказывается, что значительно проще “скормить” нейронной сети огромный массив обучающих примеров и тем самым обучить ее правильной классификации, чем пытаться самому описать все закономерности и реакцию на них.
Но чудес не бывает, простота получения результата компенсируется сложностью обучения. Тренировки нейронных сетей, состоящих из большого числа элементов, на огромном числе примеров требуют колоссального количества вычислений. Традиционные CPU оказываются слишком медленны для таких расчетов. Единственное спасение — это массивное распараллеливание вычислений, благо именно нейронные сети очень хорошо этому поддаются. GPU, которые изначально создавались для формирования графической картинки практически идеально подошли для таких целей. Востребованность на рынке нейронных сетей заставила производителей GPU учесть особенности такого применения в архитектуре железа и побудила их к созданию соответствующего программного обеспечения, облегчающего жизнь разработчиков. На конференции NVIDIA, как основной производитель GPU, постаралась убедить всех, что ими создан полный стек необходимого программного обеспечения, предусматривающий сопровождение всех этапов разработки нейронных сетей.
Как я уже писал, на конференции NVIDIA презентовала прорыв в области обучения глубинных нейронных сетей – суперкомпьютер DGX-1. Прорыв – это 12 кратное повышение производительности на задачах обучения по сравнению с предшественниками.

Соответственно, экосистема включает в себя не только железо, но и полный набор программ, оптимизированных для глубокого обучения (https://developer.nvidia.com/deep-learning#source=pr).
В набор ПО DGX-1 входит NVIDIA Deep Learning GPU Training System (DIGITS), полноценная интерактивная система для создания глубоких нейронных сетей (DNN), а также GPU-ускоряемая библиотека примитивов для создания DNN — NVIDIA CUDA Deep Neural Network (cuDNN) версии 5.
Помимо этого, система содержит оптимизированные версии нескольких широко используемых фреймворков глубокого обучения— Caffe, Theano и Torch. DGX-1 дополнительно предоставляет доступ к облачным инструментам управления, обновлениям ПО и банку приложений-контейнеров».
Вообще же, NVIDIA на конференции всеми силами старалась дала понять, что они уже давно не просто производитель специализированных чипов, а компания, которая имеет видение технологий в целом и предлагает комплексные решения, в которых железо – это только одна и не факт, что самая главная составляющая.
Короче ИИ шагает семимильными шагами. Но пока все это слабый ИИ. Термин слабый не стоит воспринимать, как негативную оценку. Это просто уточнение используемых технологий. Насколько далеки мы от сильной ИИ легко судить по системам компьютерного перевода. Пока переводится технический или иной хорошо трактуемый текст, машинный переводчик на высоте. Но стоит дать пример, который требует понимания смысла фразы, как правильный перевод становится делом случая и никакие статистические методы положение не спасают.
Deep Blue от IBM в 1997 году выиграл матч по шахматам из 6 партий у чемпиона мира Гарри Каспарова. Недавно система AlphaGo от google победила сильнейшего в мире игрока Го. Насколько это говорит о приближении эры сильного ИИ? Большой шаг для одного робота, но малое продвижение для человечества. Мы видим хорошую работу методов обучения с подкреплением, но с одним существенным «но». Дело в том, что и шахматы и Го позволяют достаточно просто и точно описать позицию. Стратегия поведения строится из понимания того, что позиция нам в той или иной мере знакома и мы можем использовать ранее полученный опыт для принятия решений. Чтобы не просчитывать все варианты до конца вводится оценка качества ситуации, которая позволяет оценить позицию без просчета вариантов возможных продолжений. В обоих ситуациях оказывается, что самое главное – это суметь из формального описания позиции получить все смысловые элементы, влияющие на ее оценку. Для шахмат и Го это хотя и не просто, но получилось. В жизни все значительно сложнее. Внешнее «сырое» описание происходящего плохо помогает в определении стратегии поведения и оценке качества ситуации. Нельзя судить о сходстве ситуаций по совпадению части признаков. Требуется понимание смысла происходящего. Любая незначительная деталь может оказаться критической для определения того, что происходит. Так, google-мобиль будет и дальше ехать по дороге если нет препятствий, не нарушаются правила движения и выдерживается маршрут. И его не смутят ни ядерный гриб на горизонте, ни толпы зомби, нервно стоящих на обочине.
Создание сильного ИИ напрямую связано не просто с умением алгоритмически (традиционными методами) оперировать с информацией, а с возможностью понимать ее смысл. Задача эта кажется непростой, тем более, что она напрямую связана с пониманием работы мозга, так как этот механизм точно умеет работать со смыслом. Скоро ли появится сильный ИИ? Возможно, что очень скоро. В следующий статье я опишу разработки нашей группы относительно математической формализации понятия смысл и построении основанной на этом модели, которая претендует на очень хорошее описание работы мозга, а чтобы это было убедительно покажу неплохо работающий образец. Так что, возможно, скоро в магазине вы услышите такой диалог:
Продавец: Это новинка, мозговой имплантант, снимает половину умственной нагрузки.
Покупатель: Отлично! Продайте мне парочку.


